
Maison >base de données >tutoriel mysql >Analysons comment l'instruction de mise à jour de MySQL est exécutée.
Analysons comment l'instruction de mise à jour de MySQL est exécutée.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2022-03-31 12:08:162865parcourir
Cet article vous apporte des connaissances pertinentes sur mysql, qui présente principalement les problèmes liés à la façon dont une instruction de mise à jour est exécutée. Lorsque l'opération de mise à jour est exécutée, le cache de requêtes lié à la table sera invalide, donc l'instruction Tous les résultats mis en cache. sur la table sera nettoyé. Examinons-les ensemble, j'espère que cela sera utile à tout le monde.

Apprentissage recommandé : Tutoriel mysql
Préparation préliminaire
Créez d'abord une table, puis insérez trois données :
CREATE TABLE T( ID int(11) NOT NULL AUTO_INCREMENT, c int(11) NOT NULL, PRIMARY KEY (ID)) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='测试表';INSERT INTO T(c) VALUES (1), (2), (3);
Effectuons l'opération de mise à jour plus tard :
update T set c=c+1 where ID=2;
Avant de parler de l'opération de mise à jour , tout le monde passe en premier Jetez un œil au processus d'exécution des instructions SQL dans MySQL~
Le processus d'exécution des instructions SQL
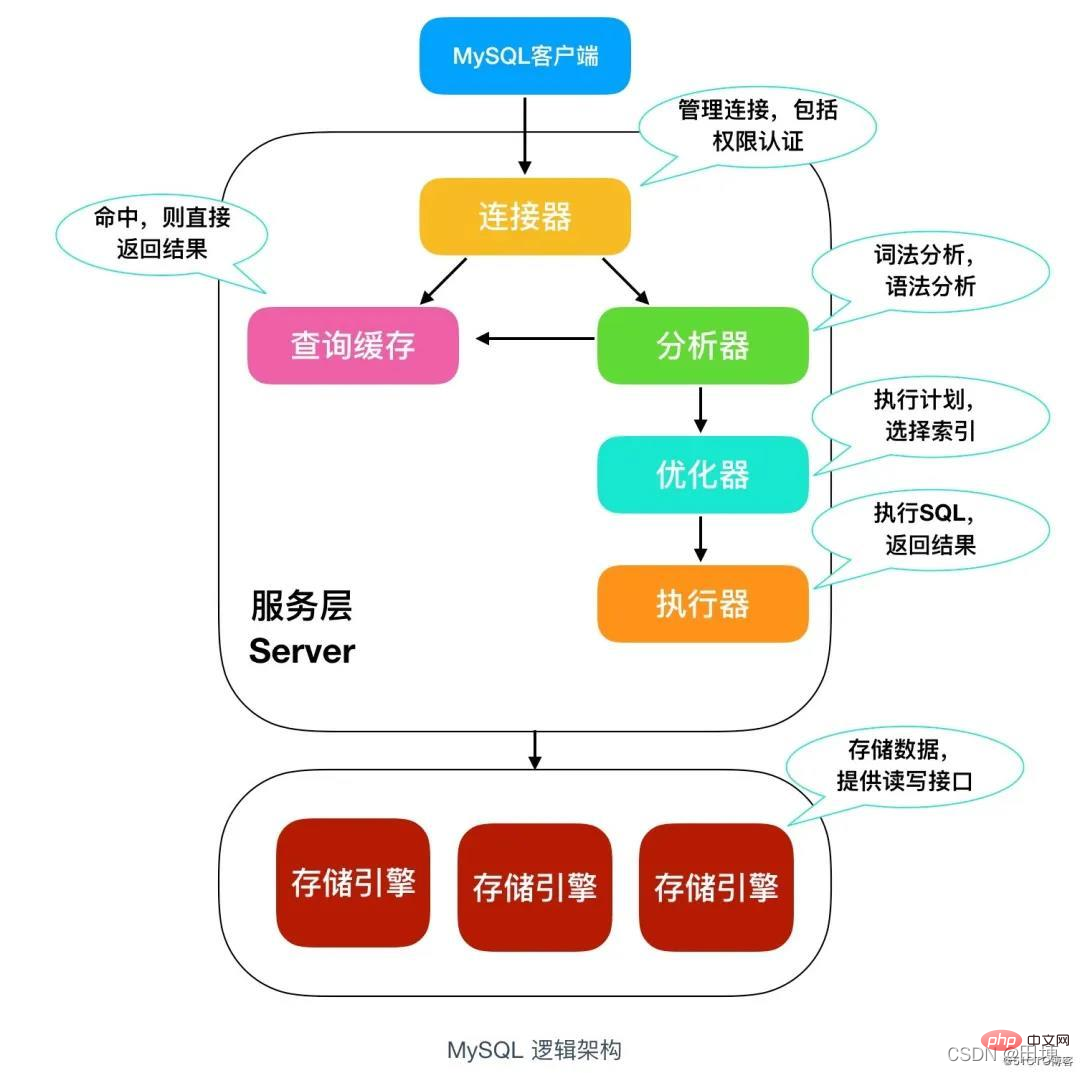
Comme le montre la figure : la base de données MySQL est principalement divisée en deux niveaux : Couche de service et Couche de service du moteur de stockage : la couche serveur comprend des connecteurs, des caches de requêtes, des analyseurs, des optimiseurs et des exécuteurs, y compris la plupart des fonctions de base de MySQL. Toutes les fonctions du moteur de stockage croisé sont également implémentées dans cette couche, y compris les procédures stockées, déclencheurs, vues, etc. Couche moteur de stockage : la couche moteur de stockage comprend les moteurs de stockage MySQL courants, notamment MyISAM, InnoDB et Memory. Le plus couramment utilisé est InnoDB, qui est également le moteur de stockage par défaut de MySQL.
Introduction aux composants de la couche serveur
Connecteur : Une connexion client MySQL est requise, et un connecteur est nécessaire pour connecter l'utilisateur et la base de données MySQL, "mysql -u username -p password" pour Connexion MySQL, après avoir terminé la négociation TCP, le connecteur authentifie la connexion en fonction du nom d'utilisateur et du mot de passe saisis.
Cache de requêtes : Après avoir reçu une demande d'exécution, MySQL recherchera d'abord dans le cache de requêtes pour voir si cette instruction SQL a déjà été exécutée. Les instructions et résultats précédemment exécutés seront stockés sous forme de clé-valeur. paires en mémoire. La clé est l'instruction de requête et la valeur est le résultat de la requête. Si cette instruction SQL peut être trouvée via la clé, le résultat de l'exécution SQL sera renvoyé directement. S'il n'existe pas dans le cache, la phase d'exécution suivante se poursuivra. Une fois l'exécution terminée, les résultats de l'exécution seront placés dans le cache des requêtes. L'avantage est une efficacité élevée. Cependant, l'utilisation du cache de requêtes n'est pas recommandée, car si une certaine table est mise à jour dans MySQL, tous les caches de requêtes deviendront invalides. Pour les bases de données fréquemment mises à jour, le taux de réussite du cache de requêtes est très faible. Remarque : dans MySQL version 8.0, la fonction de cache de requêtes a été supprimée et il n'y a pas de fonction de cache de requêtes
-
Analyseur : Elle est divisée en analyse lexicale et analyse syntaxique
- Analyse lexicale : Premièrement, MySQL Il sera analysé en fonction de l'instruction SQL. L'analyseur effectuera d'abord une analyse lexicale. Le SQL que vous écrivez est une instruction SQL composée de plusieurs chaînes et espaces. MySQL doit identifier quelles sont les chaînes qu'elle contient et ce qu'elles représentent.
- Analyse grammaticale : Effectuez ensuite une analyse grammaticale sur la base des résultats de l'analyse lexicale, l'analyseur de syntaxe déterminera si l'instruction SQL saisie satisfait à la syntaxe MySQL en fonction des règles grammaticales. Si l'instruction SQL est incorrecte, elle affichera : Vous avez une erreur dans votre suntax SQL
Optimiseur : Après analyse par l'analyseur, le SQL est légal, mais avant exécution, l'optimiseur doit être run Pour le traitement, l'optimiseur déterminera quel index utiliser et quelle connexion utiliser. Le rôle de l'optimiseur est de déterminer le plan d'exécution le plus efficace.
- Exécuteur :
Dans la phase d'exécution, MySQL déterminera d'abord s'il y a une autorisation pour exécuter l'instruction. S'il n'y a pas d'autorisation, il renverra une erreur d'absence d'autorisation, s'il y a une autorisation, il ouvrira la table ; et poursuivre l'exécution. Lorsqu'une table est ouverte, l'exécuteur utilisera l'interface fournie par le moteur cible selon la définition du moteur. Pour les tables avec index, la logique d'exécution est similaire.
Après avoir compris le processus d'exécution de l'instruction SQL, analysons en détail comment ce qui précède
update T set c=c+1 where ID=2;Analyse de l'instruction de mise à jour
update T set c=c+1 where ID=2;Lors de l'exécution de l'opération
update, le cache de requêtes lié à cette table deviendra invalide, cette instruction effacera donc tous les résultats mis en cache sur la table T. Ensuite, l'analyseur effectuera une analyse syntaxique et une analyse lexicale. Après avoir su qu'il s'agit d'une instruction de mise à jour, l'optimiseur décide quel index utiliser, puis l'exécuteur est responsable de l'exécution spécifique. Il trouve d'abord la ligne puis la met à jour. .
Selon notre pensée habituelle, trouver cet enregistrement, modifier sa valeur et le sauvegarder. Mais entrons dans les détails. Puisqu'il s'agit de modifier des données, cela implique des journaux. L'opération de mise à jour implique deux modules de journalisation importants. redo log (redo log), bin log (archive log). Ces deux journaux dans MySQL sont également indispensables. redo log(重做日志),bin log(归档日志)。MySQL中的这两个日志也是必学的。
redo log(重做日志)
- 在 MySQL 里,如果每一次的更新操作都需要写进磁盘,然后磁盘也要找到对应的那条记录,然后再更新,整个过程 IO 成本、查找成本都很高。
MySQL里使用WAL(预写式日志)技术,WAL 的全称是Write-Ahead Logging,它的关键点就是 先写日志,再写磁盘。 - 具体来说,当有一条记录需要更新的时候,InnoDB 引擎就会先把记录写到 redo log里面,并更新内存,这个时候更新就算完成了。同时,InnoDB 引擎会在适当的时候,将这个操作记录更新到磁盘里面,而这个更新往往是在系统比较空闲的时候做。
- InnoDB 的 redo log 是固定大小的,比如可以配置为一组 4 个文件,每个文件的大小是 1GB,那么总共就可以记录 4GB 的操作。从头开始写,写到末尾就又回到开头循环写。
听完上面对redo log日志的介绍后,小伙伴们可能会问:redo log日志存储在哪?, 数据库信息保存在磁盘上,redo log日志也保存在磁盘上,为什么要先写到redo log中再写到数据库中呢?,redo log日志如果存满数据了怎么办?
redo log (redo log)- Dans MySQL, si chaque opération de mise à jour doit être écrite sur le disque, alors le disque doit également trouver l'enregistrement correspondant, puis le mettre à jour dans son intégralité. Le coût des E/S du processus et le coût de recherche sont tous deux très élevés.
MySQL utilise la technologie WAL (write-ahead logging). Le nom complet de WAL est Write-Ahead Logging Son point clé est Écrivez d'abord le journal. puis Écrire sur le disque
.Après avoir écouté l'introduction ci-dessus du journal de rétablissement, vos amis peuvent demander : Où est stocké le journal de rétablissement ? , Les informations de la base de données sont enregistrées sur le disque, et le journal redo est également enregistré sur le disque. Pourquoi doivent-ils être écrits d'abord dans le journal redo, puis dans la base de données ? , Que dois-je faire si le journal redo est plein de données ? Attendez. Répondons ensuite à ces questions.
Où est stocké le journal redo ? Le moteur InnoDB écrit d'abord les enregistrements dans le journal de rétablissement. Là où se trouve le journal de rétablissement, il se trouve également sur le disque. Il s'agit également d'un processus d'écriture sur le disque, mais ce qui est différent du processus de mise à jour est que le processus d'écriture sur le disque est différent. Le processus de mise à jour est une E/S aléatoire sur le disque, qui prend du temps. L'écriture du journal redo est une E/S séquentielle sur le disque. Soyez efficace. 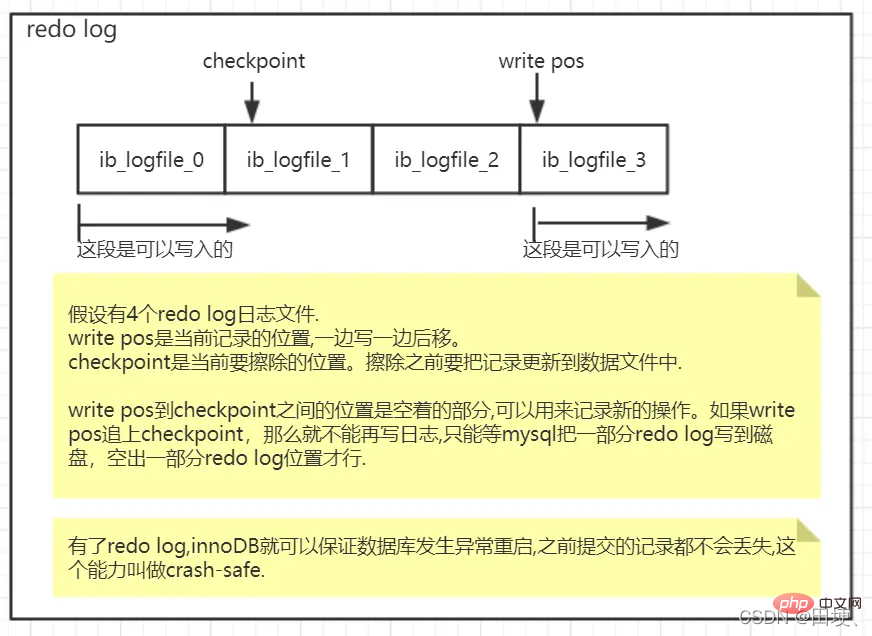
Tout d’abord, ne vous inquiétez pas du manque d’espace dans le journal de rétablissement, car il est recyclé. Par exemple, le journal redo log est configuré comme un ensemble de 4 fichiers, chaque fichier fait 1 Go. Le processus d'écriture est le suivant :
Un bref résumé : redo log est un mécanisme unique du moteur de stockage Innodb, qui peut être utilisé pour gérer la récupération anormale
,Crash-safe, refaire peut garantir que MySQL redémarre anormalement. Lorsque les transactions non validées sont annulées et que les transactions soumises sont déposées en toute sécurité dans la base de données.
anti-crash :Avec le redo log, InnoDB peut garantir que même si la base de données redémarre anormalement, les enregistrements précédemment soumis ne seront pas perdus. Cette capacité est appelée crash-safe. 🎜binlog (archive log)🎜🎜🎜redo log est un journal unique au moteur innoDB. Binlog est le journal de la couche serveur MySQL. 🎜🎜🎜En fait, le journal bin est apparu plus tôt que le journal redo, car au début MySQL n'avait pas de moteur de stockage InnoDB, et avant la 5.5 c'était MyISAM. Cependant, MyISAM ne dispose pas de fonctionnalités de sécurité contre les pannes et les journaux binlog ne peuvent être utilisés qu'à des fins d'archivage. InnoDB a été introduit dans MySQL sous la forme d'un plug-in par une autre société. Étant donné que le fait de s'appuyer uniquement sur binlog n'a pas de capacités de sécurité contre les crashs, InnoDB utilise un autre système de journalisation, à savoir le redo log, pour obtenir des capacités de sécurité contre les crashs. 🎜
redo log和bin log的总结
- redo log是为了保证innoDB引擎的crash-safe能力,也就是说在mysql异常宕机重启的时候,之前提交的事务可以保证不丢失;(因为成功提交的事务肯定是写入了redo log,可以从redo log恢复)
- bin log是归档日志,将每个更新操作都追加到日志中。这样当需要将日志恢复到某个时间点的时候,就可以根据全量备份+bin log重放实现。 如果没有开启binlog,那么数据只能恢复到全量备份的时间点,而不能恢复到任意时间点。如果连全量备份也没做,mysql宕机,磁盘也坏了,那就很尴尬了。。
redo log和bin log的区别:
- redo log 是 InnoDB 引擎特有的;bin log 是 MySQL 的 Server 层实现的,所有引擎都可以使用。
- redo log 是物理日志,记录的是“在某个数据页上做了什么修改”;bin log 是逻辑日志,记录的是这个语句的原始逻辑,比如“给 ID=2 这一行的 c 字段加 1 ”。
- redo log 是循环写的,空间固定会用完;binlog 是可以追加写入的。“追加写”是指 binlog 文件写到一定大小后会切换到下一个,并不会覆盖以前的日志。
InnoDB引擎部分在执行这个简单的update语句的时候的内部流程
update T set c=c+1 where ID=2;
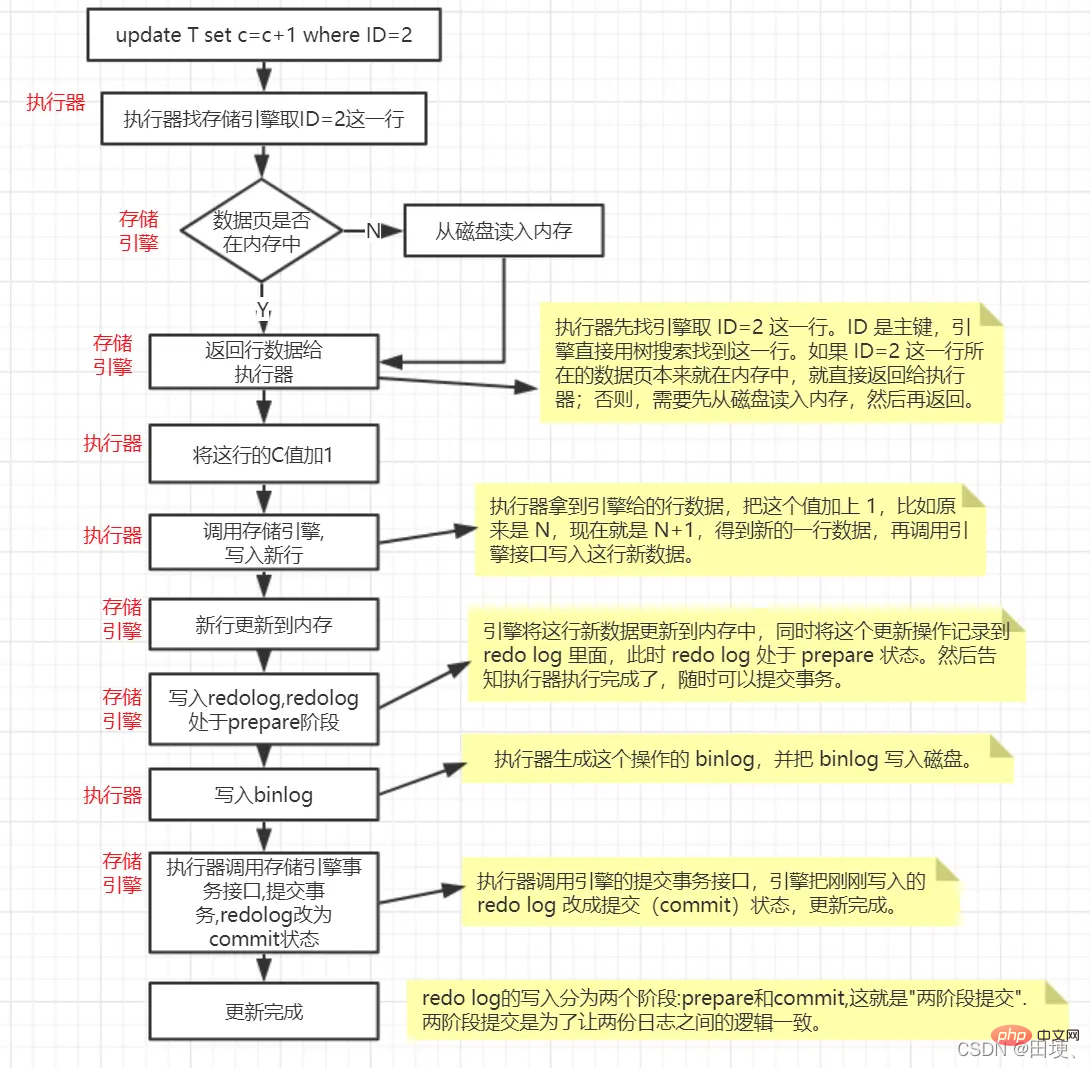
手动用begin开启事务,然后执行update语句,再然后执行commit语句,那上面的update更新流程之前 哪些是update语句执行之后做的,哪些是commit语句执行之后做的?
事实上,redo log在内存中有一个
redo log buffer,binlog 也有一个binlog cache.所以在手动开启的事务中,你执行sql语句,其实是写到redo log buffer和binlog cache中去的(肯定不可能是直接写磁盘日志,一个是性能差一个是回滚的时候不可能去回滚磁盘日志吧),然后当你执行commit的时候,首先要将redo log的提交状态游prepare改为commit状态,然后就要把binlog cache刷新到binlog日志(可能也只是flush到操作系统的page cache,这个就看你的mysql配置),redo log buffer刷新到redo log 日志(刷新时机也是可以配置的)。 如果你回滚的话,就只用把binlog cache和redo log buffer中的数据清除就行了。
在update过程中,mysql突然宕机,会发生什么情况?
如果redolog写入了,处于prepare状态,binlog还没写入,那么宕机重启后,redolog中的这个事务就直接回滚了。
如果redolog写入了,binlog也写入了,但redolog还没有更新为commit状态,那么宕机重启以后,mysql会去检查对应事务在binlog中是否完整。如果是,就提交事务;如果不是,就回滚事务。 (redolog处于prepare状态,binlog完整启动时就提交事务,为啥要这么设计? 主要是因为binlog写入了,那么就会被从库或者用这个binlog恢复出来的库使用,为了数据一致性就采用了这个策略)
redo log和binlog是通过xid这个字段关联起来的。
推荐学习:mysql教程
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Quelle est l'utilisation de ou dans l'instruction mysql select ?
- Résumé super détaillé des compétences pratiques d'optimisation MySQL
- Maîtriser complètement les opérations multi-tables MySQL
- Comment convertir des lignes en colonnes dans MySQL
- Quelle est la méthode d'implémentation de la séparation en lecture et en écriture MySQL ?