
Maison >Java >javaDidacticiel >Résumer les points de connaissance de la concurrence Java
Résumer les points de connaissance de la concurrence Java

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2022-03-25 19:16:263403parcourir
Cet article vous apporte des connaissances pertinentes sur java. Il présente principalement les problèmes liés à la concurrence Java et résume quelques problèmes. Jetons un coup d'œil et voyons à quel point cela sera utile à tout le monde.

Apprentissage recommandé : "Tutoriel Java"
1. Quelle est la différence entre le parallélisme et la concurrence ?
Du point de vue du système d'exploitation, un thread est la plus petite unité d'allocation de CPU.
- Parallèle signifie que les deux threads s'exécutent en même temps. Cela nécessite deux processeurs pour exécuter respectivement deux threads.
- La concurrence signifie qu'il n'y a qu'une seule exécution en même temps, mais sur une période donnée, les deux threads sont exécutés. La mise en œuvre de la concurrence repose sur les threads de commutation du processeur. Le temps de commutation étant très court, il est fondamentalement imperceptible pour l'utilisateur.
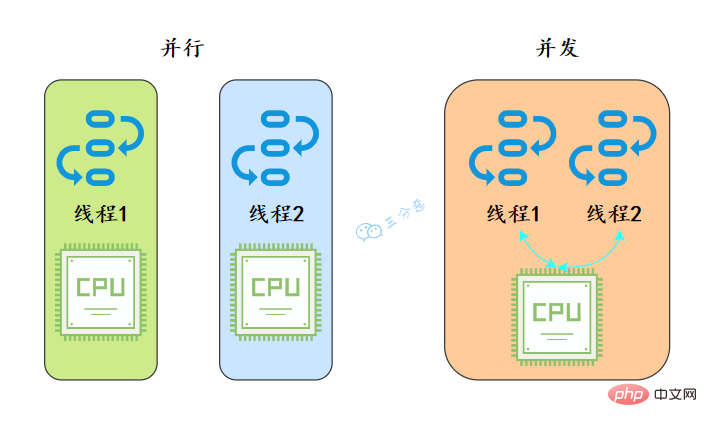
C'est comme quand on va à la cantine pour chercher à manger, le parallélisme veut dire qu'on fait la queue devant plusieurs fenêtres et que plusieurs tantes servent à manger en même temps, la simultanéité veut dire qu'on est entassés dans une seule fenêtre, et la tante donne une cuillerée à cette personne et la donne précipitamment à celle-là. Prends une cuillerée.

2. Que sont les processus et les threads ?
Pour parler de fils, il faut d'abord parler de processus.
- Processus : Un processus est une activité de code en cours d'exécution sur une collection de données. C'est l'unité de base de l'allocation et de la planification des ressources dans le système.
- Thread : Un thread est un chemin d'exécution d'un processus. Il y a au moins un thread dans un processus. Plusieurs threads dans le processus partagent les ressources du processus.
Le système d'exploitation alloue des ressources aux processus lors de l'allocation des ressources, mais la ressource CPU est assez particulière. Elle est allouée aux threads, car ce sont les threads qui occupent réellement le CPU pour l'exécution, on dit donc aussi que les threads sont les threads. base pour l’allocation du processeur.
Par exemple, en Java, lorsque nous démarrons la fonction principale, nous démarrons en fait un processus JVM, et le thread dans lequel se trouve la fonction principale est un thread de ce processus, également appelé thread principal.
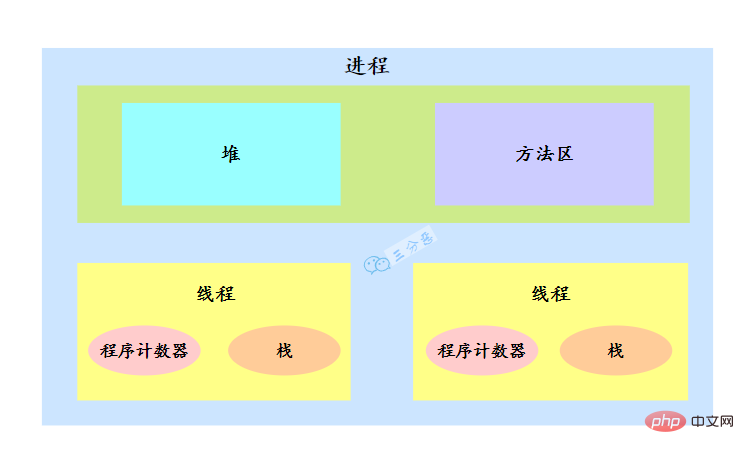
Il existe plusieurs threads dans un processus. Plusieurs threads partagent les ressources du tas et de la zone de méthode du processus, mais chaque thread a son propre compteur de programme et sa propre pile.
3. Combien y a-t-il de façons de créer un fil de discussion ?
Il existe trois manières principales de créer des threads en Java, à savoir l'héritage de la classe Thread, l'implémentation de l'interface Runnable et l'implémentation de l'interface Callable.
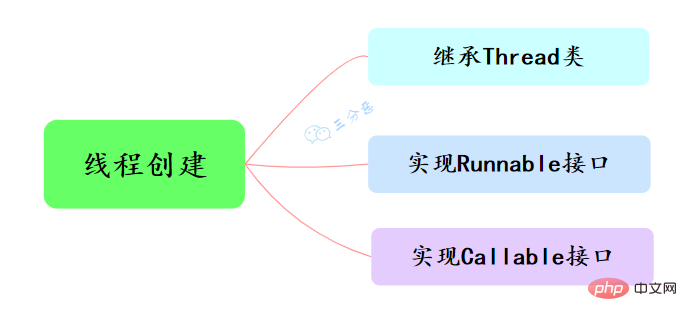
- Héritez la classe Thread, remplacez la méthode run(), appelez la méthode start() pour démarrer le thread
public class ThreadTest {
/**
* 继承Thread类
*/
public static class MyThread extends Thread {
@Override
public void run() {
System.out.println("This is child thread");
}
}
public static void main(String[] args) {
MyThread thread = new MyThread();
thread.start();
}}
- Implémentez l'interface Runnable, remplacez la méthode run()
public class RunnableTask implements Runnable {
public void run() {
System.out.println("Runnable!");
}
public static void main(String[] args) {
RunnableTask task = new RunnableTask();
new Thread(task).start();
}}
Les deux ce qui précède n'a aucun retour. Cela en vaut la peine, mais que devons-nous faire si nous avons besoin d'obtenir le résultat de l'exécution du thread ?
- Implémentez l'interface Callable et réécrivez la méthode call(). De cette façon, la valeur de retour de l'exécution de la tâche peut être obtenue via FutureTask
public class CallerTask implements Callable<string> {
public String call() throws Exception {
return "Hello,i am running!";
}
public static void main(String[] args) {
//创建异步任务
FutureTask<string> task=new FutureTask<string>(new CallerTask());
//启动线程
new Thread(task).start();
try {
//等待执行完成,并获取返回结果
String result=task.get();
System.out.println(result);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}}</string></string></string>
4 Pourquoi la méthode run() est-elle exécutée lorsque la méthode start(). est appelé ? Pourquoi pas directement ?
Lorsque la JVM exécute la méthode start, elle crée d'abord un thread, et le nouveau thread créé exécutera la méthode run du thread, ce qui permet d'obtenir l'effet multi-thread.
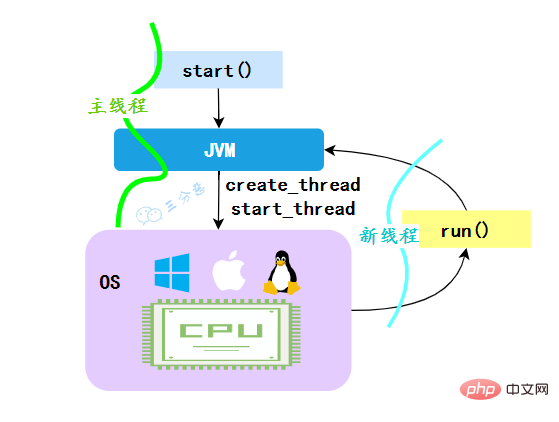
**Pourquoi ne pouvons-nous pas appeler directement la méthode run() ? **Il est également clair que si la méthode run() de Thread est appelée directement, la méthode run s'exécutera toujours dans le thread principal, ce qui équivaut à une exécution séquentielle, et n'obtiendra pas l'effet multi-thread.
5. Quelles sont les méthodes de planification couramment utilisées pour les threads ?
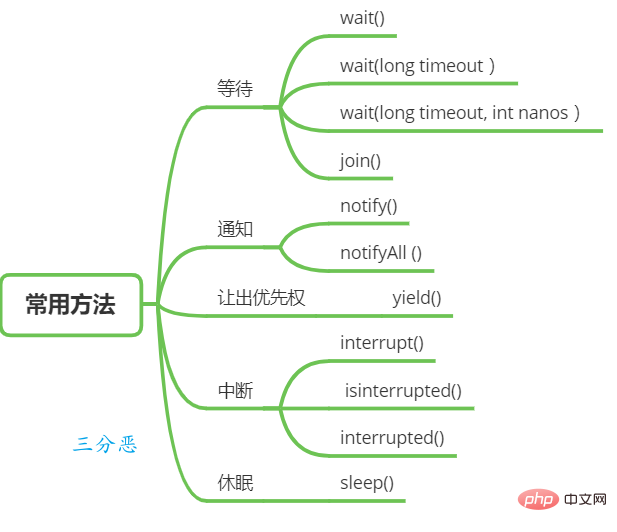
Thread en attente et notification
Certaines fonctions de la classe Object peuvent être utilisées pour l'attente de thread et la notification.
-
wait() : Lorsqu'un thread A appelle la méthode wait() d'une variable partagée, le thread A sera bloqué et suspendu, et ne reviendra que lorsque les situations suivantes se produisent :
(1) Thread A appelle la méthode notify() ou notifyAll() de l'objet partagé ;
(2) D'autres threads appellent la méthode interruption() du thread A, et le thread A renvoie une exception InterruptedException et renvoie.
wait(long timeout) : Cette méthode a un paramètre de délai d'attente de plus que la méthode wait(). La différence est que si le thread A appelle la méthode wait(long timeout) de l'objet partagé, il n'y a pas de If. le thread est réveillé par d'autres threads dans le délai d'attente spécifié en ms, cette méthode reviendra toujours en raison du délai d'attente.
wait(long timeout, int nanos), qui appelle en interne la fonction wait(long timeout).
Les méthodes ci-dessus sont des méthodes d'attente des threads, et il existe principalement deux méthodes pour réactiver les threads :
- notify() : Après qu'un thread A appelle la méthode notify() d'un objet partagé, il réveillera un thread qui a été suspendu après avoir appelé la série d'attente de méthodes sur la variable partagée. Il peut y avoir plusieurs threads en attente sur une variable partagée, et le thread en attente qui est réveillé est aléatoire.
- notifyAll() : Contrairement à l'appel de la fonction notify() sur une variable partagée, qui réveillera un thread bloqué sur la variable partagée, la méthode notifyAll() réveillera tous les threads bloqués sur la variable partagée en raison de l'appel de l'attente série de méthodes.
La classe Thread fournit également une méthode d'attente :
-
join() : Si un thread A exécute l'instruction thread.join(), la signification est : le thread actuel A attend que le thread se termine.
Revenu de thread.join().
Thread sleep
- sleep(long millis) : Méthode statique dans la classe Thread Lorsqu'un thread en cours d'exécution A appelle la méthode sleep de Thread, le thread A abandonnera temporairement les droits d'exécution pour la durée spécifiée. mais les ressources de surveillance appartenant au thread A, telles que les verrous, sont toujours conservées et ne seront pas libérées. Une fois le temps de veille spécifié écoulé, la fonction reviendra normalement, puis participera à la planification du processeur et continuera à s'exécuter après avoir obtenu les ressources du processeur.
Abandonner la priorité
- yield() : une méthode statique dans la classe Thread Lorsqu'un thread appelle la méthode rendement, il indique en fait au planificateur de thread que le thread actuel demande d'abandonner son CPU, mais le planificateur de threads Le processeur peut ignorer cet indice sans condition.
Interruption de thread
L'interruption de thread en Java est un mode de coopération entre les threads. En définissant l'indicateur d'interruption d'un thread, l'exécution du thread ne peut pas être directement terminée. Au lieu de cela, le thread interrompu le gère lui-même en fonction. l'état d'interruption.
- void interrompu() : interrompre un thread. Par exemple, lorsque le thread A est en cours d'exécution, le thread B peut appeler la méthode interruption() pour définir l'indicateur d'interruption du thread sur true et revenir immédiatement. Définir l'indicateur consiste simplement à définir l'indicateur. Le thread A n'est pas réellement interrompu et continuera à s'exécuter.
- Méthode boolean isInterrupted() : Détecte si le thread en cours est interrompu.
- Méthode booléenne interrompue() : Détecte si le thread actuel est interrompu. Contrairement à isInterrupted, cette méthode effacera l'indicateur d'interruption si elle constate que le thread actuel est interrompu.
6. Combien d’états un fil a-t-il ?
En Java, il existe six états de threads :
| État | Description |
|---|---|
| NEW | État initial : le thread est créé, mais la méthode start() n'a pas encore été appelée |
| RUNNABLE | État d'exécution : les threads Java font généralement référence aux deux états de prêt et d'exécution dans le système d'exploitation comme "en cours d'exécution" |
| BLOCKED | État de blocage : indique que le thread est bloqué dans le verrou |
| WAITING | État d'attente : indique que le thread entre dans l'état d'attente. Entrer dans cet état signifie que le thread actuel doit attendre que d'autres threads effectuent certaines actions spécifiques (notifications ou interruptions) |
| TIME_WAITING | Timeout d'attente. state : Cet état est différent de WAITIND, il peut être exécuté à une heure spécifiée |
| TERMINATED | Statut de fin renvoyé par lui-même : Indique que le thread actuel a terminé son exécution |
Dans son propre cycle de vie, un thread n'est pas dans un état fixe, mais bascule entre différents états au fur et à mesure que le code est exécuté. L'état du thread Java change comme le montre la figure :
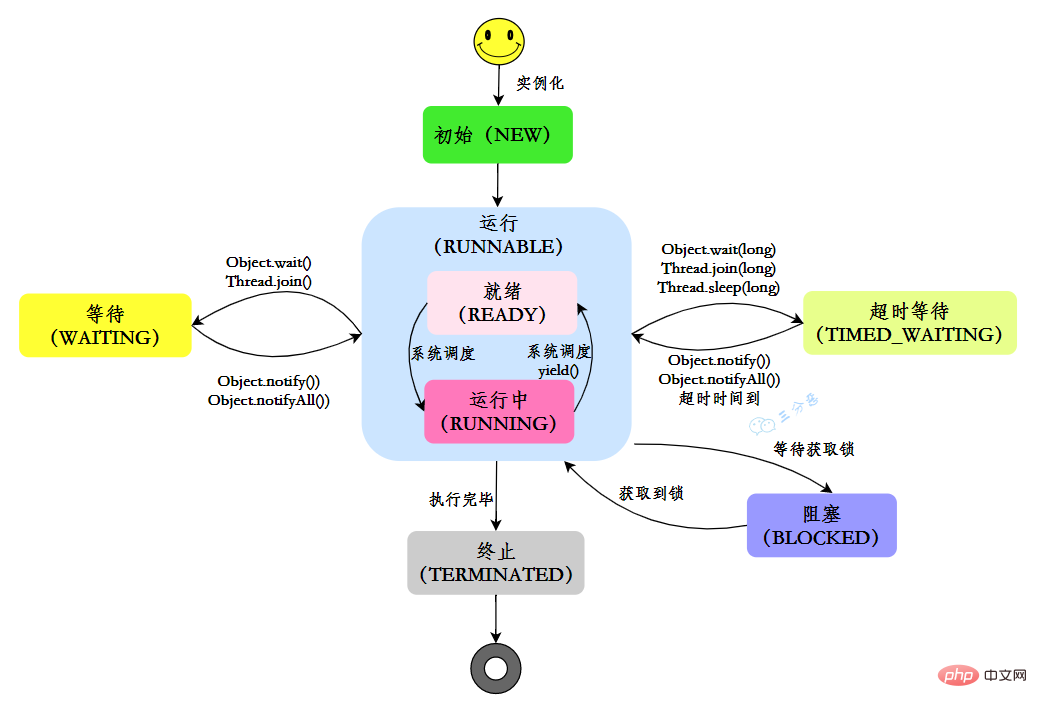
7. changer ?
Le but de l'utilisation du multithreading est d'utiliser pleinement le processeur, mais nous savons que la concurrence est en fait un processeur capable de gérer plusieurs threads.
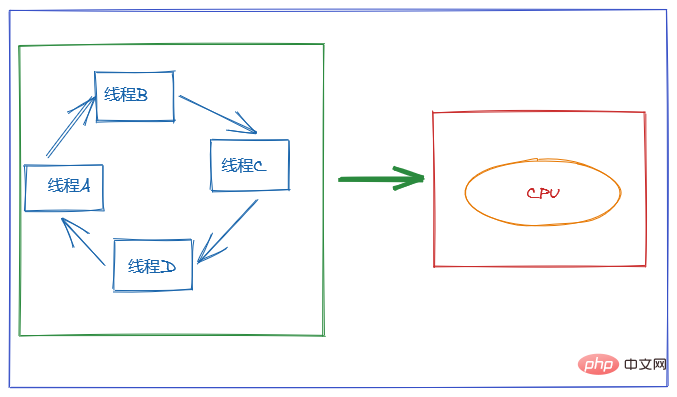
Afin de donner aux utilisateurs l'impression que plusieurs threads s'exécutent en même temps, l'allocation des ressources CPU adopte une rotation des tranches de temps, c'est-à-dire que chaque thread se voit attribuer une tranche de temps et que le thread occupe le CPU pour effectuer des tâches dans la tranche horaire. Lorsqu'un thread utilise sa tranche de temps, il sera dans un état prêt et laissera les autres threads prendre le CPU. Il s'agit d'un changement de contexte.
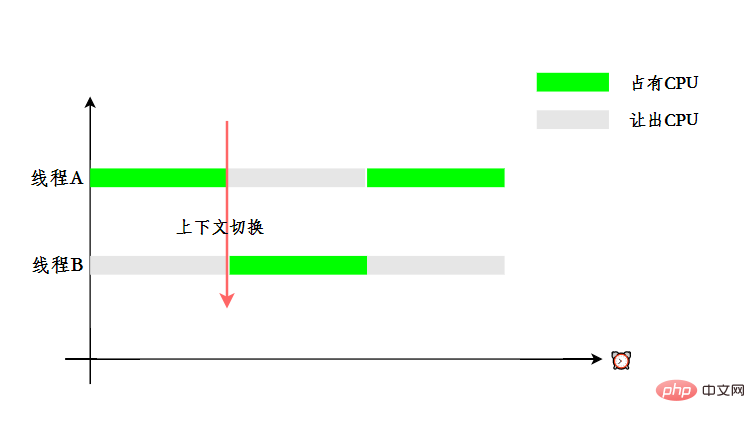
8. Comprenez-vous le fil du démon ?
Les threads en Java sont divisés en deux catégories, à savoir le thread démon (thread démon) et le thread utilisateur (thread utilisateur).
La fonction principale sera appelée au démarrage de la JVM. Le processus où se trouve la fonction principale est un thread utilisateur. En fait, de nombreux threads démons sont également démarrés à l'intérieur de la JVM, tels que les threads de garbage collection.
Alors, quelle est la différence entre le thread démon et le thread utilisateur ? L'une des différences est que lorsque le dernier thread non-démon se déforme, la JVM se fermera normalement, qu'il existe ou non un thread démon, ce qui signifie que la fin du thread démon n'affecte pas la sortie de la JVM. En d'autres termes, tant qu'un thread utilisateur n'est pas terminé, la JVM ne se fermera pas dans des circonstances normales.
9. Quelles sont les méthodes de communication entre les threads ?
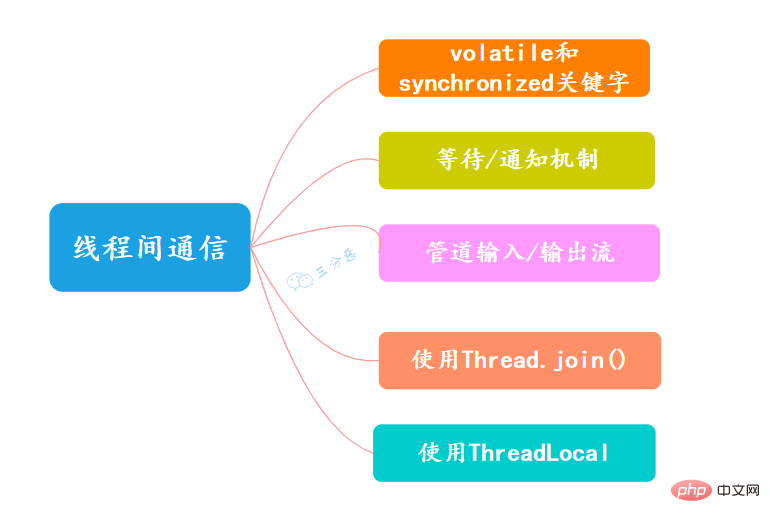
- Mots-clés volatiles et synchronisés
Le mot-clé volatile peut être utilisé pour modifier des champs (variables membres), ce qui indique au programme que tout accès à la variable doit être obtenu à partir de la mémoire partagée, et son Les modifications doivent être renvoyées dans la mémoire partagée de manière synchrone, ce qui garantit la visibilité de l'accès aux variables par tous les threads.
Le mot-clé synchronisé peut être utilisé pour modifier une méthode ou être utilisé sous la forme d'un bloc synchronisé. Il garantit principalement que plusieurs threads ne peuvent avoir qu'un seul thread dans une méthode ou un bloc synchronisé en même temps. visible lors de l’accès aux variables sexe et exclusivité.
- Mécanisme d'attente/notification
Vous pouvez utiliser le mécanisme d'attente/notification intégré de Java (wait()/notify()) pour réaliser qu'un thread modifie la valeur d'un objet et qu'un autre thread détecte le changement puis répond en conséquence à l'opération.
- Flux d'entrée/sortie de tuyau
La différence entre le flux d'entrée/sortie de tuyau et le flux d'entrée/sortie de fichier ordinaire ou le flux d'entrée/sortie réseau est qu'il est principalement utilisé pour la transmission de données entre les threads. .
Les flux d'entrée/sortie Pipe incluent principalement les quatre implémentations spécifiques suivantes : PipedOutputStream, PipedInputStream, PipedReader et PipedWriter. Les deux premiers sont orientés octets et les deux derniers sont orientés caractères.
- Utilisez Thread.join()
Si un thread A exécute l'instruction thread.join(), la signification est la suivante : le thread actuel A attend que le thread se termine avant de revenir de thread.join() . . En plus de la méthode join(), thread Thread fournit également deux méthodes avec des caractéristiques de délai d'attente : join(long millis) et join(long millis, int nanos).
- Utiliser ThreadLocal
ThreadLocal, ou variable de thread, est une structure de stockage avec un objet ThreadLocal comme clé et n'importe quel objet comme valeur. Cette structure est attachée au thread, ce qui signifie qu'un thread peut interroger une valeur liée à ce thread en fonction d'un objet ThreadLocal.
Vous pouvez définir une valeur via la méthode set(T), puis obtenir la valeur initialement définie via la méthode get() dans le thread actuel.
Concernant le multithreading, il y a une forte probabilité qu'il y ait également des questions de test écrit, telles que l'impression alternative, les virements bancaires, les modèles de production et de consommation, etc. Plus tard, Laosan publiera un numéro séparé pour passer en revue les multithreadings courants. -questions de test écrites filetées.
ThreadLocal
ThreadLocal n'a en fait pas beaucoup de scénarios d'application, mais c'est un vétéran d'entretien qui a été bombardé des milliers de fois. Il implique le multi-threading, les structures de données et la JVM. Il y a beaucoup de questions à poser, donc vous. doit gagner.
10.Qu'est-ce que ThreadLocal ?
ThreadLocal, qui est une variable locale de thread. Si vous créez une variable ThreadLocal, chaque thread qui accède à cette variable aura une copie locale de cette variable. Lorsque plusieurs threads exploitent cette variable, ils exploitent en fait les variables dans leur propre mémoire locale, réalisant ainsi la fonction d'isolation des threads pour éviter les threads. problèmes de sécurité.
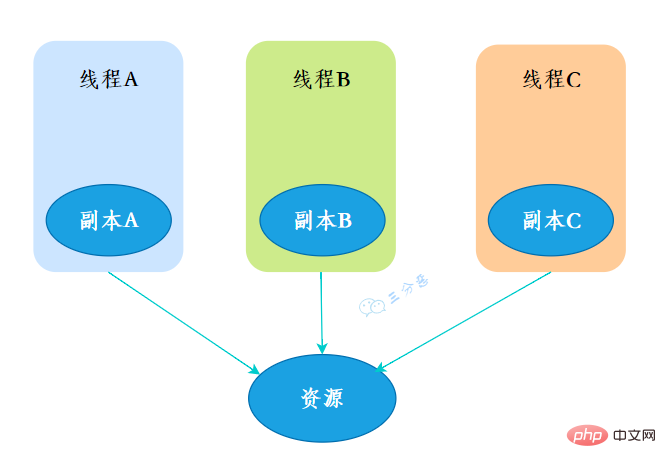
- 创建
创建了一个ThreadLoca变量localVariable,任何一个线程都能并发访问localVariable。
//创建一个ThreadLocal变量public static ThreadLocal<string> localVariable = new ThreadLocal();</string>
- 写入
线程可以在任何地方使用localVariable,写入变量。
localVariable.set("鄙人三某”);
- 读取
线程在任何地方读取的都是它写入的变量。
localVariable.get();
11.你在工作中用到过ThreadLocal吗?
有用到过的,用来做用户信息上下文的存储。
我们的系统应用是一个典型的MVC架构,登录后的用户每次访问接口,都会在请求头中携带一个token,在控制层可以根据这个token,解析出用户的基本信息。那么问题来了,假如在服务层和持久层都要用到用户信息,比如rpc调用、更新用户获取等等,那应该怎么办呢?
一种办法是显式定义用户相关的参数,比如账号、用户名……这样一来,我们可能需要大面积地修改代码,多少有点瓜皮,那该怎么办呢?
这时候我们就可以用到ThreadLocal,在控制层拦截请求把用户信息存入ThreadLocal,这样我们在任何一个地方,都可以取出ThreadLocal中存的用户数据。
很多其它场景的cookie、session等等数据隔离也都可以通过ThreadLocal去实现。
我们常用的数据库连接池也用到了ThreadLocal:
- 数据库连接池的连接交给ThreadLoca进行管理,保证当前线程的操作都是同一个Connnection。
12.ThreadLocal怎么实现的呢?
我们看一下ThreadLocal的set(T)方法,发现先获取到当前线程,再获取ThreadLocalMap,然后把元素存到这个map中。
public void set(T value) {
//获取当前线程
Thread t = Thread.currentThread();
//获取ThreadLocalMap
ThreadLocalMap map = getMap(t);
//讲当前元素存入map
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
ThreadLocal实现的秘密都在这个ThreadLocalMap了,可以Thread类中定义了一个类型为ThreadLocal.ThreadLocalMap的成员变量threadLocals。
public class Thread implements Runnable {
//ThreadLocal.ThreadLocalMap是Thread的属性
ThreadLocal.ThreadLocalMap threadLocals = null;}
ThreadLocalMap既然被称为Map,那么毫无疑问它是
static class Entry extends WeakReference<threadlocal>> {
/** The value associated with this ThreadLocal. */
Object value;
//节点类
Entry(ThreadLocal> k, Object v) {
//key赋值
super(k);
//value赋值
value = v;
}
}</threadlocal>
这里的节点,key可以简单低视作ThreadLocal,value为代码中放入的值,当然实际上key并不是ThreadLocal本身,而是它的一个弱引用,可以看到Entry的key继承了 WeakReference(弱引用),再来看一下key怎么赋值的:
public WeakReference(T referent) {
super(referent);
}
key的赋值,使用的是WeakReference的赋值。
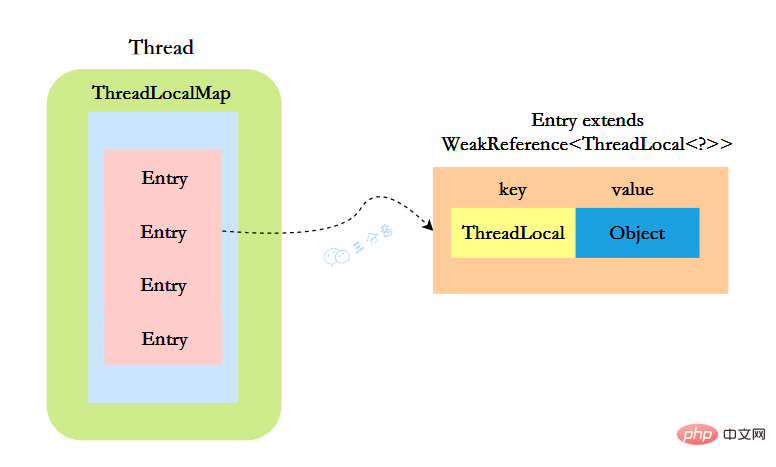
所以,怎么回答ThreadLocal原理?要答出这几个点:
- Thread类有一个类型为ThreadLocal.ThreadLocalMap的实例变量threadLocals,每个线程都有一个属于自己的ThreadLocalMap。
- ThreadLocalMap内部维护着Entry数组,每个Entry代表一个完整的对象,key是ThreadLocal的弱引用,value是ThreadLocal的泛型值。
- 每个线程在往ThreadLocal里设置值的时候,都是往自己的ThreadLocalMap里存,读也是以某个ThreadLocal作为引用,在自己的map里找对应的key,从而实现了线程隔离。
- ThreadLocal本身不存储值,它只是作为一个key来让线程往ThreadLocalMap里存取值。
13.ThreadLocal 内存泄露是怎么回事?
我们先来分析一下使用ThreadLocal时的内存,我们都知道,在JVM中,栈内存线程私有,存储了对象的引用,堆内存线程共享,存储了对象实例。
所以呢,栈中存储了ThreadLocal、Thread的引用,堆中存储了它们的具体实例。
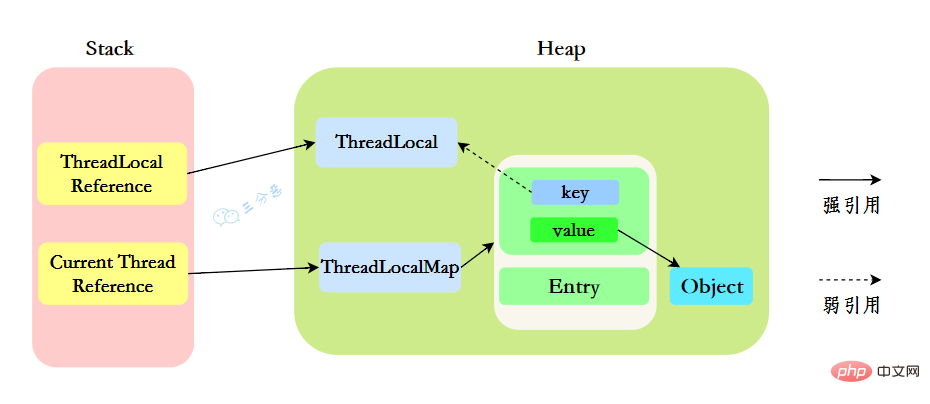
ThreadLocalMap中使用的 key 为 ThreadLocal 的弱引用。
“弱引用:只要垃圾回收机制一运行,不管JVM的内存空间是否充足,都会回收该对象占用的内存。”
那么现在问题就来了,弱引用很容易被回收,如果ThreadLocal(ThreadLocalMap的Key)被垃圾回收器回收了,但是ThreadLocalMap生命周期和Thread是一样的,它这时候如果不被回收,就会出现这种情况:ThreadLocalMap的key没了,value还在,这就会造成了内存泄漏问题。
那怎么解决内存泄漏问题呢?
很简单,使用完ThreadLocal后,及时调用remove()方法释放内存空间。
ThreadLocallocalVariable = new ThreadLocal();try { localVariable.set("鄙人三某”); ……} finally { localVariable.remove();}
那为什么key还要设计成弱引用?
key设计成弱引用同样是为了防止内存泄漏。
假如key被设计成强引用,如果ThreadLocal Reference被销毁,此时它指向ThreadLoca的强引用就没有了,但是此时key还强引用指向ThreadLoca,就会导致ThreadLocal不能被回收,这时候就发生了内存泄漏的问题。
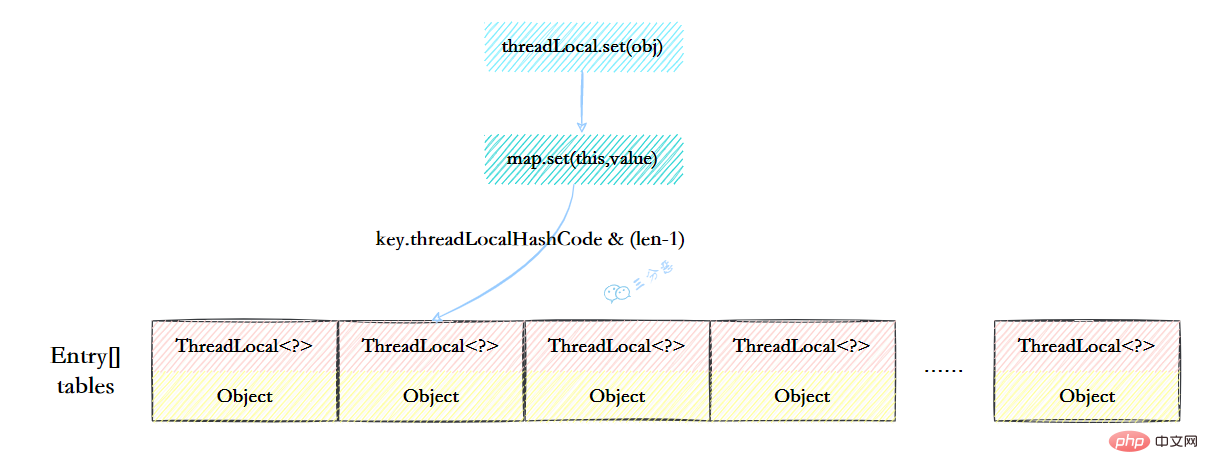
14.ThreadLocalMap的结构了解吗?
ThreadLocalMap虽然被叫做Map,其实它是没有实现Map接口的,但是结构还是和HashMap比较类似的,主要关注的是两个要素:元素数组和散列方法。
-
元素数组
一个table数组,存储Entry类型的元素,Entry是ThreaLocal弱引用作为key,Object作为value的结构。
private Entry[] table;
-
散列方法
散列方法就是怎么把对应的key映射到table数组的相应下标,ThreadLocalMap用的是哈希取余法,取出key的threadLocalHashCode,然后和table数组长度减一&运算(相当于取余)。
int i = key.threadLocalHashCode & (table.length - 1);
这里的threadLocalHashCode计算有点东西,每创建一个ThreadLocal对象,它就会新增0x61c88647,这个值很特殊,它是斐波那契数 也叫 黄金分割数。hash增量为 这个数字,带来的好处就是 hash 分布非常均匀。
private static final int HASH_INCREMENT = 0x61c88647;
private static int nextHashCode() {
return nextHashCode.getAndAdd(HASH_INCREMENT);
}
15.ThreadLocalMap怎么解决Hash冲突的?
我们可能都知道HashMap使用了链表来解决冲突,也就是所谓的链地址法。
ThreadLocalMap没有使用链表,自然也不是用链地址法来解决冲突了,它用的是另外一种方式——开放定址法。开放定址法是什么意思呢?简单来说,就是这个坑被人占了,那就接着去找空着的坑。
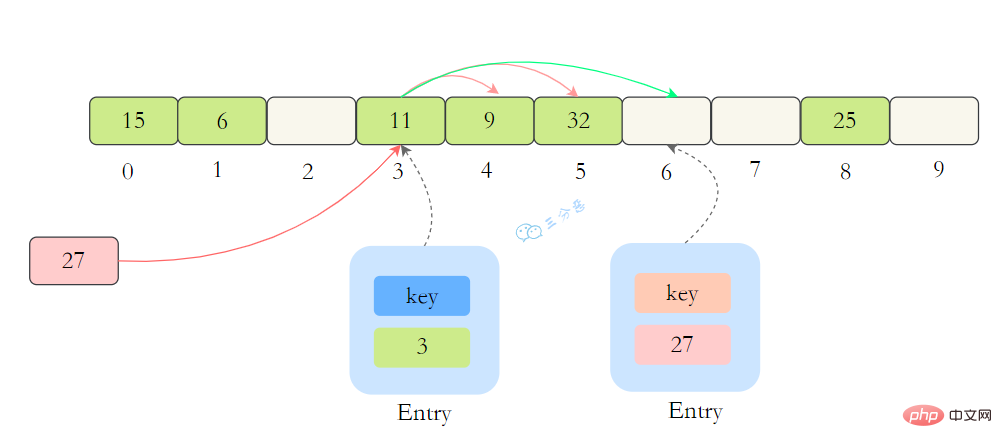
如上图所示,如果我们插入一个value=27的数据,通过 hash计算后应该落入第 4 个槽位中,而槽位 4 已经有了 Entry数据,而且Entry数据的key和当前不相等。此时就会线性向后查找,一直找到 Entry为 null的槽位才会停止查找,把元素放到空的槽中。
在get的时候,也会根据ThreadLocal对象的hash值,定位到table中的位置,然后判断该槽位Entry对象中的key是否和get的key一致,如果不一致,就判断下一个位置。
16.Résumer les points de connaissance de la concurrence Java机制了解吗?
在ThreadLocalMap.set()方法的最后,如果执行完启发式清理工作后,未清理到任何数据,且当前散列数组中Entry的数量已经达到了列表的扩容阈值(len*2/3),就开始执行rehash()逻辑:
if (!cleanSomeSlots(i, sz) && sz >= threshold) rehash();
再着看rehash()具体实现:这里会先去清理过期的Entry,然后还要根据条件判断size >= threshold - threshold / 4 也就是size >= threshold* 3/4来决定是否需要扩容。
private void rehash() {
//清理过期Entry
expungeStaleEntries();
//扩容
if (size >= threshold - threshold / 4)
resize();}//清理过期Entryprivate void expungeStaleEntries() {
Entry[] tab = table;
int len = tab.length;
for (int j = 0; j <p>接着看看具体的<code>resize()</code>方法,扩容后的<code>newTab</code>的大小为老数组的两倍,然后遍历老的table数组,散列方法重新计算位置,开放地址解决冲突,然后放到新的<code>newTab</code>,遍历完成之后,<code>oldTab</code>中所有的<code>entry</code>数据都已经放入到<code>newTab</code>中了,然后table引用指向<code>newTab</code></p><p><img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/000/000/067/6137d48077cbb320beee2007e8763d69-16.png" class="lazy" alt="Résumer les points de connaissance de la concurrence Java"></p><p>具体代码:</p><p><img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/000/000/067/85310a4f8d2bb86283cd76fb2542424d-17.png" class="lazy" alt="ThreadLocalMap resize"></p><h2>17.父子线程怎么共享数据?</h2><p>父线程能用ThreadLocal来给子线程传值吗?毫无疑问,不能。那该怎么办?</p><p>这时候可以用到另外一个类——<code>InheritableThreadLocal</code>。</p><p>使用起来很简单,在主线程的InheritableThreadLocal实例设置值,在子线程中就可以拿到了。</p><pre class="brush:php;toolbar:false">public class InheritableThreadLocalTest {
public static void main(String[] args) {
final ThreadLocal threadLocal = new InheritableThreadLocal();
// 主线程
threadLocal.set("不擅技术");
//子线程
Thread t = new Thread() {
@Override
public void run() {
super.run();
System.out.println("鄙人三某 ," + threadLocal.get());
}
};
t.start();
}}那原理是什么呢?
原理很简单,在Thread类里还有另外一个变量:
ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;
在Thread.init的时候,如果父线程的inheritableThreadLocals不为空,就把它赋给当前线程(子线程)的inheritableThreadLocals。
if (inheritThreadLocals && parent.inheritableThreadLocals != null) this.inheritableThreadLocals = ThreadLocal.createInheritedMap(parent.inheritableThreadLocals)
18.说一下你对Résumer les points de connaissance de la concurrence Java(JMM)的理解?
Résumer les points de connaissance de la concurrence Java(Java Memory Model,JMM),是一种抽象的模型,被定义出来屏蔽各种硬件和操作系统的内存访问差异。
JMM定义了线程和主内存之间的抽象关系:线程之间的共享变量存储在主内存(Main Memory)中,每个线程都有一个私有的本地内存(Local Memory),本地内存中存储了该线程以读/写共享变量的副本。
Résumer les points de connaissance de la concurrence Java的抽象图:
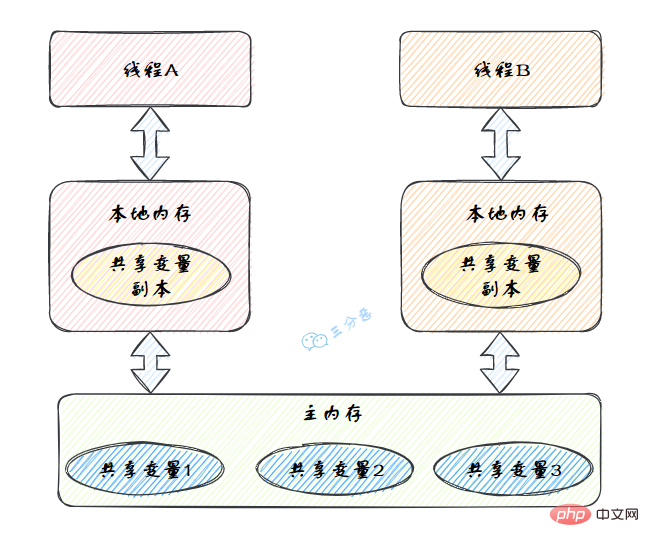
本地内存是JMM的 一个抽象概念,并不真实存在。它其实涵盖了缓存、写缓冲区、寄存器以及其他的硬件和编译器优化。
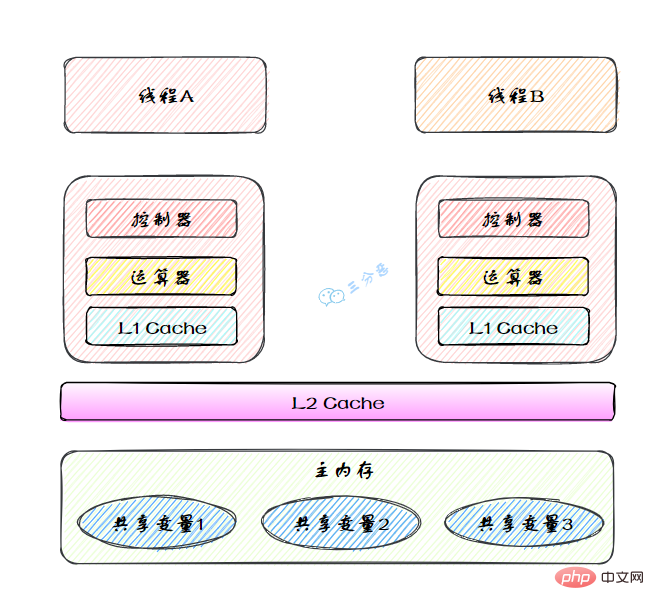
图里面的是一个双核 CPU 系统架构 ,每个核有自己的控制器和运算器,其中控制器包含一组寄存器和操作控制器,运算器执行算术逻辅运算。每个核都有自己的一级缓存,在有些架构里面还有一个所有 CPU 共享的二级缓存。 那么 Java 内存模型里面的工作内存,就对应这里的 Ll 缓存或者 L2 缓存或者 CPU 寄存器。
19.说说你对原子性、可见性、有序性的理解?
原子性、有序性、可见性是并发编程中非常重要的基础概念,JMM的很多技术都是围绕着这三大特性展开。
- 原子性:原子性指的是一个操作是不可分割、不可中断的,要么全部执行并且执行的过程不会被任何因素打断,要么就全不执行。
- 可见性:可见性指的是一个线程修改了某一个共享变量的值时,其它线程能够立即知道这个修改。
- 有序性:有序性指的是对于一个线程的执行代码,从前往后依次执行,单线程下可以认为程序是有序的,但是并发时有可能会发生指令重排。
分析下面几行代码的原子性?
int i = 2;int j = i;i++;i = i + 1;
- 第1句是基本类型赋值,是原子性操作。
- 第2句先读i的值,再赋值到j,两步操作,不能保证原子性。
- 第3和第4句其实是等效的,先读取i的值,再+1,最后赋值到i,三步操作了,不能保证原子性。
原子性、可见性、有序性都应该怎么保证呢?
- 原子性:JMM只能保证基本的原子性,如果要保证一个代码块的原子性,需要使用
synchronized。 - 可见性:Java是利用
volatile关键字来保证可见性的,除此之外,final和synchronized也能保证可见性。 - 有序性:
synchronized或者volatile都可以保证多线程之间操作的有序性。
20.那说说什么是指令重排?
在执行程序时,为了提高性能,编译器和处理器常常会对指令做重排序。重排序分3种类型。
- 编译器优化的重排序。编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序。
- 指令级并行的重排序。现代处理器采用了指令级并行技术(Instruction-Level Parallelism,ILP)来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应 机器指令的执行顺序。
- 内存系统的重排序。由于处理器使用缓存和读/写缓冲区,这使得加载和存储操作看上去可能是在乱序执行。
从Java源代码到最终实际执行的指令序列,会分别经历下面3种重排序,如图:

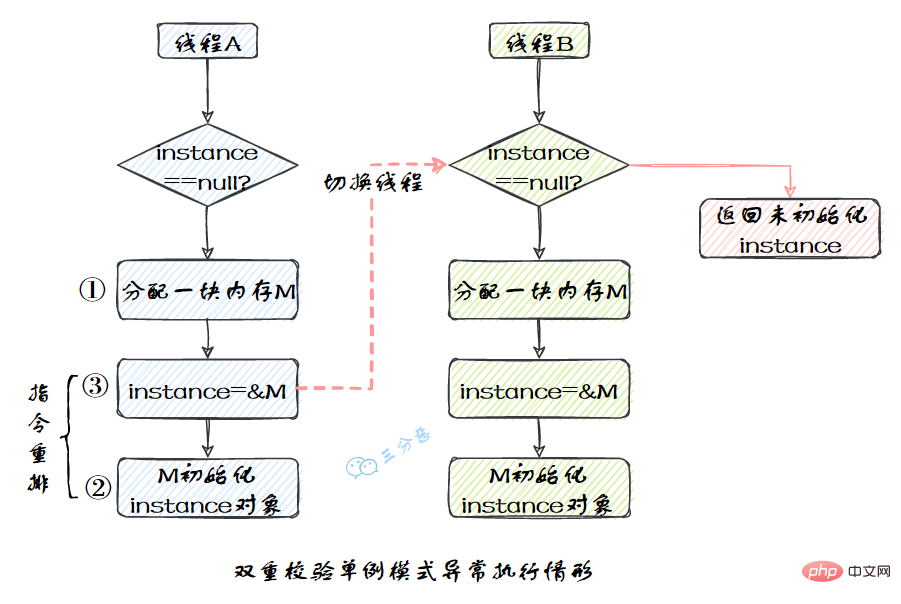
我们比较熟悉的双重校验单例模式就是一个经典的指令重排的例子,Singleton instance=new Singleton();对应的JVM指令分为三步:分配内存空间–>初始化对象—>对象指向分配的内存空间,但是经过了编译器的指令重排序,第二步和第三步就可能会重排序。
JMM属于语言级的内存模型,它确保在不同的编译器和不同的处理器平台之上,通过禁止特定类型的编译器重排序和处理器重排序,为程序员提供一致的内存可见性保证。
21.指令重排有限制吗?happens-before了解吗?
指令重排也是有一些限制的,有两个规则happens-before和as-if-serial来约束。
happens-before的定义:
- 如果一个操作happens-before另一个操作,那么第一个操作的执行结果将对第二个操作可见,而且第一个操作的执行顺序排在第二个操作之前。
- 两个操作之间存在happens-before关系,并不意味着Java平台的具体实现必须要按照 happens-before关系指定的顺序来执行。如果重排序之后的执行结果,与按happens-before关系来执行的结果一致,那么这种重排序并不非法
happens-before和我们息息相关的有六大规则:
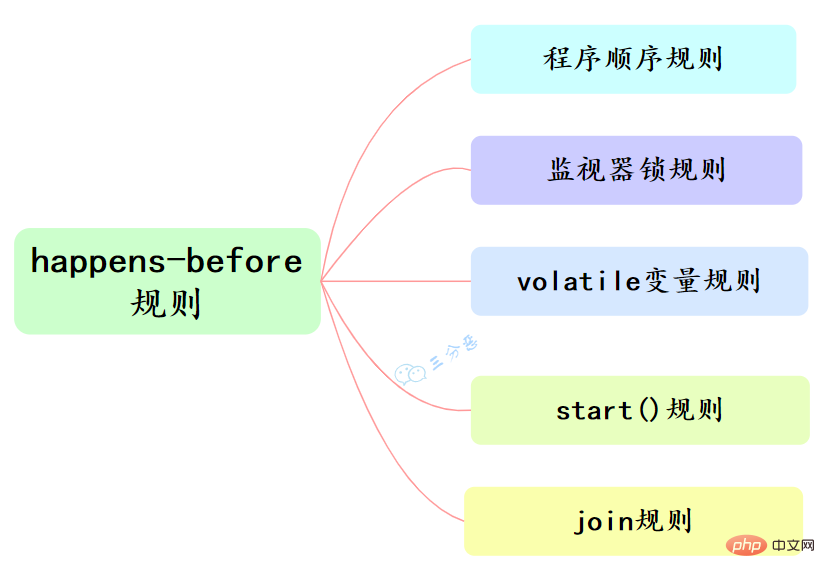
- 程序顺序规则:一个线程中的每个操作,happens-before于该线程中的任意后续操作。
- 监视器锁规则:对一个锁的解锁,happens-before于随后对这个锁的加锁。
- volatile变量规则:对一个volatile域的写,happens-before于任意后续对这个volatile域的读。
- 传递性:如果A happens-before B,且B happens-before C,那么A happens-before C。
- start()规则:如果线程A执行操作ThreadB.start()(启动线程B),那么A线程的 ThreadB.start()操作happens-before于线程B中的任意操作。
- join()规则:如果线程A执行操作ThreadB.join()并成功返回,那么线程B中的任意操作 happens-before于线程A从ThreadB.join()操作成功返回。
22.as-if-serial又是什么?单线程的程序一定是顺序的吗?
as-if-serial语义的意思是:不管怎么重排序(编译器和处理器为了提高并行度),单线程程序的执行结果不能被改变。编译器、runtime和处理器都必须遵守as-if-serial语义。
为了遵守as-if-serial语义,编译器和处理器不会对存在数据依赖关系的操作做重排序,因为这种重排序会改变执行结果。但是,如果操作之间不存在数据依赖关系,这些操作就可能被编译器和处理器重排序。为了具体说明,请看下面计算圆面积的代码示例。
double pi = 3.14; // Adouble r = 1.0; // B double area = pi * r * r; // C
上面3个操作的数据依赖关系:
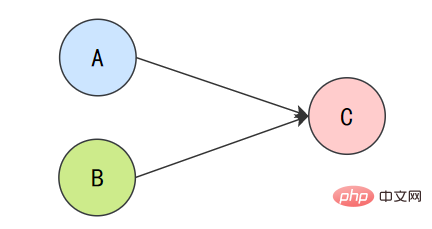
A和C之间存在数据依赖关系,同时B和C之间也存在数据依赖关系。因此在最终执行的指令序列中,C不能被重排序到A和B的前面(C排到A和B的前面,程序的结果将会被改变)。但A和B之间没有数据依赖关系,编译器和处理器可以重排序A和B之间的执行顺序。
所以最终,程序可能会有两种执行顺序:
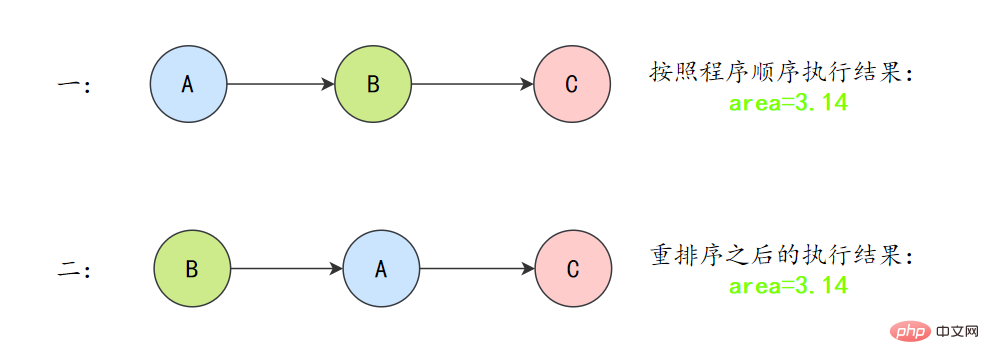
as-if-serial语义把单线程程序保护了起来,遵守as-if-serial语义的编译器、runtime和处理器共同编织了这么一个“楚门的世界”:单线程程序是按程序的“顺序”来执行的。as- if-serial语义使单线程情况下,我们不需要担心重排序的问题,可见性的问题。
23.volatile实现原理了解吗?
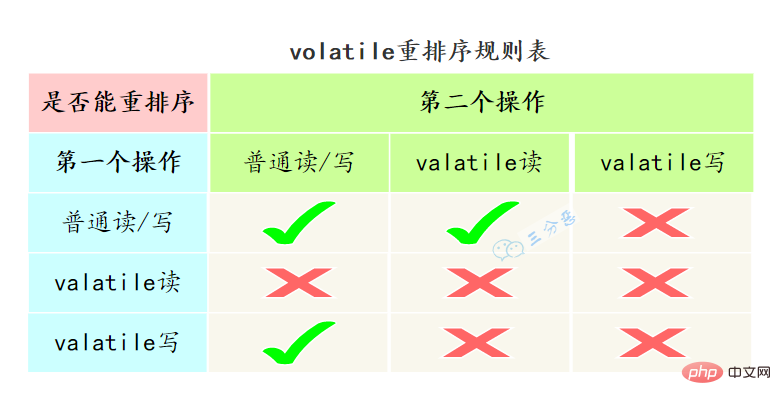
volatile有两个作用,保证可见性和有序性。
volatile怎么保证可见性的呢?
相比synchronized的加锁方式来解决共享变量的内存可见性问题,volatile就是更轻量的选择,它没有上下文切换的额外开销成本。
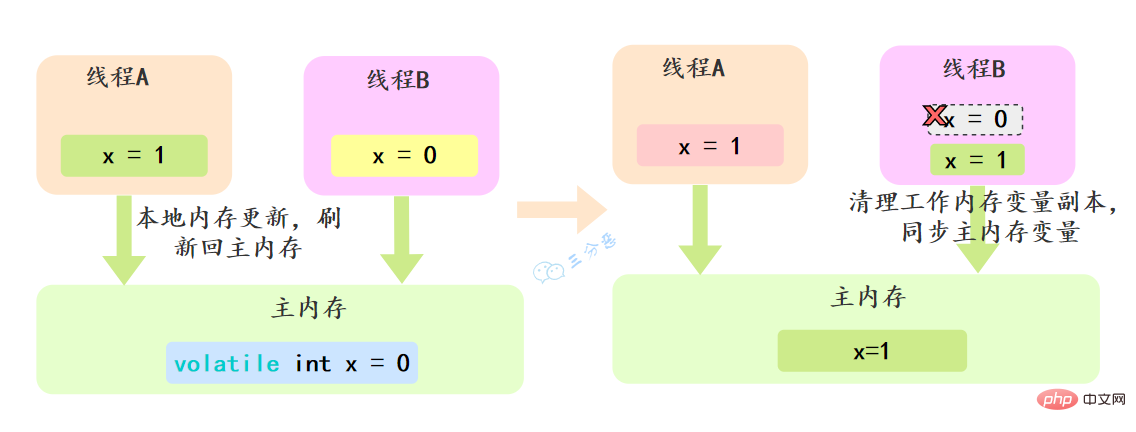
volatile可以确保对某个变量的更新对其他线程马上可见,一个变量被声明为volatile 时,线程在写入变量时不会把值缓存在寄存器或者其他地方,而是会把值刷新回主内存 当其它线程读取该共享变量 ,会从主内存重新获取最新值,而不是使用当前线程的本地内存中的值。
例如,我们声明一个 volatile 变量 volatile int x = 0,线程A修改x=1,修改完之后就会把新的值刷新回主内存,线程B读取x的时候,就会清空本地内存变量,然后再从主内存获取最新值。
volatile怎么保证有序性的呢?
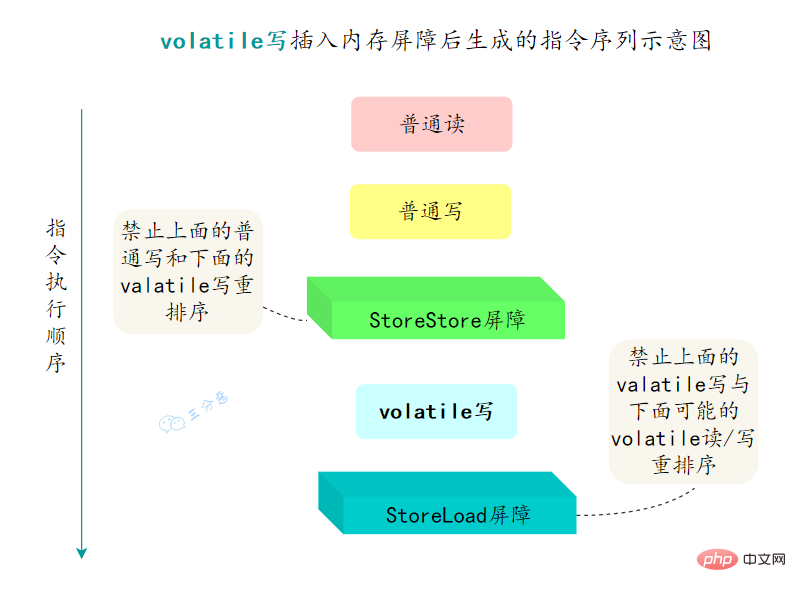
重排序可以分为编译器重排序和处理器重排序,valatile保证有序性,就是通过分别限制这两种类型的重排序。
为了实现volatile的内存语义,编译器在生成字节码时,会在指令序列中插入内存屏障来禁止特定类型的处理器重排序。
- 在每个volatile写操作的前面插入一个
StoreStore屏障 - 在每个volatile写操作的后面插入一个
StoreLoad屏障 - 在每个volatile读操作的后面插入一个
LoadLoad屏障 - 在每个volatile读操作的后面插入一个
LoadStore屏障
24.synchronized用过吗?怎么使用?
synchronized经常用的,用来保证代码的原子性。
synchronized主要有三种用法:
- 修饰实例方法: 作用于当前对象实例加锁,进入同步代码前要获得 当前对象实例的锁
synchronized void method() {
//业务代码}
-
修饰静态方法:也就是给当前类加锁,会作⽤于类的所有对象实例 ,进⼊同步代码前要获得当前 class 的锁。因为静态成员不属于任何⼀个实例对象,是类成员( static 表明这是该类的⼀个静态资源,不管 new 了多少个对象,只有⼀份)。
如果⼀个线程 A 调⽤⼀个实例对象的⾮静态 synchronized ⽅法,⽽线程 B 需要调⽤这个实例对象所属类的静态 synchronized ⽅法,是允许的,不会发⽣互斥现象,因为访问静态 synchronized ⽅法占⽤的锁是当前类的锁,⽽访问⾮静态 synchronized ⽅法占⽤的锁是当前实例对象锁。
synchronized void staic method() {
//业务代码}
- 修饰代码块 :指定加锁对象,对给定对象/类加锁。 synchronized(this|object) 表示进⼊同步代码库前要获得给定对象的锁。 synchronized(类.class) 表示进⼊同步代码前要获得 当前 class 的锁
synchronized(this) {
//业务代码}
25.synchronized的实现原理?
synchronized是怎么加锁的呢?
我们使用synchronized的时候,发现不用自己去lock和unlock,是因为JVM帮我们把这个事情做了。
-
synchronized修饰代码块时,JVM采用
monitorenter、monitorexit两个指令来实现同步,monitorenter指令指向同步代码块的开始位置,monitorexit指令则指向同步代码块的结束位置。反编译一段synchronized修饰代码块代码,
javap -c -s -v -l SynchronizedDemo.class,可以看到相应的字节码指令。
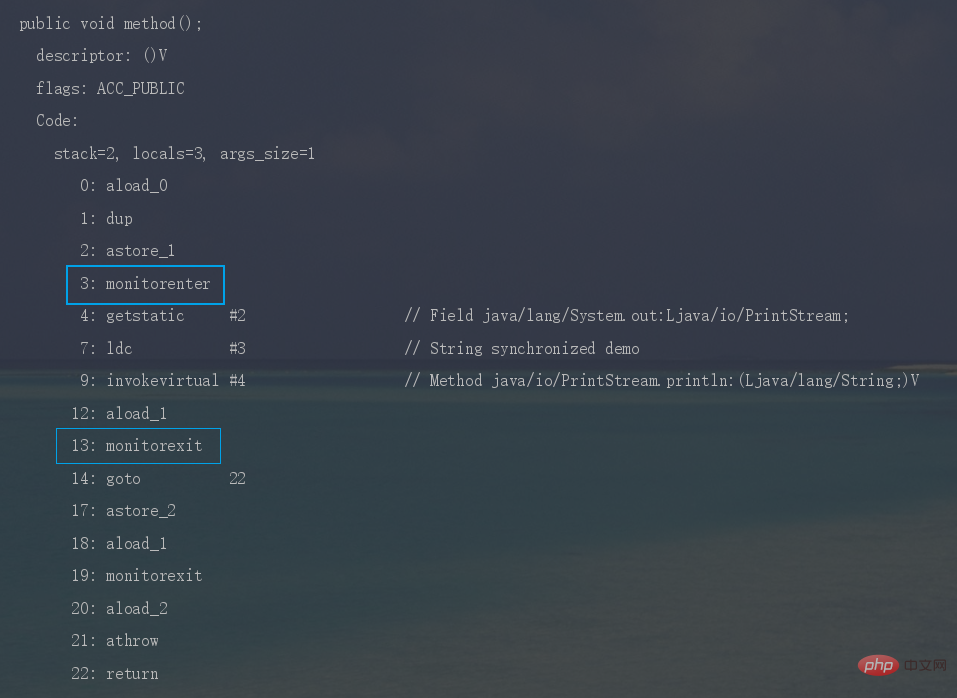
-
Résumer les points de connaissance de la concurrence Java时,JVM采用
ACC_SYNCHRONIZED标记符来实现同步,这个标识指明了该方法是一个同步方法。同样可以写段代码反编译看一下。
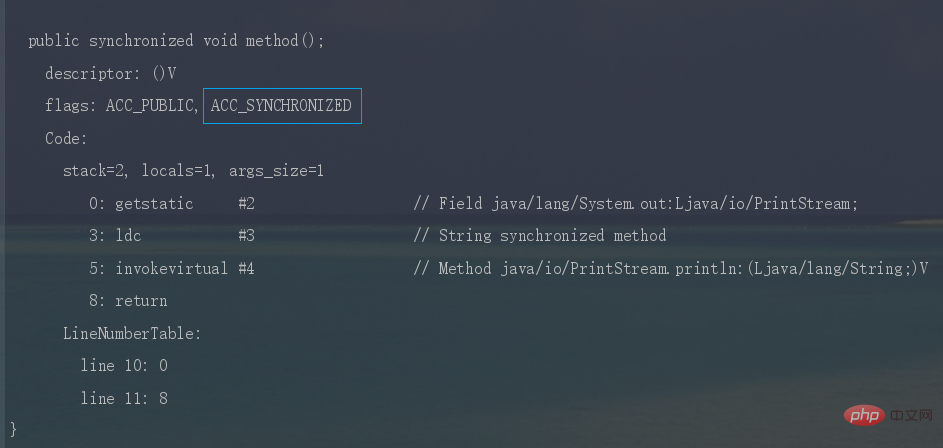
synchronized锁住的是什么呢?
monitorenter、monitorexit或者ACC_SYNCHRONIZED都是基于Monitor实现的。
实例对象结构里有对象头,对象头里面有一块结构叫Mark Word,Mark Word指针指向了monitor。
所谓的Monitor其实是一种同步工具,也可以说是一种同步机制。在Java虚拟机(HotSpot)中,Monitor是由ObjectMonitor实现的,可以叫做内部锁,或者Monitor锁。
ObjectMonitor的工作原理:
- ObjectMonitor有两个队列:_WaitSet、_EntryList,用来保存ObjectWaiter 对象列表。
- _owner,获取 Monitor 对象的线程进入 _owner 区时, _count + 1。如果线程调用了 wait() 方法,此时会释放 Monitor 对象, _owner 恢复为空, _count - 1。同时该等待线程进入 _WaitSet 中,等待被唤醒。
ObjectMonitor() {
_header = NULL;
_count = 0; // 记录线程获取锁的次数
_waiters = 0,
_recursions = 0; //锁的重入次数
_object = NULL;
_owner = NULL; // 指向持有ObjectMonitor对象的线程
_WaitSet = NULL; // 处于wait状态的线程,会被加入到_WaitSet
_WaitSetLock = 0 ;
_Responsible = NULL ;
_succ = NULL ;
_cxq = NULL ;
FreeNext = NULL ;
_EntryList = NULL ; // 处于等待锁block状态的线程,会被加入到该列表
_SpinFreq = 0 ;
_SpinClock = 0 ;
OwnerIsThread = 0 ;
}
可以类比一个去医院就诊的例子[18]:
首先,患者在门诊大厅前台或自助挂号机进行挂号;
-
随后,挂号结束后患者找到对应的诊室就诊:
- 诊室每次只能有一个患者就诊;
- 如果此时诊室空闲,直接进入就诊;
- 如果此时诊室内有其它患者就诊,那么当前患者进入候诊室,等待叫号;
就诊结束后,走出就诊室,候诊室的下一位候诊患者进入就诊室。
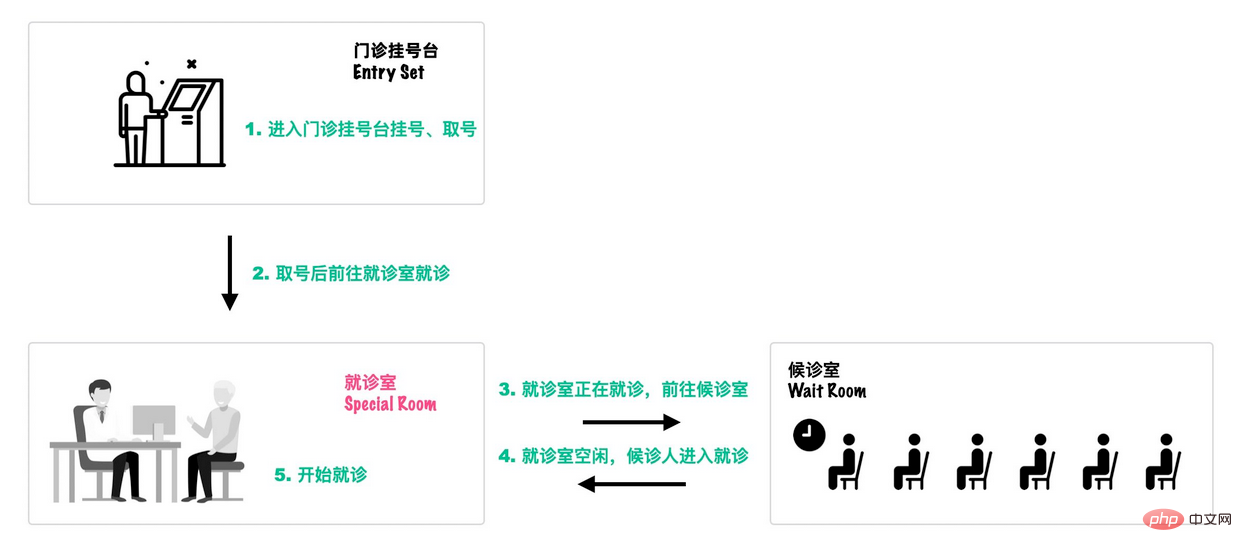
这个过程就和Monitor机制比较相似:
- Salle des patients externes : Tous les sujets en attente de participation doivent d'abord s'inscrire dans le Ensemble d'entrée pour être éligibles
- Salle de visite : Il ne peut y avoir qu'un seul sujet dans le **_Propriétaire** de la salle de clinique* ; * pour le traitement. Une fois le fil terminé, quittez la
- Salle d'attente : Lorsque la salle de traitement est occupée, entrez dans le Wait Set. Lorsque la salle de traitement est libre, appelez un nouveau fil à partir du **Wait Set. **
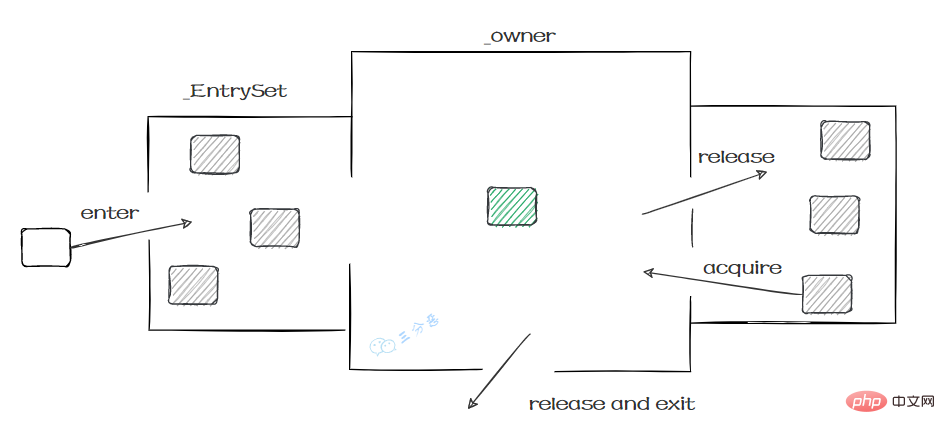
Nous savons donc quelle synchronisation est verrouillée :
- monitorenter Après avoir jugé qu'il a l'indicateur de synchronisation ACC_SYNCHRONIZED, le thread qui entre en premier dans cette méthode aura la priorité de posséder le propriétaire du moniteur At. cette fois, le compteur est à +1.
- monitorexit, lors de la sortie après exécution, le compteur -1, revient à 0 et est obtenu par les autres threads entrants.
26. En plus de l'atomicité, comment obtenir une visibilité, un ordre et une réentrée synchronisés ?
Comment la synchronisation assure-t-elle la visibilité ?
- Avant le verrouillage du fil, la valeur de la variable partagée dans la mémoire de travail sera effacée, donc lorsque vous utilisez la variable partagée, vous devez relire la dernière valeur de la mémoire principale.
- Une fois qu'un thread est verrouillé, les autres threads ne peuvent pas obtenir les variables partagées dans la mémoire principale.
- Avant que le fil ne soit déverrouillé, la dernière valeur de la variable partagée doit être actualisée dans la mémoire principale.
Comment la synchronisation assure-t-elle l'ordre ?
Le bloc de code synchronisé est exclusif et ne peut appartenir qu'à un seul thread à la fois, donc synchronisé garantit que le code est exécuté par un seul thread en même temps.
En raison de l'existence d'une sémantique en série, un programme monothread peut garantir que le résultat final est en ordre, mais il n'y a aucune garantie que les instructions ne seront pas réorganisées.
Donc, l'ordre garanti par synchronisé est l'ordre des résultats d'exécution, et non l'ordre visant à empêcher la réorganisation des instructions.
Comment la synchronisation réalise-t-elle la réentrée ?
synchronisé est un verrou réentrant, c'est-à-dire qu'un thread est autorisé à demander deux fois la ressource critique du verrou d'objet qu'il détient. Cette situation est appelée un verrou réentrant.
Il y a un compteur lors du verrouillage d'un objet. Il enregistrera le nombre de fois où le thread acquiert le verrou. Après avoir exécuté le bloc de code correspondant, le compteur sera -1 jusqu'à ce que le compteur soit effacé et que le verrou soit libéré.
La raison est qu'il est réentrant. En effet, l'objet verrou synchronisé possède un compteur, qui compte +1 une fois que le thread a acquis le verrou, et -1 lorsque le thread termine son exécution, jusqu'à ce qu'il soit effacé pour libérer le verrou.
27. Mise à niveau du verrouillage ? Comprenez-vous l’optimisation synchronisée ?
Pour déverrouiller et mettre à niveau, vous devez d'abord connaître l'état des différents verrous. A quoi fait référence ce statut ?
Dans l'en-tête de l'objet Java, il existe une structure appelée champ Mark Wordmark. Cette structure changera à mesure que l'état du verrouillage change.
La machine virtuelle 64 bits Mark Word est 64 bits. Jetons un coup d'œil à ses changements d'état :
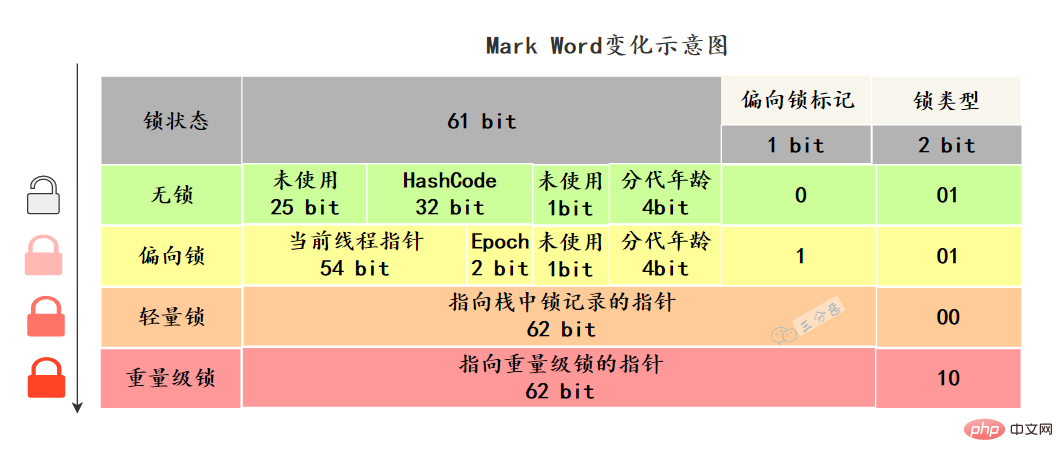
Mark Word stocke les données en cours d'exécution de l'objet lui-même, telles que le hash code, l'âge de génération GC, l'état du verrouillage. drapeau et biais Timestamp (Epoch) etc.
Quelles optimisations synchronisées ont été effectuées ?
Avant JDK1.6, l'implémentation de la synchronisation appelait directement l'entrée et la sortie d'ObjectMonitor. Ce type de verrou était appelé verrouillage lourd. À partir de JDK6, l'équipe de développement de machines virtuelles HotSpot a optimisé les verrous en Java, par exemple en ajoutant des stratégies d'optimisation telles que la rotation adaptative, l'élimination des verrous, le grossissement des verrous, les verrous légers et les verrous biaisés, pour améliorer les performances de synchronisation.
Verrouillage biaisé : en l'absence de concurrence, le pointeur de fil de discussion actuel est uniquement stocké dans Mark Word et aucune opération CAS n'est effectuée.
Verrous légers : lorsqu'il n'y a pas de concurrence multithread, par rapport aux verrous lourds, la consommation de performances causée par les mutex du système d'exploitation est réduite. Cependant, s'il existe une concurrence de verrouillage, en plus de la surcharge du mutex lui-même, il y a également la surcharge supplémentaire de l'opération CAS.
Spin Lock : réduisez les changements de contexte inutiles du processeur. Lorsqu'un verrou léger est mis à niveau vers un verrou lourd, la méthode de verrouillage par rotation est utilisée
Grossissement du verrou : connectez plusieurs opérations de verrouillage et de déverrouillage consécutives ensemble et étendez-les dans un verrou à plus grande portée.
Élimination des verrous : lorsque le compilateur juste-à-temps de la machine virtuelle est en cours d'exécution, il élimine les verrous qui nécessitent une synchronisation sur certains codes mais sont détectés comme peu susceptibles d'avoir une concurrence de données partagées.
Quel est le processus de mise à niveau du verrouillage ?
Direction de mise à niveau du verrouillage : Pas de verrouillage -> Verrouillage biaisé -> Verrouillage léger -> Verrouillage lourd, cette direction est fondamentalement irréversible.

Jetons un coup d'œil au processus de mise à niveau :
Verrouillage du biais :
Acquisition du verrouillage du biais :
- Déterminez s'il s'agit d'un état biaisable - si l'indicateur de verrouillage dans MarkWord est « 01 », si le verrou biaisé est « 1 »
- S'il s'agit d'un état biaisable, vérifiez si l'ID du fil est le fil actuel et si alors, entrez l'étape « 5 », sinon passez à l'étape « 3 »
- Concourez pour le verrouillage via l'opération CAS. Si la compétition réussit, définissez l'ID du fil dans MarkWord sur l'ID du fil actuel, puis exécutez « 5 » ; si la compétition échoue, exécutez « 4 »
- L'échec du CAS à acquérir le verrou de biais indique une concurrence. Lorsque le point de sécurité est atteint, le thread qui obtient le verrou biaisé est suspendu. Le verrou biaisé est mis à niveau vers un verrou léger. Ensuite, le thread bloqué au point de sécurité continue d'exécuter le bloc de code de synchronisation. ne sera pas activement libéré (révoqué). La révocation ne sera exécutée que lorsque d'autres threads entreront en compétition. Puisque la révocation doit connaître l'état de la pile du thread détenant actuellement le verrou biaisé, elle doit attendre que le point de sécurité soit exécuté. temps, le thread (T) détenant le verrou biaisé a deux situations : '2' et '3' ; révoqué directement Le verrou devient un état sans verrou ---- lorsque l'état atteint le seuil 20, une mise à niveau de biais lourde par lots sera effectuée - le fil T est toujours dans le bloc de code de synchronisation et le verrouillage de biais du thread T sera mis à niveau vers un thread léger. Lock
- , le thread actuel effectue l'étape d'acquisition du verrou dans l'état de verrouillage léger - si l'état atteint le seuil 40, la révocation par lots est effectuée
Verrouillage léger :
Acquisition de verrou léger :- Lors de l'exécution d'une opération de verrouillage, le jvm déterminera si un verrou lourd a été obtenu. Sinon, un espace sera creusé dans le cadre de la pile de threads actuel comme enregistrement de verrouillage du verrou, et. l'objet de verrouillage MarkWord sera copié dans l'enregistrement de verrouillage. Une fois la copie réussie, jvm utilise l'opération CAS pour mettre à jour le MarkWord de l'en-tête de l'objet vers un pointeur vers l'enregistrement de verrouillage et pointe le pointeur du propriétaire dans l'enregistrement de verrouillage vers le MarkWord de l'objet de verrouillage. en-tête d'objet. En cas de succès, exécutez « 3 », sinon exécutez « 4 ». Si la mise à jour réussit, le thread actuel détient le verrou de l'objet et l'indicateur de verrouillage MarkWord de l'objet est défini sur « 00 », ce qui signifie que cet objet est dans un état de verrouillage léger
- La mise à jour échoue, jvm vérifie d'abord si l'objet MarkWord pointe vers l'enregistrement de verrouillage dans le cadre de pile de threads actuel, si c'est le cas, exécutez « 5 », sinon exécutez « 4 » indique la réentrée du verrouillage, puis ajoutez un verrou ; enregistrement dans le cadre de pile de threads actuel. La première partie (Mot de marque déplacé) est nulle et pointe vers l'objet verrou de Mark Word, fonctionnant comme un compteur de réentrance.
attente de rotation
(par défaut 10 fois). Si le nombre d'attentes atteint le seuil et que le verrou n'est pas obtenu, alorspassez à un verrou lourd.
- ce qui permet généralement d'économiser du temps et des efforts. Processus de mise à niveau :
- Processus de mise à niveau complet :
- 28. Parlez de la différence entre synchronisé et ReentrantLock ?
- Vous pouvez répondre à cette question à partir de plusieurs dimensions telles que l'implémentation du verrouillage, les caractéristiques fonctionnelles et les performances : Implémentation du verrouillage :
Performances : 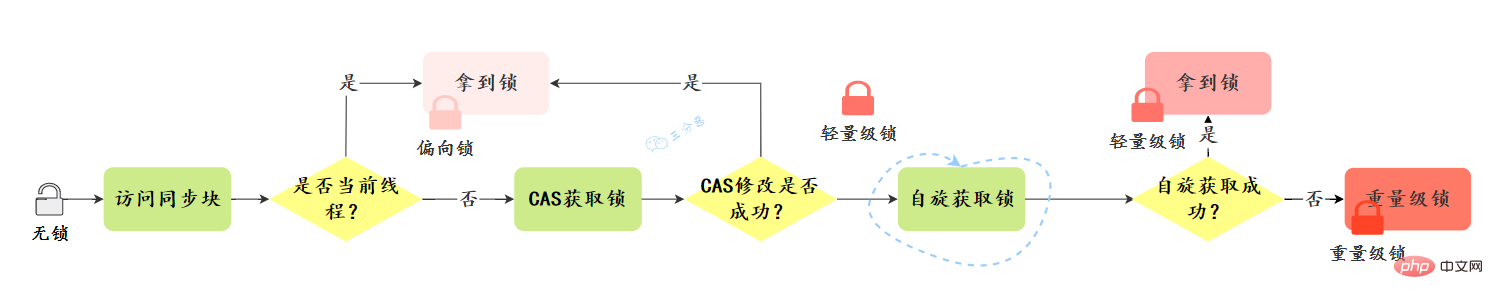 Avant l'optimisation du verrouillage JDK1.6, les performances synchronisées étaient meilleures que ReenTrantLock Très différent. Mais depuis JDK6, la rotation adaptative, l'élimination des verrous, etc. ont été ajoutées, et les performances des deux sont presque les mêmes.
Avant l'optimisation du verrouillage JDK1.6, les performances synchronisées étaient meilleures que ReenTrantLock Très différent. Mais depuis JDK6, la rotation adaptative, l'élimination des verrous, etc. ont été ajoutées, et les performances des deux sont presque les mêmes.
ReentrantLock ajoute des fonctionnalités avancées par rapport à la synchronisation, telles que l'attente interrompue, le verrouillage équitable et la notification sélective. ![synchronized 锁升级过程-来源参考[14]](https://img.php.cn/upload/article/000/000/067/2ef068e2d2216314dc9ad545dda17019-36.png)
- ReentrantLock doit être déclaré manuellement pour verrouiller et libérer le verrou. Il est généralement combiné avec finalement pour libérer le verrou. Synchronisé n'a pas besoin de libérer manuellement le verrou.
- Le tableau suivant répertorie les différences entre les deux serrures :
-
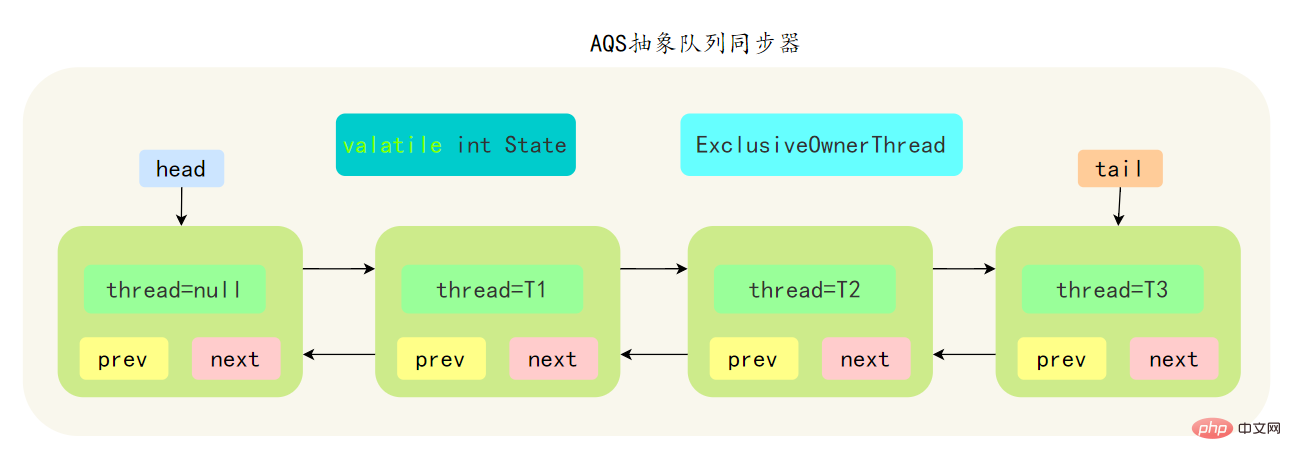
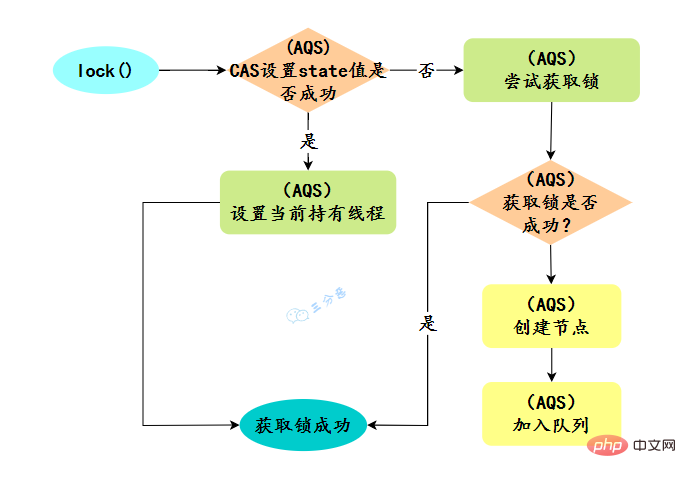
29. Que savez-vous de l'AQS ?
- AbstractQueuedSynchronizer Abstract Synchronization Queue, appelée AQS, est la base du package simultané Java. Les verrous du package simultané sont implémentés sur la base d'AQS.
- AQS是基于一个FIFO的双向队列,其内部定义了一个节点类Node,Node 节点内部的 SHARED 用来标记该线程是获取共享资源时被阻挂起后放入AQS 队列的, EXCLUSIVE 用来标记线程是 取独占资源时被挂起后放入AQS 队列
- AQS 使用一个 volatile 修饰的 int 类型的成员变量 state 来表示同步状态,修改同步状态成功即为获得锁,volatile 保证了变量在多线程之间的可见性,修改 State 值时通过 CAS 机制来保证修改的原子性
- 获取state的方式分为两种,独占方式和共享方式,一个线程使用独占方式获取了资源,其它线程就会在获取失败后被阻塞。一个线程使用共享方式获取了资源,另外一个线程还可以通过CAS的方式进行获取。
- 如果共享资源被占用,需要一定的阻塞等待唤醒机制来保证锁的分配,AQS 中会将竞争共享资源失败的线程添加到一个变体的 CLH 队列中。
- AQS 中队列是个双向链表,也是 FIFO 先进先出的特性
- 通过 Head、Tail 头尾两个节点来组成队列结构,通过 volatile 修饰保证可见性
- Head 指向节点为已获得锁的节点,是一个虚拟节点,节点本身不持有具体线程
- 获取不到同步状态,会将节点进行自旋获取锁,自旋一定次数失败后会将线程阻塞,相对于 CLH 队列性能较好
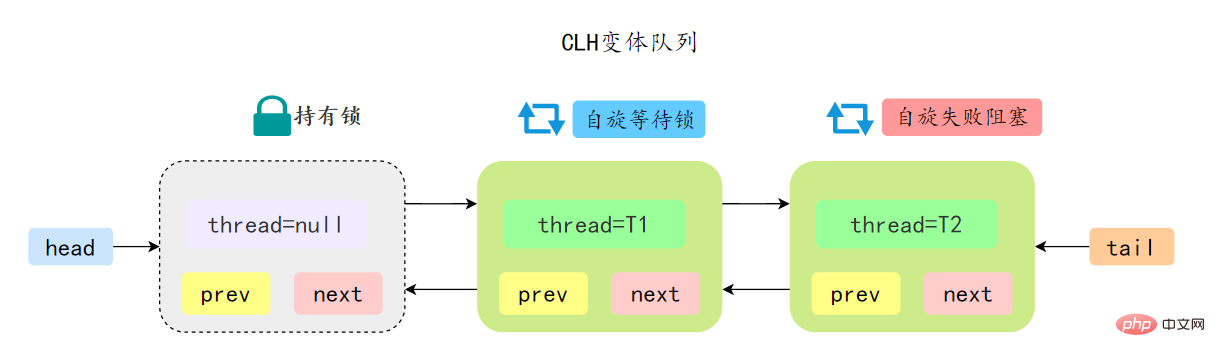
 先简单了解一下CLH:Craig、Landin and Hagersten 队列,是 单向链表实现的队列。申请线程只在本地变量上自旋,它不断轮询前驱的状态,如果发现 前驱节点释放了锁就结束自旋
先简单了解一下CLH:Craig、Landin and Hagersten 队列,是 单向链表实现的队列。申请线程只在本地变量上自旋,它不断轮询前驱的状态,如果发现 前驱节点释放了锁就结束自旋AQS 中的队列是 CLH 变体的虚拟双向队列,通过将每条请求共享资源的线程封装成一个节点来实现锁的分配:
AQS 中的 CLH 变体等待队列拥有以下特性:
ps:AQS源码里面有很多细节可问,建议有时间好好看看AQS源码。
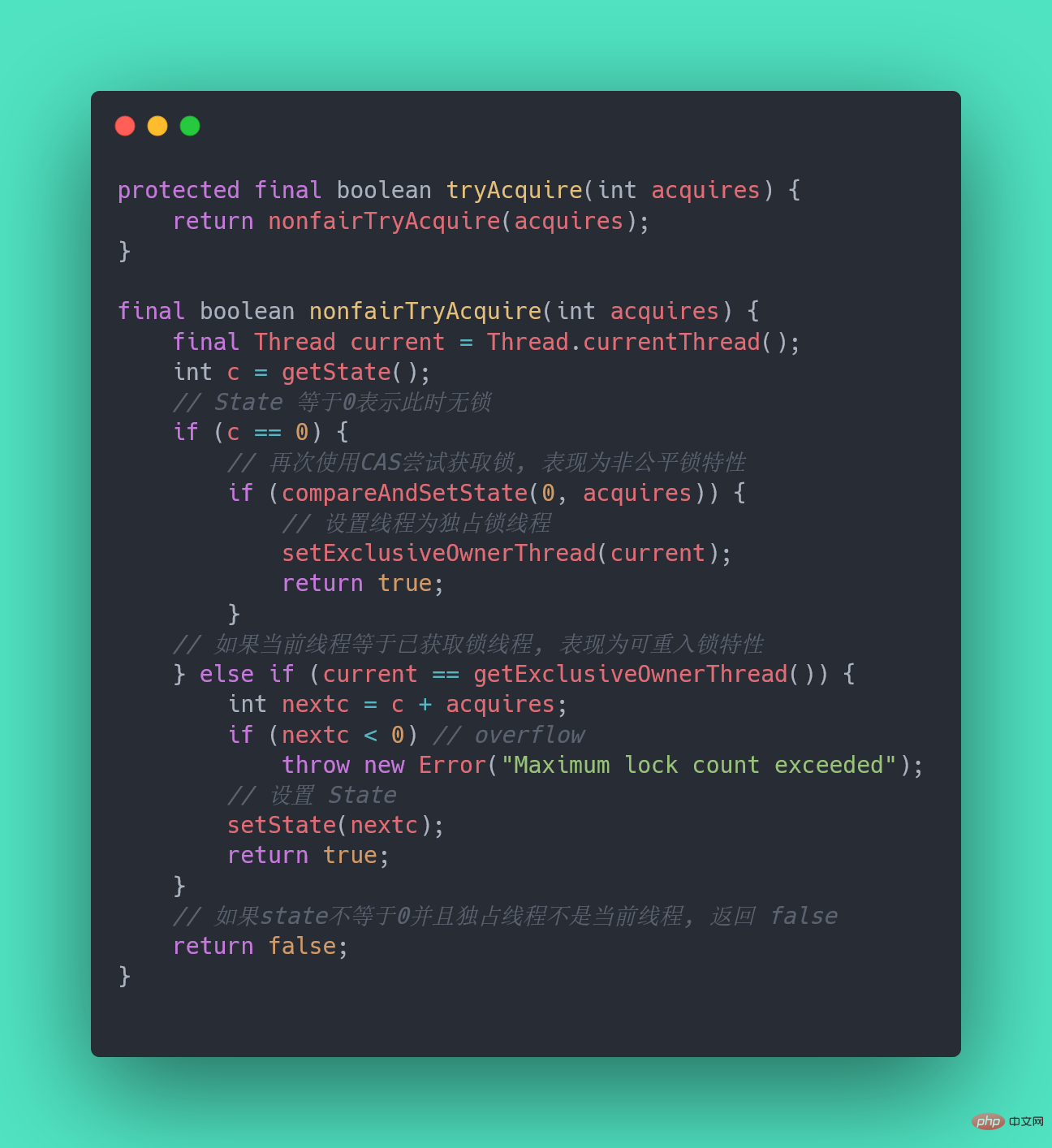
30.ReentrantLock实现原理?
ReentrantLock 是可重入的独占锁,只能有一个线程可以获取该锁,其它获取该锁的线程会被阻塞而被放入该锁的阻塞队列里面。
看看ReentrantLock的加锁操作:
// 创建非公平锁 ReentrantLock lock = new ReentrantLock(); // 获取锁操作 lock.lock(); try { // 执行代码逻辑 } catch (Exception ex) { // ... } finally { // 解锁操作 lock.unlock(); }new ReentrantLock()构造函数默认创建的是非公平锁 NonfairSync。公平锁 FairSync
- 公平锁是指多个线程按照申请锁的顺序来获取锁,线程直接进入队列中排队,队列中的第一个线程才能获得锁
- 公平锁的优点是等待锁的线程不会饿死。缺点是整体吞吐效率相对非公平锁要低,等待队列中除第一个线程以外的所有线程都会阻塞,CPU 唤醒阻塞线程的开销比非公平锁大
非公平锁 NonfairSync
- 非公平锁是多个线程加锁时直接尝试获取锁,获取不到才会到等待队列的队尾等待。但如果此时锁刚好可用,那么这个线程可以无需阻塞直接获取到锁
- 非公平锁的优点是可以减少唤起线程的开销,整体的吞吐效率高,因为线程有几率不阻塞直接获得锁,CPU 不必唤醒所有线程。缺点是处于等待队列中的线程可能会饿死,或者等很久才会获得锁
默认创建的对象lock()的时候:
- 如果锁当前没有被其它线程占用,并且当前线程之前没有获取过该锁,则当前线程会获取到该锁,然后设置当前锁的拥有者为当前线程,并设置 AQS 的状态值为1 ,然后直接返回。如果当前线程之前己经获取过该锁,则这次只是简单地把 AQS 的状态值加1后返回。
- 如果该锁己经被其他线程持有,非公平锁会尝试去获取锁,获取失败的话,则调用该方法线程会被放入 AQS 队列阻塞挂起。
31.ReentrantLock怎么实现公平锁的?
new ReentrantLock()构造函数默认创建的是非公平锁 NonfairSyncpublic ReentrantLock() { sync = new NonfairSync();}同时也可以在创建锁构造函数中传入具体参数创建公平锁 FairSync
ReentrantLock lock = new ReentrantLock(true);--- ReentrantLock// true 代表公平锁,false 代表非公平锁public ReentrantLock(boolean fair) { sync = fair ? new FairSync() : new NonfairSync();}FairSync、NonfairSync 代表公平锁和非公平锁,两者都是 ReentrantLock 静态内部类,只不过实现不同锁语义。
非公平锁和公平锁的两处不同:
- Après avoir appelé la serrure pour serrure injuste, le CAS sera d'abord appelé pour saisir la serrure. Si la serrure n'est pas occupée à ce moment-là, la serrure sera obtenue directement et restituée.
- Après l'échec du CAS, le verrou injuste entrera dans la méthode tryAcquire tout comme le verrou équitable. Dans la méthode tryAcquire, s'il s'avère que le verrou a été libéré à ce moment (état == 0), le verrou injuste entrera. récupérez directement le verrou du CAS, mais Fair Lock déterminera s'il y a un thread dans la file d'attente à l'état d'attente. S'il y en a, il ne saisira pas le verrou et sera mis en file d'attente à l'arrière.
Relativement parlant, le verrouillage injuste aura de meilleures performances car son débit est relativement important. Bien entendu, les verrous injustes rendent le délai d'acquisition du verrou plus incertain, ce qui peut entraîner une privation prolongée des threads dans la file d'attente de blocage.
32. Et le CAS ? Que sait le CAS ?
CAS s'appelle CompareAndSwap, qui compare et échange. Il utilise principalement les instructions du processeur pour garantir la nature atomique de l'opération.
L'instruction CAS contient 3 paramètres : l'adresse mémoire A de la variable partagée, la valeur attendue B et la nouvelle valeur C de la variable partagée.
Seulement lorsque la valeur à l'adresse A en mémoire est égale à B, la valeur à l'adresse A en mémoire peut être mise à jour vers la nouvelle valeur C. En tant qu'instruction CPU, l'instruction CAS elle-même peut garantir l'atomicité.
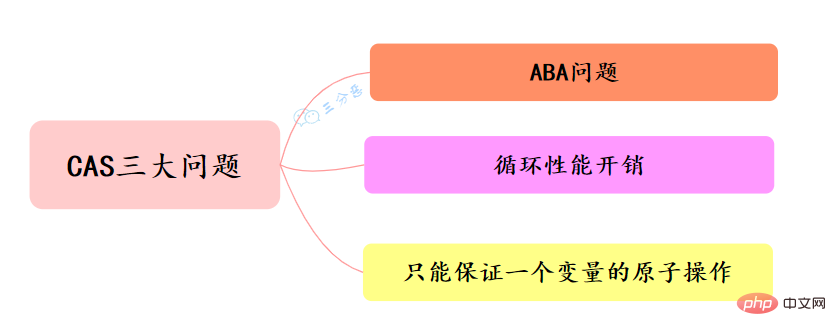
33. Quel est le problème avec le CAS ? Comment le résoudre ?
Trois problèmes classiques du CAS :
Problème ABA
Dans un environnement concurrent, en supposant que la condition initiale est A, lorsque vous modifiez les données, si elles s'avèrent être A, la modification sera effectuée. Mais bien que ce que vous voyez soit A, A peut s’être transformé en B, et B est redevenu A. A ce moment, A n'est plus l'autre A. Même si les données sont modifiées avec succès, des problèmes peuvent survenir.
Comment résoudre le problème ABA ?
- Ajouter un numéro de version
Chaque fois que vous modifiez une variable, ajoutez 1 au numéro de version de cette variable De cette façon, juste A->B->A, bien que la valeur de A n'ait pas changé, c'est. version Le numéro a changé. Si vous jugez à nouveau le numéro de version, vous constaterez que A a été modifié à ce moment-là. En se référant au numéro de version du verrouillage optimiste, cette approche peut apporter un test pratique aux données.
Java fournit la classe AtomicStampReference. Sa méthode compareAndSet vérifie d'abord si la valeur de référence actuelle de l'objet est égale à la référence attendue et si l'indicateur de tampon actuel (Stamp) est égal à l'indicateur attendu. Si tous sont égaux, la valeur de référence. et le tampon sont atomiquement. La valeur de l'indicateur de tampon est mise à jour à la valeur de mise à jour donnée.
Surcharge de performances en boucle
Spin CAS, s'il continue à s'exécuter en boucle sans succès, cela entraînera une très grande surcharge d'exécution pour le CPU.
Comment résoudre le problème de surcharge de performances de boucle ?
En Java, dans de nombreux endroits où spin CAS est utilisé, il y aura une limite sur le nombre de tours s'il dépasse un certain nombre, le spin s'arrêtera.
Ne peut garantir que le fonctionnement atomique d'une variable
CAS garantit l'atomicité de l'opération sur une variable. Si plusieurs variables sont opérées, CAS ne peut actuellement pas garantir directement l'atomicité de l'opération.
Comment résoudre le problème du fonctionnement atomique qui ne peut garantir qu'une seule variable ?
- Vous pouvez envisager d'utiliser des verrous pour garantir l'atomicité des opérations
- Vous pouvez envisager de fusionner plusieurs variables, d'encapsuler plusieurs variables dans un seul objet et d'assurer l'atomicité via AtomicReference.
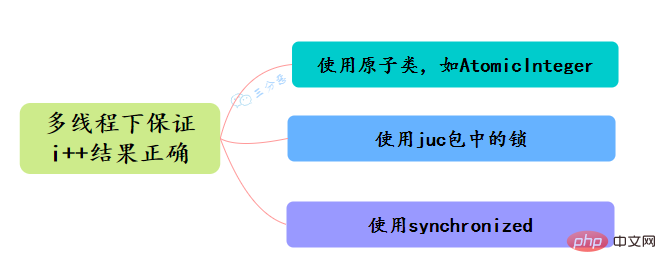
34.Quelles sont les méthodes pour assurer l'atomicité en Java ? Comment s'assurer que les résultats de i++ sous multi-threading sont corrects ?
- Utilisez des classes atomiques cycliques, telles que AtomicInteger, pour implémenter des opérations atomiques i++
- Utilisez des verrous sous le package juc, tels que ReentrantLock, pour verrouiller les opérations i++ avec lock.lock() pour obtenir l'atomicité
- Utilisez synchronisé , pour le verrouillage des opérations i++
35. Que savez-vous de la classe d'opération atomique ?
Lorsque le programme met à jour une variable, si plusieurs threads mettent à jour la variable en même temps, des valeurs inattendues peuvent être obtenues. Par exemple, la variable i=1, le thread A met à jour i+1 et le thread B met également à jour i+. 1. Après deux threads, Après l'opération, je ne suis peut-être pas égal à 3, mais égal à 2. Étant donné que les threads A et B obtiennent tous deux la valeur 1 lors de la mise à jour de la variable i, il s'agit d'une opération de mise à jour non sécurisée. Généralement, nous utiliserons synchronisé pour résoudre ce problème afin de garantir que plusieurs threads ne mettront pas à jour la variable i en même temps. .
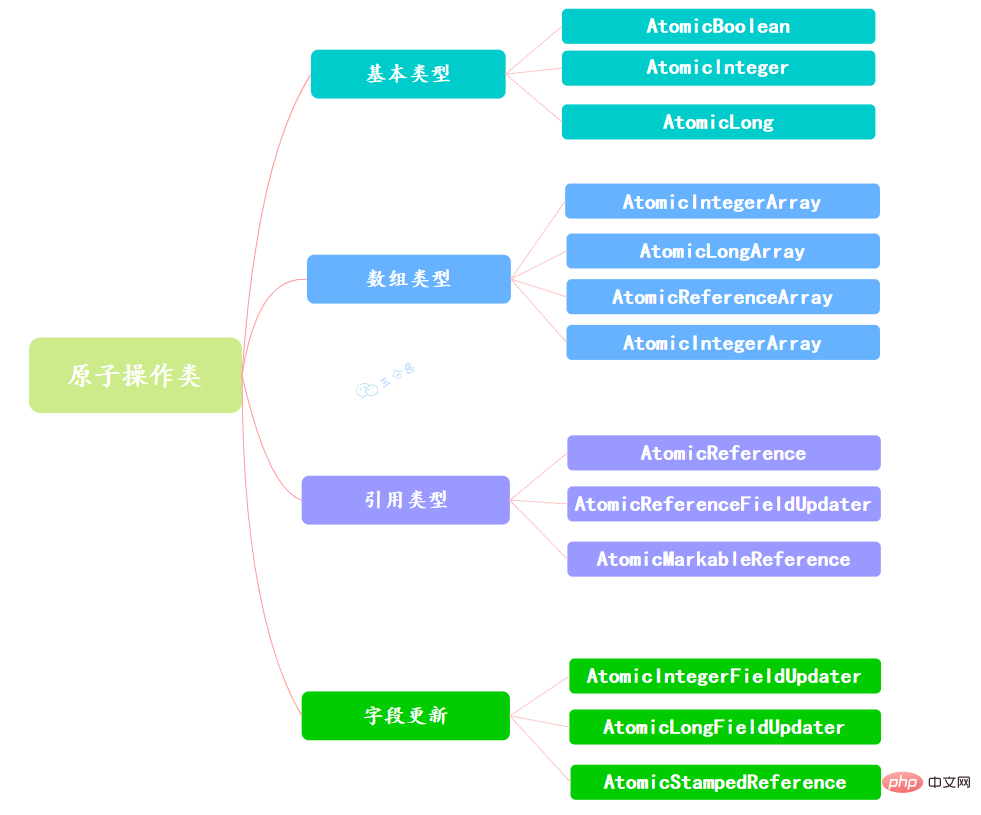
En fait, en plus de cela, il existe des options plus légères. Java fournit le package java.util.concurrent.atomic depuis JDK 1.5. La classe d'opération atomique de ce package offre une utilisation simple, de hautes performances et Thread-safe. moyen de mettre à jour une variable.
Comme il existe de nombreux types de variables, un total de 13 classes sont fournies dans le package Atomic, qui appartiennent à 4 types de méthodes de mise à jour atomique, à savoir le type de base de mise à jour atomique, le tableau de mise à jour atomique, la référence de mise à jour atomique et l'attribut de mise à jour atomique ( champ).
Les classes du package Atomic sont essentiellement des classes wrapper implémentées à l'aide d'Unsafe.
使用原子的方式更新基本类型,Atomic包提供了以下3个类:
AtomicBoolean:原子更新布尔类型。
AtomicInteger:原子更新整型。
AtomicLong:原子更新长整型。
通过原子的方式更新数组里的某个元素,Atomic包提供了以下4个类:
AtomicIntegerArray:原子更新整型数组里的元素。
AtomicLongArray:原子更新长整型数组里的元素。
AtomicReferenceArray:原子更新引用类型数组里的元素。
AtomicIntegerArray类主要是提供原子的方式更新数组里的整型
原子更新基本类型的AtomicInteger,只能更新一个变量,如果要原子更新多个变量,就需要使用这个原子更新引用类型提供的类。Atomic包提供了以下3个类:
AtomicReference:原子更新引用类型。
AtomicReferenceFieldUpdater:原子更新引用类型里的字段。
AtomicMarkableReference:原子更新带有标记位的引用类型。可以原子更新一个布尔类型的标记位和引用类型。构造方法是AtomicMarkableReference(V initialRef,boolean initialMark)。
如果需原子地更新某个类里的某个字段时,就需要使用原子更新字段类,Atomic包提供了以下3个类进行原子字段更新:
- AtomicIntegerFieldUpdater:原子更新整型的字段的更新器。
- AtomicLongFieldUpdater:原子更新长整型字段的更新器。
- AtomicStampedReference:原子更新带有版本号的引用类型。该类将整数值与引用关联起来,可用于原子的更新数据和数据的版本号,可以解决使用CAS进行原子更新时可能出现的 ABA问题。
36.AtomicInteger 的原理?
一句话概括:使用CAS实现。
以AtomicInteger的添加方法为例:
public final int getAndIncrement() { return unsafe.getAndAddInt(this, valueOffset, 1); }通过
Unsafe类的实例来进行添加操作,来看看具体的CAS操作:public final int getAndAddInt(Object var1, long var2, int var4) { int var5; do { var5 = this.getIntVolatile(var1, var2); } while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4)); return var5; }compareAndSwapInt 是一个native方法,基于CAS来操作int类型变量。其它的Résumer les points de connaissance de la concurrence Java基本都是大同小异。
37.线程死锁了解吗?该如何避免?
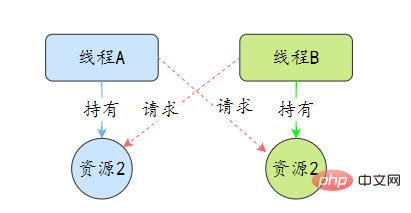
死锁是指两个或两个以上的线程在执行过程中,因争夺资源而造成的互相等待的现象,在无外力作用的情况下,这些线程会一直相互等待而无法继续运行下去。
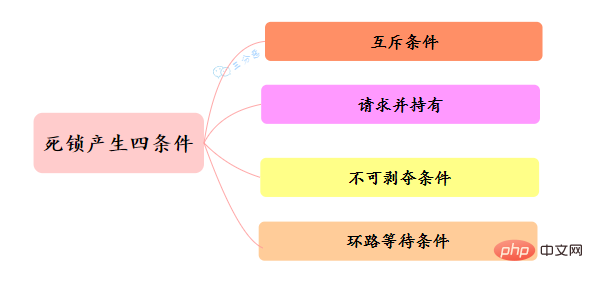
那么为什么会产生死锁呢? 死锁的产生必须具备以下四个条件:
- 互斥条件:指线程对己经获取到的资源进行它性使用,即该资源同时只由一个线程占用。如果此时还有其它线程请求获取获取该资源,则请求者只能等待,直至占有资源的线程释放该资源。
- 请求并持有条件:指一个 线程己经持有了至少一个资源,但又提出了新的资源请求,而新资源己被其它线程占有,所以当前线程会被阻塞,但阻塞 的同时并不释放自己已经获取的资源。
- 不可剥夺条件:指线程获取到的资源在自己使用完之前不能被其它线程抢占,只有在自己使用完毕后才由自己释放该资源。
- 环路等待条件:指在发生死锁时,必然存在一个线程——资源的环形链,即线程集合 {T0,T1,T2,…… ,Tn} 中 T0 正在等待一 T1 占用的资源,Tl1正在等待 T2用的资源,…… Tn 在等待己被 T0占用的资源。
该如何避免死锁呢?答案是至少破坏死锁发生的一个条件。
其中,互斥这个条件我们没有办法破坏,因为用锁为的就是互斥。不过其他三个条件都是有办法破坏掉的,到底如何做呢?
对于“请求并持有”这个条件,可以一次性请求所有的资源。
对于“不可剥夺”这个条件,占用部分资源的线程进一步申请其他资源时,如果申请不到,可以主动释放它占有的资源,这样不可抢占这个条件就破坏掉了。
对于“环路等待”这个条件,可以靠按序申请资源来预防。所谓按序申请,是指资源是有线性顺序的,申请的时候可以先申请资源序号小的,再申请资源序号大的,这样线性化后就不存在环路了。
38.那死锁问题怎么排查呢?
可以使用jdk自带的命令行工具排查:
- 使用jps查找运行的Java进程:jps -l
- 使用jstack查看线程堆栈信息:jstack -l 进程id
基本就可以看到死锁的信息。
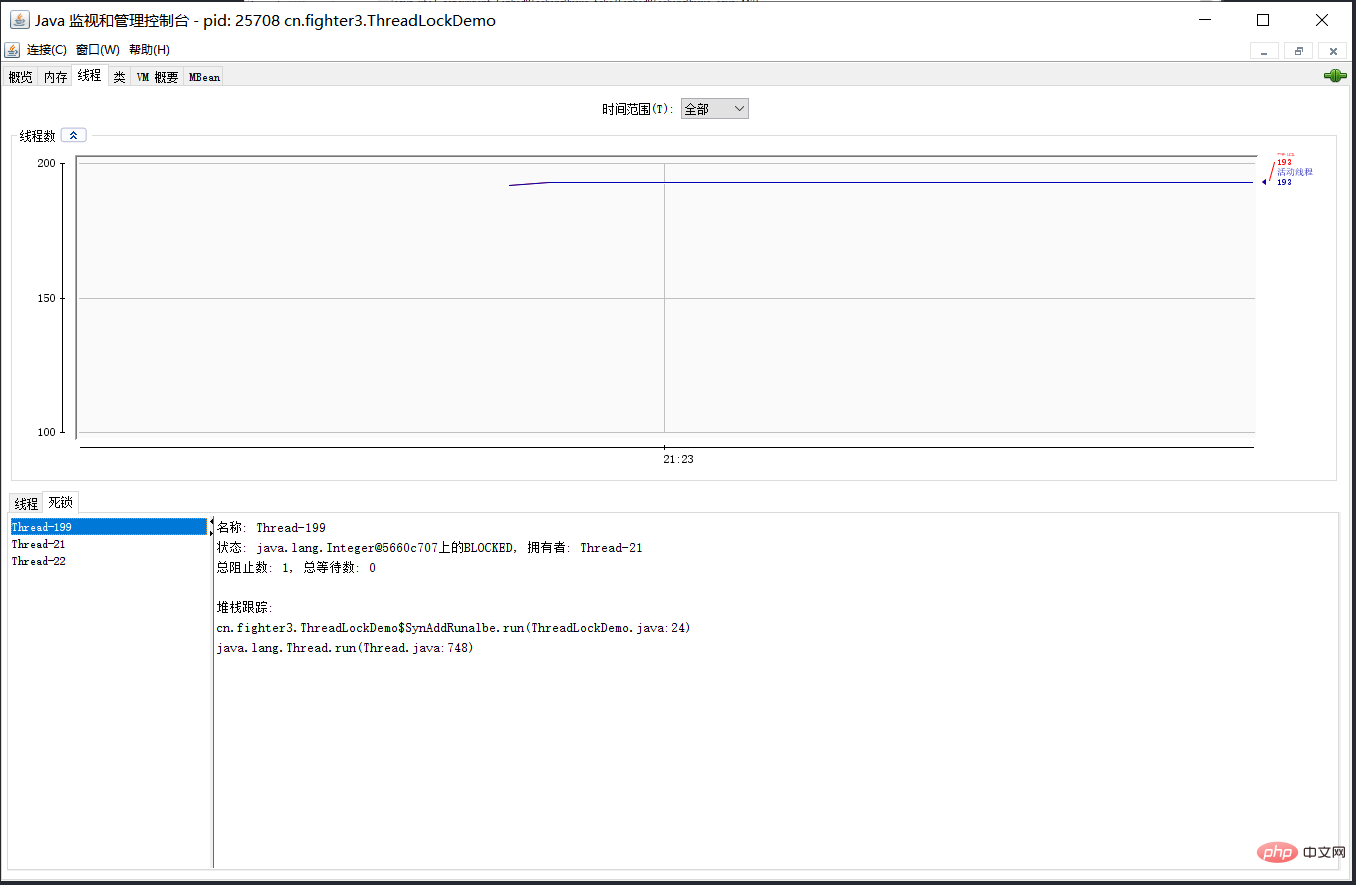
还可以利用图形化工具,比如JConsole。出现线程死锁以后,点击JConsole线程面板的
检测到死锁按钮,将会看到线程的死锁信息。39.CountDownLatch(倒计数器)了解吗?
CountDownLatch,倒计数器,有两个常见的应用场景[18]:
场景1:协调子线程结束动作:等待所有子线程运行结束
CountDownLatch允许一个或多个线程等待其他线程完成操作。
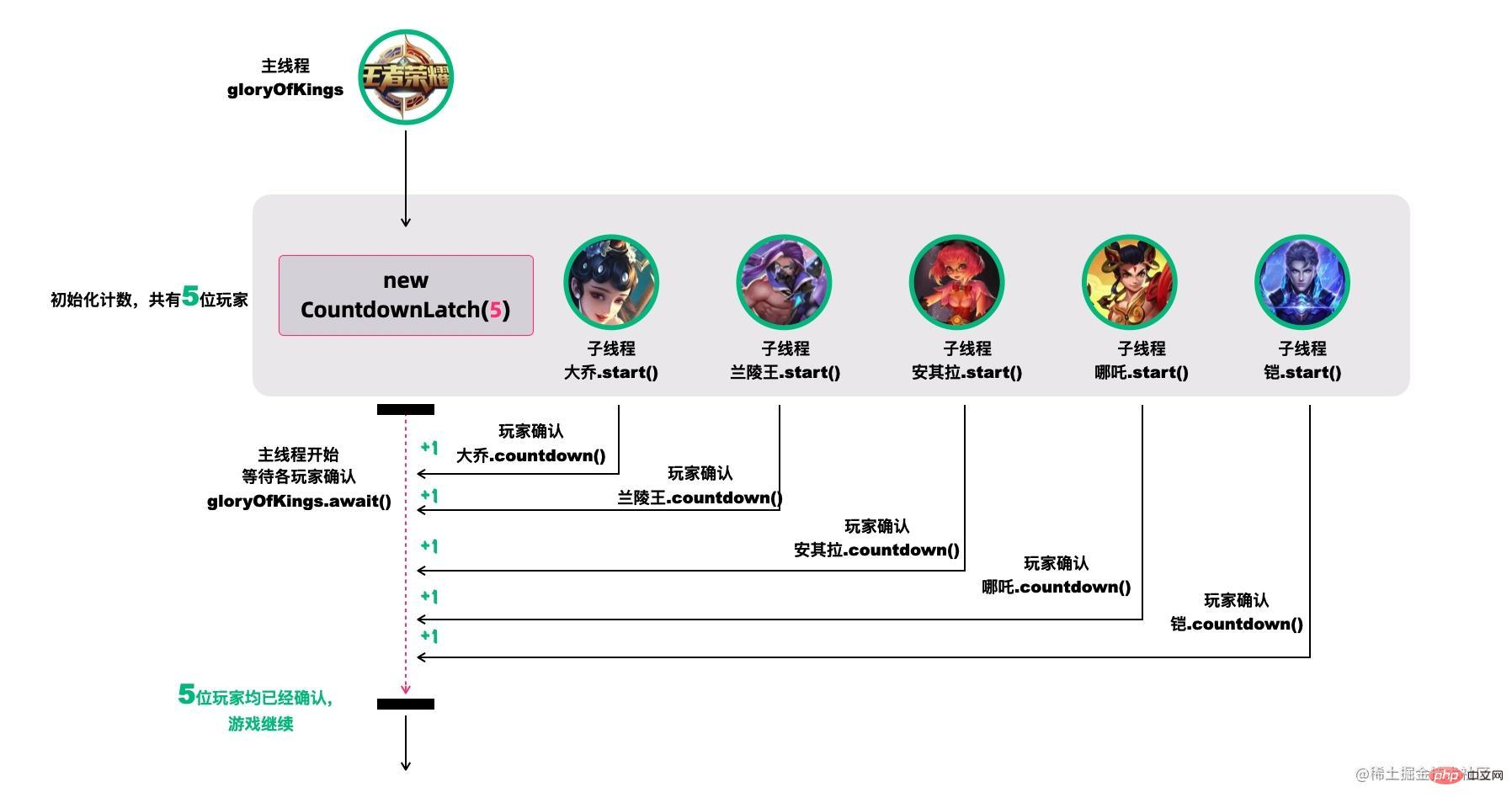
例如,我们很多人喜欢玩的王者荣耀,开黑的时候,得等所有人都上线之后,才能开打。
CountDownLatch模仿这个场景(参考[18]):
创建大乔、兰陵王、安其拉、哪吒和铠等五个玩家,主线程必须在他们都完成确认后,才可以继续运行。
在这段代码中,
new CountDownLatch(5)用户创建初始的latch数量,各玩家通过countDownLatch.countDown()完成状态确认,主线程通过countDownLatch.await()等待。public static void main(String[] args) throws InterruptedException { CountDownLatch countDownLatch = new CountDownLatch(5); Thread 大乔 = new Thread(countDownLatch::countDown); Thread 兰陵王 = new Thread(countDownLatch::countDown); Thread 安其拉 = new Thread(countDownLatch::countDown); Thread 哪吒 = new Thread(countDownLatch::countDown); Thread 铠 = new Thread(() -> { try { // 稍等,上个卫生间,马上到... Thread.sleep(1500); countDownLatch.countDown(); } catch (InterruptedException ignored) {} }); 大乔.start(); 兰陵王.start(); 安其拉.start(); 哪吒.start(); 铠.start(); countDownLatch.await(); System.out.println("所有玩家已经就位!"); }场景2. 协调子线程开始动作:统一各线程动作开始的时机
王者游戏中也有类似的场景,游戏开始时,各玩家的初始状态必须一致。不能有的玩家都出完装了,有的才降生。
所以大家得一块出生,在
在这个场景中,仍然用五个线程代表大乔、兰陵王、安其拉、哪吒和铠等五个玩家。需要注意的是,各玩家虽然都调用了
start()线程,但是它们在运行时都在等待countDownLatch的信号,在信号未收到前,它们不会往下执行。public static void main(String[] args) throws InterruptedException { CountDownLatch countDownLatch = new CountDownLatch(1); Thread 大乔 = new Thread(() -> waitToFight(countDownLatch)); Thread 兰陵王 = new Thread(() -> waitToFight(countDownLatch)); Thread 安其拉 = new Thread(() -> waitToFight(countDownLatch)); Thread 哪吒 = new Thread(() -> waitToFight(countDownLatch)); Thread 铠 = new Thread(() -> waitToFight(countDownLatch)); 大乔.start(); 兰陵王.start(); 安其拉.start(); 哪吒.start(); 铠.start(); Thread.sleep(1000); countDownLatch.countDown(); System.out.println("敌方还有5秒达到战场,全军出击!"); } private static void waitToFight(CountDownLatch countDownLatch) { try { countDownLatch.await(); // 在此等待信号再继续 System.out.println("收到,发起进攻!"); } catch (InterruptedException e) { e.printStackTrace(); } }CountDownLatch的核心方法也不多:
-
await():等待latch降为0; -
boolean await(long timeout, TimeUnit unit):等待latch降为0,但是可以设置超时时间。比如有玩家超时未确认,那就重新匹配,总不能为了某个玩家等到天荒地老。 -
countDown():latch数量减1; -
getCount():获取当前的latch数量。
40.CyclicBarrier(同步屏障)了解吗?
CyclicBarrier的字面意思是可循环使用(Cyclic)的屏障(Barrier)。它要做的事情是,让一 组线程到达一个屏障(也可以叫同步点)时被阻塞,直到最后一个线程到达屏障时,屏障才会开门,所有被屏障拦截的线程才会继续运行。
它和CountDownLatch类似,都可以协调多线程的结束动作,在它们结束后都可以执行特定动作,但是为什么要有CyclicBarrier,自然是它有和CountDownLatch不同的地方。
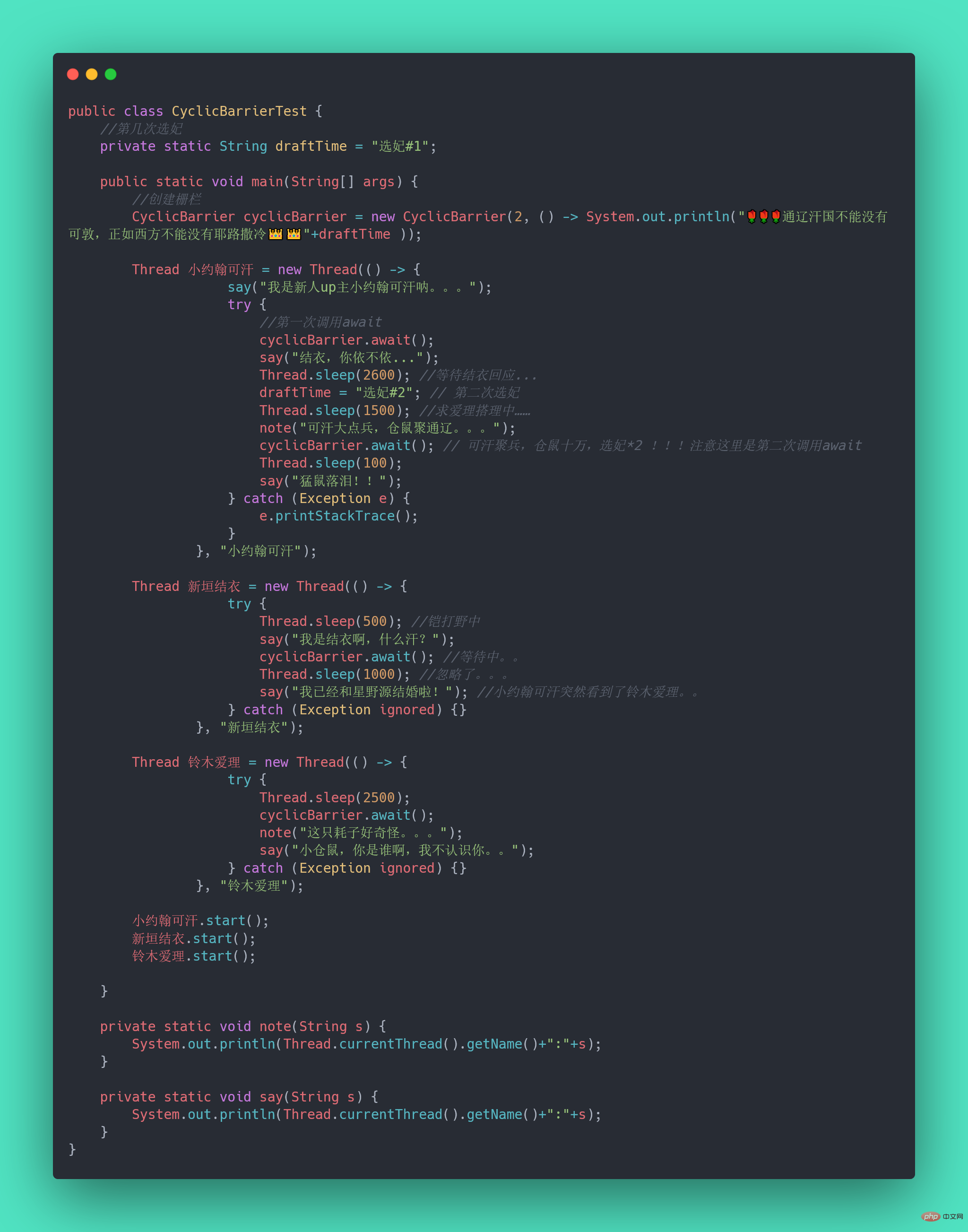
不知道你听没听过一个新人UP主小约翰可汗,小约翰生平有两大恨——“Résumer les points de connaissance de la concurrence Java”我们来还原一下事情的经过:小约翰在亲政后认识了新垣结衣,于是决定第一次选妃,向结衣表白,等待回应。然而新垣结衣回应嫁给了星野源,小约翰伤心欲绝,发誓生平不娶,突然发现了铃木爱理,于是小约翰决定第二次选妃,求爱理搭理,等待回应。
我们拿代码模拟这一场景,发现CountDownLatch无能为力了,因为CountDownLatch的使用是一次性的,无法重复利用,而这里等待了两次。此时,我们用CyclicBarrier就可以实现,因为它可以重复利用。
Résumer les points de connaissance de la concurrence Java:
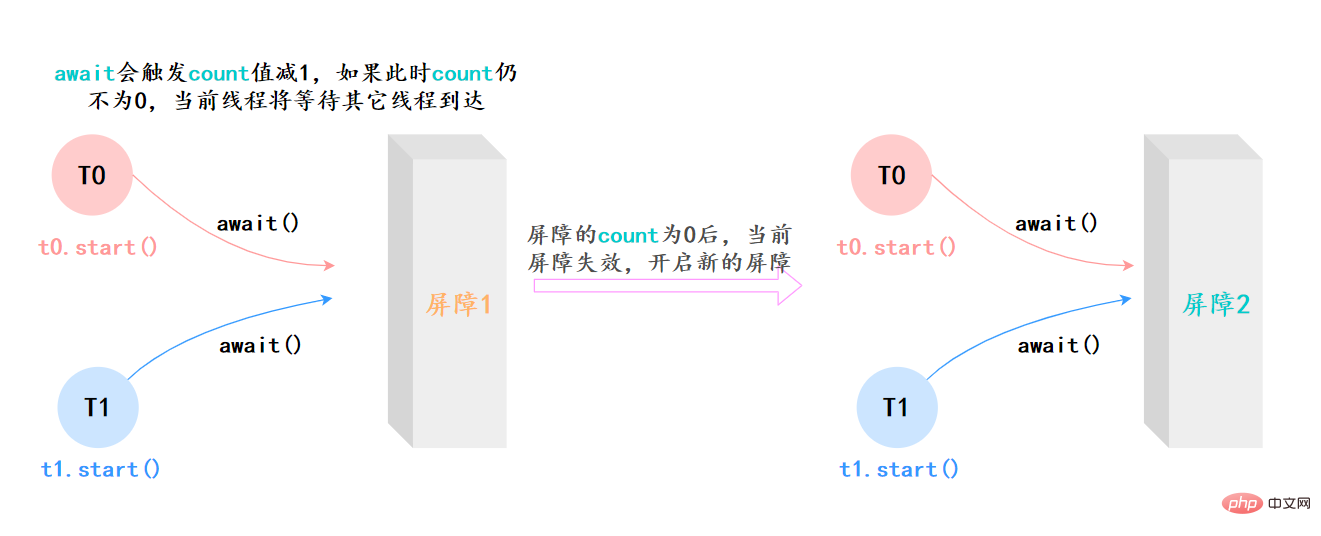
CyclicBarrier最最核心的方法,仍然是await():
- 如果当前线程不是第一个到达屏障的话,它将会进入等待,直到其他线程都到达,除非发生被中断、屏障被拆除、屏障被重设等情况;
上面的例子抽象一下,本质上它的流程就是这样就是这样:
41.CyclicBarrier和CountDownLatch有什么区别?
两者最核心的区别[18]:
- CountDownLatch est à usage unique, tandis que CyclicBarrier peut définir la barrière plusieurs fois pour la réutiliser ;
- Chaque sous-thread de CountDownLatch ne peut pas attendre d'autres threads et ne peut effectuer que ses propres tâches tandis que chaque thread de CyclicBarrier peut attendre d'autres threads ;
Leurs différences sont organisées dans un tableau :
CyclicBarrier CountDownLatch CyclicBarrier est réutilisable et les threads qu'il contient attendront que tous les threads terminent leurs tâches. À ce moment-là, la barrière sera supprimée et certaines actions spécifiques pourront être effectuées de manière sélective. CountDownLatch est unique, différents threads fonctionnent sur le même compteur jusqu'à ce que le compteur soit 0. CyclicBarrier est orienté vers le nombre de threads CountDownLatch est orienté vers le nombre de tâches Lors de l'utilisation de CyclicBarrier , Vous devez spécifier le nombre de threads participant à la collaboration dans le constructeur. Ces threads doivent appeler la méthode wait() Lors de l'utilisation de CountDownLatch, vous devez spécifier le nombre de tâches qui effectuent ces tâches CyclicBarrier peut être utilisé dans tous les threads. Le thread est libéré et réutilisé CountDownLatch ne peut plus être utilisé lorsque le compteur est à 0 Dans CyclicBarrier, si un thread rencontre une interruption, un délai d'attente, etc., des problèmes surviendront dans le fil attendu Dans CountDownLatch, si un problème survient dans un fil, les autres fils ne seront pas affectés 42.Semaphore(信号量)了解吗?
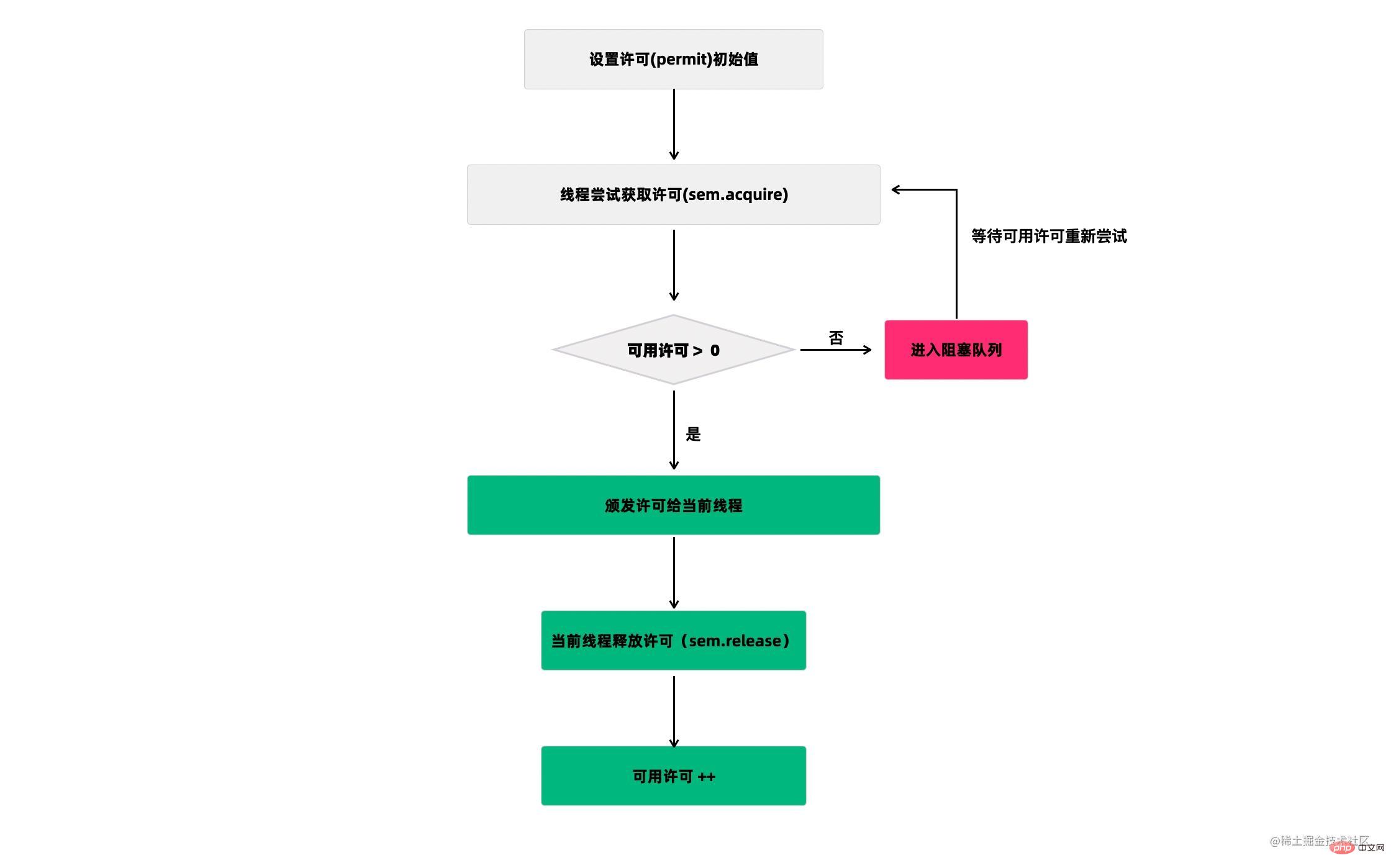
Semaphore(信号量)是用来控制同时访问特定资源的线程数量,它通过协调各个线程,以保证合理的使用公共资源。
听起来似乎很抽象,现在汽车多了,开车出门在外的一个老大难问题就是停车 。停车场的车位是有限的,只能允许若干车辆停泊,如果停车场还有空位,那么显示牌显示的就是绿灯和剩余的车位,车辆就可以驶入;如果停车场没位了,那么显示牌显示的就是绿灯和数字0,车辆就得等待。如果满了的停车场有车离开,那么显示牌就又变绿,显示空车位数量,等待的车辆就能进停车场。
我们把这个例子类比一下,车辆就是线程,进入停车场就是线程在执行,离开停车场就是线程执行完毕,看见红灯就表示线程被阻塞,不能执行,Semaphore的本质就是协调多个线程对共享资源的获取。
我们再来看一个Semaphore的用途:它可以用于做流量控制,特别是公用资源有限的应用场景,比如数据库连接。
假如有一个需求,要读取几万个文件的数据,因为都是IO密集型任务,我们可以启动几十个线程并发地读取,但是如果读到内存后,还需要存储到数据库中,而数据库的连接数只有10个,这时我们必须控制只有10个线程同时获取数据库连接保存数据,否则会报错无法获取数据库连接。这个时候,就可以使用Semaphore来做流量控制,如下:
public class SemaphoreTest { private static final int THREAD_COUNT = 30; private static ExecutorService threadPool = Executors.newRésumer les points de connaissance de la concurrence Java(THREAD_COUNT); private static Semaphore s = new Semaphore(10); public static void main(String[] args) { for (int i = 0; i <p>在代码中,虽然有30个线程在执行,但是只允许10个并发执行。Semaphore的构造方法<code>Semaphore(int permits</code>)接受一个整型的数字,表示可用的许可证数量。<code>Semaphore(10)</code>表示允许10个线程获取许可证,也就是最大并发数是10。Semaphore的用法也很简单,首先线程使用 Semaphore的acquire()方法获取一个许可证,使用完之后调用release()方法归还许可证。还可以用tryAcquire()方法尝试获取许可证。</p><h2>43.Exchanger 了解吗?</h2><p>Exchanger(交换者)是一个用于线程间协作的工具类。Exchanger用于进行线程间的数据交换。它提供一个同步点,在这个同步点,两个线程可以交换彼此的数据。</p><p><img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/000/000/067/a99f1f171b5f8c414e2981e6a7d5189a-57.png" class="lazy" alt="Résumer les points de connaissance de la concurrence Java"></p><p>这两个线程通过 exchange方法交换数据,如果第一个线程先执行exchange()方法,它会一直等待第二个线程也执行exchange方法,当两个线程都到达同步点时,这两个线程就可以交换数据,将本线程生产出来的数据传递给对方。</p><p>Exchanger可以用于遗传算法,遗传算法里需要选出两个人作为交配对象,这时候会交换两人的数据,并使用交叉规则得出2个交配结果。Exchanger也可以用于校对工作,比如我们需要将纸制银行流水通过人工的方式录入成电子银行流水,为了避免错误,采用AB岗两人进行录入,录入到Excel之后,系统需要加载这两个Excel,并对两个Excel数据进行校对,看看是否录入一致。</p><pre class="brush:php;toolbar:false">public class ExchangerTest { private static final Exchanger<string> exgr = new Exchanger<string>(); private static ExecutorService threadPool = Executors.newRésumer les points de connaissance de la concurrence Java(2); public static void main(String[] args) { threadPool.execute(new Runnable() { @Override public void run() { try { String A = "银行流水A"; // A录入银行流水数据 exgr.exchange(A); } catch (InterruptedException e) { } } }); threadPool.execute(new Runnable() { @Override public void run() { try { String B = "银行流水B"; // B录入银行流水数据 String A = exgr.exchange("B"); System.out.println("A和B数据是否一致:" + A.equals(B) + ",A录入的是:" + A + ",B录入是:" + B); } catch (InterruptedException e) { } } }); threadPool.shutdown(); }}</string></string>假如两个线程有一个没有执行exchange()方法,则会一直等待,如果担心有特殊情况发生,避免一直等待,可以使用
exchange(V x, long timeOut, TimeUnit unit)设置最大等待时长44.什么是线程池?
线程池: 简单理解,它就是一个Résumer les points de connaissance de la concurrence Java。
- 它帮我们管理线程,避免增加创建线程和销毁线程的资源损耗。因为线程其实也是一个对象,创建一个对象,需要经过类加载过程,销毁一个对象,需要走GC垃圾回收流程,都是需要资源开销的。
- 提高响应速度。 如果任务到达了,相对于从线程池拿线程,重新去创建一条线程执行,速度肯定慢很多。
- 重复利用。 线程用完,再放回池子,可以达到重复利用的效果,节省资源。
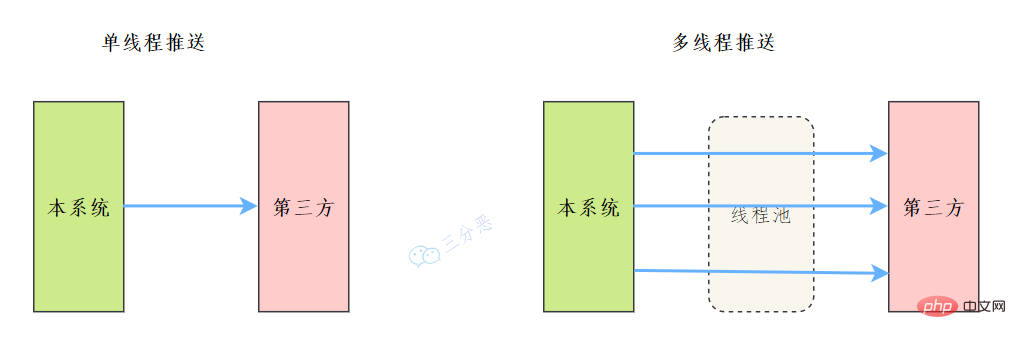
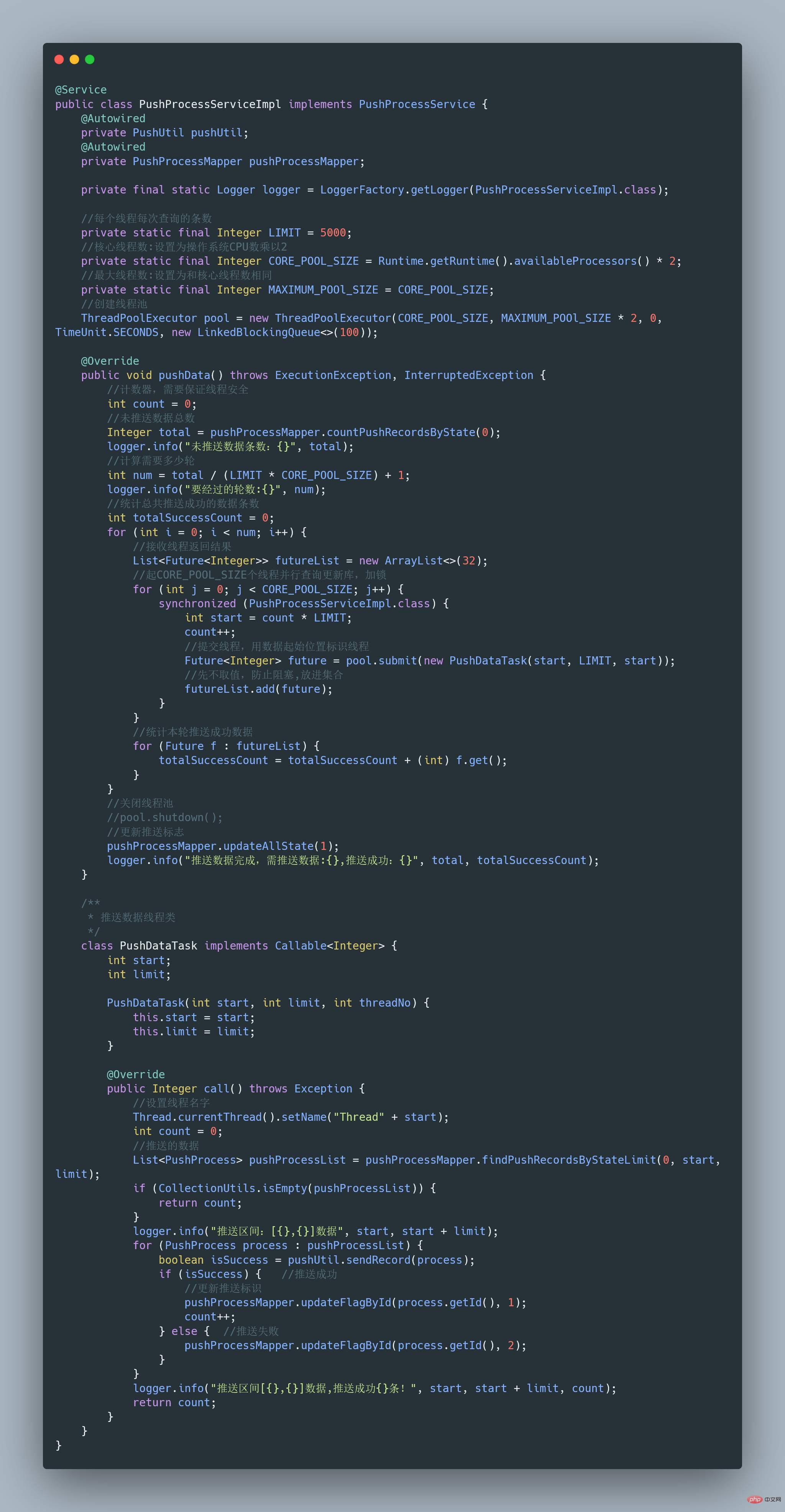
45.能说说工作中线程池的应用吗?
之前我们有一个和第三方对接的需求,需要向第三方推送数据,引入了多线程来提升数据推送的效率,其中用到了线程池来管理线程。
Résumer les points de connaissance de la concurrence Java如下:
完整可运行代码地址:https://gitee.com/fighter3/thread-demo.git
线程池的参数如下:
corePoolSize:线程核心参数选择了CPU数×2
maximumPoolSize:最大线程数选择了和核心线程数相同
keepAliveTime:非核心闲置线程存活时间直接置为0
unit:非核心线程保持存活的时间选择了 TimeUnit.SECONDS 秒
workQueue:线程池等待队列,使用 LinkedBlockingQueue阻塞队列
同时还用了synchronized 来加锁,保证数据不会被重复推送:
synchronized (PushProcessServiceImpl.class) {}ps:这个例子只是简单地进行了数据推送,实际上还可以结合其他的业务,像什么数据清洗啊、数据统计啊,都可以套用。
46.能简单说一下线程池的工作流程吗?
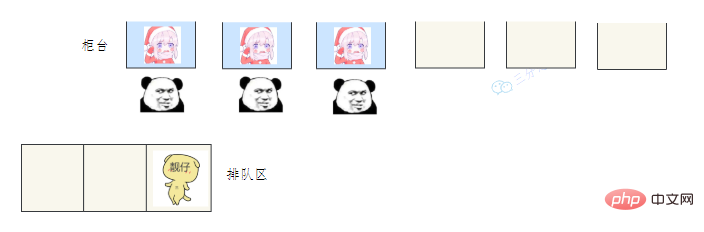
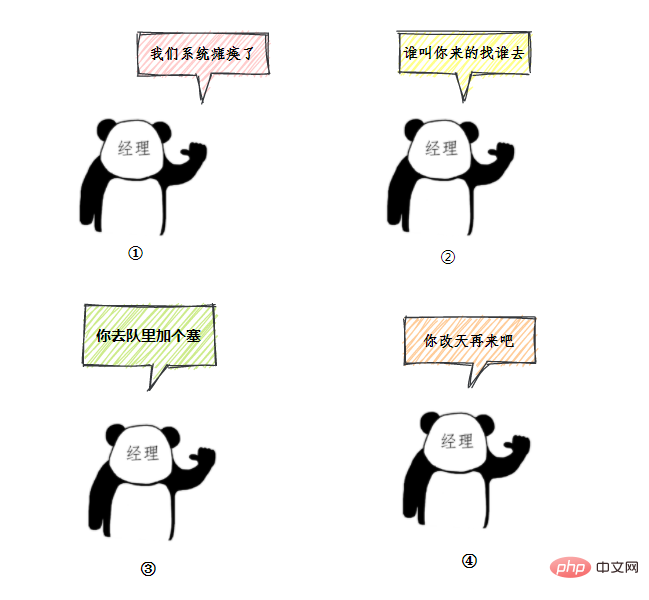
用一个通俗的比喻:
有一个营业厅,总共有六个窗口,现在开放了三个窗口,现在有三个窗口坐着三个营业员小姐姐在营业。
老三去办业务,可能会遇到什么情况呢?
- 老三发现有空间的在营业的窗口,直接去找小姐姐办理业务。
- 老三发现没有空闲的窗口,就在排队区排队等。
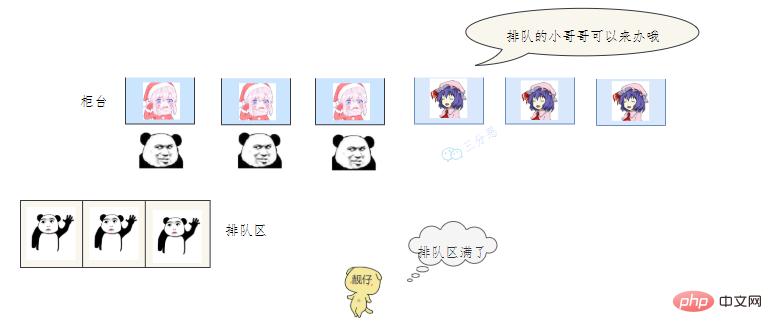
- 老三发现没有空闲的窗口,等待区也满了,蚌埠住了,经理一看,就让休息的小姐姐赶紧回来上班,等待区号靠前的赶紧去新窗口办,老三去排队区排队。小姐姐比较辛苦,假如一段时间发现他们可以不用接着营业,经理就让她们接着休息。
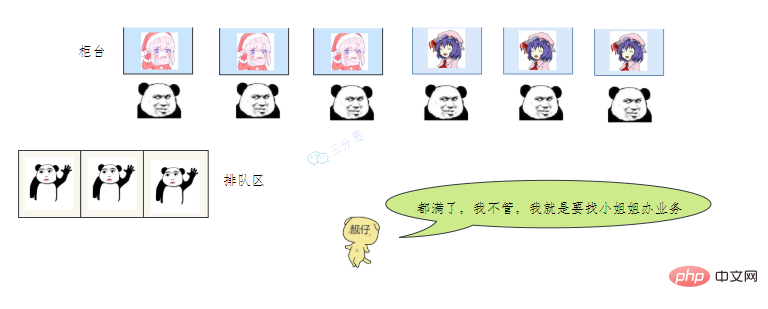
- 老三一看,六个窗口都满了,等待区也没位置了。老三急了,要闹,经理赶紧出来了,经理该怎么办呢?
我们银行系统已经瘫痪
谁叫你来办的你找谁去
看你比较急,去队里加个塞
今天没办法,不行你看改一天
上面的这个流程几乎就跟 JDK 线程池的大致流程类似,
- 营业中的 3个窗口对应核心线程池数:corePoolSize
- 总的营业窗口数6对应:maximumPoolSize
- 打开的临时窗口在多少时间内无人办理则关闭对应:unit
- 排队区就是等待队列:workQueue
- 无法办理的时候银行给出的解决方法对应:RejectedExecutionHandler
- threadFactory 该参数在 JDK 中是 线程工厂,用来创建线程对象,一般不会动。
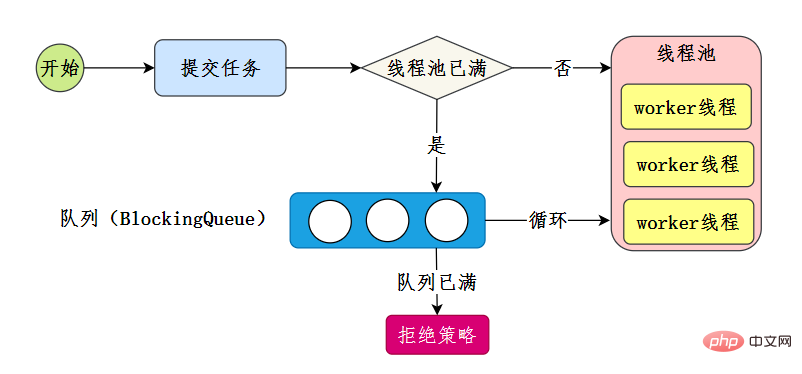
所以我们线程池的工作流程也比较好理解了:
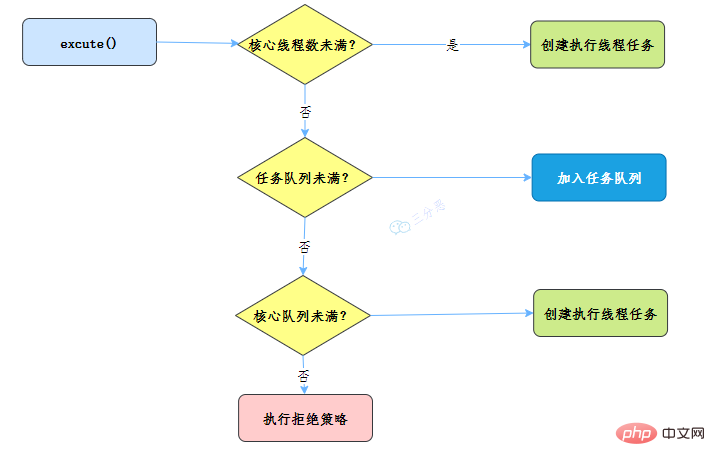
- 线程池刚创建时,里面没有一个线程。任务队列是作为参数传进来的。不过,就算队列里面有任务,线程池也不会马上执行它们。
- 当调用 execute() 方法添加一个任务时,线程池会做如下判断:
- 如果正在运行的线程数量小于 corePoolSize,那么马上创建线程运行这个任务;
- 如果正在运行的线程数量大于或等于 corePoolSize,那么将这个任务放入队列;
- 如果这时候队列满了,而且正在运行的线程数量小于 maximumPoolSize,那么还是要创建非核心线程立刻运行这个任务;
- 如果队列满了,而且正在运行的线程数量大于或等于 maximumPoolSize,那么线程池会根据拒绝策略来对应处理。
当一个线程完成任务时,它会从队列中取下一个任务来执行。
当一个线程无事可做,超过一定的时间(keepAliveTime)时,线程池会判断,如果当前运行的线程数大于 corePoolSize,那么这个线程就被停掉。所以线程池的所有任务完成后,它最终会收缩到 corePoolSize 的大小。
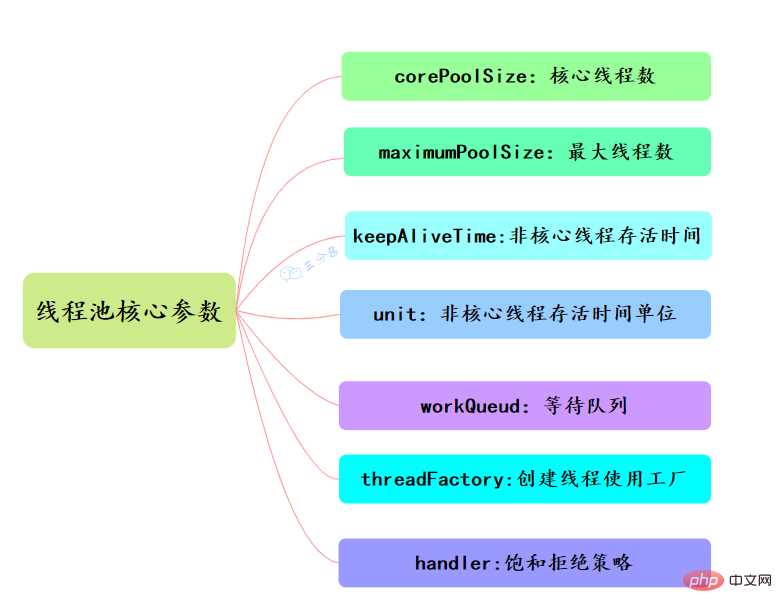
47.线程池主要参数有哪些?
线程池有七大参数,需要重点关注
corePoolSize、maximumPoolSize、workQueue、handler这四个。- corePoolSize
此值是用来初始化线程池中核心线程数,当线程池中线程池数corePoolSize时,系统默认是添加一个任务才创建一个线程池。当线程数 = corePoolSize时,新任务会追加到workQueue中。
- maximumPoolSize
maximumPoolSize表示允许的最大线程数 = (非核心线程数+核心线程数),当BlockingQueue也满了,但线程池中总线程数 maximumPoolSize时候就会再次创建新的线程。- keepAliveTime
非核心线程 =(maximumPoolSize - corePoolSize ) ,非核心线程闲置下来不干活最多存活时间。
- unit
线程池中非核心线程保持存活的时间的单位
- TimeUnit.DAYS; 天
- TimeUnit.HOURS; 小时
- TimeUnit.MINUTES; 分钟
- TimeUnit.SECONDS; 秒
- TimeUnit.MILLISECONDS; 毫秒
- TimeUnit.MICROSECONDS; 微秒
- TimeUnit.NANOSECONDS; 纳秒
- workQueue
线程池等待队列,维护着等待执行的
Runnable对象。当运行当线程数= corePoolSize时,新的任务会被添加到workQueue中,如果workQueue也满了则尝试用非核心线程执行任务,等待队列应该尽量用有界的。- threadFactory
创建一个新线程时使用的工厂,可以用来设定线程名、是否为daemon线程等等。
- handler
corePoolSize、workQueue、maximumPoolSize都不可用的时候执行的饱和策略。48.线程池的拒绝策略有哪些?
类比前面的例子,无法办理业务时的处理方式,帮助记忆:
- AbortPolicy :直接抛出异常,默认使用此策略
- CallerRunsPolicy:用调用者所在的线程来执行任务
- DiscardOldestPolicy:丢弃阻塞队列里最老的任务,也就是队列里靠前的任务
- DiscardPolicy :当前任务直接丢弃
想实现自己的拒绝策略,实现RejectedExecutionHandler接口即可。
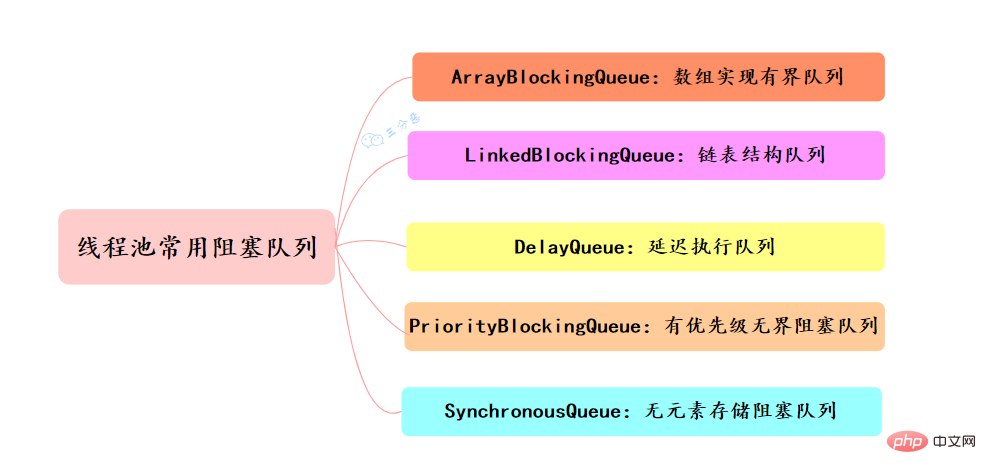
49.线程池有哪几种工作队列?
常用的阻塞队列主要有以下几种:
- ArrayBlockingQueue:ArrayBlockingQueue(有界队列)是一个用数组实现的有界阻塞队列,按FIFO排序量。
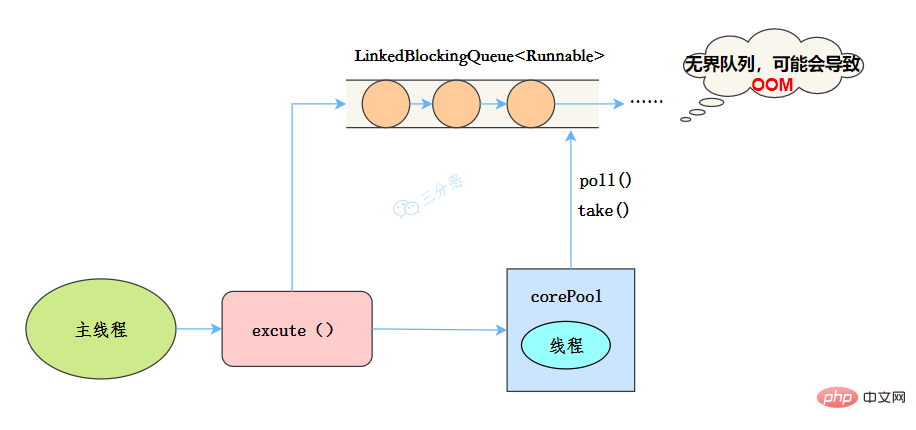
- LinkedBlockingQueue:LinkedBlockingQueue(可设置容量队列)是基于链表结构的阻塞队列,按FIFO排序任务,容量可以选择进行设置,不设置的话,将是一个无边界的阻塞队列,最大长度为Integer.MAX_VALUE,吞吐量通常要高于ArrayBlockingQuene;newRésumer les points de connaissance de la concurrence Java线程池使用了这个队列
- DelayQueue:DelayQueue(延迟队列)是一个任务定时周期的延迟执行的队列。根据指定的执行时间从小到大排序,否则根据插入到队列的先后排序。newScheduledThreadPool线程池使用了这个队列。
- PriorityBlockingQueue:PriorityBlockingQueue(优先级队列)是具有优先级的无界阻塞队列
- SynchronousQueue:SynchronousQueue(同步队列)是一个不存储元素的阻塞队列,每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态,吞吐量通常要高于LinkedBlockingQuene,newCachedThreadPool线程池使用了这个队列。
50.线程池提交execute和submit有什么区别?
- execute 用于提交不需要返回值的任务
threadsPool.execute(new Runnable() { @Override public void run() { // TODO Auto-generated method stub } });- submit()方法用于提交需要返回值的任务。线程池会返回一个future类型的对象,通过这个 future对象可以判断任务是否执行成功,并且可以通过future的get()方法来获取返回值
Future<object> future = executor.submit(harReturnValuetask); try { Object s = future.get(); } catch (InterruptedException e) { // 处理中断异常 } catch (ExecutionException e) { // 处理无法执行任务异常 } finally { // 关闭线程池 executor.shutdown();}</object>51.线程池怎么关闭知道吗?
可以通过调用线程池的
shutdown或shutdownNow方法来关闭线程池。它们的原理是遍历线程池中的工作线程,然后逐个调用线程的interrupt方法来中断线程,所以无法响应中断的任务可能永远无法终止。shutdown() 将线程池状态置为shutdown,并不会立即停止:
- 停止接收外部submit的任务
- 内部正在跑的任务和队列里等待的任务,会执行完
- 等到第二步完成后,才真正停止
shutdownNow() 将线程池状态置为stop。一般会立即停止,事实上不一定:
- 和shutdown()一样,先停止接收外部提交的任务
- 忽略队列里等待的任务
- 尝试将正在跑的任务interrupt中断
- 返回未执行的任务列表
shutdown 和shutdownnow简单来说区别如下:
- shutdownNow()能立即停止线程池,正在跑的和正在等待的任务都停下了。这样做立即生效,但是风险也比较大。
- shutdown()只是关闭了提交通道,用submit()是无效的;而内部的任务该怎么跑还是怎么跑,跑完再彻底停止线程池。
52.线程池的线程数应该怎么配置?
线程在Java中属于稀缺资源,线程池不是越大越好也不是越小越好。任务分为计算密集型、IO密集型、混合型。
- 计算密集型:大部分都在用CPU跟内存,加密,逻辑操作业务处理等。
- IO密集型:数据库链接,网络通讯传输等。
一般的经验,不同类型线程池的参数配置:
- 计算密集型一般推荐线程池不要过大,一般是CPU数 + 1,+1是因为可能存在页缺失(就是可能存在有些数据在硬盘中需要多来一个线程将数据读入内存)。如果线程池数太大,可能会频繁的 进行线程上下文切换跟任务调度。获得当前CPU核心数代码如下:
Runtime.getRuntime().availableProcessors();
- IO密集型:线程数适当大一点,机器的Cpu核心数*2。
- 混合型:可以考虑根绝情况将它拆分成CPU密集型和IO密集型任务,如果执行时间相差不大,拆分可以提升吞吐量,反之没有必要。
当然,实际应用中没有固定的公式,需要结合测试和监控来进行调整。
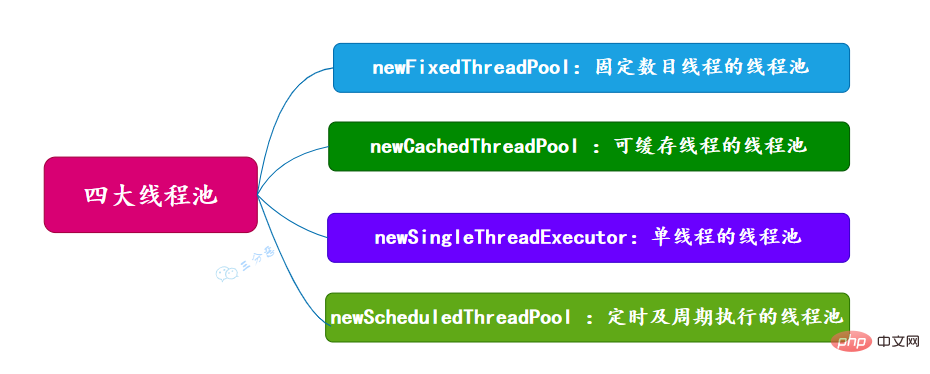
53.有哪几种常见的线程池?
面试常问,主要有四种,都是通过工具类Excutors创建出来的,需要注意,阿里巴巴《Java开发手册》里禁止使用这种方式来创建线程池。
newRésumer les points de connaissance de la concurrence Java (固定数目线程的线程池)
newCachedThreadPool (可缓存线程的线程池)
newSingleThreadExecutor (单线程的线程池)
newScheduledThreadPool (定时及周期执行的线程池)
54.能说一下四种常见线程池的原理吗?
前三种线程池的构造直接调用ThreadPoolExecutor的构造方法。
newSingleThreadExecutor
public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory) { return new FinalizableDelegatedExecutorService (new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<runnable>(), threadFactory)); }</runnable>线程池特点
- 核心线程数为1
- 最大线程数也为1
- 阻塞队列是无界队列LinkedBlockingQueue,可能会导致OOM
- keepAliveTime为0
工作流程:
- 提交任务
- 线程池是否有一条线程在,如果没有,新建线程执行任务
- 如果有,将任务加到阻塞队列
- 当前的唯一线程,从队列取任务,执行完一个,再继续取,一个线程执行任务。
适用场景
适用于串行执行任务的场景,一个任务一个任务地执行。
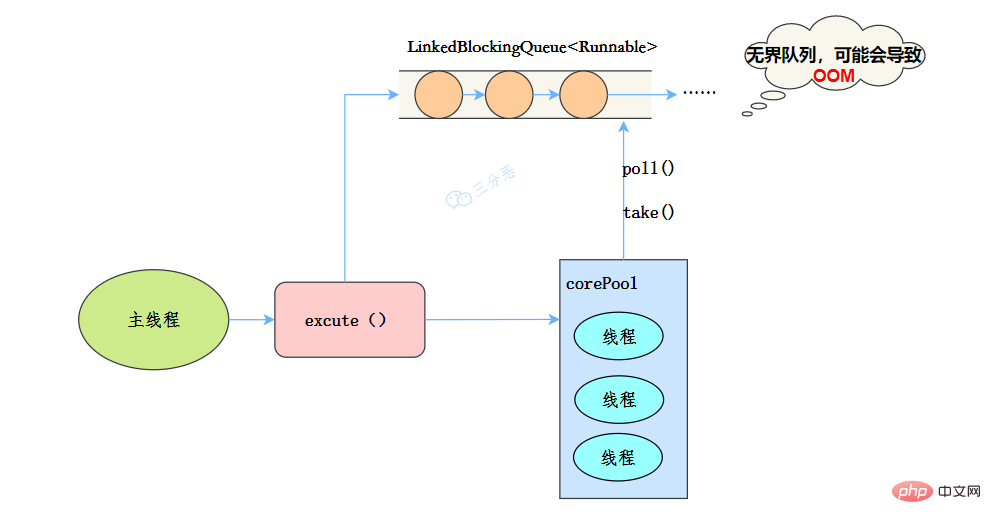
newRésumer les points de connaissance de la concurrence Java
public static ExecutorService newRésumer les points de connaissance de la concurrence Java(int nThreads, ThreadFactory threadFactory) { return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<runnable>(), threadFactory); }</runnable>线程池特点:
- 核心线程数和最大线程数大小一样
- 没有所谓的非空闲时间,即keepAliveTime为0
- 阻塞队列为无界队列LinkedBlockingQueue,可能会导致OOM
工作流程:
- 提交任务
- 如果线程数少于核心线程,创建核心线程执行任务
- 如果线程数等于核心线程,把任务添加到LinkedBlockingQueue阻塞队列
- 如果线程执行完任务,去阻塞队列取任务,继续执行。
使用场景
Résumer les points de connaissance de la concurrence Java 适用于处理CPU密集型的任务,确保CPU在长期被工作线程使用的情况下,尽可能的少的分配线程,即适用执行长期的任务。
newCachedThreadPool
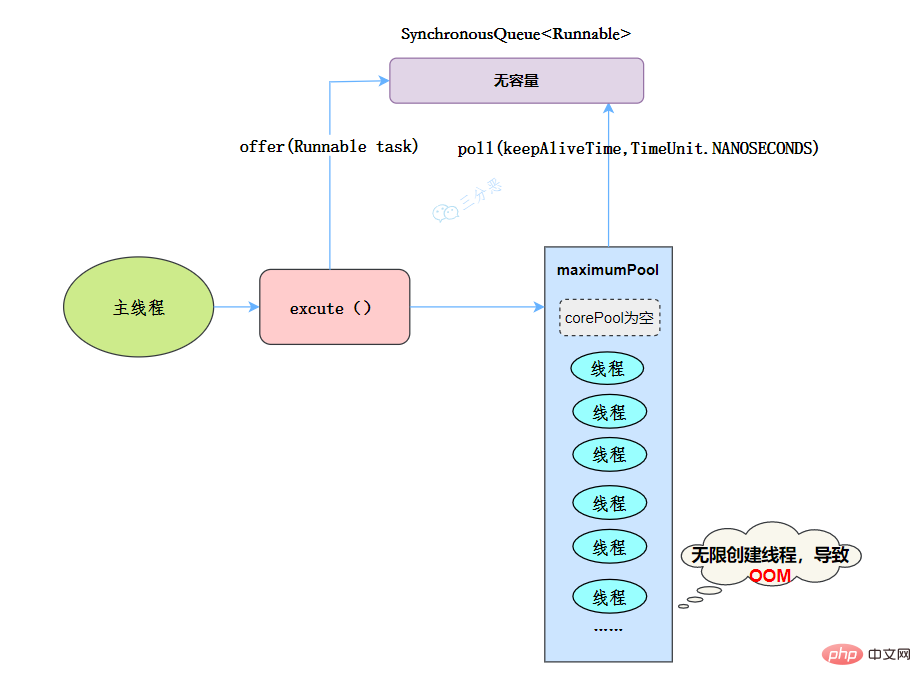
public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory) { return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<runnable>(), threadFactory); }</runnable>线程池特点:
- 核心线程数为0
- 最大线程数为Integer.MAX_VALUE,即无限大,可能会因为无限创建线程,导致OOM
- 阻塞队列是SynchronousQueue
- 非核心线程空闲存活时间为60秒
当提交任务的速度大于处理任务的速度时,每次提交一个任务,就必然会创建一个线程。极端情况下会创建过多的线程,耗尽 CPU 和内存资源。由于空闲 60 秒的线程会被终止,长时间保持空闲的 CachedThreadPool 不会占用任何资源。
工作流程:
- 提交任务
- 因为没有核心线程,所以任务直接加到SynchronousQueue队列。
- 判断是否有空闲线程,如果有,就去取出任务执行。
- 如果没有空闲线程,就新建一个线程执行。
- 执行完任务的线程,还可以存活60秒,如果在这期间,接到任务,可以继续活下去;否则,被销毁。
适用场景
用于并发执行大量短期的小任务。
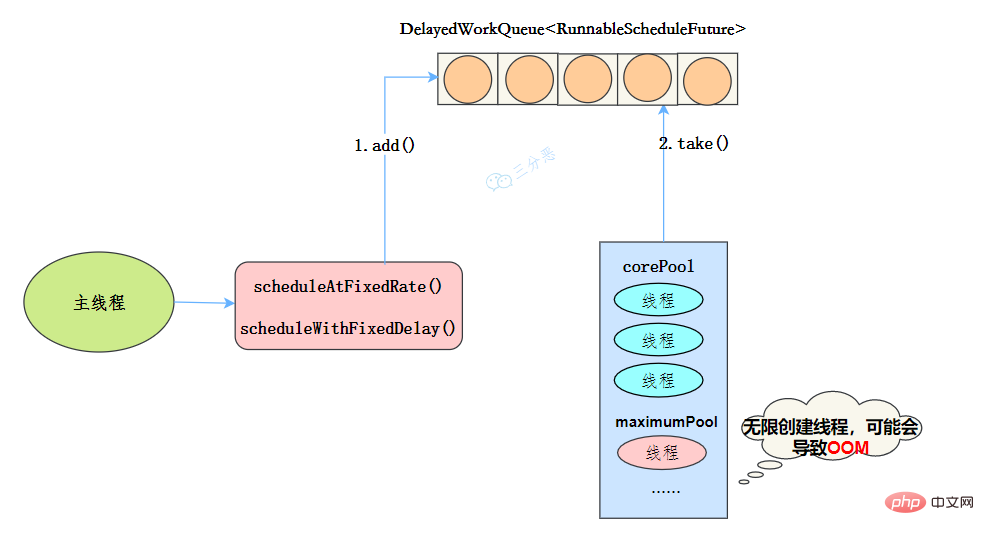
newScheduledThreadPool
public ScheduledThreadPoolExecutor(int corePoolSize) { super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS, new DelayedWorkQueue()); }线程池特点
- 最大线程数为Integer.MAX_VALUE,也有OOM的风险
- 阻塞队列是DelayedWorkQueue
- keepAliveTime为0
- scheduleAtFixedRate() :按某种速率周期执行
- scheduleWithFixedDelay():在某个延迟后执行
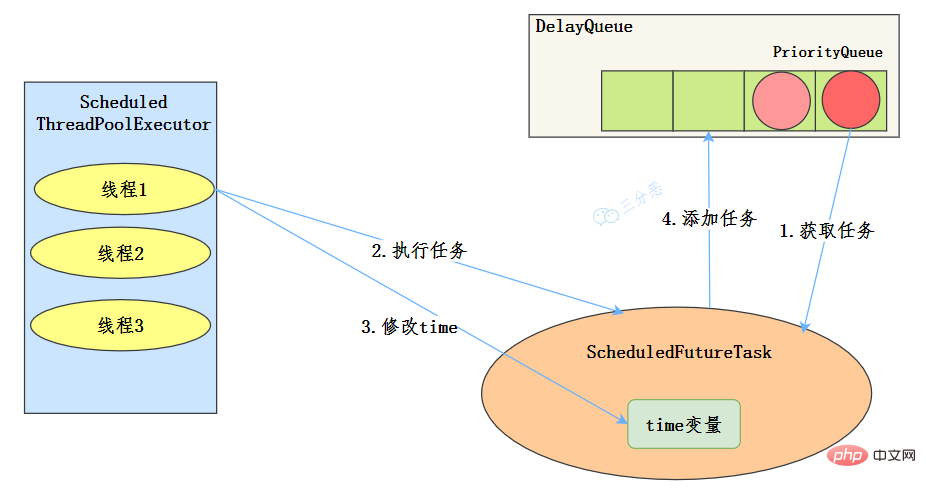
工作机制
- 线程从DelayQueue中获取已到期的ScheduledFutureTask(DelayQueue.take())。到期任务是指ScheduledFutureTask的time大于等于当前时间。
- 线程执行这个ScheduledFutureTask。
- 线程修改ScheduledFutureTask的time变量为下次将要被执行的时间。
- 线程把这个修改time之后的ScheduledFutureTask放回DelayQueue中(DelayQueue.add())。
使用场景
周期性执行任务的场景,需要限制线程数量的场景
使用无界队列的线程池会导致什么问题吗?
例如newRésumer les points de connaissance de la concurrence Java使用了无界的阻塞队列LinkedBlockingQueue,如果线程获取一个任务后,任务的执行时间比较长,会导致队列的任务越积越多,导致机器内存使用不停飙升,最终导致OOM。
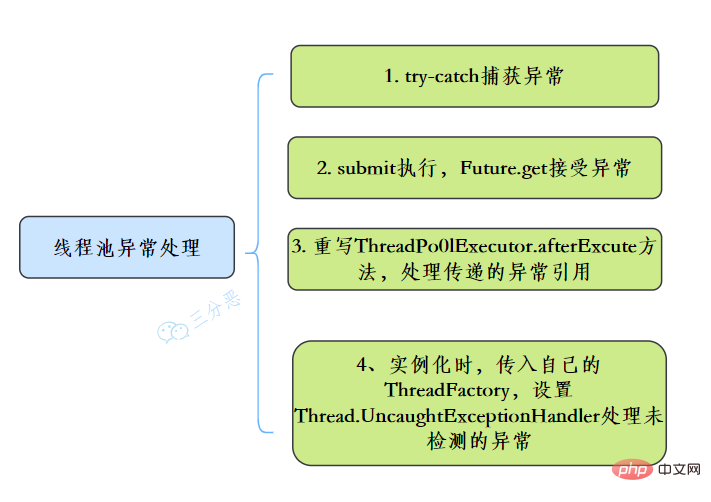
55.线程池异常怎么处理知道吗?
在使用线程池处理任务的时候,任务代码可能抛出RuntimeException,抛出异常后,线程池可能捕获它,也可能创建一个新的线程来代替异常的线程,我们可能无法感知任务出现了异常,因此我们需要考虑线程池异常情况。
常见的异常处理方式:
56.能说一下线程池有几种状态吗?
线程池有这几个状态:RUNNING,SHUTDOWN,STOP,TIDYING,TERMINATED。
//线程池状态 private static final int RUNNING = -1 <p>线程池各个状态切换图:</p><p><img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/000/000/067/47690a2c7799a7bd0d10ed5490da3a7b-77.png" class="lazy" alt="Résumer les points de connaissance de la concurrence Java"></p><p><strong>RUNNING</strong></p>
- 该状态的线程池会接收新任务,并处理阻塞队列中的任务;
- 调用线程池的shutdown()方法,可以切换到SHUTDOWN状态;
- 调用线程池的shutdownNow()方法,可以切换到STOP状态;
SHUTDOWN
- 该状态的线程池不会接收新任务,但会处理阻塞队列中的任务;
- 队列为空,并且线程池中执行的任务也为空,进入TIDYING状态;
STOP
- 该状态的线程不会接收新任务,也不会处理阻塞队列中的任务,而且会中断正在运行的任务;
- 线程池中执行的任务为空,进入TIDYING状态;
TIDYING
- 该状态表明所有的任务已经运行终止,记录的任务数量为0。
- terminated()执行完毕,进入TERMINATED状态
TERMINATED
- 该状态表示线程池彻底终止
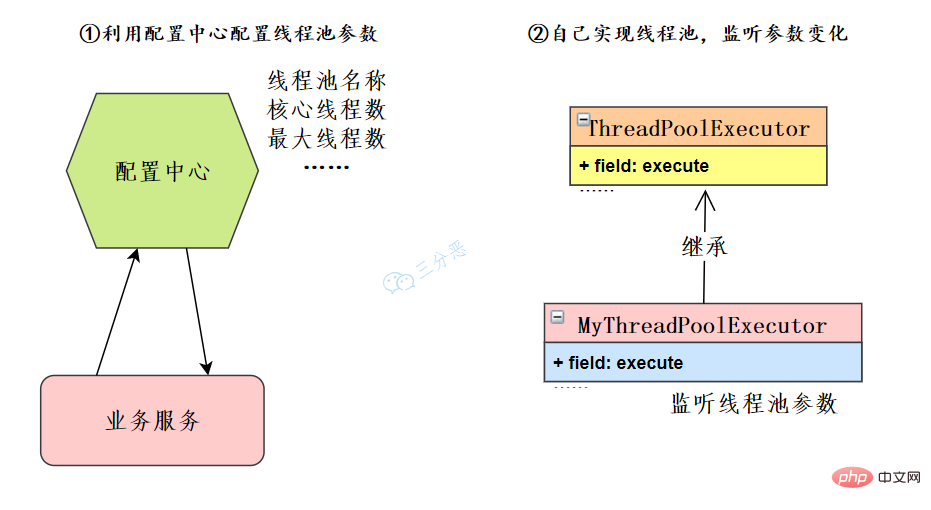
57.线程池如何实现参数的动态修改?
线程池提供了几个 setter方法来设置线程池的参数。
这里主要有两个思路:
Dans notre architecture de microservices, vous pouvez utiliser des centres de configuration tels que Nacos, Apollo, etc., ou vous pouvez développer votre propre centre de configuration. Le service métier lit la configuration du pool de threads et obtient l'instance de pool de threads correspondante pour modifier les paramètres du pool de threads.
Si vous limitez l'utilisation du centre de configuration, vous pouvez également étendre vous-même ThreadPoolExecutor, réécrire les méthodes, surveiller les modifications des paramètres du pool de threads et modifier dynamiquement les paramètres du pool de threads.
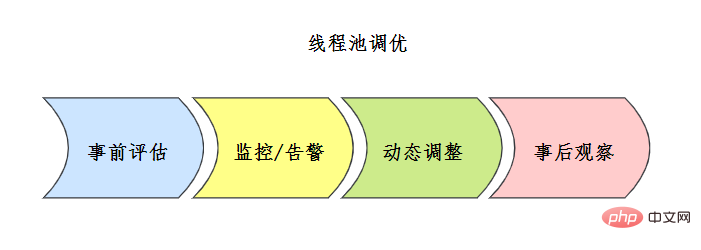
Connaissez-vous le réglage des pools de threads ?
Il n'y a pas de formule fixe pour la configuration du pool de threads. Habituellement, le pool de threads sera évalué dans une certaine mesure au préalable. Les plans d'évaluation courants sont les suivants :
Des tests complets doivent être effectués avant la mise en ligne, et un test complet doit être effectué. Un mécanisme complet de surveillance du pool de threads doit être établi après la mise en ligne. Combinez le mécanisme de surveillance et d'alarme pendant le processus pour analyser les problèmes du pool de threads, ou optimisez les points et ajustez la configuration en conjonction avec le mécanisme de configuration des paramètres dynamiques du pool de threads. Veuillez observer attentivement par la suite et procéder à des ajustements à tout moment.
Pour les cas de réglage spécifiques, veuillez vous référer au [7] Meituan Technology Blog. 58. Pouvez-vous concevoir et implémenter un pool de threads ? Cette question apparaît fréquemment dans les interviews d'AliVous pouvez consulter le principe de mise en œuvre du pool de threads Si quelqu'un avait déjà parlé de pools de threads comme celui-ci, j'aurais dû le comprendre depuis longtemps ! , bien sûr, nous l'implémentons nous-mêmes, il nous suffit de comprendre le processus principal du pool de threads - référence [6] :
Notre propre implémentation consiste à terminer ce processus principal :- Il y a N threads de travail dans le pool de threads
- Soumettez la tâche au pool de threads pour qu'elle soit exécutée
- Si le pool de threads est plein, mettez la tâche dans la file d'attente
- Enfin, lorsqu'il y a du temps libre, mettez la tâche dans la file d'attente pour l'exécuter
De cette façon, une classe qui implémente le processus principal du pool de threads est terminée. 59. Que dois-je faire si l'exécution du pool de threads sur une seule machine est désactivée ? Nous pouvons gérer les transactions pour les tâches en cours de traitement et les files d'attente bloquées ou conserver les tâches dans les files d'attente bloquées, et lorsqu'il y a une panne de courant ou une panne du système et que l'opération ne peut pas continuer, elle peut être annulée en consultant le journalTraitement qui ont été exécutées avec succès. Réexécutez ensuite toute la file d’attente de blocage.正在处理的已经执行成功的操作。然后重新执行整个阻塞队列。也就是说,对阻塞队列持久化;正在处理任务事务控制;断电之后正在处理任务的回滚,通过日志恢复该次操作;服务器重启后阻塞队列中的数据再加载。
并发容器和框架
关于一些并发容器,可以去看看 面渣逆袭:Java集合连环三十问 ,里面有
CopyOnWriteList和ConcurrentHashMapEn d'autres termes, la file d'attente de blocage est conservée ; le contrôle des transactions de la tâche est en cours de traitement ; la restauration de la tâche est en cours de traitement après une panne de courant et l'opération est restaurée via le journal, les données de la file d'attente de blocage sont rechargées ; le serveur est redémarré.Concurrent Containers and Frameworks
Pour certains conteneurs simultanés, vous pouvez consulter Counterattack : Java Collection Thirty Questions, qui comprend
CopyOnWriteListetConcurrentHashMapQuestions et réponses sur ces deux classes de conteneurs thread-safe. .60. Comprenez-vous le framework Fork/Join ?
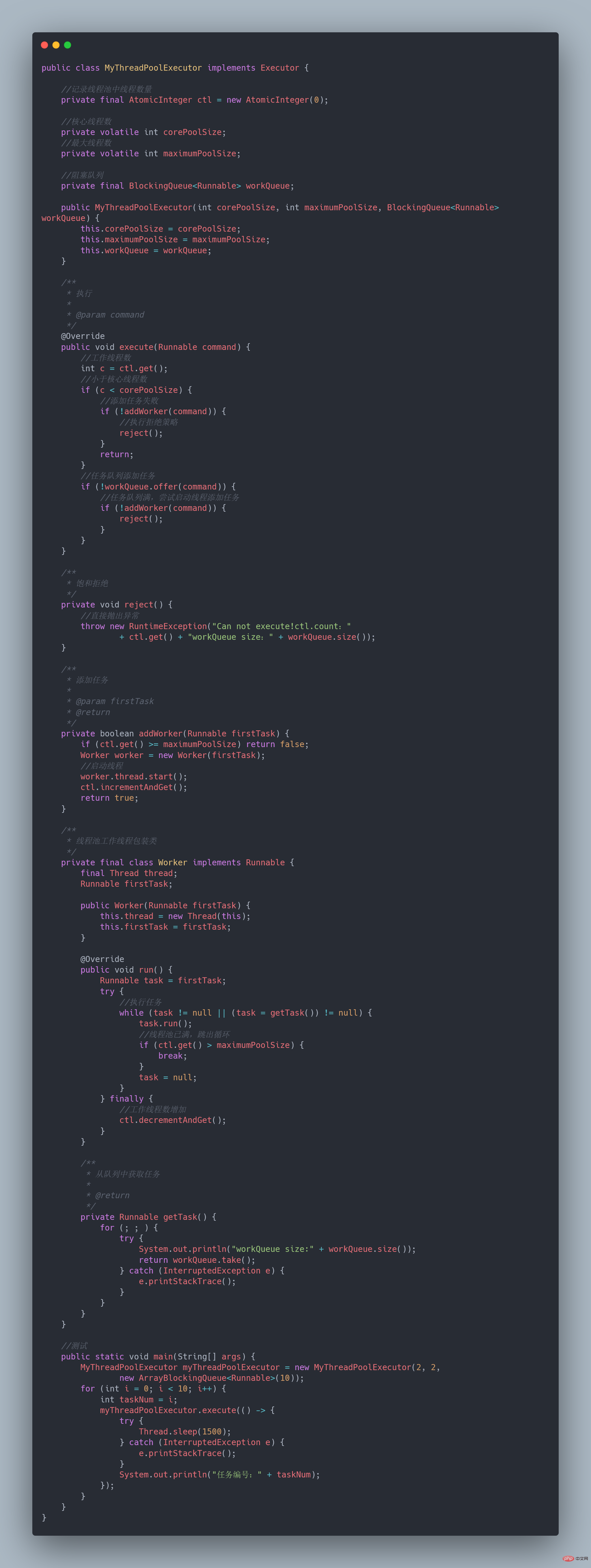
Le framework Fork/Join est un framework fourni par Java7 pour exécuter des tâches en parallèle. C'est un framework qui divise les grandes tâches en plusieurs petites tâches, et résume enfin les résultats de chaque petite tâche pour obtenir les résultats de la grande tâche. Pour maîtriser le framework Fork/Join, vous devez d'abord comprendre deux points, Divide and Conquer et
Work Stealing Algorithm.
Divide and ConquerLa définition du framework Fork/Join incarne en fait l'idée de diviser pour mieux régner : décomposer un problème de taille N en K sous-problèmes de taille plus petite, qui sont indépendants les uns des autres et ont les mêmes propriétés que le problème d'origine. En trouvant la solution au sous-problème, vous pouvez obtenir la solution au problème initial.
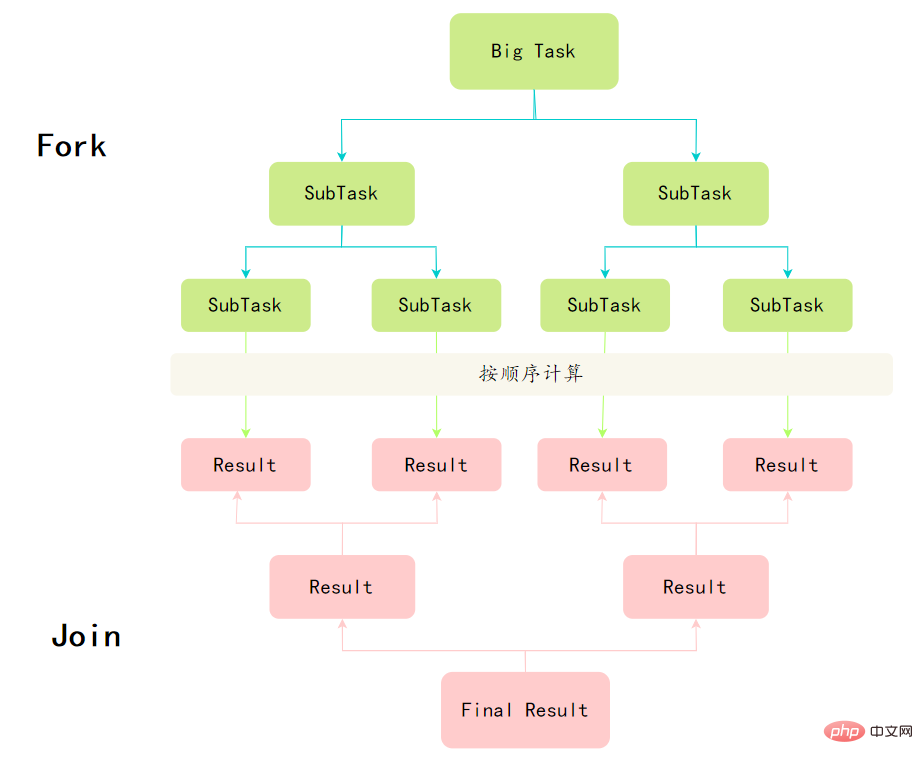
Algorithme de vol de travail
Divisez une grande tâche en plusieurs petites tâches, placez ces petites tâches dans différentes files d'attente et créez des threads séparés pour exécuter les tâches dans la file d'attente. Ensuite, le problème survient, certains threads travaillent dur et certains threads fonctionnent lentement. Le thread qui a terminé son travail ne peut pas rester inactif ; il doit être autorisé à travailler pour le thread qui n'a pas terminé son travail. Il vole une tâche dans la file d'attente d'autres threads pour l'exécuter. C'est ce qu'on appelle le
vol de travail.
Lorsque le vol de travail se produit, ils accéderont à la même file d'attente. Afin de réduire la concurrence entre le fil de tâche volé et le fil de tâche volé, la tâche utilise généralement une file d'attente à double extrémité. Le fil de tâche volé commence toujours par la tête. de la file d'attente à double extrémité Take, et le thread qui vole la tâche prend toujours la tâche de la queue de la file d'attente à double extrémité pour l'exécution.
🎜Regardez un exemple d'application du framework Fork/Join, calculez la somme entre 1~n : 1+2+3+…+n🎜- 设置一个分割阈值,任务大于阈值就拆分任务
- 任务有结果,所以需要继承RecursiveTask
public class CountTask extends RecursiveTask<integer> { private static final int THRESHOLD = 16; // 阈值 private int start; private int end; public CountTask(int start, int end) { this.start = start; this.end = end; } @Override protected Integer compute() { int sum = 0; // 如果任务足够小就计算任务 boolean canCompute = (end - start) result = forkJoinPool.submit(task); try { System.out.println(result.get()); } catch (InterruptedException e) { } catch (ExecutionException e) { } } }</integer>ForkJoinTask与一般Task的主要区别在于它需要实现compute方法,在这个方法里,首先需要判断任务是否足够小,如果足够小就直接执行任务。如果比较大,就必须分割成两个子任务,每个子任务在调用fork方法时,又会进compute方法,看看当前子任务是否需要继续分割成子任务,如果不需要继续分割,则执行当前子任务并返回结果。使用join方法会等待子任务执行完并得到其结果。
推荐学习:《java教程》
 先简单了解一下CLH:Craig、Landin and Hagersten 队列,是 单向链表实现的队列。申请线程只在本地变量上自旋,它不断轮询前驱的状态,如果发现 前驱节点释放了锁就结束自旋
先简单了解一下CLH:Craig、Landin and Hagersten 队列,是 单向链表实现的队列。申请线程只在本地变量上自旋,它不断轮询前驱的状态,如果发现 前驱节点释放了锁就结束自旋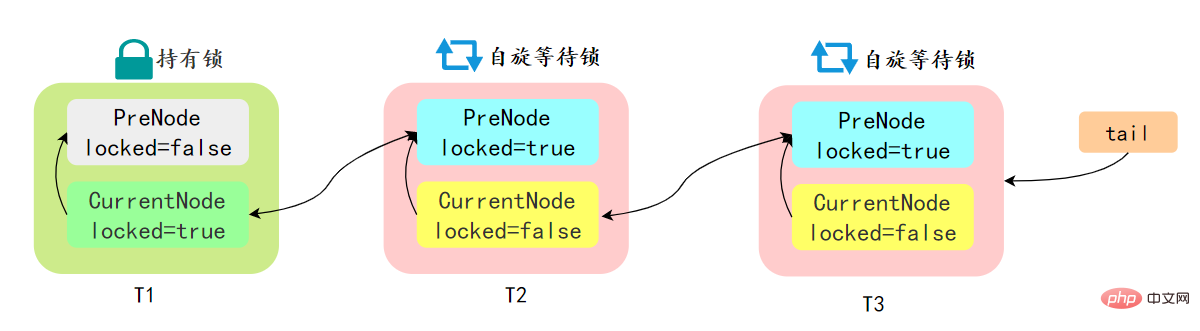






![JDK Résumer les points de connaissance de la concurrence Java设置接口来源参考[7]](https://img.php.cn/upload/article/000/000/067/6094178ce7a357b1c3eb573fc35e4d09-78.png)
![线程池评估方案 来源参考[7]](https://img.php.cn/upload/article/000/000/067/b8171ba02ccd61fc1cad003f65eae9c1-80.png)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!