
Maison >Java >javaDidacticiel >Explication détaillée avec images et texte ! Qu'est-ce que le modèle de mémoire Java
Explication détaillée avec images et texte ! Qu'est-ce que le modèle de mémoire Java

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2022-03-22 18:00:411764parcourir
Cet article vous apporte des connaissances liées à java, qui présentent principalement des problèmes liés au modèle de mémoire, notamment pourquoi il existe un modèle de mémoire, la programmation simultanée et la relation entre la zone mémoire et la mémoire matérielle, etc. J'espère qu'il sera utile pour tout le monde utile.

Étude recommandée : "Tutoriel Java"
Lors des entretiens, les intervieweurs aiment souvent demander : "Qu'est-ce que le modèle de mémoire Java (JMM) ?" 』
L'intervieweur était aux anges. Il venait de mémoriser cette question : "La mémoire Java est principalement divisée en cinq parties principales : tas, zone de méthodes, pile de machines virtuelles, pile de méthodes locales, registre PC, balabala..."
Le L'intervieweur a souri d'un air entendu, révélant une lumière : "D'accord, l'interview d'aujourd'hui est là en premier, retournez en arrière et attendez la notification"
De manière générale, lorsque vous entendez l'expression "attendre la notification", cette interview sera probablement cool. Pourquoi? Parce que l'intervieweur a mal compris le concept, l'intervieweur a voulu examiner JMM, mais dès qu'il a entendu les mots-clés Java Memory, il a commencé à réciter l'essai à huit pattes. Il existe une grande différence entre le modèle de mémoire Java (JMM) et la zone de mémoire d'exécution Java. Ne partez pas et continuez à lire. Java内存这几个关键字就开始背诵八股文了。Java内存模型(JMM)和Java运行时内存区域区别可大了呢,不要走开接着往下看,答应我要看完。
1. 为什么要有内存模型?
要想回答这个问题,我们需要先弄懂传统计算机硬件内存架构。好了,我要开始画图了。
1.1. 硬件内存架构

(1)CPU
去过机房的同学都知道,一般在大型服务器上会配置多个CPU,每个CPU还会有多个核,这就意味着多个CPU或者多个核可以同时(并发)工作。如果使用Java 起了一个多线程的任务,很有可能每个 CPU 都会跑一个线程,那么你的任务在某一刻就是真正并发执行了。
(2)CPU Register
CPU Register也就是 CPU 寄存器。CPU 寄存器是 CPU 内部集成的,在寄存器上执行操作的效率要比在主存上高出几个数量级。
(3)CPU Cache Memory
CPU Cache Memory也就是 CPU 高速缓存,相对于寄存器来说,通常也可以成为 L2 二级缓存。相对于硬盘读取速度来说内存读取的效率非常高,但是与 CPU 还是相差数量级,所以在 CPU 和主存间引入了多级缓存,目的是为了做一下缓冲。
(4)Main Memory
Main Memory 就是主存,主存比 L1、L2 缓存要大很多。
注意:部分高端机器还有 L3 三级缓存。
1.2. 缓存一致性问题
由于主存与 CPU 处理器的运算能力之间有数量级的差距,所以在传统计算机内存架构中会引入高速缓存来作为主存和处理器之间的缓冲,CPU 将常用的数据放在高速缓存中,运算结束后 CPU 再讲运算结果同步到主存中。
使用高速缓存解决了 CPU 和主存速率不匹配的问题,但同时又引入另外一个新问题:缓存一致性问题。
在多CPU的系统中(或者单CPU多核的系统),每个CPU内核都有自己的高速缓存,它们共享同一主内存(Main Memory)。当多个CPU的运算任务都涉及同一块主内存区域时,CPU 会将数据读取到缓存中进行运算,这可能会导致各自的缓存数据不一致。
因此需要每个 CPU 访问缓存时遵循一定的协议,在读写数据时根据协议进行操作,共同来维护缓存的一致性。这类协议有 MSI、MESI、MOSI、和 Dragon Protocol 等。
1.3. 处理器优化和指令重排序
为了提升性能在 CPU 和主内存之间增加了高速缓存,但在多线程并发场景可能会遇到缓存一致性问题
1. Pourquoi avons-nous besoin d'un modèle de mémoire ?
Pour répondre à cette question, nous devons d'abord comprendre l'architecture traditionnelle de la mémoire matérielle informatique. Bon, je vais commencer à dessiner.1.1. Architecture de la mémoire matérielle
(1) CPU
Les étudiants qui sont allés dans la salle informatique savent que généralement plusieurs processeurs sont configurés sur de grands serveurs, et chaque processeur possède également plusieurs cœurs. Cela signifie que plusieurs processeurs ou plusieurs cœurs peuvent fonctionner en même temps (simultanément). Si vous utilisez Java pour démarrer une tâche multithread, il est très probable que chaque processeur exécute un thread, et votre tâche sera alors véritablement exécutée simultanément à un certain moment.  (2) Registre CPU
(2) Registre CPU
Le registre CPU est le registre CPU. Les registres du processeur sont intégrés à l'intérieur du processeur et l'efficacité des opérations sur les registres est plusieurs ordres de grandeur supérieure à celle sur la mémoire principale. (3) Mémoire cache du processeur🎜🎜La mémoire cache du processeur est le cache du processeur. Par rapport au registre, elle peut généralement également devenir le cache L2 niveau 2. Par rapport à la vitesse de lecture du disque dur, l'efficacité de la lecture de la mémoire est très élevée, mais elle reste néanmoins d'un ordre de grandeur différent de celle du CPU. Par conséquent, un cache multi-niveaux est introduit à cet effet entre le CPU et la mémoire principale. de mise en mémoire tampon. 🎜🎜(4) Mémoire principale🎜🎜La mémoire principale est la mémoire principale, qui est beaucoup plus grande que les caches L1 et L2. 🎜🎜Remarque : Certaines machines haut de gamme disposent également d'un cache L3 niveau 3. 🎜1.2. Problème de cohérence du cache
🎜En raison de l'écart d'ordre de grandeur entre la puissance de calcul de la mémoire principale et du processeur CPU, un cache est introduit dans l'architecture de mémoire informatique traditionnelle pour servir de mémoire principale. et processeur Le processeur place les données couramment utilisées dans le cache et, une fois l'opération terminée, le processeur synchronise les résultats de l'opération avec la mémoire principale. 🎜🎜L'utilisation du cache résout le problème de non-concordance du taux de CPU et de la mémoire principale, mais introduit en même temps un autre nouveau problème : le problème de cohérence du cache. 🎜1.3. Optimisation du processeur et réorganisation des instructions
🎜Afin d'améliorer les performances, un cache est ajouté entre le CPU et la mémoire principale, mais dans des scénarios simultanés multithreads, desproblèmes de cohérence du cache peuvent être rencontrés.. Existe-t-il un moyen d'améliorer encore l'efficacité d'exécution du processeur ? La réponse est : l’optimisation du processeur. 🎜🎜🎜Afin de maximiser la pleine utilisation de l'unité de calcul à l'intérieur du processeur, le processeur exécutera le code d'entrée dans le désordre. Il s'agit d'une optimisation du processeur. 🎜🎜🎜En plus du processeur qui optimise le code, de nombreux compilateurs de langages de programmation modernes effectueront également des optimisations similaires. Par exemple, le compilateur juste à temps (JIT) de Java effectuera la réorganisation des instructions. 🎜🎜🎜🎜🎜L'optimisation du processeur est en fait un type de réorganisation. Pour résumer, la réorganisation peut être divisée en trois types : 🎜
- Réorganisation optimisée du compilateur. Le compilateur peut réorganiser l'ordre d'exécution des instructions sans modifier la sémantique d'un programme monothread.
- Réorganisation parallèle au niveau de l'instruction. Les processeurs modernes utilisent le parallélisme au niveau des instructions pour chevaucher l'exécution de plusieurs instructions. S'il n'y a pas de dépendances de données, le processeur peut modifier l'ordre dans lequel les instructions correspondent aux instructions machine.
- Réorganisation du système de mémoire. Étant donné que le processeur utilise du cache et des tampons de lecture et d'écriture, les opérations de chargement et de stockage peuvent sembler exécutées dans le désordre.
2. Problèmes de programmation simultanés
Les nombreux éléments liés au matériel mentionnés ci-dessus peuvent être un peu confus. Après un si grand cercle, ces choses ont-elles quelque chose à voir avec le modèle de mémoire Java ? Ne vous inquiétez pas, regardons lentement.
Les étudiants qui connaissent la concurrence Java doivent être familiers avec ces trois problèmes : "problème de visibilité", "problème d'atomicité" et "problème d'ordre". Si vous examinez ces trois problèmes d'un niveau plus approfondi, ils sont en réalité causés par la « cohérence du cache », « l'optimisation du processeur » et la « réorganisation des instructions » mentionnées ci-dessus.
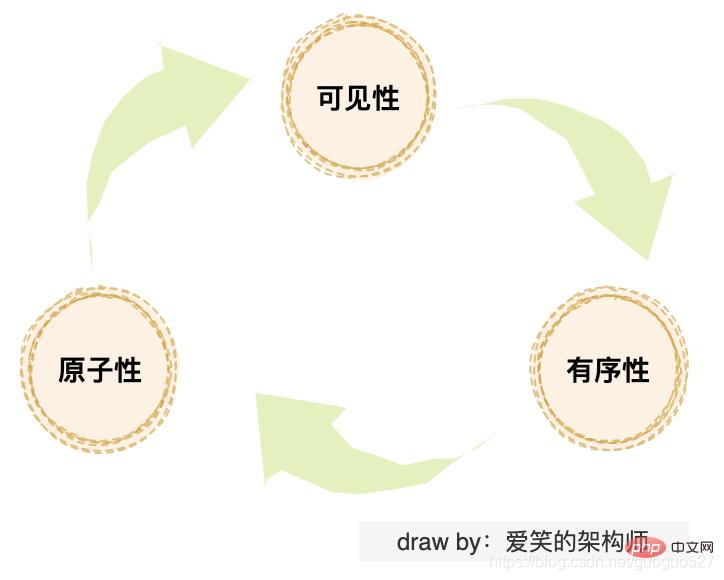
Le problème de cohérence du cache est en fait un problème de visibilité. L'optimisation du processeur peut entraîner des problèmes d'atomicité, et la réorganisation des instructions peut entraîner des problèmes d'ordre. Vérifiez si elles sont toutes connectées.
Les problèmes doivent toujours être résolus, alors quelle est la solution ? Tout d'abord, j'ai pensé à un moyen simple et grossier. Supprimer le cache et laisser le processeur interagir directement avec la mémoire principale résout le problème de visibilité. La désactivation de l'optimisation du processeur et de la réorganisation des instructions résout les problèmes d'atomicité et d'ordre, mais cela reviendra à avant. libération du jour au lendemain, évidemment indésirable.
Les responsables techniques ont donc pensé à définir un ensemble de modèles de mémoire sur des machines physiques pour standardiser les opérations de lecture et d'écriture en mémoire. Le modèle de mémoire utilise principalement deux manières de résoudre les problèmes de concurrence : 限制处理器优化和使用内存屏障.
3. Modèle de mémoire Java
Avec le même ensemble de spécifications de modèle de mémoire, différents langages peuvent présenter des différences dans l'implémentation. Ensuite, nous nous concentrerons sur les principes d’implémentation du modèle de mémoire Java.
3.1. La relation entre la zone mémoire d'exécution Java et la mémoire matérielle
Les étudiants qui connaissent la JVM savent que la zone mémoire d'exécution de la JVM est fragmentée et divisée en piles, tas, etc. . Dans l'architecture de mémoire matérielle traditionnelle, il n'y a pas de concept de pile et de tas. 
On peut voir sur la figure que la pile et le tas existent à la fois dans le cache et dans la mémoire principale, il n'y a donc pas de relation directe entre les deux.
3.2. La relation entre les threads Java et la mémoire principale
Le modèle de mémoire Java est une spécification qui définit beaucoup de choses :
- Toutes les variables sont stockées dans la mémoire principale (Main Memory).
- Chaque thread possède une mémoire locale privée (mémoire locale) et la mémoire locale stocke une copie de la variable partagée que le thread peut lire/écrire.
- Toutes les opérations sur les variables par les threads doivent être effectuées dans la mémoire locale et ne peuvent pas lire ou écrire directement la mémoire principale.
- Différents threads ne peuvent pas accéder directement aux variables dans la mémoire locale de chacun.
La lecture du texte est trop ennuyeuse, j'ai dessiné une autre image : 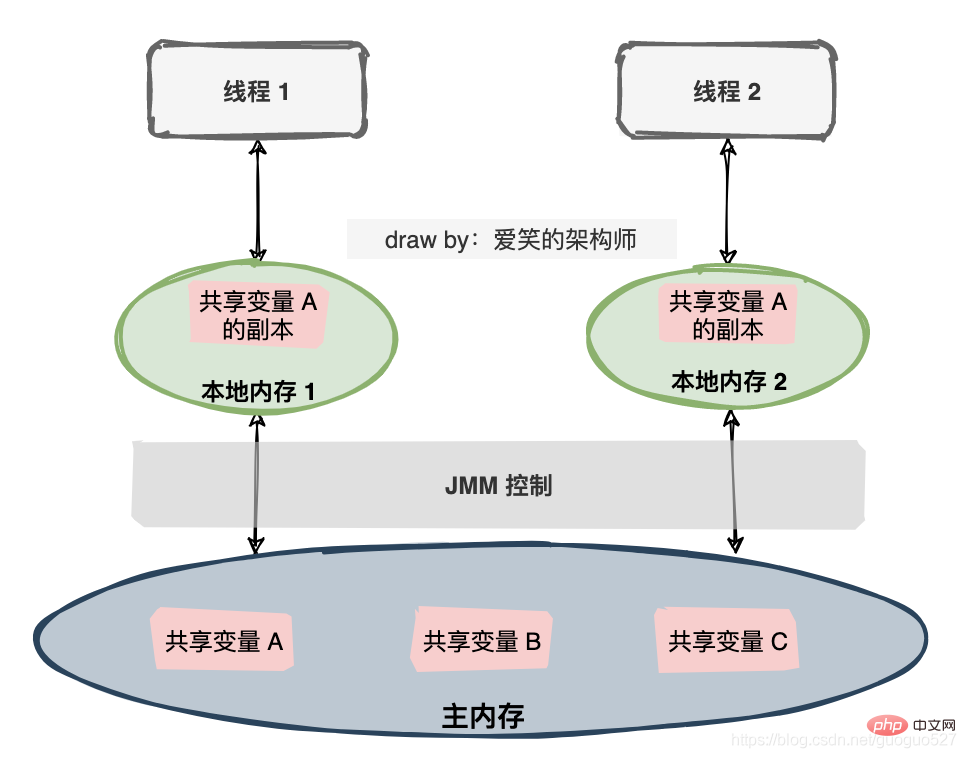
3.3. Communication inter-thread
Si deux threads opèrent sur une variable partagée, la valeur initiale de la variable partagée est 1, et chaque thread les deux variables sont incrémentés de 1 et la valeur attendue de la variable partagée est 3. Il existe une série d'opérations sous la spécification JMM. 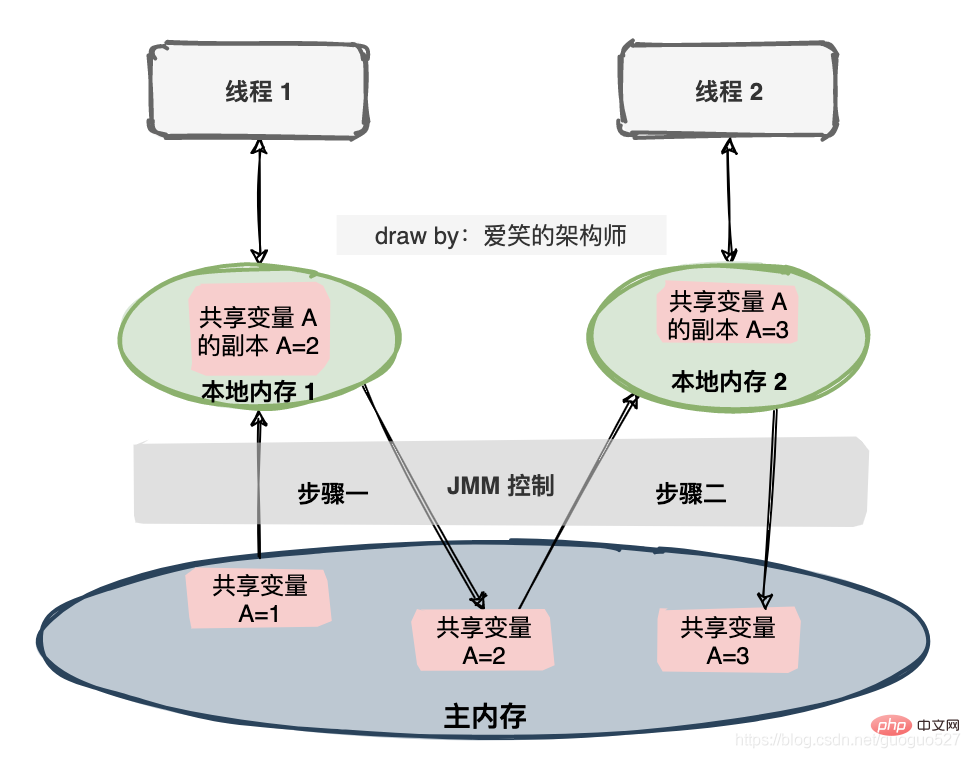
Afin de mieux contrôler l'interaction entre la mémoire principale et la mémoire locale, le modèle de mémoire Java définit huit opérations à réaliser :
- verrouillage : Verrouiller. Agit sur les variables de la mémoire principale, marquant une variable comme exclusive à un thread.
- déverrouiller : Déverrouiller. Agit sur les variables de la mémoire principale pour libérer une variable verrouillée afin que la variable libérée puisse être verrouillée par d'autres threads.
- lire : lire. Agit sur les variables de la mémoire principale et transfère une valeur variable de la mémoire principale vers la mémoire de travail du thread pour les actions de chargement ultérieures
- load : Load. Agit sur les variables de la mémoire de travail, ce qui place la valeur de la variable obtenue de la mémoire principale par l'opération de lecture dans une copie de la variable en mémoire de travail.
- utilisation : utiliser. Les variables qui agissent sur la mémoire de travail transmettent une valeur de variable dans la mémoire de travail au moteur d'exécution. Cette opération sera effectuée chaque fois que la machine virtuelle rencontrera une instruction de bytecode qui nécessite la valeur de la variable.
- assigner : mission. Agit sur une variable en mémoire de travail. Il attribue une valeur reçue du moteur d'exécution à une variable en mémoire de travail. Cette opération est effectuée chaque fois que la machine virtuelle rencontre une instruction de bytecode qui attribue une valeur à la variable.
- magasin : stockage. Agit sur les variables de la mémoire de travail et transfère la valeur d'une variable de la mémoire de travail vers la mémoire principale pour les opérations d'écriture ultérieures.
- écrire : écrire. Agit sur les variables de la mémoire principale, ce qui transfère l'opération de stockage de la valeur d'une variable de la mémoire de travail vers une variable de la mémoire principale.
Remarque : La mémoire de travail signifie également la mémoire locale.
4. Un résumé d'attitude
En raison de la différence d'ordre de grandeur entre la vitesse du processeur et la mémoire principale, j'ai pensé à introduire l'architecture de mémoire matérielle traditionnelle du cache multi-niveaux pour résoudre le problème. sert d'espace entre le processeur et la mémoire principale. La mise en mémoire tampon améliore les performances globales. Cela résout le problème de la faible vitesse, mais pose également le problème de la cohérence du cache.
Les données existent à la fois dans le cache et dans la mémoire principale Si elles ne sont pas standardisées, elles provoqueront inévitablement un désastre, le modèle de mémoire est donc abstrait sur les machines traditionnelles.
Le langage Java a lancé la spécification JMM basée sur le modèle de mémoire. Le but est de résoudre le problème de l'incohérence des données de la mémoire locale, des instructions de code de réorganisation du compilateur et du code de réorganisation du processeur lorsque plusieurs threads communiquent via la mémoire partagée. par exécution dans le désordre, etc.
Afin de contrôler plus précisément l'interaction entre la mémoire de travail et la mémoire principale, JMM définit également huit opérations : lock, unlock, read, load,use,assign, store, write.
Apprentissage recommandé : "Tutoriel d'apprentissage Java"
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment obtenir les paramètres d'URL en JavaScript ? Explication détaillée de 4 méthodes courantes
- Résumer et organiser le contrôle des processus d'apprentissage JAVA
- Quel est le code de la divisibilité javascript par cinq ?
- Vous aider à obtenir des objets JavaScript
- Explication graphique détaillée des structures de données et des algorithmes Java