
Maison >base de données >Redis >Résumez 10 conseils pour améliorer les performances de Redis
Résumez 10 conseils pour améliorer les performances de Redis

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2022-03-07 17:55:093560parcourir
Cet article vous apporte des connaissances pertinentes sur Redis Il présente principalement quelques conseils pour améliorer les performances de Redis, notamment le pipeline, l'activation du multithread IO, l'évitement des grosses clés, etc.

Apprentissage recommandé : Tutoriel Redis
01 Utilisation du pipeline
Redis est un serveur TCP basé sur le modèle requête-réponse. Signifie RTT (temps d'aller-retour) à requête unique, dépend des conditions actuelles du réseau . Cela se traduit par une seule requête Redis potentiellement très rapide, par exemple sur une carte réseau en boucle locale. Peut être très lent, par exemple dans un environnement réseau médiocre.
D'un autre côté, chaque requête-réponse Redis implique des appels système de lecture et d'écriture. Il peut même déclencher plusieurs appels système epoll_wait (plateforme Linux). Cela amène Redis à basculer constamment entre le mode utilisateur et le mode noyau.
static int connSocketRead(connection *conn, void *buf, size_t buf_len) {
// read 系统调用
int ret = read(conn->fd, buf, buf_len);}static int connSocketWrite(connection *conn, const void *data, size_t data_len) {
// write 系统调用
int ret = write(conn->fd, data, data_len);}int aeProcessEvents(aeEventLoop *eventLoop, int flags) {
// 事件触发,Linux 下为 epoll_wait 系统调用
numevents = aeApiPoll(eventLoop, tvp);}
Alors, comment économiser le temps d'aller-retour et les appels système ? Le traitement par lots est une bonne idée.
A cet effet, Redis fournit "pipeline". Le principe du pipeline est très simple. Plusieurs commandes sont regroupées en « une seule commande » et envoyées. Une fois que Redis l'a reçu, il l'analyse en plusieurs commandes à exécuter. Enfin, plusieurs résultats sont empaquetés et renvoyés.
「Pipeline peut améliorer efficacement les performances de Redis」.
Cependant, il y a quelques points auxquels vous devez faire attention lorsque vous utilisez un pipeline
"Le pipeline ne peut pas garantir l'atomicité". Lors de l'exécution d'une commande pipeline, des commandes initiées par d'autres clients peuvent être exécutées. N'oubliez pas qu'un pipeline regroupe simplement les commandes. Pour garantir l'atomicité, utilisez des scripts MULTI ou Lua.
「N'ayez pas trop de commandes de pipeline à la fois」. Lors de l'utilisation du pipeline, Redis stockera temporairement les résultats de réponse des commandes du pipeline dans le tampon de réponse de la mémoire et attendra que toutes les commandes soient exécutées avant de revenir. S'il y a trop de commandes de pipeline, cela peut occuper plus de mémoire. Un seul pipeline peut être divisé en plusieurs pipelines.
02 Activez le multi-threading IO
Avant la version "Redis 6", Redis était "mono-thread" pour lire, analyser et exécuter des commandes. À partir de Redis 6, le multithreading IO a été introduit.
Le thread IO est responsable de la lecture des commandes, de l'analyse des commandes et du renvoi des résultats. Lorsqu'il est activé, il peut améliorer efficacement les performances des E/S.
J'ai dessiné un diagramme schématique pour votre référence
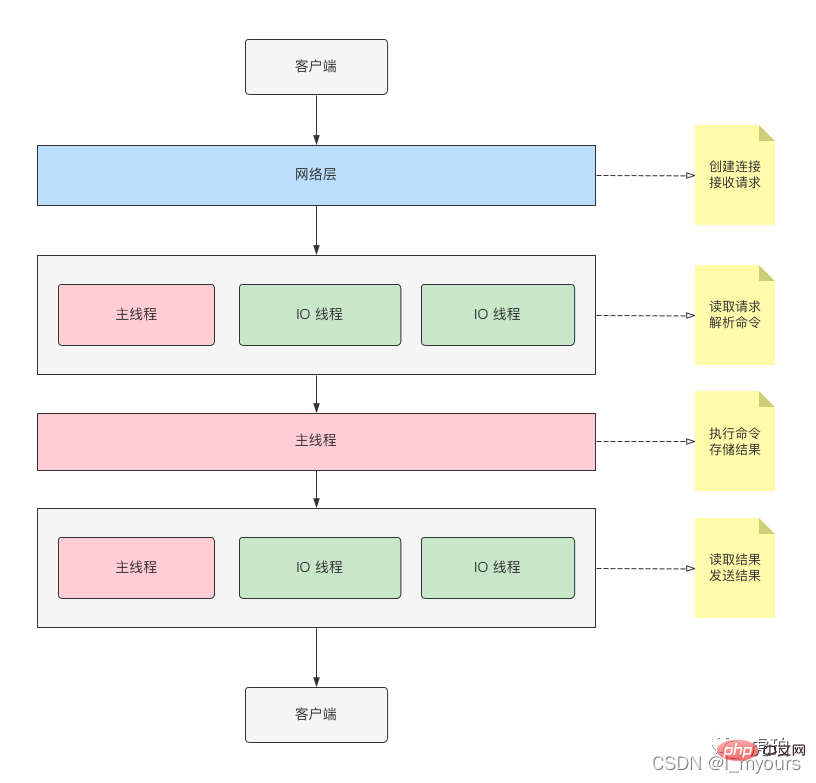
Comme le montre l'image ci-dessus, le thread principal et le thread IO participeront conjointement à la lecture, à l'analyse et à la réponse aux résultats des commandes.
Mais celui qui exécute la commande est le "thread principal".
Le thread IO est fermé par défaut. Vous pouvez modifier la configuration suivante dans redis.conf pour l'activer.
io-threads 4 io-threads-do-reads yes
"io-threads" est le nombre de threads IO (y compris le thread principal). Je vous suggère de définir différentes valeurs en fonction de la machine pour les tests de stress et d'obtenir la valeur optimale.
03 Évitez les grosses clés
La commande d'exécution de Redis est monothread, ce qui signifie qu'il y a un risque de blocage lorsque Redis actionne la "grosse clé".
La grande clé fait généralement référence à une valeur stockée dans Redis qui est trop grande. Y compris :
- Une seule valeur est trop grande. Comme une chaîne de taille 200 M.
- Trop d'éléments de collection. Par exemple, il existe des centaines ou des dizaines de millions de données dans List, Hash, Set et ZSet.
Par exemple, supposons que nous ayons une clé de chaîne de 200 M nommée "foo".
Exécutez la commande suivante
127.0.0.1:6379> GET foo
Lorsque le résultat est renvoyé, Redis allouera 200 m de mémoire et effectuera une copie memcpy.
void _addReplyProtoToList(client *c, const char *s, size_t len) {
...
if (len) {
/* Create a new node, make sure it is allocated to at
* least PROTO_REPLY_CHUNK_BYTES */
size_t size = len size = zmalloc_usable_size(tail) - sizeof(clientReplyBlock);
tail->used = len;
// 内存拷贝
memcpy(tail->buf, s, len);
listAddNodeTail(c->reply, tail);
c->reply_bytes += tail->size;
closeClientOnOutputBufferLimitReached(c, 1);
}}
Et le buf de sortie Redis est de 16k
// server.h#define PROTO_REPLY_CHUNK_BYTES (16*1024) /* 16k output buffer */typedef struct client {
...
char buf[PROTO_REPLY_CHUNK_BYTES];} client;
Cela signifie que Redis ne peut pas renvoyer les données de réponse en une seule fois et doit enregistrer un "événement inscriptible", déclenchant ainsi plusieurs appels système d'écriture.
Il y a deux points qui prennent du temps ici :
- Allouer une grande mémoire (peut également libérer de la mémoire, comme la commande DEL)
- Déclencher plusieurs événements inscriptibles (exécuter fréquemment des appels système, tels que write, epoll_wait)
Ensuite , Comment trouver la grosse clé ?
Si des commandes simples apparaissent dans le journal lent, telles que GET, SET et DEL, il y a une forte probabilité qu'une grosse clé apparaisse.
127.0.0.1:6379> SLOWLOG GET 3) (integer) 201323 // 单位微妙 4) 1) "GET" 2) "foo"
Deuxièmement, vous pouvez utiliser l'outil d'analyse Redis pour trouver la grande clé.
$ redis-cli --bigkeys -i 0.1 ... [00.00%] Biggest string found so far '"foo"' with 209715200 bytes -------- summary ------- Sampled 1 keys in the keyspace! Total key length in bytes is 3 (avg len 3.00) Biggest string found '"foo"' has 209715200 bytes 1 strings with 209715200 bytes (100.00% of keys, avg size 209715200.00) 0 lists with 0 items (00.00% of keys, avg size 0.00) 0 hashs with 0 fields (00.00% of keys, avg size 0.00) 0 streams with 0 entries (00.00% of keys, avg size 0.00) 0 sets with 0 members (00.00% of keys, avg size 0.00) 0 zsets with 0 members (00.00% of keys, avg size 0.00)
Concernant les grosses clés, nous avons les suggestions suivantes :
1. Essayez d'éviter les grosses clés en entreprise. Lorsqu'une grosse clé apparaît, vous devez juger si la conception est raisonnable ou si un bug s'est produit.
2. Divisez la grande clé en plusieurs petites clés.
3. Utilisez des commandes alternatives.
Si la version Redis est supérieure à 4.0, vous pouvez utiliser la commande UNLINK au lieu de DEL. Si la version Redis est supérieure à 6.0, le mécanisme sans paresseux peut être activé. L'opération de libération de mémoire sera exécutée sur le thread d'arrière-plan.
LRANGE, HGETALL, etc. sont remplacés par LSCAN, HSCAN pour obtenir par lots.
Mais je recommande quand même d'éviter les grosses clés en affaires.
04 Évitez d'exécuter des commandes avec une complexité temporelle élevée
Nous savons que Redis exécute les commandes dans un "unique thread". L'exécution de commandes avec une complexité temporelle élevée est susceptible de bloquer d'autres requêtes.
复杂度高的命令和元素数量有关。通常有以下两种场景。
元素太多,消耗 IO 资源。如 HGETALL、LRANGE,时间复杂度为 O(N)。
计算过于复杂,消费 CPU 资源。如 ZUNIONSTORE,时间复杂度为 O(N)+O(M log(M))
Redis 官方手册,标记了命令执行的时间复杂度。建议你在使用不熟悉的命令前,先查看手册,留意时间复杂度。
实际业务中,你应该尽量避免时间复杂度高的命令。如果必须要用,有两点建议
保证操作的元素数量,尽可能少。
读写分离。复杂命令通常是读请求,可以放到「slave」结点执行。
05 使用惰性删除 Lazy free
key 过期或是使用 DEL 删除命令时,Redis 除了从全局 hash 表移除对象外,还会将对象分配的内存释放。当遇到 big key 时,释放内存会造成主线程阻塞。
为此,Redis 4.0 引入了 UNLINK 命令,将释放对象内存操作放入 bio 后台线程执行。从而有效减少主线程阻塞。
Redis 6.0 更进一步,引入了 Lazy-free 相关配置。当开启配置后,key 过期和 DEL 命令内部,会将「释放对象」操作「异步执行」。
void delCommand(client *c) {
delGenericCommand(c,server.lazyfree_lazy_user_del);}void delGenericCommand(client *c, int lazy) {
int numdel = 0, j;
for (j = 1; j argc; j++) {
expireIfNeeded(c->db,c->argv[j]);
// 开启 lazy free 则使用异步删除
int deleted = lazy ? dbAsyncDelete(c->db,c->argv[j]) :
dbSyncDelete(c->db,c->argv[j]);
...
}}
建议至少升级到 Redis 6,并开启 Lazy-free。
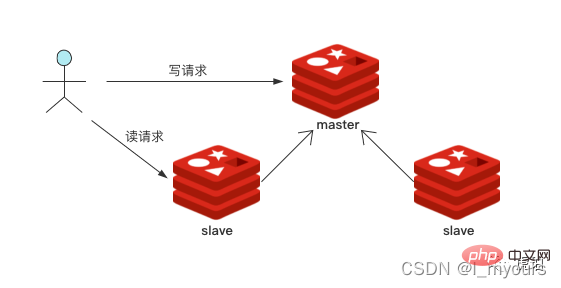
06 读写分离
Redis 通过副本,实现「主-从」运行模式,是故障切换的基石,用来提高系统运行可靠性。也支持读写分离,提高读性能。
你可以部署一个主结点,多个从结点。将读命令分散到从结点中,从而减轻主结点压力,提升性能。
07 绑定 CPU
Redis 6.0 开始支持绑定 CPU,可以有效减少线程上下文切换。
CPU 亲和性(CPU Affinity)是一种调度属性,它将一个进程或线程,「绑定」到一个或一组 CPU 上。也称为 CPU 绑定。
设置 CPU 亲和性可以一定程度避免 CPU 上下文切换,提高 CPU L1、L2 Cache 命中率。
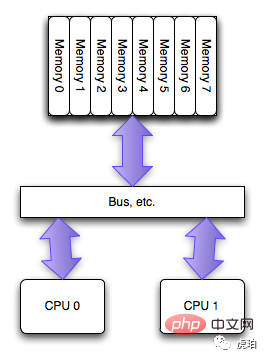
早期「SMP」架构下,每个 CPU 通过 BUS 总线共享资源。CPU 绑定意义不大。
而在当前主流的「NUMA」架构下,每个 CPU 有自己的本地内存。访问本地内存有更快的速度。而访问其他 CPU 内存会导致较大的延迟。这时,CPU 绑定对系统运行速度的提升有较大的意义。
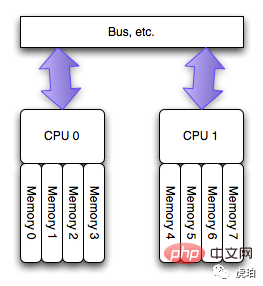
现实中的 NUMA 架构比上图更复杂,通常会将 CPU 分组,若干个 CPU 分配一组内存,称为 「node」。
你可以通过 「numactl -H 」 命令来查看 NUMA 硬件信息。
$ numactl -H available: 2 nodes (0-1)node 0 cpus: 0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 34 36 38 node 0 size: 32143 MB node 0 free: 26681 MB node 1 cpus: 1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39 node 1 size: 32309 MB node 1 free: 24958 MB node distances: node 0 1 0: 10 21 1: 21 10
上图中可以得知该机器有 40 个 CPU,分组为 2 个 node。
node distances 是一个二维矩阵,表示 node 之间 「访问距离」,10 为基准值。上述命令中可以得知,node 自身访问,距离是 10。跨 node 访问,如 node 0 访问 node 1 距离为 21。说明该机器「跨 node 访问速度」比「node 自身访问速度」慢 2.1 倍。
其实,早在 2015 年,有人提出 Redis 需要支持设置 CPU 亲和性,而当时的 Redis 还没有支持 IO 多线程,该提议搁置。
而 Redis 6.0 引入 IO 多线程。同时,也支持了设置 CPU 亲和性。
我画了一张 Redis 6.0 线程家族供你参考。

上图可分为 3 个模块
- 主线程和 IO 线程:负责命令读取、解析、结果返回。命令执行由主线程完成。
- bio 线程:负责执行耗时的异步任务,如 close fd。
- 后台进程:fork 子进程来执行耗时的命令。
Redis 支持分别配置上述模块的 CPU 亲和度。你可以在 redis.conf 找到以下配置(该配置需手动开启)。
# IO 线程(包含主线程)绑定到 CPU 0、2、4、6 server_cpulist 0-7:2 # bio 线程绑定到 CPU 1、3 bio_cpulist 1,3 # aof rewrite 后台进程绑定到 CPU 8、9、10、11 aof_rewrite_cpulist 8-11 # bgsave 后台进程绑定到 CPU 1、10、11 bgsave_cpulist 1,10-11
我在上述机器,针对 IO 线程和主线程,进行如下测试:
首先,开启 IO 线程配置。
io-threads 4 # 主线程 + 3 个 IO 线程io-threads-do-reads yes # IO 线程开启读和解析命令功能
测试如下三种场景:
不开启 CPU 绑定配置。
绑定到不同 node。
「server_cpulist 0,1,2,3」绑定到相同 node。
「server_cpulist 0,2,4,6」
通过 redis-benchmark 对 get 命令进行基准测试,每种场景执行 3 次。
$ redis-benchmark -n 5000000 -c 50 -t get --threads 4
结果如下:
1.不开启 CPU 绑定配置
throughput summary: 248818.11 requests per second throughput summary: 248694.36 requests per second throughput summary: 249004.00 requests per second
2.绑定不同 node
throughput summary: 248880.03 requests per second throughput summary: 248447.20 requests per second throughput summary: 248818.11 requests per second
3.绑定相同 node
throughput summary: 284414.09 requests per second throughput summary: 284333.25 requests per second throughput summary: 265252.00 requests per second
根据测试结果,绑定到同一个 node,qps 大约提升 15%
使用绑定 CPU,你需要注意以下几点:
Linux 下,你可以使用 「numactl --hardware」 查看硬件布局,确保支持并开启 NUMA。
线程要尽可能分布在 「不同的 CPU,相同的 node」,设置 CPU 亲和度才有效。否则会造成频繁上下文切换和远距离内存访问。
你要熟悉 CPU 架构,做好充分的测试。否则可能适得其反,导致 Redis 性能下降。
08 合理配置持久化策略
Redis 支持两种持久化策略,RDB 和 AOF。
RDB 通过 fork 子进程,生成数据快照,二进制格式。
AOF 是增量日志,文本格式,通常较大。会通过 AOF rewrite 重写日志,节省空间。
除了手动执行「BGREWRITEAOF」命令外,以下 4 点也会触发 AOF 重写
执行「config set appendonly yes」命令
AOF 文件大小比例超出阈值,「auto-aof-rewrite-percentage」
AOF 文件大小绝对值超出阈值,「auto-aof-rewrite-min-size」
主从复制完成 RDB 加载
RDB 和 AOF,都是在主线程中触发执行。虽然具体执行,会通过 fork 交给后台子进程。但 fork 操作,会拷贝进程数据结构、页表等,当实例内存较大时,会影响性能。
AOF 支持以下三种策略。
appendfsync no:由操作系统决定执行 fsync 时机。 对 Linux 来说,通常每 30 秒执行一次 fsync,将缓冲区中的数据刷到磁盘上。如果 Redis qps 过高或写 big key,可能导致 buffer 写满,从而频繁触发 fsync。
appendfsync everysec: 每秒执行一次 fsync。
appendfsync always: 每次「写」会调用一次 fsync,性能影响较大。
AOF 和 RDB 都会对磁盘 IO 造成较高的压力。其中,AOF rewrite 会将 Redis hash 表所有数据进行遍历并写磁盘。对性能会产生一定的影响。
线上业务 Redis 通常是高可用的。如果对缓存数据丢失不敏感。考虑关闭 RDB 和 AOF 以提升性能。
如果无法关闭,有以下几点建议:
RDB 选择业务低峰期做,通常为凌晨。保持单个实例内存不超过 32 G。太大的内存会导致 fork 耗时增加。
AOF 选择 appendfsync no 或者 appendfsync everysec。
AOF auto-aof-rewrite-min-size 配置大一些,如 2G。避免频繁触发 rewrite。
AOF 可以仅在从节点开启,减轻主节点压力。
根据本地测试,不开启 AOF,写性能大约能提升 20% 左右。
09 使用长连接
Redis 是基于 TCP 协议,请求-响应式服务器。使用短连接会导致频繁的创建连接。
短连接有以下几个慢速操作:
创建连接时,TCP 会执行三次握手、慢启动等策略。
Redis 会触发新建/断开连接事件,执行分配/销毁客户端等耗时操作。
如果你使用的是 Redis Cluster,新建连接时,客户端会拉取 slots 信息初始化。建立连接速度更慢。
所以,相对于性能快速的 Redis,创建连接是十分慢速的操作。
「建议使用连接池,并合理设置连接池大小」。
但使用长连接时,需要留意一点,要有「自动重连」策略。避免因网络异常,导致连接失效,影响正常业务。
10 关闭 SWAP
SWAP 是内存交换技术。将内存按页,复制到预先设定的磁盘空间上。
内存是快速的,昂贵的。而磁盘是低速的,廉价的。
通常使用 SWAP 越多,系统性能越低。
Redis 是内存数据库,使用 SWAP 会导致性能快速下降。
建议留有足够内存,并关闭 SWAP。
总结
以上就是今天为大家分享的 「提升 Redis 性能的 10 个手段」。
我绘制了思维导图,方便大家记忆。
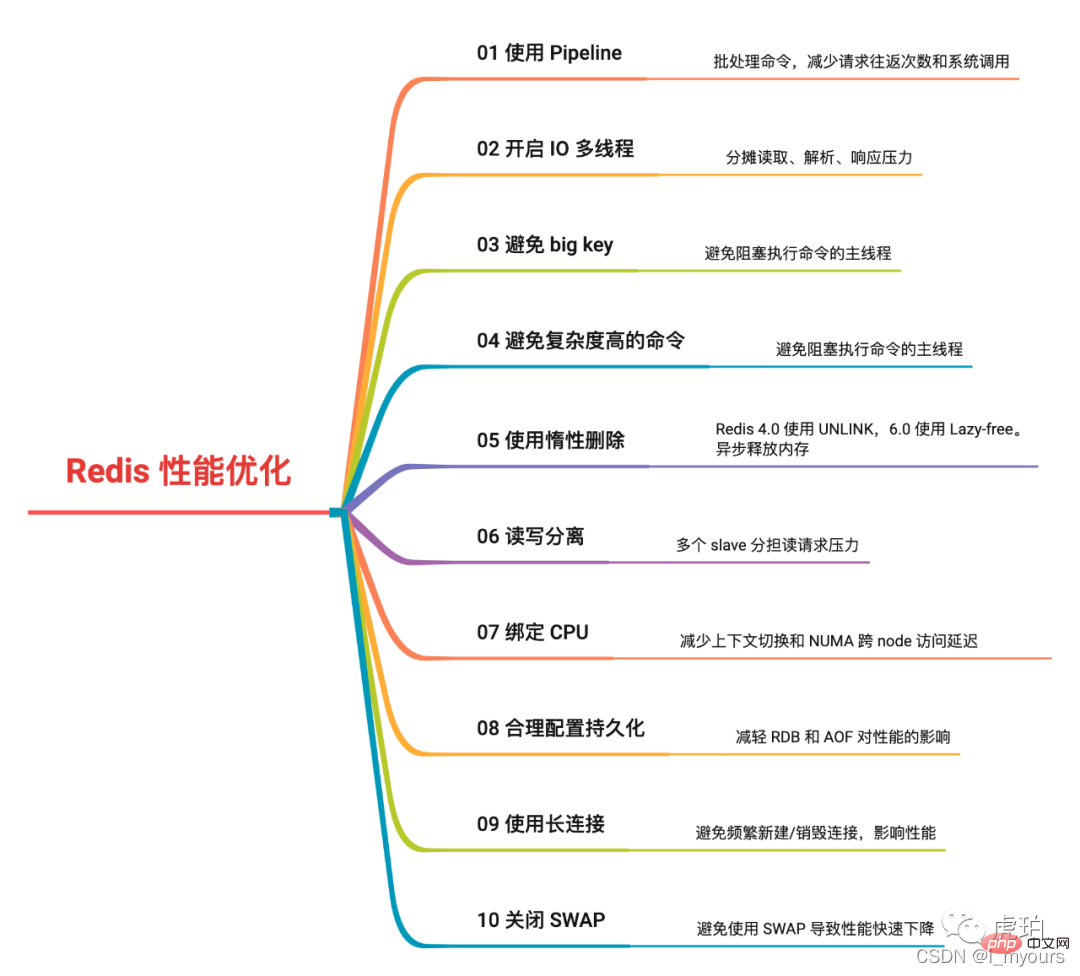
可以看到,性能优化并不容易,需要我们了解很多底层知识,并做出充分测试。在不同机器、不同系统、不同配置下,Redis 都会有不同的性能表现。
推荐学习:Redis学习教程
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- 12 points clés souvent demandés lors des entretiens Redis (avec réponses)
- Comprendre les opérations atomiques Redis en dix minutes
- Redis Advanced Learning High Availability Sentinel (partage de résumé)
- Résumer les types de données Redis et les scénarios d'utilisation
- Redis ralentit soudainement ? Analysons comment déterminer si Redis a des problèmes de performances et comment les résoudre