
Maison >base de données >Redis >Comprendre les opérations atomiques Redis en dix minutes
Comprendre les opérations atomiques Redis en dix minutes

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2022-02-17 18:27:194735parcourir
Cet article vous apporte des connaissances pertinentes sur les opérations atomiques Redis. Afin de garantir l'exactitude des accès simultanés, Redis propose deux méthodes, à savoir le verrouillage et les opérations atomiques. J'espère que cela sera utile à tout le monde.

Opération atomique redis
Lorsque nous utilisons Redis, nous rencontrerons inévitablement des problèmes d'accès simultanés. Par exemple, si plusieurs utilisateurs passent des commandes en même temps, l'inventaire des produits mis en cache dans Redis sera mis à jour simultanément. Une fois qu'il y aura des opérations d'écriture simultanées, les données seront modifiées. Si nous ne contrôlons pas les demandes d'écriture simultanées, les données peuvent être corrigées, affectant l'utilisation normale de l'entreprise (par exemple, des erreurs de données d'inventaire entraînent une passation de commande anormale).
Afin de garantir l'exactitude des accès simultanés, Redis propose deux méthodes, à savoir le verrouillage et les opérations atomiques.
Le verrouillage est une méthode courante. Avant de lire les données, le client doit d'abord obtenir le verrou, sinon l'opération ne pourra pas être effectuée. Lorsqu'un client obtient un verrou, il le maintiendra jusqu'à ce qu'il termine la mise à jour des données, puis libèrera le verrou.
Cela semble être une bonne solution, mais il y a en fait deux problèmes ici : l'un est que s'il y a trop d'opérations de verrouillage, cela réduira les performances d'accès simultané du système ; le second est que le client Redis doit être verrouillé lorsque ; pour ce faire, des verrous distribués doivent être utilisés, et la mise en œuvre de verrous distribués est complexe et nécessite un système de stockage supplémentaire pour fournir les opérations d'ajout et de déverrouillage. Je vous le présenterai dans la prochaine leçon.
Les opérations atomiques sont un autre moyen de fournir un contrôle d'accès simultané. Les opérations atomiques font référence aux opérations qui maintiennent l'atomicité pendant l'exécution et ne nécessitent pas de verrous supplémentaires lors de l'exécution d'opérations atomiques, permettant ainsi d'obtenir des opérations sans verrouillage. De cette manière, le contrôle de la concurrence peut être garanti et l'impact sur les performances de concurrence du système peut être réduit.
Qu'est-ce qui doit être contrôlé lors d'un accès simultané ?
Ce que nous appelons le contrôle d'accès simultané fait référence au contrôle du processus par lequel plusieurs clients accèdent et exploitent les mêmes données pour garantir que les opérations envoyées par n'importe quel client s'excluent mutuellement lorsqu'elles sont exécutées sur l'instance Redis. Par exemple, pendant l'exécution de l'opération d'accès du client A, l'opération du client B ne peut pas être exécutée et doit attendre que l'opération du client A soit terminée.
Les opérations correspondant au contrôle d'accès concurrent sont principalement des opérations de modification de données. Lorsque le client a besoin de modifier des données, le processus de base est divisé en deux étapes :
- Le client lit d'abord les données localement et les modifie localement ;
- Une fois que le client a modifié les données, il les réécrit dans Redis ;
Nous appelons ce processus opération "Lecture-Modification-Ecriture" (Lecture-Modification-Ecriture, appelée opération RMW). Lorsque plusieurs clients effectuent des opérations RMW sur les mêmes données, nous devons permettre au code impliqué dans les opérations RMW d'être exécuté de manière atomique. Le code d'opération RMW qui accède aux mêmes données est appelé code de section critique.
Cependant, lorsque plusieurs clients exécutent simultanément le code d'une section critique, il y aura des problèmes potentiels. Ensuite, j'utiliserai un exemple de plusieurs clients mettant à jour l'inventaire de produits pour expliquer.
Jetons d’abord un coup d’œil au code de la section critique. Supposons que le client souhaite déduire 1 de l'inventaire du produit. Le pseudo-code est le suivant :
current = GET(id) current-- SET(id, current)
Vous pouvez voir que le client lira d'abord la valeur actuelle de l'inventaire du produit auprès de Redis en fonction de l'identifiant du produit (correspondant à Read). ), puis le client diminue la valeur de l'inventaire de 1 (correspondant à Modifier), puis réécrit la valeur de l'inventaire dans Redis (correspondant à Write). Lorsque plusieurs clients exécutent ce code, il s'agit d'un code de section critique.
Si nous n'avons aucun mécanisme de contrôle sur l'exécution du code des sections critiques, des erreurs de mise à jour des données se produiront. Dans l'exemple précédent, en supposant qu'il y ait deux clients A et B exécutant le code de la section critique en même temps, une erreur se produira. Vous pouvez regarder l'image ci-dessous. 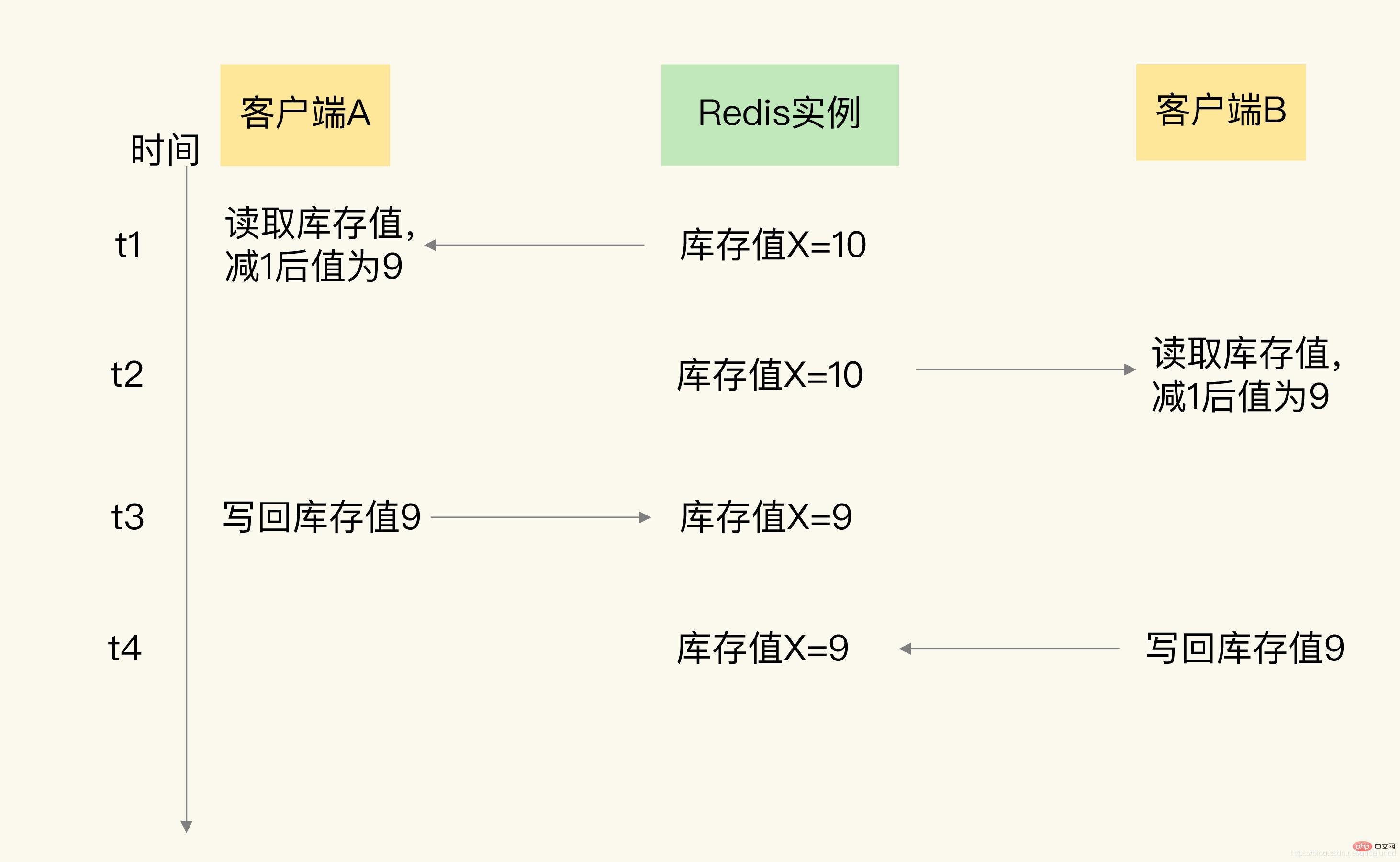
Vous pouvez voir que le client A lit la valeur d'inventaire 10 et déduit 1 à t1. À t2, le client A n'a pas encore écrit la valeur d'inventaire déduite 9 à Redis. À ce moment, le client B lit la valeur d'inventaire de. 10 et déduit 1. La valeur d'inventaire enregistrée par B est également 9. Lorsque t3, A réécrit la valeur d'inventaire 9 dans Redis, et lorsque t4, B réécrit également la valeur d'inventaire 9.
S'ils sont traités selon la logique correcte, les clients A et B déduisent chacun la valeur de l'inventaire une fois, et la valeur de l'inventaire doit être de 8. Par conséquent, la valeur de l’inventaire ici n’est évidemment pas mise à jour de manière incorrecte.
La raison de ce phénomène est que le client dans le code de la section critique implique trois opérations : lire les données, mettre à jour les données et réécrire les données. Cependant, ces trois opérations ne s'excluent pas mutuellement lorsqu'elles sont exécutées. Opérations multiples Le client effectue des modifications en fonction. sur la même valeur initiale, plutôt que sur la valeur modifiée par le client précédent.
Afin de garantir l'exactitude de la modification simultanée des données, nous pouvons utiliser des verrous pour transformer les opérations parallèles en opérations en série, et les opérations en série s'excluent mutuellement. Une fois qu'un client détient le verrou, les autres clients ne peuvent qu'attendre que le verrou soit libéré avant de pouvoir le prendre et apporter des modifications.
Le pseudo-code suivant montre l'utilisation de verrous pour contrôler l'exécution du code de section critique, vous pouvez y jeter un œil.
LOCK() current = GET(id) current-- SET(id, current) UNLOCK()
虽然加锁保证了互斥性,但是加锁也会导致系统并发性能降低。
如下图所示,当客户端 A 加锁执行操作时,客户端 B、C 就需要等待。A 释放锁后,假设 B 拿到锁,那么 C 还需要继续等待,所以,t1 时段内只有 A 能访问共享数据,t2 时段内只有 B 能访问共享数据,系统的并发性能当然就下降了。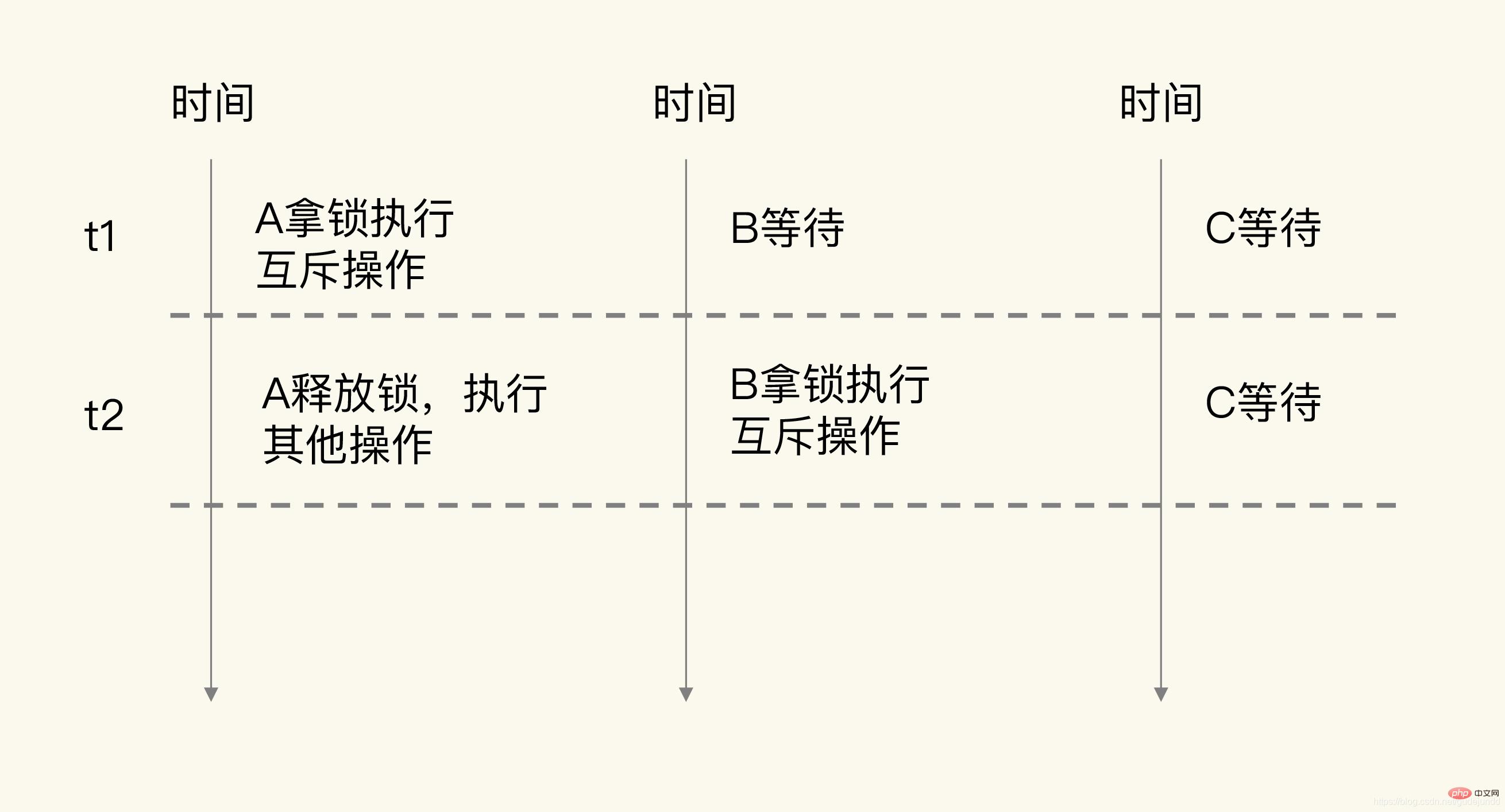
和加锁类似,原子操作也能实现并发控制,但是原子操作对系统并发性能的影响较小,接下来,我们就来了解下 Redis 中的原子操作。
Redis 的两种原子操作方法
为了实现并发控制要求的临界区代码互斥执行,Redis 的原子操作采用了两种方法:
- 把多个操作在 Redis 中实现成一个操作,也就是单命令操作;
- 把多个操作写到一个 Lua 脚本中,以原子性方式执行单个 Lua 脚本。
我们先来看下 Redis 本身的单命令操作。
Redis 是使用单线程来串行处理客户端的请求操作命令的,所以,当 Redis 执行某个命令操作时,其他命令是无法执行的,这相当于命令操作是互斥执行的。当然,Redis 的快照生成、AOF 重写这些操作,可以使用后台线程或者是子进程执行,也就是和主线程的操作并行执行。不过,这些操作只是读取数据,不会修改数据,所以,我们并不需要对它们做并发控制。
你可能也注意到了,虽然 Redis 的单个命令操作可以原子性地执行,但是在实际应用中,数据修改时可能包含多个操作,至少包括读数据、数据增减、写回数据三个操作,这显然就不是单个命令操作了,那该怎么办呢?
别担心,Redis 提供了 INCR/DECR 命令,把这三个操作转变为一个原子操作了。INCR/DECR 命令可以对数据进行增值 / 减值操作,而且它们本身就是单个命令操作,Redis 在执行它们时,本身就具有互斥性。
比如说,在刚才的库存扣减例子中,客户端可以使用下面的代码,直接完成对商品 id 的库存值减 1 操作。即使有多个客户端执行下面的代码,也不用担心出现库存值扣减错误的问题。
DECR id
所以,如果我们执行的 RMW 操作是对数据进行增减值的话,Redis 提供的原子操作 INCR 和 DECR 可以直接帮助我们进行并发控制。
但是,如果我们要执行的操作不是简单地增减数据,而是有更加复杂的判断逻辑或者是其他操作,那么,Redis 的单命令操作已经无法保证多个操作的互斥执行了。所以,这个时候,我们需要使用第二个方法,也就是 Lua 脚本。
Redis 会把整个 Lua 脚本作为一个整体执行,在执行的过程中不会被其他命令打断,从而保证了 Lua 脚本中操作的原子性。如果我们有多个操作要执行,但是又无法用 INCR/DECR 这种命令操作来实现,就可以把这些要执行的操作编写到一个 Lua 脚本中。
然后,我们可以使用 Redis 的 EVAL 命令来执行脚本。这样一来,这些操作在执行时就具有了互斥性。
再举个例子,具体解释下 Lua 的使用。
当一个业务应用的访问用户增加时,我们有时需要限制某个客户端在一定时间范围内的访问次数,比如爆款商品的购买限流、社交网络中的每分钟点赞次数限制等。
那该怎么限制呢?我们可以把客户端 IP 作为 key,把客户端的访问次数作为 value,保存到 Redis 中。客户端每访问一次后,我们就用 INCR 增加访问次数。
不过,在这种场景下,客户端限流其实同时包含了对访问次数和时间范围的限制,例如每分钟的访问次数不能超过 20。所以,我们可以在客户端第一次访问时,给对应键值对设置过期时间,例如设置为 60s 后过期。同时,在客户端每次访问时,我们读取客户端当前的访问次数,如果次数超过阈值,就报错,限制客户端再次访问。你可以看下下面的这段代码,它实现了对客户端每分钟访问次数不超过 20 次的限制。
//获取ip对应的访问次数 current = GET(ip) //如果超过访问次数超过20次,则报错 IF current != NULL AND current > 20 THEN ERROR "exceed 20 accesses per second" ELSE //如果访问次数不足20次,增加一次访问计数 value = INCR(ip) //如果是第一次访问,将键值对的过期时间设置为60s后 IF value == 1 THEN EXPIRE(ip,60) END //执行其他操作 DO THINGS END
可以看到,在这个例子中,我们已经使用了 INCR 来原子性地增加计数。但是,客户端限流的逻辑不只有计数,还包括访问次数判断和过期时间设置。
对于这些操作,我们同样需要保证它们的原子性。否则,如果客户端使用多线程访问,访问次数初始值为 0,第一个线程执行了 INCR(ip) 操作后,第二个线程紧接着也执行了 INCR(ip),此时,ip 对应的访问次数就被增加到了 2,我们就无法再对这个 ip 设置过期时间了。这样就会导致,这个 ip 对应的客户端访问次数达到 20 次之后,就无法再进行访问了。即使过了 60s,也不能再继续访问,显然不符合业务要求。
所以,这个例子中的操作无法用 Redis 单个命令来实现,此时,我们就可以使用 Lua 脚本来保证并发控制。我们可以把访问次数加 1、判断访问次数是否为 1,以及设置过期时间这三个操作写入一个 Lua 脚本,如下所示:
local current
current = redis.call("incr",KEYS[1])
if tonumber(current) == 1 then
redis.call("expire",KEYS[1],60)
end
假设我们编写的脚本名称为 lua.script,我们接着就可以使用 Redis 客户端,带上 eval 选项,来执行该脚本。脚本所需的参数将通过以下命令中的 keys 和 args 进行传递。
redis-cli --eval lua.script keys , args
这样一来,访问次数加 1、判断访问次数是否为 1,以及设置过期时间这三个操作就可以原子性地执行了。即使客户端有多个线程同时执行这个脚本,Redis 也会依次串行执行脚本代码,避免了并发操作带来的数据错误。
推荐学习:《Redis视频教程》、《2022最新redis面试题大全及答案》
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Une brève analyse des modèles monothread et multithread dans Redis6
- Analyse du code source Redis et compréhension approfondie des fichiers Makefile
- Comment résoudre le problème d'erreur php redis502
- Redis Learning : compréhension approfondie des bitmaps
- Un article pour parler des opérations d'expiration et des stratégies d'expiration dans Redis