
Maison >base de données >tutoriel mysql >Explication détaillée des instructions count(), union() et group by dans MySQL
Explication détaillée des instructions count(), union() et group by dans MySQL

- 青灯夜游avant
- 2021-09-03 18:49:304096parcourir
Cet article vous guidera à travers les instructions count(), union() et group by, et complétera les points de connaissances MySQL (utilisation de différents count(), processus d'exécution d'union, instruction group by).

1. Différentes utilisations de count() dans MySQL
count() est une fonction d'agrégation. L'ensemble de résultats renvoyé est jugé ligne par ligne. Si le paramètre de la fonction count n'est pas NULL, le cumulatif. la valeur est ajoutée 1, sinon ne pas ajouter. Enfin, la valeur cumulée est renvoyée. [Recommandations associées : Tutoriel vidéo mysql]
1. Pour le nombre (identifiant de clé primaire), le moteur InnoDB parcourra toute la table, supprimera la valeur d'identifiant de chaque ligne et la renverra à la couche serveur. Une fois que la couche serveur a obtenu l'identifiant, elle juge qu'il ne peut pas être vide, elle l'accumule donc par ligne
2 Pour count(1), le moteur InnoDB parcourt la table entière mais ne prend pas de valeur. La couche serveur met un numéro 1 dans chaque ligne renvoyée. Il est jugé qu'il ne peut pas être vide et est accumulé par ligne 3. Pour le nombre (champ), si ce champ est défini comme non nul, ligne par ligne, lisez ce champ à partir de. l'enregistrement, juge qu'il ne peut pas être nul et accumule-le par ligne ; si la définition du champ autorise null, alors lors de l'exécution, il est jugé qu'il peut être nul, et la valeur doit être retirée et jugée pour voir si elle l'est. non nul. Accumuler
4. Pour
, il ne doit pas être nul. Accumuler par lignecount(*)来说,并不会把全部字段取出来,而是专门做了优化。不取值,count(*)

Afin de faciliter l'analyse quantitative, prenons le tableau t1 suivant comme exemple
.create table t1(id int primary key, a int, b int, index(a));
CREATE DEFINER=`root`@`%` PROCEDURE `idata`()
BEGIN
declare i int;
set i=1;
while(i<=1000)do
insert into t1 values(i, i, i);
set i=i+1;
end while;
ENDanalysez l'instruction SQL suivante : La sémantique de
(select 1000 as f) union (select id from t1 order by id desc limit 2);
union est de prendre l'union des résultats de ces deux sous-requêtes. L'union signifie que les deux ensembles sont additionnés et qu'une seule ligne de lignes en double est conservée

- Champ supplémentaire dans la troisième row, Indique que lors de l'exécution de l'union sur l'ensemble de résultats de la sous-requête, une table temporaire est utilisée. Le flux d'exécution de cette instruction est le suivant :
- 1 Créez une table temporaire en mémoire. Cette table temporaire n'a qu'un seul champ entier f. , et f est le champ de clé primaire
obtenez l'identifiant de la première ligne = 1000 et essayez de l'insérer dans la table temporaire. Mais comme la valeur 1000 existe déjà dans la table temporaire, ce qui viole la contrainte d'unicité, l'insertion échoue, puis l'exécution continue
La deuxième ligne id=999 est obtenue, et l'insertion dans la table temporaire est réussie
- 4. Appuyez sur depuis la table temporaire Retirez les données ligne par ligne, renvoyez le résultat et supprimez la table temporaire. Le résultat contient deux lignes de données, qui sont 1000 et 999
La table temporaire de mémoire joue ici le rôle. rôle de stockage temporaire des données, et le processus de calcul utilise également la table temporaire. La contrainte d'unicité de l'identifiant de clé primaire implémente la sémantique de l'union
Si l'union dans l'instruction ci-dessus est modifiée en union all, il n'y aura pas de sémantique de déduplication. Lorsqu'elles sont exécutées de cette manière, les sous-requêtes sont exécutées dans l'ordre et les résultats obtenus sont directement envoyés au client dans le cadre de l'ensemble de résultats. Par conséquent, il n'est pas nécessaire d'avoir une table temporaire
Le champ Extra dans la deuxième ligne indique Using index, ce qui signifie que seul l'index de couverture est utilisé et que la table temporaire n'est pas utilisée
1 , group by processus d'exécution
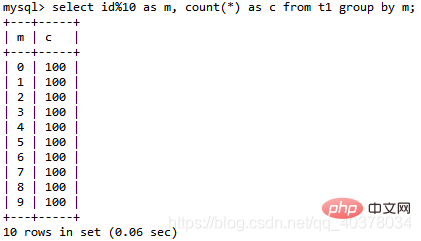
Utilisez toujours le tableau t1 ci-dessus pour analyser l'instruction SQL suivante :select id%10 as m, count(*) as c from t1 group by m;
La logique de cette instruction est de regrouper les données dans la table t1 selon id%10, et effectue des statistiques en fonction du résultat de m Sortie après tri. Le résultat de l'explication est le suivant :
Dans le champ Extra, vous pouvez voir trois informations :
Using index, ce qui signifie que cette instruction utilise un index de couverture, sélectionne l'index a et n'a pas besoin de retourner la table 
Utiliser temporaire, ce qui signifie utiliser La table temporaire
- Utiliser filesort signifie qu'un tri est requis
- Le flux d'exécution de cette instruction est le suivant :
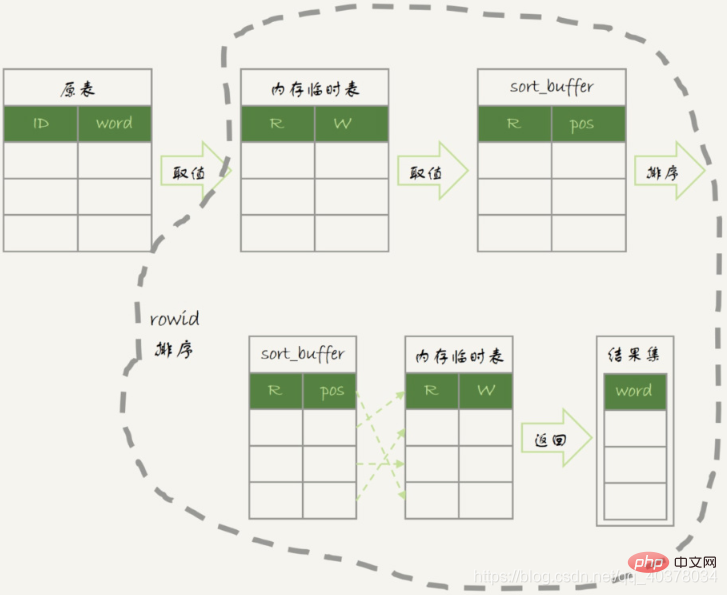
- 1. Créez une table temporaire en mémoire. m et c dans le tableau, et la clé primaire est m
内存临时表排序流程图:
如果并不需要对结果进行排序,在SQL语句末尾增加order by null:
select id%10 as m, count(*) as c from t1 group by m order by null;
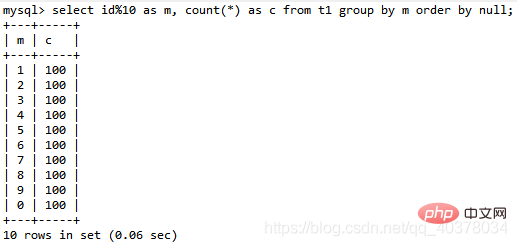
由于表t1中的id值是从1开始的,因此返回的结果集中第一行是id=1
这个例子里由于临时表只有10行,内存可以放得下,因此全程只使用了内存临时表。但是,内存临时表的大小是有限的,参数tmp_table_size就是控制整个内存大小的,默认是16M
set tmp_table_size=1024; select id%100 as m, count(*) as c from t1 group by m order by null limit 10;
把内存临时表的大小限制为最大1024字节,并把语句改成id%100,这样返回结果里有100行数据。但是,这时的内存临时表大小不够存下这100行数据,也就是说,执行过程中会发现内存临时表大小达到了上限。那么,这时候会把内存临时表转成磁盘临时表,磁盘临时表默认使用的引擎是InnoDB
2、group by优化方法——索引
group by的语义逻辑,是统计不同的值的个数。但是,由于每一行的id%100的结果是无序的,所以就需要有一个临时表来记录并统计结果。那么,如果扫描过程中可以保证出现的数据是有序的就可以了
假设,现在有一个类似下图的这么一个数据结构

如果可以确保输入的数据是有序的,那么计算group by的时候,就只需要从左到右,顺序扫描,依次累加。也就是下面这个流程:
- 当碰到第一个1的时候,已经知道累积了X个0,结果集里的第一行就是(0,X)
- 当碰到第一个2的时候,已经知道累积了Y个1,结果集里的第一行就是(1,Y)
按照这个逻辑执行的话,扫描到整个输入的数据结束,就可以拿到group by的结果,不需要临时表,也需要再额外排序
在MySQL5.7版本支持了generated column机制,用来实现列数据的关联更新。创建一个列z,在z列上创建一个索引
alter table t1 add column z int generated always as(id % 100), add index(z);
这样,索引z上的数据就是有序的了。group by语句就可以改成:
select z, count(*) as c from t1 group by z;

从这个Extra字段可以看到,这个语句的执行不再需要临时表,也不需要排序了
3、group by优化方法——直接排序
在group by语句中加入SQL_BIG_RESULT这个提示,就可以告诉优化器:这个语句涉及的数据量很大,直接用磁盘临时表。因为磁盘临时表是B+树存储,存储效率不如数组来得高。所以MySQL优化器直接用数组来存
select SQL_BIG_RESULT id%100 as m, count(*) as c from t1 group by m;
1.初始化sort_buffer,确定放入一个整型字段,记为m
2.扫描表t1的索引a,依次取出里面的id值,将id%100的值存入sort_buffer中
3.扫描完成后,对sort_buffer的字段m做排序(如果sort_buffer内存不够用,就会利用磁盘临时文件辅助排序)
4.排序完成后,就得到了一个有序数组
根据有序数组,得到数组里面的不同值,以及每个值的出现次数
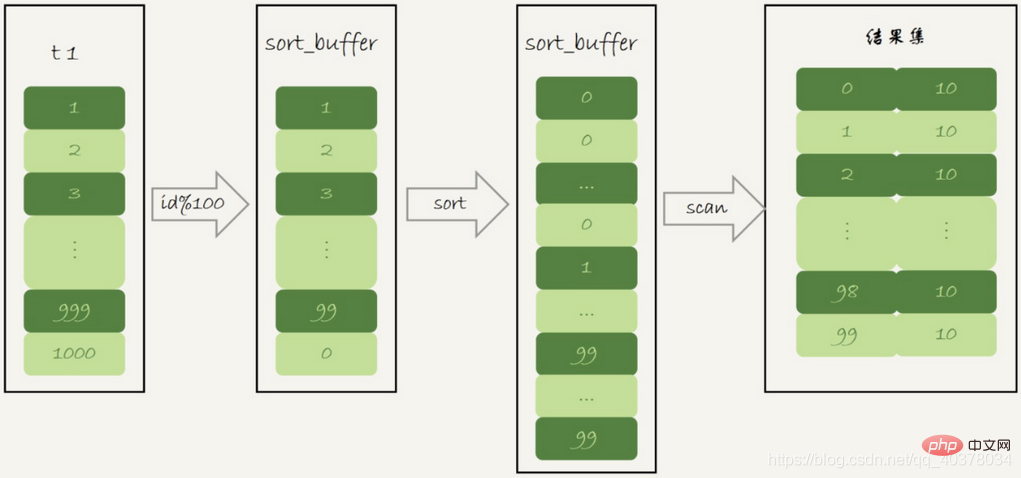
这个语句的执行没有再使用临时表,而是直接用了排序算法
,%20union()%20et%20group%20by%20dans%20MySQL)
更多编程相关知识,请访问:编程入门!!
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Parlons de l'isolation des transactions dans MySQL
- Compréhension approfondie des verrous dans MySQL (verrous globaux, verrous au niveau des tables, verrous de ligne)
- Comment résoudre le problème d'erreur php emoji mysql
- Analyser l'installation et l'utilisation de mysql (Collection)
- En savoir plus sur la séparation maître-veille, maître-esclave et lecture-écriture dans MySQL