
Maison >base de données >tutoriel mysql >En savoir plus sur la séparation maître-veille, maître-esclave et lecture-écriture dans MySQL
En savoir plus sur la séparation maître-veille, maître-esclave et lecture-écriture dans MySQL

- 青灯夜游original
- 2021-09-01 18:46:572768parcourir
Cet article vous guidera à travers la séparation maître-esclave, maître-esclave et lecture-écriture dans MySQL. J'espère qu'il vous sera utile !
1. Les principes de base du maître et de la sauvegarde MySQL
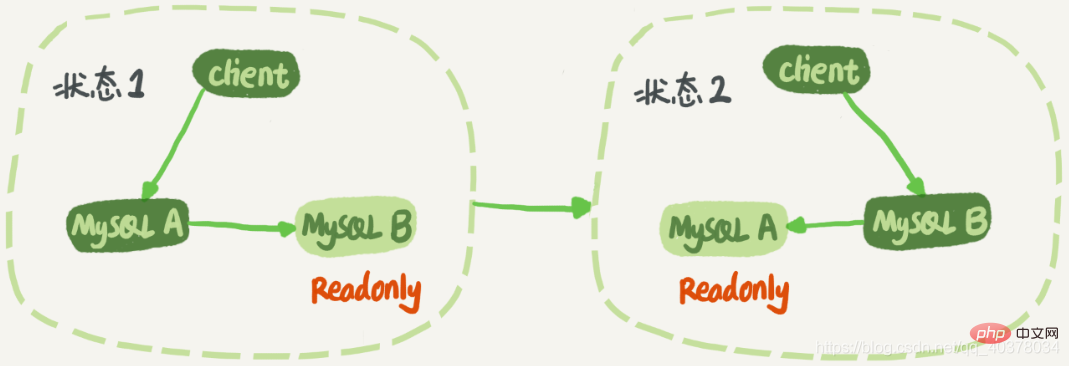
Dans l'état 1, le client accède directement au nœud A en lecture et en écriture, et le nœud B est la base de données de sauvegarde de A. Il synchronise simplement les mises à jour de A. à Exécuté localement. Cela conserve les mêmes données des nœuds B et A. Lorsqu’une commutation est requise, passez à l’état 2. À ce stade, le client lit et écrit sur le nœud B, et le nœud A est la base de données de secours de B. [Recommandations associées : Tutoriel vidéo mysql]
Dans l'état 1, bien que le nœud B ne soit pas directement accessible, il est recommandé de définir le nœud B de veille en mode lecture seule. Il y a plusieurs raisons :
1. Parfois, certaines instructions de requête opérationnelles seront placées dans la base de données de secours pour la requête. La définir en lecture seule peut éviter des erreurs d'opération
2. Pour éviter des bogues dans la logique de commutation
3. être utilisé en lecture seule pour déterminer le rôle du nœud
Si la base de données de secours est définie en lecture seule, comment peut-elle être mise à jour de manière synchrone avec la base de données principale ?
Le paramètre en lecture seule n'est pas valide pour les utilisateurs super privilégiés et le thread utilisé pour les mises à jour synchronisées possède des super privilèges
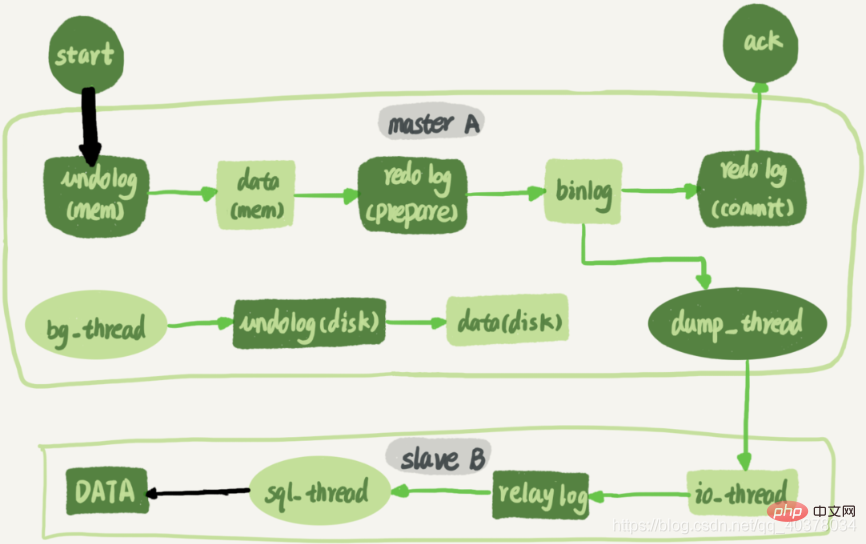
La figure suivante est un organigramme complet d'une instruction de mise à jour exécutée sur le nœud A puis synchronisée avec le nœud B : 
Une longue connexion est maintenue entre la base de données de secours B et la base de données principale A. Il existe un thread à l'intérieur de la bibliothèque principale A, dédié à la longue connexion de la bibliothèque de secours B. Le processus complet de synchronisation du journal des transactions est le suivant :
1. Utilisez la commande change master sur la base de données de secours B pour définir l'adresse IP, le port, le nom d'utilisateur, le mot de passe de la base de données principale A et l'emplacement à partir duquel demander ce journal binaire. location contient le nom du fichier et le décalage du journal
2. Exécutez la commande start slave sur la base de données en veille B. À ce stade, la base de données en veille démarrera deux threads, à savoir io_thread et sql_thread dans la figure. Parmi eux, io_thread est responsable de l'établissement d'une connexion avec la bibliothèque principale
3. Une fois que la bibliothèque principale A a vérifié le nom d'utilisateur et le mot de passe, elle commence à lire le journal binaire depuis le local en fonction de l'emplacement transmis par la bibliothèque de secours B et l'envoie. dans B
4. Bibliothèque de secours B Après avoir obtenu le journal binaire, écrivez-le dans un fichier local, appelé journal de transit
5.sql_thread lit le journal de transit, analyse les commandes dans le journal et l'exécute
En raison de Avec l'introduction du schéma de réplication multithread, sql_thread a évolué vers plusieurs threads
2. Problème de réplication circulaire
Structure double M :
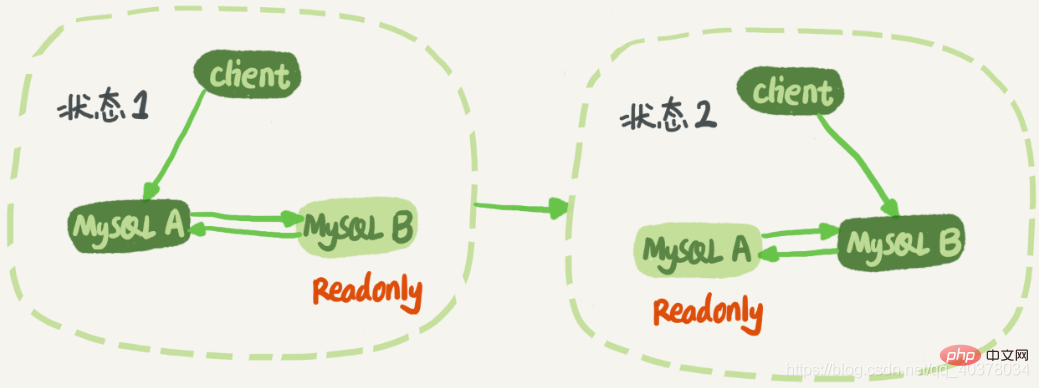
Le nœud A et le nœud B ont une relation maître-veille l'un avec l'autre. De cette façon, il n'est pas nécessaire de modifier la relation actif-veille pendant le changement. Il y a un problème à résoudre dans la structure double-M. La logique métier met à jour une instruction sur le nœud A, puis envoie le binlog généré à. nœud B. Après l'exécution du nœud B, ce Binlog sera également généré après les instructions de mise à jour. Ensuite, si le nœud A est également la base de données de secours du nœud B, cela équivaut à prendre le binlog nouvellement généré du nœud B et à l'exécuter une fois. Ensuite, l'instruction de mise à jour sera exécutée en continu dans une boucle entre les nœuds A et B, c'est-à-dire. c'est-à-dire la réplication en boucle
MySQL enregistre l'identifiant du serveur de l'instance où cette commande a été exécutée pour la première fois dans le binlog. Par conséquent, la logique suivante peut être utilisée pour résoudre le problème de réplication circulaire entre deux nœuds :
1. Il est stipulé que les ID de serveur des deux bibliothèques doivent être différents s'ils sont identiques, ils ne peuvent pas être définis comme maître. -relation de sauvegarde
2. Une base de données de secours reçoit le binlog et, pendant le processus de relecture, génère un nouveau binlog avec le même ID de serveur que le binlog d'origine
3. Après que chaque base de données ait reçu le journal envoyé par sa base de données principale, elle est d'abord envoyée. détermine Si l'identifiant du serveur est le même que le vôtre, cela signifie que le journal a été généré par vous-même, alors supprimez simplement le journal directement
Le flux d'exécution du journal de la structure double M est le suivant :
1. du nœud A sont enregistrés dans l'identifiant du serveur binlog A
2 Après avoir été envoyé une fois au nœud B pour exécution, l'identifiant du serveur du journal binaire généré par le nœud B est également l'identifiant du serveur A
3. Le nœud A et A détermine que l'identifiant du serveur est le même que le sien. Ce journal ne sera plus traité. Par conséquent, la boucle infinie est rompue ici
3. Les retards primaires et secondaires
Les points temporels liés à la synchronisation des données comprennent principalement les trois suivants :
1. La base de données principale A termine une transaction et l'écrit dans le binlog. Ce moment est enregistré comme T1
2. base de données de secours B et la base de données de secours Le moment où B finit de recevoir le binlog est enregistré comme T2
3 Une fois que la base de données de secours B a terminé la transaction, le moment est enregistré comme T3
Le délai dit de sauvegarde principale est. l'heure à laquelle l'exécution de la même transaction est terminée dans la base de données de secours et la base de données maître La différence entre l'heure de fin d'exécution, c'est-à-dire T3-T1
Vous pouvez exécuter la commande show slave status sur la base de données de secours, et son le résultat du retour affichera seconds_behind_master, qui est utilisé pour indiquer combien de secondes la base de données de veille actuelle est retardée
seconds_behind_master La méthode de calcul est la suivante :
1. Il y a un champ d'heure dans le journal binaire de chaque transaction, qui est utilisé pour enregistrer l'heure écrite dans la base de données principale
2 La base de données de veille extrait la valeur du champ d'heure de la transaction en cours d'exécution et calcule. sa différence avec l'heure système actuelle. Différence, obtenez seconds_behind_master
Si les paramètres d'heure système des machines de base de données maître et de sauvegarde sont incohérents, les valeurs de délai maître et de sauvegarde ne seront pas inexactes. Lorsque la base de données de secours est connectée à la base de données principale, elle obtiendra l'heure système de la base de données primaire actuelle via la fonction SELECTUNIX_TIMESTAMP(). S'il s'avère à ce moment que l'heure système de la base de données principale est incohérente avec la sienne, la base de données de secours déduira automatiquement cette différence lors de l'exécution du calcul seconds_behind_master
Dans des conditions normales de réseau, la principale source de délai entre l'heure active et l'heure de veille bases de données est le temps après que la base de données de secours reçoit le journal binaire et termine l'exécution. La différence de temps entre cette transaction
La manifestation la plus directe du délai de sauvegarde principale est que la vitesse à laquelle la base de données de sauvegarde consomme les journaux de transfert est plus lente que la base de données de secours. vitesse à laquelle la base de données principale produit des binlogs
2. La raison initiale du retard de sauvegarde principale
1 Certaines Dans les conditions de déploiement, les performances de la machine sur laquelle se trouve la base de données de secours sont pires que celles de la machine. où se trouve la base de données principale. 2. La base de données de secours est soumise à une plus grande pression. La base de données principale offre des capacités d'écriture et la base de données de secours offre des capacités de lecture. En ignorant le contrôle de pression de la base de données de secours, la requête sur la base de données de secours consomme beaucoup de ressources CPU, affecte la vitesse de synchronisation et provoque le retard du maître et de la sauvegarde. Le traitement suivant peut être effectué :
Un maître et une sauvegarde. plusieurs esclaves. En plus de la base de données de secours, vous pouvez connecter plusieurs bibliothèques esclaves supplémentaires pour partager la pression de lectureSortie vers des systèmes externes via binlog, tels que Hadoop, afin que le système externe puisse fournir des capacités de requêtes statistiques- 3 .Grande entreprise. Parce que la base de données principale doit attendre que la transaction soit exécutée avant qu'elle ne soit écrite dans le binlog puis transmise à la base de données de secours. Par conséquent, si une instruction sur la base de données principale est exécutée pendant 10 minutes, alors cette transaction est susceptible de provoquer un retard de 10 minutes sur la base de données esclave. Scénario typique de transaction importante : utilisation de l'instruction delete pour supprimer trop de données et de DDL d'un. grande table à la fois
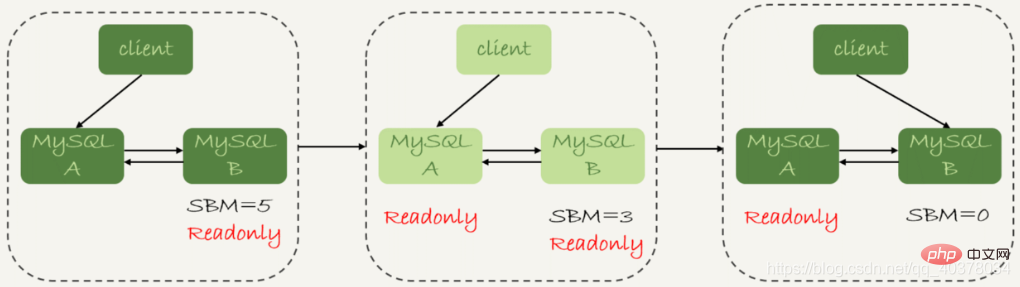
Sous la structure double M, le processus détaillé de passage de l'état 1 à l'état 2 est le suivant :
1. . Déterminez le seconds_behind_master actuel de la base de données de secours B, si s'il est inférieur à une certaine valeur, passez à l'étape suivante, sinon continuez à réessayer cette étape2 Changez la bibliothèque principale A en lecture seule, c'est-à-dire. , définissez la lecture seule sur true
3. Déterminez la valeur de seconds_behind_master de la bibliothèque de veille B jusqu'à ce qu'elle devienne 0
4. Changez la base de données de veille B en état de lecture-écriture, c'est-à-dire définissez la lecture seule sur false
. 5. Basculez la demande commerciale vers la base de données de veille B
Y a-t-il une indisponibilité dans ce processus de changement de temps ? Après l'étape 2, la base de données principale A et la base de données de secours B sont en lecture seule, ce qui signifie que le système est dans un état non inscriptible et ne peut pas être restauré tant que l'étape 5 n'est pas terminée. Dans cet état d'indisponibilité, l'étape la plus chronophage est l'étape 3, qui peut prendre plusieurs secondes. C'est pourquoi nous devons d'abord porter un jugement à l'étape 1 pour nous assurer que la valeur de seconds_behind_master est suffisamment petite
Le temps d'indisponibilité du système est déterminé par cette stratégie de priorité de fiabilité des données
 2. Stratégie de priorité de disponibilité : Si forcer les étapes 4 et 5 de la stratégie de priorité de fiabilité à exécuter au tout début, c'est-à-dire sans attendre la synchronisation des données primaires et secondaires, basculer directement la connexion vers la base de secours B, et en permettant à la base de données de secours B de lire et d'écrire, le système n'aura presque aucun problème de temps d'utilisation. Le coût de ce processus de changement est qu'une incohérence des données peut survenir
2. Stratégie de priorité de disponibilité : Si forcer les étapes 4 et 5 de la stratégie de priorité de fiabilité à exécuter au tout début, c'est-à-dire sans attendre la synchronisation des données primaires et secondaires, basculer directement la connexion vers la base de secours B, et en permettant à la base de données de secours B de lire et d'écrire, le système n'aura presque aucun problème de temps d'utilisation. Le coût de ce processus de changement est qu'une incohérence des données peut survenir
mysql> CREATE TABLE `t` ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT, `c` int(11) unsigned DEFAULT NULL, PRIMARY KEY (`id`)) ENGINE=InnoDB;insert into t(c) values(1),(2),(3);Le tableau t définit un identifiant de clé primaire à incrémentation automatique. Une fois les données initialisées, il y a 3 lignes de données dans la base de données principale et la base de données de secours. Continuez à exécuter deux commandes d'instruction d'insertion sur la table t, dans l'ordre :
insert into t(c) values(4);insert into t(c) values(5);Supposons qu'il y ait un grand nombre de mises à jour d'autres tables de données sur la base de données principale, ce qui fait que le délai de veille principale atteint 5 secondes. Après avoir inséré une instruction avec c=4, le basculement actif/veille est initié
La figure suivante montre le processus de commutation et les résultats des données lorsque la stratégie de priorité de disponibilité et binlog_format=mixed
1. À l'étape 2, la bibliothèque principale A se termine l'instruction insert, en insérant une ligne de données (4,4), puis en démarrant le commutateur actif-veille
2 À l'étape 3, en raison du délai de 5 secondes entre l'actif et le veille, la base de données de veille B n'a pas eu. il est temps d'appliquer l'insertion de c=4 Après avoir transféré le journal, elle commence à recevoir la commande du client pour insérer c=5
3 À l'étape 4, la base de données de secours B insère une ligne de données (4,5) et l'envoie. binlog vers la base de données principale A
4. Étape 5, la base de données de secours B exécute l'insertion du journal de transfert c=4 et insère une ligne de données (5,4). L'instruction insert c=5 qui est directement exécutée dans la base de données de secours B est transmise à la base de données principale A et une nouvelle ligne de données (5,5) est insérée. Le résultat final est que deux lignes apparaissent sur la base de données principale A. et la base de données de veille B. Lignes de données incohérentes
Stratégie de priorité de disponibilité, définissez binlog_format=row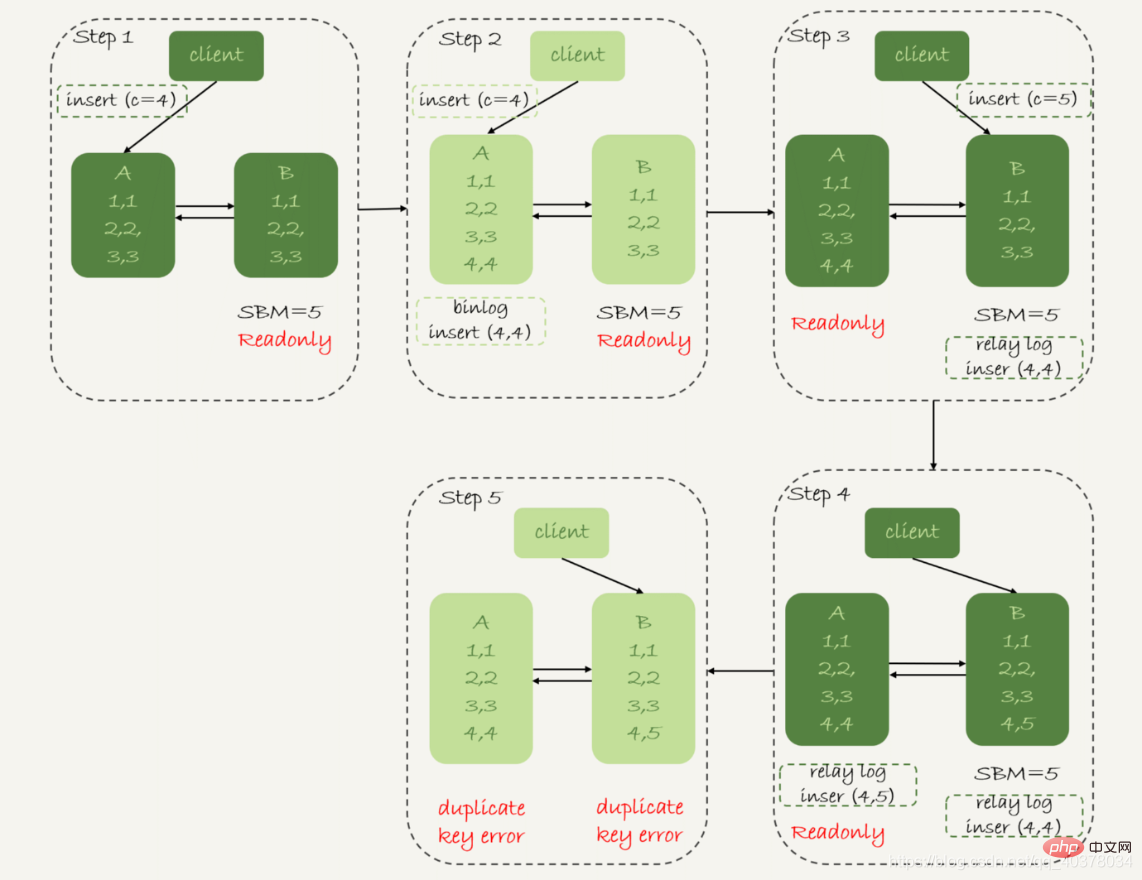
Par conséquent, lorsque le format de ligne enregistre binlog, il enregistrera toutes les valeurs de champ des lignes nouvellement insérées, donc à la fin il n'y aura qu'une seule ligne incohérente . De plus, les threads d'application de la synchronisation active et en veille des deux côtés signaleront une erreur de clé en double et s'arrêteront. En d'autres termes, dans ce cas, les deux lignes de données (5,4) dans la base de données de secours B et (5,5) dans la base de données primaire A ne seront pas exécutées par l'autre partie
Résumé
. 1. Lorsque vous utilisez binlog au format ligne, les problèmes d'incohérence des données sont plus faciles à détecter. Lors de l'utilisation d'un binlog au format mixte ou au format d'instruction, la découverte du problème d'incohérence des données peut prendre beaucoup de temps
2 La stratégie de priorité de disponibilité du basculement actif/veille entraînera une incohérence des données. Par conséquent, dans la plupart des cas, il est recommandé d'adopter une stratégie axée sur la fiabilité
5. La stratégie de réplication parallèle de MySQL
Ce à quoi vous devez faire attention, ce sont les deux flèches noires dans l'image ci-dessus pour le parallèle capacités de réplication des serveurs principal et secondaire. L'un représente l'écriture du client dans la base de données principale et l'autre représente le journal de transfert d'exécution sql_thread sur la base de données de secours. Avant la version 5.6 de MySQL, MySQL ne prenait en charge que la réplication monothread. Par conséquent, de sérieux problèmes survenaient lorsque la simultanéité de la base de données principale et TPS. étaient élevés. Le problème de délai principal et de sauvegarde
Le mécanisme de réplication multithread divise le sql_thread avec un seul thread en plusieurs threads, ce qui est conforme au modèle suivant :
Le coordinateur est le sql_thread d'origine, mais maintenant ce n'est plus le cas. met plus à jour les données directement, uniquement responsable de la lecture du journal de transit et de la distribution des transactions. Ce qui met réellement à jour le journal devient le thread de travail. Le nombre de threads de travail est déterminé par le paramètre slave_parallel_workers. Lors de la distribution, le coordinateur doit répondre aux deux exigences de base suivantes : 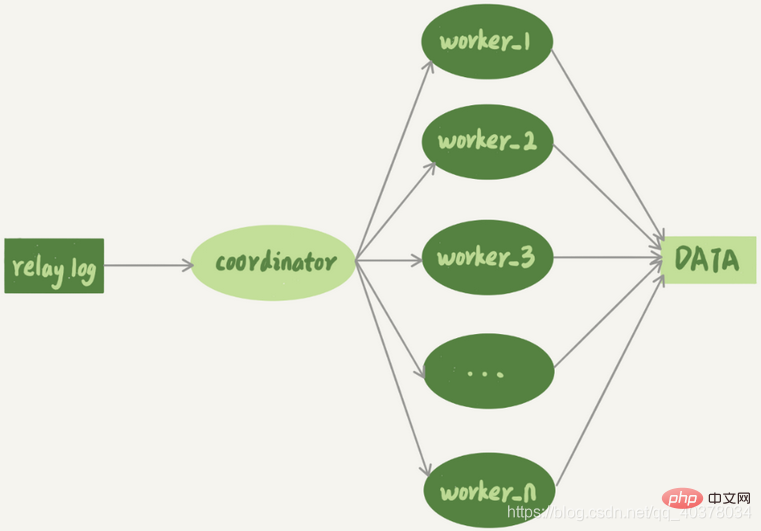
- 1 Stratégie de réplication parallèle de MySQL version 5.6
MySQL. la version 5.6 prend en charge la réplication parallèle, mais la granularité prise en charge est parallèle par base de données. Dans la table de hachage utilisée pour déterminer la stratégie de distribution, la clé est le nom de la base de donnéesL'effet parallèle de cette stratégie dépend du modèle de pression. S'il y a plusieurs bases de données sur la base de données principale et que la pression de chaque base de données est équilibrée, l'effet de l'utilisation de cette stratégie sera très bon
Deux avantages de cette stratégie :
La construction de la valeur de hachage est très rapide, seule la le nom de la bibliothèque est nécessaireLe format de binlog n'est pas requis, car binlog au format instruction peut également facilement obtenir le nom de la bibliothèque
- Vous pouvez créer différentes bases de données, répartir uniformément les tables avec la même popularité dans ces différentes bases de données et l'utiliser stratégie de force
optimisation de la soumission des groupes de journaux redo, et la stratégie de réplication parallèle de MariaDB profite de cette fonctionnalité :
Les transactions qui peuvent être soumises dans le même groupe ne modifieront certainement pas la même ligne Les transactions principales qui peuvent être exécutées en parallèle sur la base de données doivent également être exécutées en parallèle sur la base de données de secours. En termes d'implémentation, MariaDB fait ceci :- 1 Les transactions soumises ensemble dans un groupe ont le même commit_id. Le groupe est commit_id+1
- 2. Commit_id est écrit directement dans le binlog
En veille Lors de l'exécution sur la bibliothèque, le deuxième groupe de transactions doit attendre que le premier groupe de transactions soit complètement exécuté, le débit du système n'est donc pas suffisant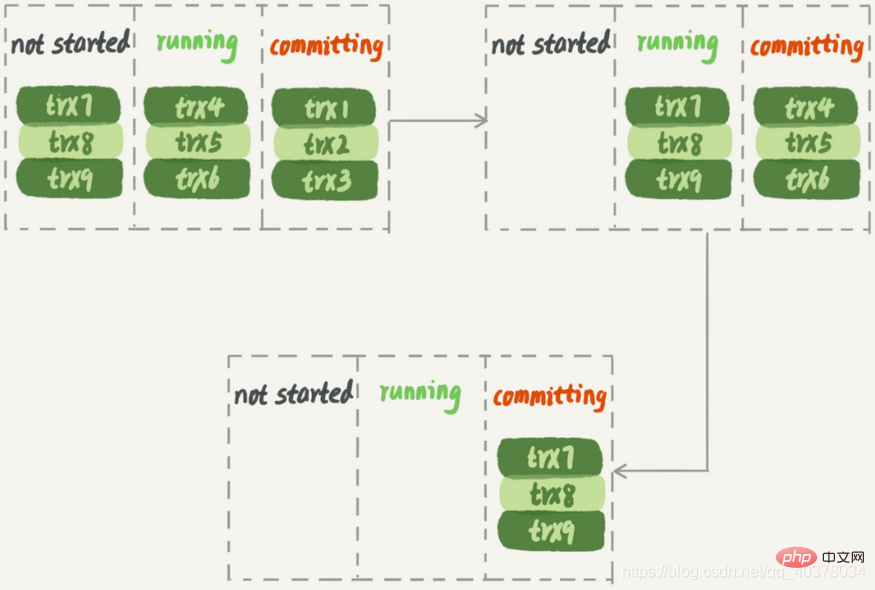
De plus, cette solution est facilement gênée par les transactions volumineuses. En supposant que trx2 est une transaction très volumineuse, lorsque la base de données de secours est appliquée, une fois l'exécution de trx1 et trx3 terminée, le groupe suivant peut commencer l'exécution. Un seul thread de travail fonctionne, ce qui représente un gaspillage de ressources
3. Stratégie de réplication parallèle de la version MySQL5.7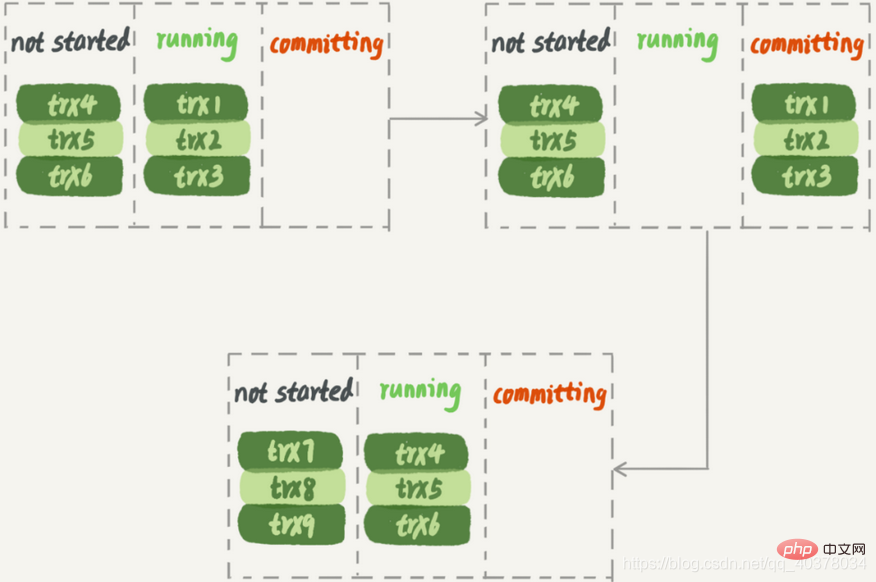
Configuré en tant que DATABASE signifie utiliser la stratégie parallèle base de données par base de données de la version MySQL 5.6 configurée en tant que LOGICAL_CLOCK, ce qui signifie une stratégie similaire à MariaDB. MySQL a été optimisé sur cette base. Toutes les transactions qui sont en cours d'exécution en même temps peuvent-elles être parallélisées ?
不可以,因为这里面可能有由于锁冲突而处于锁等待状态的事务。如果这些事务在备库上被分配到不同的worker,就会出现备库跟主库不一致的情况
而MariaDB这个策略的核心是所有处于commit状态的事务可以并行。事务处于commit状态表示已经通过了锁冲突的检验了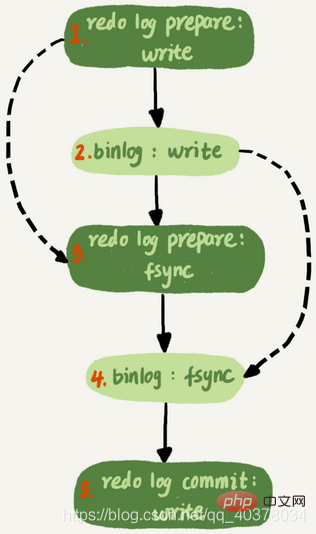
其实只要能够达到redo log prepare阶段就表示事务已经通过锁冲突的检验了
因此,MySQL5.7并行复制策略的思想是:
1.同时处于prepare状态的事务,在备库执行时是可以并行的
2.处于prepare状态的事务,与处于commit状态的事务之间,在备库执行时也是可以并行的
binlog组提交的时候有两个参数:
- binlog_group_commit_sync_delay参数表示延迟多少微妙后才调用fsync
- binlog_group_commit_sync_no_delay_count参数表示基类多少次以后才调用fsync
这两个参数是用于故意拉长binlog从write到fsync的时间,以此减少binlog的写盘次数。在MySQL5.7的并行复制策略里,它们可以用来制造更多的同时处于prepare阶段的事务。这样就增加了备库复制的并行度。也就是说,这两个参数既可以故意让主库提交得慢些,又可以让备库执行得快些
4、MySQL5.7.22的并行复制策略
MySQL5.7.22增加了一个新的并行复制策略,基于WRITESET的并行复制,新增了一个参数binlog-transaction-dependency-tracking用来控制是否启用这个新策略。这个参数的可选值有以下三种:
- COMMIT_ORDER,根据同时进入prepare和commit来判断是否可以并行的策略
- WRITESET,表示的是对于事务涉及更新的每一行,计算出这一行的hash值,组成集合writeset。如果两个事务没有操作相同的行,也就是说它们的writeset没有交集,就可以并行
- WRITESET_SESSION,是在WRITESET的基础上多了一个约束,即在主库上同一个线程先后执行的两个事务,在备库执行的时候,要保证相同的先后顺序
为了唯一标识,hash值是通过库名+表名+索引名+值计算出来的。如果一个表上除了有主键索引外,还有其他唯一索引,那么对于每个唯一索引,insert语句对应的writeset就要多增加一个hash值
1.writeset是在主库生成后直接写入到binlog里面的,这样在备库执行的时候不需要解析binlog内容
2.不需要把整个事务的binlog都扫一遍才能决定分发到哪个worker,更省内存
3.由于备库的分发策略不依赖于binlog内容,索引binlog是statement格式也是可以的
对于表上没主键和外键约束的场景,WRITESET策略也是没法并行的,会暂时退化为单线程模型
六、主库出问题了,从库怎么办?
下图是一个基本的一主多从结构
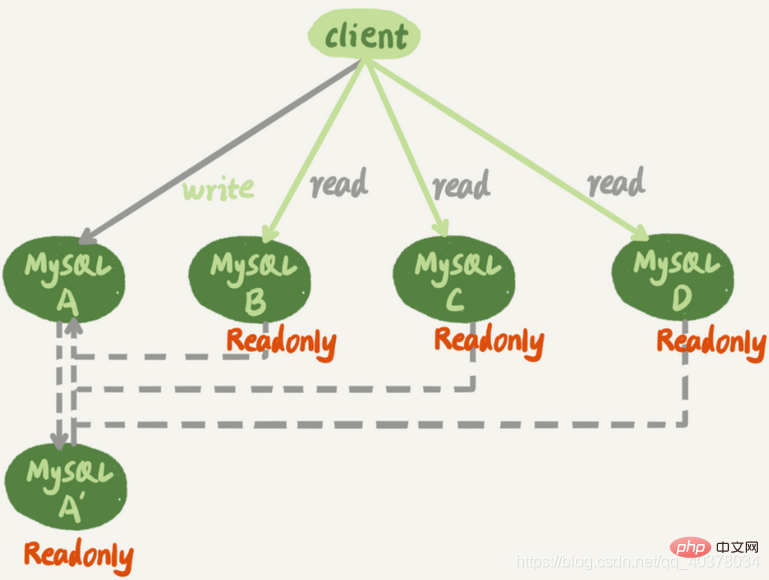
图中,虚线箭头表示的是主备关系,也就是A和A’互为主备,从库B、C、D指向的是主库A。一主多从的设置,一般用于读写分离,主库负责所有的写入和一部分读,其他的读请求则由从库分担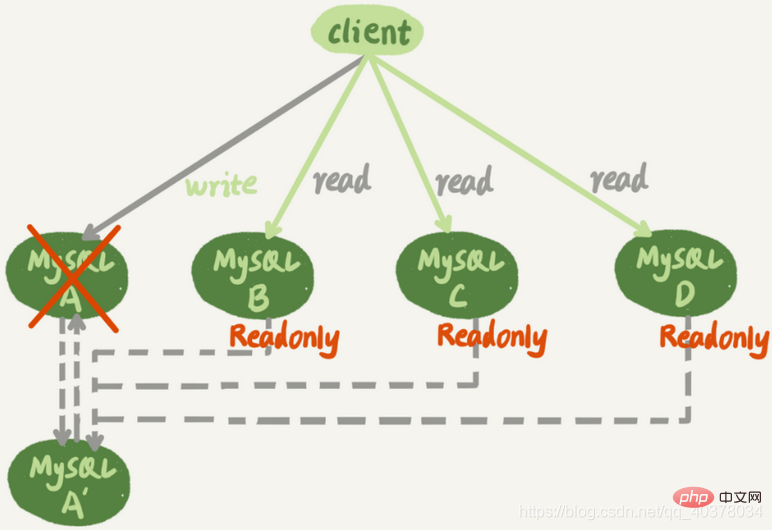
一主多从结构在切换完成后,A’会成为新的主库,从库B、C、D也要改接到A’
1、基于位点的主备切换
当我们把节点B设置成节点A’的从库的时候,需要执行一条change master命令:
CHANGE MASTER TO MASTER_HOST=$host_name MASTER_PORT=$port MASTER_USER=$user_name MASTER_PASSWORD=$password MASTER_LOG_FILE=$master_log_name MASTER_LOG_POS=$master_log_pos
- MASTER_HOST、MASTER_PORT、MASTER_USER和MASTER_PASSWORD四个参数,分别代表了主库A’的IP、端口、用户名和密码
- 最后两个参数MASTER_LOG_FILE和MASTER_LOG_POS表示,要从主库的master_log_name文件的master_log_pos这个位置的日志继续同步。而这个位置就是所说的同步位点,也就是主库对应的文件名和日志偏移量
找同步位点很难精确取到,只能取一个大概位置。一种去同步位点的方法是这样的:
1.等待新主库A’把中转日志全部同步完成
2.在A’上执行show master status命令,得到当前A’上最新的File和Position
3.取原主库A故障的时刻T
4.用mysqlbinlog工具解析A’的File,得到T时刻的位点,这个值就可以作为$master_log_pos
这个值并不精确,有这么一种情况,假设在T这个时刻,主库A已经执行完成了一个insert语句插入了一行数据R,并且已经将binlog传给了A’和B,然后在传完的瞬间主库A的主机就掉电了。那么,这时候系统的状态是这样的:
1.在从库B上,由于同步了binlog,R这一行已经存在
2.在新主库A’上,R这一行也已经存在,日志是写在master_log_pos这个位置之后的
3.在从库B上执行change master命令,指向A’的File文件的master_log_pos位置,就会把插入R这一行数据的binlog又同步到从库B去执行,造成主键冲突,然后停止tongue
通常情况下,切换任务的时候,要先主动跳过这些错误,有两种常用的方法
一种是,主动跳过一个事务
set global sql_slave_skip_counter=1;start slave;
另一种方式是,通过设置slave_skip_errors参数,直接设置跳过指定的错误。这个背景是,我们很清楚在主备切换过程中,直接跳过这些错误是无损的,所以才可以设置slave_skip_errors参数。等到主备间的同步关系建立完成,并稳定执行一段时间之后,还需要把这个参数设置为空,以免之后真的出现了主从数据不一致,也跳过了
2、GTID
MySQL5.6引入了GTID,是一个全局事务ID,是一个事务提交的时候生成的,是这个事务的唯一标识。它的格式是:
GTID=source_id:transaction_id
- source_id是一个实例第一次启动时自动生成的,是一个全局唯一的值
- transaction_id是一个整数,初始值是1,每次提交事务的时候分配给这个事务,并加1
GTID模式的启动只需要在启动一个MySQL实例的时候,加上参数gtid_mode=on和enforce_gtid_consistency=on就可以了
在GTID模式下,每个事务都会跟一个GTID一一对应。这个GTID有两种生成方式,而使用哪种方式取决于session变量gtid_next的值
1.如果gtid_next=automatic,代表使用默认值。这时,MySQL就把GTID分配给这个事务。记录binlog的时候,先记录一行SET@@SESSION.GTID_NEXT=‘GTID’。把这个GTID加入本实例的GTID集合
2.如果gtid_next是一个指定的GTID的值,比如通过set gtid_next=‘current_gtid’,那么就有两种可能:
- 如果current_gtid已经存在于实例的GTID集合中,接下里执行的这个事务会直接被系统忽略
- 如果current_gtid没有存在于实例的GTID集合中,就将这个current_gtid分配给接下来要执行的事务,也就是说系统不需要给这个事务生成新的GTID,因此transaction_id也不需要加1
一个current_gtid只能给一个事务使用。这个事务提交后,如果要执行下一个事务,就要执行set命令,把gtid_next设置成另外一个gtid或者automatic
这样每个MySQL实例都维护了一个GTID集合,用来对应这个实例执行过的所有事务
3、基于GTID的主备切换
在GTID模式下,备库B要设置为新主库A’的从库的语法如下:
CHANGE MASTER TO MASTER_HOST=$host_name MASTER_PORT=$port MASTER_USER=$user_name MASTER_PASSWORD=$password master_auto_position=1
其中master_auto_position=1就表示这个主备关系使用的是GTID协议
实例A’的GTID集合记为set_a,实例B的GTID集合记为set_b。我们在实例B上执行start slave命令,取binlog的逻辑是这样的:
1.实例B指定主库A’,基于主备协议建立连接
2.实例B把set_b发给主库A’
3.实例A’算出set_a与set_b的差集,也就是所有存在于set_a,但是不存在于set_b的GTID的集合,判断A’本地是否包含了这个差集需要的所有binlog事务
- 如果不包含,表示A’已经把实例B需要的binlog给删掉了,直接返回错误
- 如果确认全部包含,A’从自己的binlog文件里面,找出第一个不在set_b的事务,发给B
4.之后从这个事务开始,往后读文件,按顺序取binlog发给B去执行
4、GTID和在线DDL
如果是由于索引缺失引起的性能问题,可以在线加索引来解决。但是,考虑到要避免新增索引对主库性能造成的影响,可以先在备库加索引,然后再切换,在双M结构下,备库执行的DDL语句也会传给主库,为了避免传回后对主库造成影响,要通过set sql_log_bin=off关掉binlog,但是操作可能会导致数据和日志不一致
两个互为主备关系的库实例X和实例Y,且当前主库是X,并且都打开了GTID模式。这时的主备切换流程可以变成下面这样:
- 在实例X上执行stop slave
- 在实例Y上执行DDL语句。这里不需要关闭binlog
- 执行完成后,查出这个DDL语句对应的GTID,记为source_id_of_Y:transaction_id
- 到实例X上执行一下语句序列:
set GTID_NEXT="source_id_of_Y:transaction_id";begin;commit;set gtid_next=automatic;start slave;
这样做的目的在于,既可以让实例Y的更新有binlog记录,同时也可以确保不会在实例X上执行这条更新
七、MySQL读写分离
读写分离的基本结构如下图:
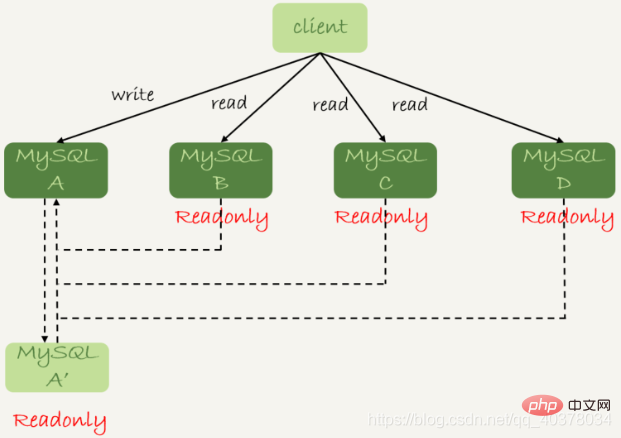
读写分离的主要目的就是分摊主库的压力。上图中的结构是客户端主动做负载均衡,这种模式下一般会把数据库的连接信息放在客户端的连接层。由客户端来选择后端数据库进行查询
还有一种架构就是在MySQL和客户端之间有一个中间代理层proxy,客户端只连接proxy,由proxy根据请求类型和上下文决定请求的分发路由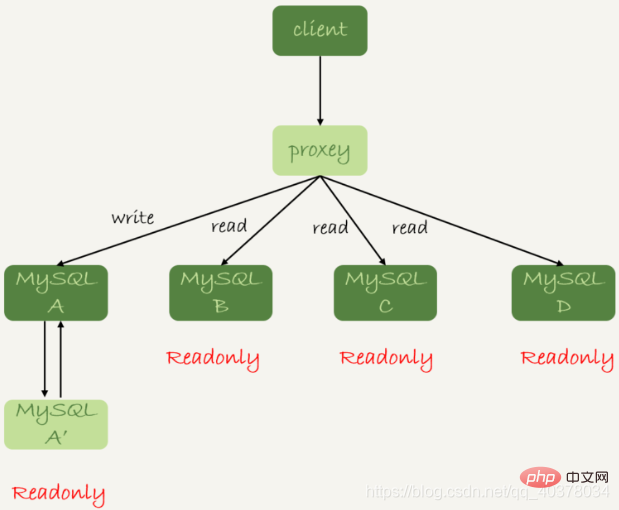
1.客户端直连方案,因此少了一层proxy转发,所以查询性能稍微好一点,并且整体架构简单,排查问题更方便。但是这种方案,由于要了解后端部署细节,所以在出现主备切换、库迁移等操作的时候,客户端都会感知到,并且需要调整数据库连接信息。一般采用这样的架构,一定会伴随一个负责管理后端的组件,比如Zookeeper,尽量让业务端只专注于业务逻辑开发
2.带proxy的架构,对客户端比较友好。客户端不需要关注后端细节,连接维护、后端信息维护等工作,都是由proxy完成的。但这样的话,对后端维护团队的要求会更高,而且proxy也需要有高可用架构
在从库上会读到系统的一个过期状态的现象称为过期读
1、强制走主库方案
强制走主库方案其实就是将查询请求做分类。通常情况下,可以分为这么两类:
1.对于必须要拿到最新结果的请求,强制将其发到主库上
2.对于可以读到旧数据的请求,才将其发到从库上
这个方案最大的问题在于,有时候可能会遇到所有查询都不能是过期读的需求,比如一些金融类的业务。这样的话,就需要放弃读写分离,所有读写压力都在主库,等同于放弃了扩展性
2、Sleep方案
主库更新后,读从库之前先sleep一下。具体的方案就是,类似于执行一条select sleep(1)命令。这个方案的假设是,大多数情况下主备延迟在1秒之内,做一个sleep可以很大概率拿到最新的数据
以买家发布商品为例,商品发布后,用Ajax直接把客户端输入的内容作为最新商品显示在页面上,而不是真正地去数据库做查询。这样,卖家就可以通过这个显示,来确认产品已经发布成功了。等到卖家再刷新页面,去查看商品的时候,其实已经过了一段时间,也就达到了sleep的目的,进而也就解决了过期读的问题
但这个方案并不精确:
1.如果这个查询请求本来0.5秒就可以在从库上拿到正确结果,也会等1秒
2.如果延迟超过1秒,还是会出现过期读
3、判断主备无延迟方案
show slave status结果里的seconds_behind_master参数的值,可以用来衡量主备延迟时间的长短
1.第一种确保主备无延迟的方法是,每次从库执行查询请求前,先判断seconds_behind_master是否已经等于0。如果还不等于0,那就必须等到这个参数变为0才能执行查询请求
show slave status结果的部分截图如下:
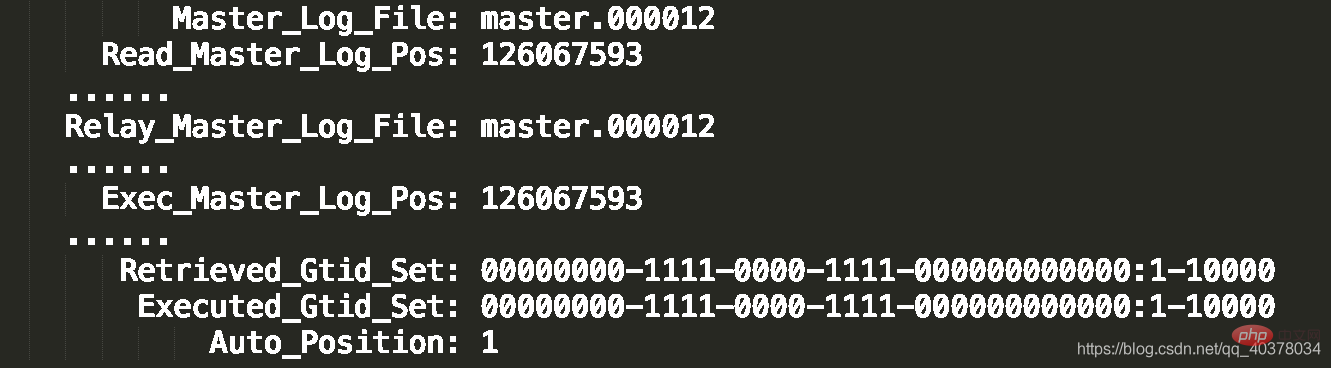
2.第二种方法,对比位点确保主备无延迟:
- Master_Log_File和Read_Master_Log_Pos表示的是读到的主库的最新位点
- Relay_Master_Log_File和Exec_Master_Log_Pos表示的是备库执行的最新位点
如果Master_Log_File和Read_Master_Log_Pos和Relay_Master_Log_File和Exec_Master_Log_Pos这两组值完全相同,就表示接收到的日志已经同步完成
3.第三种方法,对比GTID集合确保主备无延迟:
- Auto_Position=1表示这堆主备关系使用了GTID协议
- Retrieved_Gitid_Set是备库收到的所有日志的GTID集合
- Executed_Gitid_Set是备库所有已经执行完成的GTID集合
如果这两个集合相同,也表示备库接收到的日志都已经同步完成
4.一个事务的binlog在主备库之间的状态:
1)主库执行完成,写入binlog,并反馈给客户端
2)binlog被从主库发送给备库,备库收到
3)在备库执行binlog完成
上面判断主备无延迟的逻辑是备库收到的日志都执行完成了。但是,从binlog在主备之间状态的分析中,有一部分日志,处于客户端已经收到提交确认,而备库还没收到日志的状态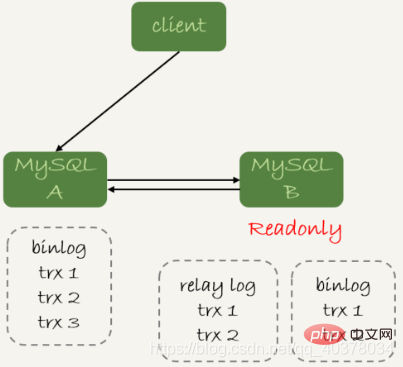
这时,主库上执行完成了三个事务trx1、trx2和trx3,其中:
- trx1和trx2已经传到从库,并且已经执行完成了
- trx3在主库执行完成,并且已经回复给客户端,但是还没有传到从库中
如果这时候在从库B上执行查询请求,按照上面的逻辑,从库认为已经没有同步延迟,但还是查不到trx3的
4、配合semi-sync
要解决上面的问题,就要引入半同步复制。semi-sync做了这样的设计:
1.事务提交的时候,主库把binlog发送给从库
2.从库收到binlog以后,发回给主库一个ack,表示收到了
3.主库收到这个ack以后,才能给客户端返回事务完成的确认
如果启用了semi-sync,就表示所有给客户端发送过确认的事务,都确保了备库已经收到了这个日志
semi-sync+位点判断的方案,只对一主一备的场景是成立的。在一主多从场景中,主库只要等到一个从库的ack,就开始给客户端返回确认。这时,在从库上执行查询请求,就有两种情况:
1.如果查询是落在这个响应了ack的从库上,是能够确保读到最新数据
2.但如果查询落到其他从库上,它们可能还没有收到最新的日志,就会产生过期读的问题
判断同步位点的方案还有另外一个潜在的问题,即:如果在业务更新的高峰期,主库的位点或者GTID集合更新很快,那么上面的两个位点等值判断就会一直不成立,很有可能出现从库上迟迟无法响应查询请求的情况
上图从状态1到状态4,一直处于延迟一个事务的状态。但是,其实客户端是在发完trx1更新后发起的select语句,我们只需要确保trx1已经执行完成就可以执行select语句了。也就是说,如果在状态3执行查询请求,得到的就是预期结果了
semi-sync配合主备无延迟的方案,存在两个问题:
1.一主多从的时候,在某些从库执行查询请求会存在过期读的现象
2.在持续延迟的情况下,可能出现过度等待的问题
5、等主库位点方案
select master_pos_wait(file, pos[, timeout]);
这条命令的逻辑如下:
1.它是在从库执行的
2.参数file和pos指的是主库上的文件名和位置
3.timeout可选,设置为正整数N表示这个函数最多等待N秒
这个命令正常返回的结果是一个正整数M,表示从命令开始执行,到应用完file和pos表示的binlog位置,执行了多少事务
1.如果执行期间,备库同步线程发生异常,则返回NULL
2.如果等待超过N秒,就返回-1
3.如果刚开始执行的时候,就发现已经执行过这个位置了,则返回0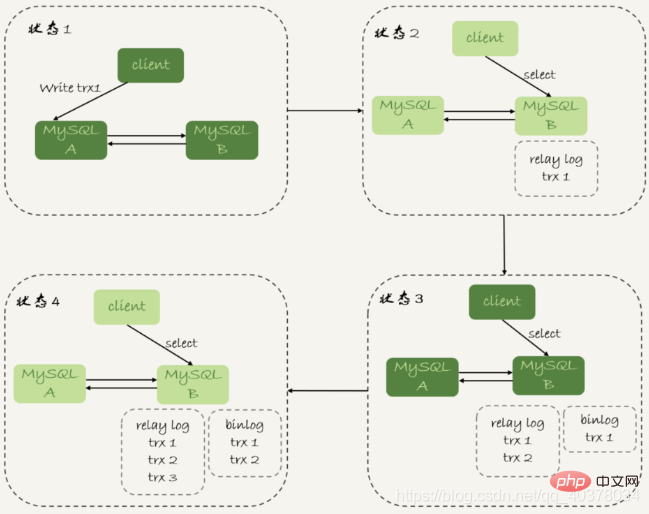
对于上图中先执行trx1,再执行一个查询请求的逻辑,要保证能够查到正确的数据,可以使用这个逻辑:
1.trx1事务更新完成后,马上执行show master status得到当前主库执行到的File和Position
2.选定一个从库执行查询语句
3.在从库上执行select master_pos_wait(file, pos, 1)
4.如果返回值是>=0的正整数,则在这个从库执行查询语句
5.否则,到主库执行查询语句
流程如下:
6、GTID方案
select wait_for_executed_gtid_set(gtid_set, 1);
这条命令的逻辑如下:
1.等待,直到这个库执行的事务中包含传入的gtid_set,返回0
2.超时返回1
等主库位点方案中,执行完事务后,还要主动去主库执行show master status。而MySQL5.7.6版本开始,允许在执行完更新类事务后,把这个事务的GTID返回给客户端,这样等GTID的方案可以减少一次查询
等GTID的流程如下:
1.trx1事务更新完成后,从返回包直接获取这个事务的GTID,记为gtid1
2.选定一个从库执行查询语句
3. Exécutez select wait_for_executed_gtid_set(gtid1, 1);
4. Si la valeur de retour est 0, exécutez l'instruction de requête dans cette bibliothèque esclave
5. pour plus de connaissances liées à la programmation, veuillez visiter :
Introduction à la programmation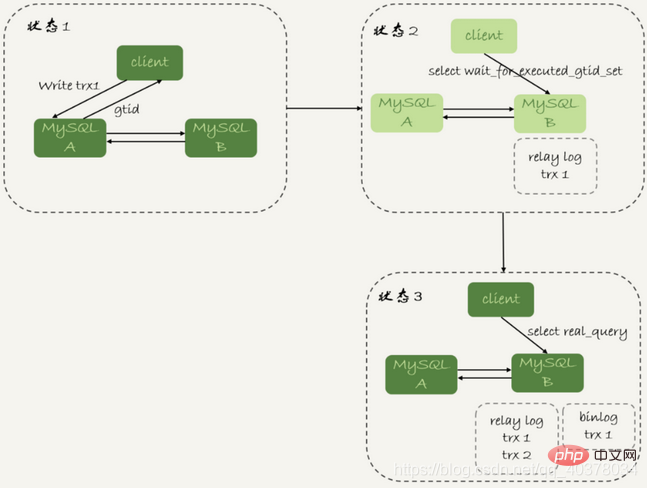 ! !
! !
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- En savoir plus sur l'incrémentation automatique des clés primaires dans MySQL
- Compréhension approfondie de l'algorithme d'instruction de jointure et des méthodes d'optimisation dans MySQL
- Parlons de l'isolation des transactions dans MySQL
- Compréhension approfondie des verrous dans MySQL (verrous globaux, verrous au niveau des tables, verrous de ligne)