
Maison >Opération et maintenance >exploitation et maintenance Linux >Comment fonctionne keepalived
Comment fonctionne keepalived

- 醉折花枝作酒筹original
- 2021-06-24 11:08:293861parcourir
Le principe de fonctionnement de keepalived est le suivant : détecter l'état de chaque nœud de service en fonction du mécanisme de commutation de troisième, quatrième et cinquième couches du modèle de référence TCP/IP. Si un nœud de serveur est anormal ou échoue, Keepalived le fera. Le nœud de serveur défaillant est détecté et supprimé du système de cluster.

L'environnement d'exploitation de ce tutoriel : système centos7, ordinateur thinkpad t480.
Introduction à Keepalived
Keepalived est la prochaine solution légère à haute disponibilité pour Linux. Haute disponibilité : Au sens large, cela fait référence à la haute disponibilité de l'ensemble du système ; au sens étroit, cela fait référence à la redondance et à la prise en charge de l'hôte.
Il implémente des fonctions similaires à HeartBeat, qui peuvent toutes deux atteindre une haute disponibilité des services ou des réseaux, mais il existe des différences. HeartBeat est un logiciel professionnel de haute disponibilité entièrement fonctionnel qui fournit les exigences de base pour le logiciel HA. Fonctions telles que : détection de battement de cœur, prise de contrôle de ressources, détection de services dans le cluster, transfert des propriétaires d'adresses IP partagées sur les nœuds du cluster, etc.
HeartBeat est puissant, mais le déploiement et l'utilisation sont relativement difficiles. Par rapport à HeartBeat, Keepalived implémente principalement des fonctions de haute disponibilité via une redondance de routage virtuel. Bien qu'il ne soit pas aussi puissant que HeartBeat, Keepalived est très simple à déployer et à utiliser. . Très simple, toutes les configurations ne nécessitent qu'un seul fichier de configuration.
Qu'est-ce que Keepalived ?
Keepalived a été initialement conçu pour LVS et est spécifiquement utilisé pour surveiller l'état de chaque nœud de service dans le système de cluster. Il est basé sur les mécanismes de commutation de troisième, quatrième et cinquième couches de TCP/IP. modèle de référence. Détectez l'état de chaque nœud de service. Si un nœud de serveur est anormal ou si le travail échoue, Keepalived le détectera et supprimera le nœud de serveur défaillant du système de cluster. Toutes ces tâches sont effectuées automatiquement et ne nécessitent aucune intervention manuelle. travail manuel uniquement pour réparer le nœud de service défaillant.
Plus tard, Keepalived a ajouté la fonction VRRP. Le but de VRRP (VritrualRouterRedundancyProtocol, protocole de redondance de routage virtuel) est de résoudre le problème de point de défaillance unique dans le routage statique, permettant ainsi un fonctionnement ininterrompu et stable du réseau. D'une part, Keepalvied dispose de fonctions de détection de l'état du serveur et d'isolation des pannes, et d'autre part, il dispose également de la fonction HAcluster.
Le contrôle de santé et le basculement sont les deux fonctions principales de keepalived. Le soi-disant contrôle de santé utilise une négociation à trois voies TCP, une requête ICMP, une requête HTTP, une requête d'écho UDP, etc. pour maintenir en vie le serveur réel derrière l'équilibreur de charge (généralement le serveur qui gère les activités réelles en cas d'échec de la commutation) ; principalement l'application Pour les équilibreurs de charge configurés en mode actif et en veille, VRRP est utilisé pour maintenir le rythme cardiaque des équilibreurs de charge actifs et en veille Lorsqu'un problème survient avec l'équilibreur de charge actif, l'équilibreur de charge en veille transporte les services correspondants, minimisant ainsi le trafic. perte et assurer la stabilité des services.
Protocole VRRP et principe de fonctionnement
Dans un environnement réseau réel. La communication entre les hôtes est complétée par la configuration du routage statique ou (passerelle par défaut). Une fois le routeur entre les hôtes défaillant, la communication échouera. Par conséquent, dans ce mode de communication, le routeur devient un goulot d'étranglement unique. Le protocole VRRP a été introduit.
Le protocole VRRP est un protocole de mode de sauvegarde maître tolérant aux pannes, qui garantit que lorsque la route du prochain saut de l'hôte échoue, un autre routeur remplacera le routeur défaillant et pourra être utilisé dans le réseau en cas de panne. se produit, la commutation de périphérique est effectuée de manière transparente sans affecter la communication de données entre les hôtes.
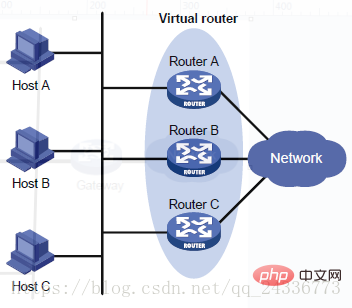
Routeur virtuel : Le routeur virtuel est un ensemble de tous les routeurs du groupe de sauvegarde VRRP. C'est un concept logique et n'existe pas vraiment. En regardant les routeurs du groupe de sauvegarde depuis l'extérieur du groupe de sauvegarde, on a l'impression que tous les routeurs du groupe ne font qu'un, ce qui peut être compris comme étant dans un groupe : routeur principal + tous les routeurs de sauvegarde = routeur virtuel.
Un routeur virtuel possède une adresse IP virtuelle et une adresse MAC. L'hôte utilise le routeur virtuel comme passerelle par défaut. Le format de l'adresse MAC virtuelle est 00-00-5E-00-01-{VRID}. Normalement, un routeur virtuel répond aux requêtes ARP en utilisant une adresse MAC virtuelle Ce n'est que lorsque le routeur virtuel est spécialement configuré qu'il répond à la véritable adresse MAC de l'interface.
Routeur principal (MASTER) : Le routeur virtuel fournit des services au monde extérieur via l'IP virtuelle. Au sein du routeur virtuel, il n'y a qu'un seul routeur physique qui fournit des services au monde extérieur en même temps. Le routeur physique qui fournit des services est appelé routeur maître. Généralement, le maître est généré par un algorithme d'élection. Il dispose d'une adresse IP virtuelle pour les services externes et fournit diverses fonctions réseau, telles que les requêtes ARP, le transfert de données ICMP, etc.
Routeur de sauvegarde (BACKUP) : les autres routeurs physiques du routeur virtuel n'ont pas d'adresses IP virtuelles externes et ne fournissent pas non plus de fonctions réseau externes. Ils acceptent uniquement les informations d'annonce d'état VRRP du MAÎTRE. En cas de panne du routeur principal, le routeur de secours dans le rôle BACKUP sera réélu pour générer un nouveau routeur principal pour entrer dans le rôle MASTER et continuer à fournir des services externes. L'ensemble du commutateur est complètement transparent pour les utilisateurs.
Mécanisme d'élection VRRP
Le routeur VRRP a trois états pendant le fonctionnement :
1. État d'initialisation : après le démarrage du système, il entre dans l'initialisation. Ceci Dans cet état, le routeur ne traite pas les messages VRRP ;
2. État maître
3. et le routeur de secours est dans l'état Sauvegarde.
VRRP utilise un mécanisme d'élection pour déterminer l'état du routeur :
1. Propriétaire IP dans le groupe VRRP. Si l'adresse IP virtuelle est la même que l'adresse IP d'un routeur VRRP du groupe VRRP, alors ce routeur est propriétaire de l'adresse IP et ce routeur sera positionné comme routeur maître.
2. Comparez les priorités. S'il n'y a pas de propriétaire d'adresse IP, comparez les priorités des routeurs. La plage de priorité est de 0 à 255. Celui avec la priorité la plus élevée sera utilisé comme routeur principal
3. Comparez les adresses IP. Dans le cas où il n’y a pas de propriétaire d’adresse IP et que la priorité est la même, celui avec la plus grande adresse IP fait office de routeur principal.
Comme le montre la figure ci-dessous, l'adresse IP virtuelle est 10.1.1.254. Il n'y a pas de propriétaire d'adresse IP dans le groupe VRRP. Il est évident que la priorité de RB et RA est supérieure. Comparez ensuite RA et RB. L'adresse IP de RB est plus grande. RB est donc le routeur principal du groupe.
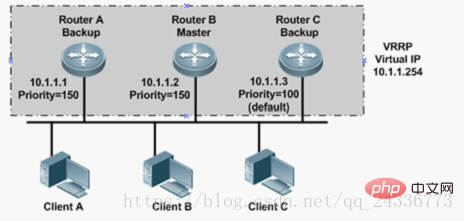
Une fois que le routeur utilise la fonction VRRP, il déterminera son rôle dans le groupe de sauvegarde en fonction de la priorité. Le routeur ayant la priorité la plus élevée devient le routeur maître et le routeur ayant la priorité la plus faible devient le routeur de secours. Le maître dispose d'une adresse IP virtuelle pour les services externes, fournit diverses fonctions réseau et envoie régulièrement des messages VRRP pour informer les autres appareils du groupe de sauvegarde qu'il fonctionne normalement ; le routeur de sauvegarde ne reçoit que les informations de message envoyées par le maître pour surveiller le fonctionnement de ; l'état du Maître. Lorsque le maître échoue, le routeur de sauvegarde fera son choix et la sauvegarde ayant la priorité la plus élevée deviendra le nouveau maître.
En mode préemption, lorsque le routeur de sauvegarde reçoit le message VRRP, il comparera sa propre priorité avec la priorité du message. S'il est supérieur à la priorité dans le message publicitaire, il deviendra le routeur Maître ; sinon il restera en état de Sauvegarde
En mode non préemption, tant que le routeur Maître ne tombe pas en panne, les routeurs du groupe de sauvegarde resteront toujours en statut Maître ou Sauvegarde, le routeur de sauvegarde ne deviendra pas le routeur Maître même s'il est ensuite configuré avec une priorité plus élevée
Si le routeur de sauvegarde ne reçoit pas le VRRP ; message envoyé par le routeur maître après l'expiration de son délai, il est considéré que le routeur maître ne fonctionne plus correctement. À ce moment-là, le routeur de secours pensera qu'il s'agit du routeur maître et enverra des paquets VRRP au monde extérieur. Les routeurs du groupe de sauvegarde élisent un routeur maître en fonction de la priorité pour assumer la fonction de transfert de paquets.
Principe de fonctionnement de KeepalviedPrincipe de fonctionnement de Keepalived pour l'état de fonctionnement du serveur et l'isolation des pannes :
Keepalived fonctionne dans la troisième phase de la référence TCP/IP modèle Couche 4, Couche 5 (couche physique, couche liaison) :
Couche réseau (3) : Keepalived envoie un paquet ICMP à chaque nœud du cluster de serveurs via le protocole ICMP (un peu similaire à la fonction Ping), si un nœud ne renvoie pas de paquet de réponse, on considère que le nœud a échoué. Keepalived signalera la défaillance du nœud et supprimera le nœud défaillant du cluster de serveurs.
Couche de transport (4) : Keepalived utilise la technologie de connexion de port et d'analyse du protocole TCP dans la couche de transport pour déterminer si le port du nœud du cluster est normal, comme le port 80 du serveur WEB commun. Ou le port de service SSH 22. Une fois que Keepalived détecte que ces numéros de port n'ont pas de réponse de données ou de retour de données au niveau de la couche de transport, il considérera ces ports comme anormaux, puis supprimera de force les nœuds correspondant à ces ports du cluster de serveurs.
Couche d'application (5) : le mode de fonctionnement de Keepalived est également plus complet et complexe. Les utilisateurs peuvent personnaliser le mode de fonctionnement de Keepalived. Par exemple, vous pouvez exécuter Keepalived en écrivant un programme ou un script, et Keepalived le fera. être exécuté selon les paramètres définis par l'utilisateur pour détecter si divers programmes ou services sont autorisés à fonctionner normalement. Si les résultats de détection de Keepalived ne correspondent pas aux paramètres de l'utilisateur, Keepalived supprimera le serveur correspondant du cluster de serveurs.
Architecture Keepalived
Keepalived a été initialement conçu pour LVS. Étant donné que Keepalived peut implémenter la détection de l'état des nœuds de cluster et qu'IPVS peut implémenter des fonctions d'équilibrage de charge, Keepalived s'appuie sur le module tiers. IPVS peut facilement créer un système d’équilibrage de charge. Le module IPVS de Keepalived est configurable Si vous avez besoin de la fonction d'équilibrage de charge, vous pouvez activer la fonction d'équilibrage de charge lors de la compilation de Keepalived, ou la désactiver via les paramètres de compilation.
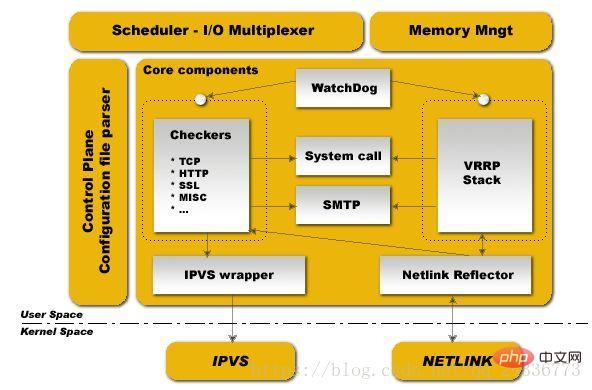
SchedulerI/OMultiplexer est un planificateur de distribution de multiplexage d'E/S, qui planifie toutes les demandes de tâches internes de Keepalived
Memory Mngt est un mécanisme de gestion de la mémoire, ce framework fournit certaines méthodes courantes d'accès à la mémoire ;
Control Plane est le plan de contrôle de keepalived, qui peut compiler et analyser les fichiers de configuration
Composants de base Cette partie comprend principalement 5 parties ; >
- Watchdog : C'est un outil de détection extrêmement simple et très efficace dans le domaine de la fiabilité informatique, qui surveille les Checkers et les processus VRRP à travers lui.
- Vérificateurs : Il s'agit de la fonction la plus basique de Keepalived et de la fonction la plus importante, qui peut détecter l'état de fonctionnement du serveur et isoler les pannes.
- Pile VRRP : Il s'agit de la fonction VRRP qui a été citée plus tard et qui peut réaliser la fonction de basculement dans le cluster HA. Responsable de la commutation de basculement entre les équilibreurs de charge FailOver ;
- Wrapper IPVS : Il s'agit d'une implémentation de la fonction IPVS. Le module IPVSwarrper enverra les règles IPVS définies à l'espace du noyau et les fournira. Le module IPVS réalise enfin la fonction de chargement du module IPVS.
- Netlink Reflector : utilisé pour implémenter la configuration et la commutation d'adresses IP virtuelles (VIP) pendant le basculement du cluster haute disponibilité
par rapport à heartbeat/corosync
Les trois composants du cluster de Heartbeat , Corosync et Keepalived Lequel devrions-nous choisir ? Heartbeat et Corosync appartiennent au même type, Heartbeat et Corosync ne sont pas du tout du même type. Keepalived utilise la méthode du protocole de redondance de routage virtuel vrrp ; Heartbeat ou Corosync est une méthode de haute disponibilité basée sur les services hôtes ou réseau, le but de Keepalived est de simuler la haute disponibilité du routeur, Heartbeat ; ou Corosync Le but est d'atteindre une haute disponibilité du Service. Donc, généralement, Keepalived est utilisé pour atteindre une haute disponibilité frontale. Les combinaisons couramment utilisées de haute disponibilité frontale incluent nos communs LVS+Keepalived, Nginx+Keepalived et HAproxy+Keepalived. Heartbeat ou Corosync est utilisé pour obtenir une haute disponibilité des services. Les combinaisons courantes incluent Heartbeat v3(Corosync)+Pacemaker+NFS+Httpd pour obtenir une haute disponibilité des serveurs Web, et Heartbeat v3(Corosync)+Pacemaker+NFS+MySQL pour obtenir une haute disponibilité. des serveurs MySQL. Pour résumer, Keepalived implémente une haute disponibilité légère, qui est généralement utilisée pour la haute disponibilité frontale et ne nécessite pas de stockage partagé. Elle est généralement utilisée pour la haute disponibilité de deux nœuds. Heartbeat (ou Corosync) est généralement utilisé pour la haute disponibilité des services et nécessite un stockage partagé, et est généralement utilisé pour la haute disponibilité de plusieurs nœuds. (Apprentissage recommandé :tutoriel Linux)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Prenez une minute pour comprendre le concept et les principes de l'héritage de chaîne de prototypes JavaScript
- Qui a proposé le principe du contrôle des programmes stockés ?
- Le principe de la réalisation d'un triangle en CSS
- Qu'est-ce qui utilise les principes optiques pour stocker les données ?
- Quel est le principe de mise en œuvre du verrouillage distribué Redis