
Maison >base de données >Redis >Partagez quelques questions d'entretien sur la mise en cache distribuée dans Redis (avec analyse des réponses)
Partagez quelques questions d'entretien sur la mise en cache distribuée dans Redis (avec analyse des réponses)

- 青灯夜游avant
- 2021-04-07 10:50:262884parcourir
Cet article partagera avec vous quelques questions d'entretien sur la mise en cache distribuée dans Redis, y compris l'analyse des réponses. Il a une certaine valeur de référence. Les amis dans le besoin peuvent s'y référer. J'espère qu'il sera utile à tout le monde.

Questions d'entretien
Quelle est la différence entre Redis et Memcached ? Quel est le modèle de thread de Redis ? Pourquoi Redis peut-il prendre en charge une concurrence élevée avec un seul thread ?
Analyse psychologique de l'intervieweur
C'est la question la plus fondamentale lorsque l'on pose Redis, la partie interne la plus fondamentale de Redis Le principe et les caractéristiques sont que Redis est en fait un modèle de travail à thread unique Si vous ne le savez pas, lorsque vous jouerez avec Redis plus tard, ne saurez-vous rien si quelque chose ne va pas ?
L'intervieweur peut également vous poser des questions sur la différence entre redis et memcached, mais memcached était une solution de mise en cache courante utilisée par les grandes sociétés Internet dans les premières années, mais maintenant, c'est essentiellement redis ces dernières années, et peu d'entreprises utilisez memcached. [Recommandations associées : Tutoriel vidéo Redis]
Analyse des questions d'entretien
Quelle est la différence entre Redis et Memcached ?
redis prend en charge des structures de données complexes
Par rapport à Memcached, Redis a plus de structures de données et peut prendre en charge des opérations de données plus riches. Si vous avez besoin du cache pour prendre en charge des structures et des opérations plus complexes, Redis serait un bon choix.
Redis prend en charge nativement le mode cluster
Dans le fichier redis3.
Comparaison des performances
Étant donné que Redis n'utilise que un seul cœur, alors que Memcached peut utiliser des multi-cœurs, donc en moyenne, Redis stocke de petites données sur chaque cœur Performances supérieures à celles de Memcached. Pour les données de plus de 100 000, les performances de Memcached sont supérieures à celles de Redis. Bien que Redis ait récemment été optimisé pour les performances de stockage de Big Data, il reste légèrement inférieur à Memcached.
Modèle de thread de redis
Redis utilise en interne un processeur d'événements de fichier file event handler Ce processeur d'événements de fichier est monothread, donc redis est appelé monothread. Modèle. Il utilise un mécanisme de multiplexage d'E/S pour surveiller plusieurs sockets en même temps et pousse le socket qui génère l'événement dans la file d'attente mémoire. Le répartiteur d'événements sélectionne le processeur d'événements correspondant pour le traitement en fonction du type d'événement sur le socket.
La structure du gestionnaire d'événements de fichier contient 4 parties :
- Sockets multiples
- Multiplexeur IO
- Périphérique de répartition des événements de fichier
- Gestionnaire d'événements (gestionnaire de réponse de connexion, gestionnaire de demande de commande, gestionnaire de réponse de commande)
Plusieurs sockets peuvent générer différentes opérations simultanément, et chaque opération correspond à différents événements de fichier, mais le multiplexeur IO surveillera plusieurs sockets et place les sockets qui génèrent des événements dans la file d'attente. Le répartiteur d'événements retirera à chaque fois un socket de la file d'attente et le remettra au socket correspondant en fonction du type d'événement du gestionnaire d'événements de socket pour le traitement.
Jetons un coup d'œil à un processus de communication entre le client et Redis :
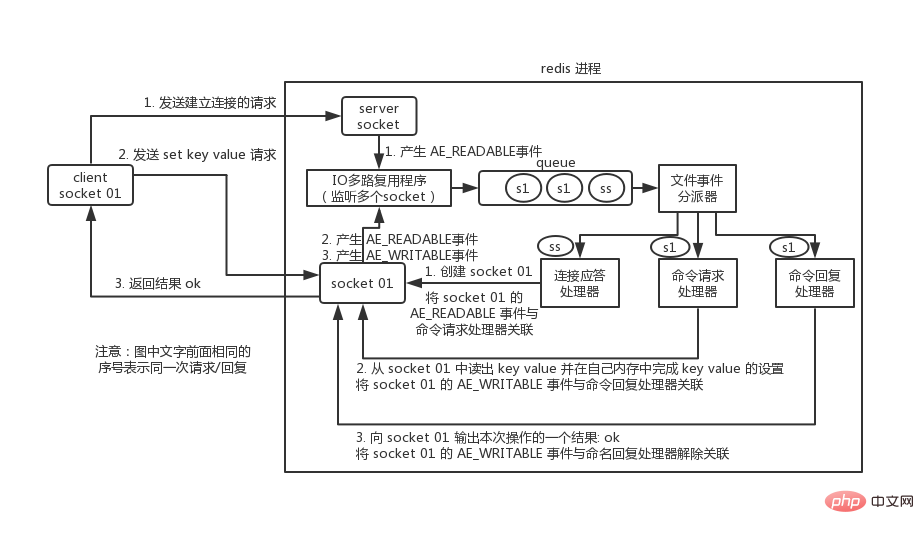
Vous devez comprendre que la communication s'effectue via des sockets. comprendre peut commencer par Jetez un oeil à la programmation réseau socket.
Tout d'abord, lorsque le processus du serveur Redis est initialisé, l'événement AE_READABLE du socket du serveur sera associé au processeur de réponse de connexion.
Le socket client01 demande au socket serveur du processus redis d'établir une connexion. À ce moment, le socket serveur générera un événement AE_READABLE après que le programme de multiplexage IO aura écouté l'événement généré par le socket serveur. , il compressera le socket dans la file d'attente. Le répartiteur d'événements de fichier obtient le socket de la file d'attente et le remet au gestionnaire de réponse de connexion. Le gestionnaire de réponse de connexion créera un socket01 qui pourra communiquer avec le client et associera l'événement AE_READABLE du socket01 au gestionnaire de demande de commande.
Supposons que le client envoie une requête set key value à ce moment-là, socket01 dans redis générera un événement AE_READABLE Le multiplexeur IO poussera socket01 dans la file d'attente. Le répartiteur d'événements démarrera à partir de L'événement AE_READABLE généré par socket01 est obtenu dans la file d'attente. Puisque l'événement AE_READABLE précédent de socket01 a été associé au processeur de demande de commande, le répartiteur d'événements transmet l'événement au processeur de demande de commande pour traitement. . Le processeur de requête de commande lit le key value du socket01 et complète les réglages de key value dans sa propre mémoire. Une fois l'opération terminée, il associe l'événement AE_WRITABLE de socket01 au gestionnaire de réponse de commande.
Si le client est prêt à recevoir le résultat de retour à ce moment-là, alors socket01 dans redis générera un événement AE_WRITABLE, qui est également placé dans la file d'attente. Le répartiteur d'événements trouve le processeur de réponse de commande associé, qui est traité. par la réponse de commande. Le processeur saisit un résultat de cette opération dans le socket01, tel que ok, puis dissocie l'événement AE_WRITABLE du socket01 du processeur de réponse de commande.
Cela complète une communication. Concernant le processus de communication de Redis, il est recommandé aux lecteurs de lire « Conception et mise en œuvre de Redis - Huang Jianhong » pour un apprentissage systématique.
Pourquoi le modèle redis monothread est-il si efficace ?
- Opération de mémoire pure.
- Le noyau est basé sur un mécanisme de multiplexage IO non bloquant.
- Implémentation du langage C. De manière générale, les programmes implémentés en langage C sont "plus proches" du système d'exploitation et la vitesse d'exécution sera relativement plus rapide.
- Un seul thread évite le problème des changements de contexte fréquents des multi-threads et évite d'éventuels problèmes de concurrence causés par les multi-threads.
Questions d'entretien
Quel est le problème de conflit de concurrence dans edis ? Comment résoudre ce problème ? Connaissez-vous la solution CAS pour les transactions redis ?
Analyse psychologique de l'intervieweur
C'est également un problème très courant en ligne, c'est-à-direPlusieurs clients simultanément lors de l'écriture une clé, les données qui auraient dû arriver en premier peuvent arriver plus tard, ce qui entraîne une erreur dans la version des données ; ou plusieurs clients peuvent obtenir une clé en même temps, modifier la valeur puis la réécrire tant que la commande est effectuée. est faux, les données seront fausses.
Et redis lui-même dispose d'une solution de verrouillage optimiste de type CAS qui résout naturellement ce problème.
Analyse des questions d'entretien
À un certain moment, plusieurs instances du système mettent à jour une certaine clé. Des verrous distribués peuvent être implémentés sur la base de zookeeper. Chaque système obtient des verrous distribués via zookeeper pour garantir qu'une seule instance du système peut utiliser une certaine clé en même temps et que les autres ne sont pas autorisées à lire ou à écrire.
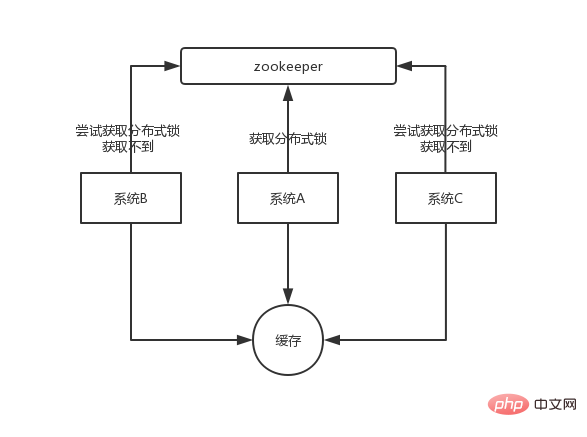
Les données que vous souhaitez écrire dans le cache sont toutes trouvées à partir de MySQL et doivent être écrites dans MySQL Lors de l'écriture sur MySQL, un horodatage doit être enregistré lors de la vérification. extrait de MySQL, l'horodatage est également extrait.
Chaque fois que vous souhaitez écrire, déterminez d'abord si l'horodatage de la valeur actuelle est plus récent que l'horodatage de la valeur dans le cache. Si tel est le cas, il peut être écrit, sinon il ne peut pas écraser les nouvelles données par les anciennes données.
Pour plus de connaissances sur la programmation, veuillez visiter : Vidéo de programmation ! !
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Résoudre le problème de l'inventaire survendu dans Redis
- 21 points auxquels vous devez faire attention lors de l'utilisation de Redis (résumé)
- Une brève discussion sur trois méthodes permettant à Redis de mettre en œuvre le push d'abonnement en temps réel
- Explication détaillée de l'architecture de réplication maître-esclave dans Redis
- 40 questions d'entretien Redis à ne pas manquer (y compris les réponses et les cartes mentales)