
Maison >base de données >Redis >40 questions d'entretien Redis à ne pas manquer (y compris les réponses et les cartes mentales)
40 questions d'entretien Redis à ne pas manquer (y compris les réponses et les cartes mentales)

- 青灯夜游avant
- 2021-04-02 10:34:258641parcourir
Cet article partage avec vous 40 questions d'entretien Redis, y compris une analyse des réponses et des cartes mentales des points de connaissance Redis. Il a une certaine valeur de référence. Les amis dans le besoin peuvent s'y référer. J'espère qu'il sera utile à tout le monde.

Questions d'entretien sur Redis
1. Qu'est-ce que Redis ?
Redis est Entièrement open source et gratuite, conforme au protocole BSD, il s'agit d'une base de données clé-valeur performante.
Redis et d'autres produits de mise en cache clé-valeur ont les trois caractéristiques suivantes :
(1) Redis prend en charge la persistance des données et peut enregistrer les données en mémoire sur le disque lors du redémarrage. Peut être chargé à nouveau pour être utilisé.
(2) Redis prend non seulement en charge les données de type clé-valeur simples, mais fournit également le stockage de structures de données telles que liste, ensemble, zset et hachage.
(3) Redis prend en charge la sauvegarde des données, c'est-à-dire la sauvegarde des données en mode maître-esclave.
[Recommandations associées : Tutoriel vidéo Redis]
Avantages de Redis
(1) Performances extrêmement élevées – Redis peut lire 110 000 fois/s, le la vitesse d'écriture est de 81 000 fois/s.
(2) Types de données riches – Redis prend en charge les opérations de type de données Chaînes, Listes, Hachages, Ensembles et Ensembles ordonnés pour les cas binaires.
(3) Atomique - Toutes les opérations de Redis sont atomiques, ce qui signifie qu'elles seront soit exécutées avec succès, soit pas exécutées du tout en cas d'échec. Les opérations individuelles sont atomiques. Les opérations multiples prennent également en charge les transactions, c'est-à-dire l'atomicité, encapsulées par les instructions MULTI et EXEC.
(4) Fonctionnalités riches – Redis prend également en charge la publication/abonnement, les notifications, l'expiration des clés et d'autres fonctionnalités.
En quoi Redis est-il différent des autres magasins à valeur clé ?
(1) Redis a des structures de données plus complexes et fournit des opérations atomiques sur celles-ci. Il s'agit d'un chemin évolutif différent des autres bases de données. Les types de données de Redis sont basés sur des structures de données de base et sont transparents pour les programmeurs, sans nécessiter d'abstractions supplémentaires.
(2) Redis s'exécute en mémoire mais peut être conservé sur le disque, la mémoire doit donc être pesée lors de la lecture et de l'écriture à grande vitesse de différents ensembles de données, car la quantité de données ne peut pas être supérieure à celle du matériel. mémoire. Un autre avantage des bases de données en mémoire est que par rapport aux mêmes structures de données complexes sur disque, le fonctionnement en mémoire est très simple, donc Redis peut faire beaucoup de choses avec une forte complexité interne. De plus, en termes de format de disque, ils sont générés de manière compacte car ils ne nécessitent pas d'accès aléatoire.
2. Quels sont les types de données de Redis ?
Réponse : Redis prend en charge cinq types de données : string (string), hash (hash), list (list), set (set) et zsetsorted set : ensemble ordonné).
Les plus couramment utilisés dans nos projets actuels sont la chaîne et le hachage. Si vous êtes un utilisateur Redis avancé, vous devez également ajouter les structures de données suivantes : HyperLogLog, Geo et Pub/Sub.
Si vous dites que vous avez joué avec le module Redis, tel que BloomFilter, RedisSearch et Redis-ML, les yeux de l'intervieweur commenceront à briller.
3. Quels sont les avantages de l'utilisation de Redis ?
(1) Rapide car les données sont stockées en mémoire, similaire à HashMap L'avantage de HashMap est que la complexité temporelle de la recherche et de l'opération est O1)
(2) Prise en charge des types de données riches, chaîne de prise en charge, liste, ensemble, Zset, hachage, etc.
(3) Prise en charge des transactions, les opérations sont atomiques. Ce qu'on appelle l'atomicité signifie que toutes les modifications apportées aux données sont soit exécutées, soit. non exécuté.
(4) Fonctionnalités riches : peut être utilisé pour la mise en cache, la messagerie, le réglage du délai d'expiration par clé, il sera automatiquement supprimé après l'expiration
4. avantages de Redis par rapport à Memcached ?
(1) Toutes les valeurs dans Memcached sont des chaînes simples, et redis, en remplacement, prend en charge des types de données plus riches
(2) Redis est plus rapide que Memcached Très rapide
(3) Redis peut conserver ses données
5 Quelles sont les différences entre Memcache et Redis ?
(1) Méthode de stockage Memecache stocke toutes les données dans la mémoire. Il raccrochera après une panne de courant. Les données ne peuvent pas dépasser la taille de la mémoire. Redis est partiellement stocké sur le disque dur, ce qui garantit la persistance des données.
(2) Types de support de données Memcache prend en charge des types de données relativement simples. Redis a des types de données complexes.
(3) Les modèles sous-jacents utilisés sont différents, les méthodes de mise en œuvre sous-jacentes et les protocoles d'application pour la communication avec le client sont différents. Redis construit directement son propre mécanisme de VM, car si le système général appelle les fonctions système, il perdra un certain temps à se déplacer et à demander.
6. Redis est-il mono-processus et mono-thread ?
Réponse : Redis est un processus unique et un thread unique. Redis utilise la technologie de file d'attente pour transformer l'accès simultané en accès série, éliminant ainsi la surcharge du contrôle série de base de données traditionnel.
7. Quelle est la capacité maximale qu'une valeur de type chaîne peut stocker ?
Réponse : 512M

8. Quel est le mécanisme de persistance de Redis ? Quels sont les avantages et les inconvénients de chacun ?
Redis fournit deux mécanismes de persistance, les mécanismes RDB et AOF :
1 (RDBRedis DataBase) méthode de persistance :
fait référence à la méthode d'utilisation des instantanés d'ensemble de données Semi. -mode persistant) enregistre toutes les paires clé-valeur de la base de données redis et écrit les données dans un fichier temporaire à un certain moment dans le temps. Une fois la persistance terminée, ce fichier temporaire est utilisé pour remplacer le dernier fichier persistant afin de récupérer les données.
Avantages :
(1) Il n'y a qu'un seul fichier dump.rdb, ce qui est pratique pour la persistance.
(2) La tolérance aux catastrophes est bonne, un fichier peut être enregistré sur un disque sécurisé.
(3) Pour maximiser les performances, forkez le processus enfant pour terminer l'opération d'écriture et laissez le processus principal continuer à traiter les commandes, afin que les E/S soient maximisées. Utilisez un sous-processus distinct pour la persistance, et le processus principal n'effectuera aucune opération d'E/S, garantissant les hautes performances de redis)
(4) Lorsque l'ensemble de données est volumineux, l'efficacité de démarrage est supérieure à AOF .
Inconvénients :
Faible sécurité des données. RDB est conservé à intervalles réguliers. Si Redis échoue entre les persistances, une perte de données se produira. Par conséquent, cette méthode est plus adaptée lorsque les exigences en matière de données ne sont pas strictes
2. AOFAppend-only file) méthode de persistance :
signifie que tous les enregistrements de ligne de commande sont entièrement au format redis protocole de demande de commande Stockage persistant) est enregistré sous forme de fichier aof.
Avantages :
(1) La sécurité des données, la persistance aof peut être configurée avec l'attribut appendfsync, avec toujours, chaque opération de commande est enregistrée dans le fichier aof.
(2) Écrivez des fichiers en mode ajout. Même si le serveur tombe en panne au milieu, vous pouvez utiliser l'outil redis-check-aof pour résoudre le problème de cohérence des données.
(3) mode de réécriture du mécanisme AOF. Avant que le fichier AOF ne soit réécrit (les commandes seront fusionnées et réécrites lorsque le fichier est trop volumineux), vous pouvez supprimer certaines commandes (comme flushall par erreur))
Inconvénients :
( 1) Les fichiers AOF sont plus volumineux que les fichiers RDB et la vitesse de récupération est lente.
(2) Lorsque l'ensemble de données est volumineux, l'efficacité du démarrage est inférieure à celle de rdb.
9. Problèmes de performances courants et solutions de Redis :
(1) Il est préférable que le maître n'écrive pas d'instantanés de mémoire. Si le maître écrit des instantanés de mémoire, la commande save planifie les instantanés de mémoire. La fonction rdbSave bloquera le travail du thread principal. Lorsque l'instantané est relativement volumineux, l'impact sur les performances sera très important et le service sera suspendu par intermittence
(2) Si les données sont importantes, un esclave permettra de sauvegarder les données AOF, les paramètres de politique Synchroniser un par seconde
(3) Pour la vitesse de réplication maître-esclave et la stabilité de la connexion, il est préférable que le maître et l'esclave soient sur le même LAN
(4) Essayez d'éviter d'être sous forte pression Ajoutez un esclave
à la bibliothèque maître (5) N'utilisez pas de structure graphique pour la réplication maître-esclave. Il est plus stable de le faire. utilisez une structure de liste chaînée unidirectionnelle, c'est-à-dire : Maître <- Esclave1<- Esclave2 <- Esclave3... comme ceci La structure est pratique pour résoudre le problème du point de défaillance unique et réaliser le remplacement de l'esclave par le maître. Si le maître raccroche, vous pouvez immédiatement activer Slave1 en tant que maître, laissant tout le reste inchangé.
10. Quelle est la stratégie de suppression des clés redis expirées ?
(1) Suppression programmée : lors du réglage du délai d'expiration de la clé, créez un minuteur (minuterie). Laissez le minuteur effectuer immédiatement la suppression de la clé lorsque le délai d'expiration de la clé arrive.
(2) Suppression paresseuse : laissez la clé expirer, mais chaque fois que vous récupérez la clé de l'espace clé, vérifiez si la clé obtenue a expiré, supprimez la clé si ce n'est pas le cas ; expiré, retournez simplement cette clé.
(3) Suppression périodique : de temps en temps, le programme vérifie la base de données et supprime les clés expirées qu'elle contient. C'est à l'algorithme de décider combien de clés expirées supprimer et combien de bases de données vérifier.
11. Stratégie de recyclage Redis (stratégie d'élimination) ?
volatile-lru : À partir de l'ensemble de données avec le délai d'expiration défini (server.db[i].expires ) et sélectionnez les données les moins récemment utilisées à éliminer
volatile-ttl : sélectionnez les données qui expireront dans l'ensemble de données (server.db[i].expires) avec un délai d'expiration défini pour éliminer
volatile-random : sélectionnez aléatoirement les données à éliminer de l'ensemble de données (server.db[i].expires) avec un délai d'expiration défini
allkeys-lru : à partir de l'ensemble de données (server.db[i] .dict) Sélectionnez les données les moins récemment utilisées pour l'élimination
allkeys-random : sélectionnez arbitrairement les données dans l'ensemble de données (server.db[i].dict) pour l'élimination
no-enviction ( eviction) : Données d'expulsion interdites
Faites attention aux 6 mécanismes ici volatile et allkeys spécifiez s'il faut expulser les données de l'ensemble de données avec un délai d'expiration ou de tous les ensembles de données. trois stratégies d'élimination différentes, plus une stratégie sans incitation consistant à ne jamais recycler.
Utiliser les règles de politique :
(1) Si les données montrent une distribution de loi de puissance, c'est-à-dire que certaines données ont une fréquence d'accès élevée et d'autres ont une fréquence d'accès faible, utilisez allkeys-lru
(2) Si les données sont également réparties, c'est-à-dire que toutes les fréquences d'accès aux données sont les mêmes, utilisez allkeys-random
12. Pourquoi edis doit-il mettre toutes les données en mémoire ?
Réponse : Afin d'obtenir la vitesse de lecture et d'écriture la plus rapide, Redis lit toutes les données dans la mémoire et écrit les données sur le disque de manière asynchrone. Redis présente donc les caractéristiques d'une vitesse rapide et d'une persistance des données. Si les données ne sont pas placées en mémoire, la vitesse des E/S du disque affectera sérieusement les performances de Redis. Aujourd'hui, alors que la mémoire devient de moins en moins chère, Redis deviendra de plus en plus populaire. Si la mémoire maximale utilisée est définie, de nouvelles valeurs ne peuvent pas être insérées une fois que le nombre d'enregistrements de données existants atteint la limite de mémoire.
13. Comprenez-vous le mécanisme de synchronisation de Redis ?
Réponse : Redis peut utiliser la synchronisation maître-esclave et la synchronisation esclave-esclave. Lors de la première synchronisation, le nœud principal effectue une sauvegarde et enregistre les opérations de modification ultérieures dans la mémoire tampon. Une fois terminé, l'intégralité du fichier rdb sera synchronisée avec le nœud de réplique. Une fois que le nœud de réplique aura accepté les données, il chargera l'image rdb. dans la mémoire. Une fois le chargement terminé, le nœud maître est invité à synchroniser les enregistrements d'opération modifiés pendant la période avec le nœud réplica pour la relecture, et le processus de synchronisation est terminé.
14. Quels sont les avantages de Pipeline ? Pourquoi utiliser Pipeline ?
Réponse : Le temps de plusieurs allers-retours d'E/S peut être réduit à un, à condition qu'il n'y ait pas de corrélation causale entre les instructions exécutées par le pipeline. Lors de l'utilisation de redis-benchmark pour les tests de résistance, on peut constater qu'un facteur important affectant la valeur maximale de QPS de redis est le nombre d'instructions par lots du pipeline.
15. Avez-vous déjà utilisé le cluster Redis ? Quel est le principe du clustering ?
(1) Redis Sentinal se concentre sur la haute disponibilité Lorsque le maître tombe en panne, il promouvra automatiquement l'esclave au rang de maître et continuera à fournir des services.
(2) Redis Cluster se concentre sur l'évolutivité Lorsqu'une seule mémoire Redis est insuffisante, le cluster est utilisé pour le stockage des fragments.
16. Dans quelles circonstances la solution de cluster Redis rendra-t-elle l'ensemble du cluster indisponible ?
Réponse : dans un cluster avec trois nœuds A, B et C, sans modèle de réplication, si le nœud B échoue, l'ensemble du cluster pensera que la plage de 5 501 à 11 000 est manquante. n'est pas disponible.
17. Quels sont les clients Java pris en charge par Redis ? Lequel est officiellement recommandé ?
Réponse : Redisson, Jedis, laitue, etc. Redisson est officiellement recommandé.
18. Quels sont les avantages et les inconvénients des Jedis et Redisson ?
Réponse : Jedis est le client de l'implémentation Java de Redis. Son API fournit un support relativement complet pour les commandes Redis ; Redisson implémente des structures de données Java distribuées et évolutives, par rapport à Jedis, la fonction est relativement simple. , ne prend pas en charge les opérations sur les chaînes et ne prend pas en charge les fonctionnalités Redis telles que le tri, les transactions, les pipelines et les partitions.
Le but de Redisson est de promouvoir la séparation des préoccupations des utilisateurs de Redis, afin que les utilisateurs puissent se concentrer davantage sur le traitement de la logique métier.
19. Comment définir un mot de passe et vérifier le mot de passe dans Redis ?
Définir le mot de passe : config set requirepass 123456
Mot de passe d'autorisation : auth 123456
20. Parlez du concept de l'emplacement de hachage Redis ?
Réponse : le cluster Redis n'utilise pas de hachage cohérent, mais introduit le concept d'emplacements de hachage. Le cluster Redis dispose de 16 384 emplacements de hachage. Chaque clé est vérifiée modulo 16 384 après avoir passé la vérification CRC16. place, chaque nœud du cluster est responsable d’une partie de l’emplacement de hachage.

21. Quel est le modèle de réplication maître-esclave du cluster Redis ?
Réponse : Afin de rendre le cluster toujours disponible lorsque certains nœuds échouent ou que la plupart des nœuds ne peuvent pas communiquer, le cluster utilise un modèle de réplication maître-esclave et chaque nœud aura N-1 répliques.
22. Les opérations d'écriture seront-elles perdues dans le cluster Redis ? Pourquoi?
Réponse : Redis ne garantit pas une forte cohérence des données, ce qui signifie qu'en pratique, le cluster peut perdre les opérations d'écriture sous certaines conditions.
23. Comment les clusters Redis sont-ils répliqués ?
Réponse : Réplication asynchrone
24. Quel est le nombre maximum de nœuds dans un cluster Redis ?
Réponse : 16384.
25. Comment choisir une base de données pour le cluster Redis ?
Réponse : Le cluster Redis ne peut actuellement pas sélectionner de base de données et la valeur par défaut est la base de données 0.
26. Comment tester la connectivité de Redis ?
Réponse : utilisez la commande ping.
27. Comment comprendre les transactions Redis ?
Réponse :
(1) Une transaction est une opération isolée distincte : toutes les commandes de la transaction seront sérialisées et exécutées dans l'ordre. Lors de l'exécution de la transaction, celle-ci ne sera pas interrompue par les demandes de commandes envoyées par d'autres clients.
(2) Une transaction est une opération atomique : soit toutes les commandes de la transaction sont exécutées, soit aucune d'entre elles n'est exécutée.
28. Quelles sont les commandes liées aux transactions Redis ?
Réponse : MULTI, EXEC, DISCARD, WATCH
29 Comment définir respectivement le délai d'expiration et la validité permanente de la clé Redis ?
Réponse : commandes EXPIRE et PERSIST.
30. Comment Redis optimise-t-il la mémoire ?
Réponse : utilisez autant que possible les tables de hachage (hachages). Les tables de hachage (ce qui signifie que le nombre stocké dans la table de hachage est petit) utilisent très peu de mémoire, vous devriez donc essayer de simplifier vos données. modèle autant que possible. Résumé dans une table de hachage. Par exemple, s'il existe un objet utilisateur dans votre système Web, ne définissez pas de clé distincte pour le nom, le prénom, l'adresse e-mail et le mot de passe de l'utilisateur. Stockez plutôt toutes les informations de l'utilisateur dans une table de hachage.
31. Comment fonctionne le processus de recyclage Redis ?
Réponse : Un client a exécuté une nouvelle commande et ajouté de nouvelles données. Redi vérifie l'utilisation de la mémoire si elle est supérieure à la limite maximale de mémoire, elle sera recyclée conformément à la politique définie. Une nouvelle commande est exécutée, etc. Nous franchissons donc constamment la limite de la mémoire en atteignant constamment la limite, puis en revenant constamment en dessous de la limite. Si le résultat d'une commande entraîne l'utilisation d'une grande quantité de mémoire (par exemple, l'enregistrement de l'intersection d'un grand ensemble dans une nouvelle clé), il ne faudra pas longtemps pour que la limite de mémoire soit dépassée par cette utilisation de la mémoire.
32. Quels sont les moyens de réduire l'utilisation de la mémoire de Redis ?
Réponse : Si vous utilisez une instance Redis 32 bits, vous pouvez faire bon usage des données de type collection telles que le hachage, la liste, l'ensemble trié, l'ensemble, etc., car généralement de nombreuses petites clés -Les valeurs peuvent être utilisées de manière plus compacte pour stocker ensemble.
33. Que se passe-t-il lorsque Redis manque de mémoire ?
Réponse : Si la limite supérieure définie est atteinte, la commande d'écriture Redis renverra un message d'erreur (mais la commande de lecture peut toujours revenir normalement.) Ou vous pouvez utiliser Redis comme cache pour utiliser le mécanisme d'élimination de la configuration. Lorsque Redis L'ancien contenu sera vidé lorsque la limite de mémoire est atteinte.
34. Combien de clés une instance Redis peut-elle stocker au maximum ? Liste, Ensemble, Ensemble Trié Combien d'éléments peuvent-ils stocker au maximum ?
R : En théorie, Redis peut gérer jusqu'à 232 clés, et dans les tests réels, chaque instance stockait au moins 250 millions de clés. Nous testons des valeurs plus grandes. N'importe quelle liste, ensemble et ensemble trié peut contenir 232 éléments. En d’autres termes, la limite de stockage de Redis est la quantité de mémoire disponible dans le système.
35. Il y a 20 millions de données dans MySQL, mais seulement 200 000 données sont stockées dans Redis. Comment s'assurer que les données dans Redis sont des données chaudes ?
Réponse : lorsque la taille de l'ensemble de données de la mémoire Redis augmente jusqu'à une certaine taille, la stratégie d'élimination des données sera mise en œuvre.
Connaissances associées : Redis propose 6 stratégies d'élimination de données :
volatile-lru : sélectionnez l'ensemble de données le moins récemment utilisé (server.db[i].expires) avec un délai d'expiration défini. Élimination des données
volatile-ttl : sélectionnez les données qui expireront dans l'ensemble de données (server.db[i].expires) avec un délai d'expiration défini.
volatile-random : éliminez les données qui. a expiré Sélectionnez toutes les données de l'ensemble de données (server.db[i].expires) avec un délai d'expiration pour éliminer
allkeys-lru : Sélectionnez les données les moins récemment utilisées de l'ensemble de données (server.db[i]. ].dict) Élimination des données
allkeys-random : sélectionnez arbitrairement des données dans l'ensemble de données (server.db[i].dict) Élimination
no-enviction (eviction) : interdire l'expulsion de data
36. Pour quel scénario Redis est-il le plus adapté ?
1. Cache de session
L'un des scénarios les plus couramment utilisés pour utiliser Redis est le cache de session. L'avantage de la mise en cache des sessions avec Redis par rapport à d'autres magasins tels que Memcached est que Redis assure la persistance. Lors de la maintenance d'un cache qui n'exige pas strictement de cohérence, la plupart des gens seraient mécontents si toutes les informations du panier d'achat de l'utilisateur étaient perdues. Le seraient-ils toujours ? Heureusement, à mesure que Redis s'est amélioré au fil des années, il est facile de comprendre comment utiliser correctement Redis pour mettre en cache les documents de session. Même la célèbre plateforme commerciale Magento propose un plug-in pour Redis.
2. Cache pleine page (FPC)
En plus des jetons de session de base, Redis fournit également une plate-forme FPC très simple. Revenons au problème de cohérence, même si l'instance Redis est redémarrée, les utilisateurs ne verront pas de baisse de la vitesse de chargement des pages en raison de la persistance du disque. Il s'agit d'une grande amélioration, similaire au FPC local PHP. En prenant à nouveau Magento comme exemple, Magento fournit un plugin pour utiliser Redis comme backend de cache pleine page. De plus, pour les utilisateurs de WordPress, Pantheon dispose d’un très bon plug-in wp-redis, qui pourra vous aider à charger le plus rapidement possible les pages que vous avez parcourues.
3. File d'attente
L'un des grands avantages de Redis dans le domaine des moteurs de stockage en mémoire est qu'il fournit des opérations de liste et d'ensemble, ce qui permet à Redis d'être utilisé comme une bonne plateforme de file d'attente de messages. . Les opérations utilisées par Redis comme file d'attente sont similaires aux opérations push/pop des langages de programmation locaux (tels que Python) sur les listes. Si vous recherchez rapidement « files d'attente Redis » dans Google, vous trouverez immédiatement un grand nombre de projets open source. Le but de ces projets est d'utiliser Redis pour créer de très bons outils back-end pour répondre à divers besoins de files d'attente. Par exemple, Celery a un backend qui utilise Redis comme courtier. Vous pouvez le visualiser à partir d'ici.
4, Classement/Compteur
Redis implémente très bien l'opération d'incrémentation ou de décrémentation de nombres en mémoire. Les ensembles et les ensembles triés nous permettent également d'effectuer très simplement ces opérations. Redis fournit simplement ces deux structures de données. Donc, pour obtenir les 10 meilleurs utilisateurs de l'ensemble trié – appelons-les « user_scores », nous procédons simplement comme ceci : Bien sûr, cela suppose que vous le faites en fonction des scores de votre utilisateur. Tri croissant. Si vous souhaitez renvoyer l'utilisateur et son score, vous devez l'exécuter comme ceci : ZRANGE user_scores 0 10 WITHSCORES Agora Games est un bon exemple, implémenté dans Ruby, et ses classements utilisent Redis pour stocker les données, vous pouvez voir ici.
5. Publier/Abonnez-vous
Le dernier (mais certainement pas le moindre) est la fonction de publication/abonnement de Redis. Il existe en effet de nombreux cas d’usage pour la publication/abonnement. J'ai vu des gens l'utiliser dans les connexions de réseaux sociaux, comme déclencheurs de scripts basés sur la publication/abonnement, et même pour créer des systèmes de discussion en utilisant la fonctionnalité de publication/abonnement de Redis !

37. S'il y a 100 millions de clés dans Redis, 100 000 d'entre elles commencent par un préfixe fixe et connu. Si elles sont toutes trouvées ?
Réponse : utilisez la commande keys pour analyser la liste des clés du mode spécifié.
L'autre partie a ensuite demandé : si ce redis fournit des services aux entreprises en ligne, quels sont les problèmes liés à l'utilisation de la commande key ?
À ce stade, vous devez répondre à une fonctionnalité clé de redis : redis est monothread. L'instruction key entraînera le blocage du thread pendant un certain temps et le service en ligne sera mis en pause. Le service ne pourra pas être restauré tant que l'instruction n'est pas exécutée. À ce stade, vous pouvez utiliser la commande scan. La commande scan peut extraire la liste des clés du mode spécifié sans blocage, mais il y aura une certaine probabilité de duplication. Il suffit de le faire une fois sur le client, mais le temps global passé sera le même. être plus long que de l'utiliser directement.
38. S'il y a un grand nombre de clés qui doivent expirer en même temps, à quoi devez-vous généralement faire attention ?
Réponse : Si le délai d'expiration d'un grand nombre de clés est défini de manière trop concentrée, redis peut connaître un bref décalage au moment de l'expiration. Généralement, il est nécessaire d’ajouter une valeur aléatoire au temps pour étaler le délai d’expiration.
39. Avez-vous déjà utilisé Redis comme file d'attente asynchrone ?
Réponse : Généralement, la structure de liste est utilisée comme file d'attente, rpush produit des messages et lpop consomme des messages. Lorsqu'il n'y a pas de message dans lpop, dormez un moment et réessayez. Que se passe-t-il si l'autre partie demande si le sommeil peut être utilisé ? Il existe également une commande appelée blpop dans la liste Lorsqu'il n'y a pas de message, elle se bloque jusqu'à ce que le message arrive. Que se passe-t-il si l'autre partie demande s'il peut être produit une fois et consommé plusieurs fois ? En utilisant le modèle d'abonné au sujet pub/sub, une file d'attente de messages 1:N peut être implémentée.
Si l'autre partie demande quels sont les inconvénients du pub/sub ?
Lorsque le consommateur se déconnecte, les messages produits seront perdus, vous devez donc utiliser une file d'attente de messages professionnelle telle que RabbitMQ.
Si l'autre partie demande comment Redis implémente une file d'attente différée ?
Je suppose que maintenant vous voulez battre l'intervieweur à mort. Si vous avez une batte de baseball à la main, pourquoi posez-vous des questions aussi détaillées ? Mais vous avez été très retenu, puis avez répondu calmement : utilisez sortedset, utilisez l'horodatage comme score, le contenu du message comme clé, appelez zadd pour produire le message, et le consommateur utilise l'instruction zrangebyscore pour obtenir les données interrogées il y a N secondes pour le traitement. À ce stade, l’intervieweur vous a secrètement donné un coup de pouce. Mais ce qu’il ne savait pas, c’est que tu étais en train de lever le majeur derrière la chaise à ce moment-là.
40. Avez-vous déjà utilisé le verrouillage distribué Redis ?
Utilisez d'abord setnx pour saisir le verrou. Après l'avoir saisi, utilisez expire pour ajouter un délai d'expiration au verrou afin d'éviter qu'il oublie de le libérer.
À ce moment-là, l'autre partie vous dira que votre réponse est bonne, puis vous demandera ce qui se passera si le processus plante de manière inattendue ou doit être redémarré pour la maintenance avant d'exécuter expire après setnx ? À ce moment-là, vous devez donner un retour surprenant : Oh, oui, ce verrou ne sera jamais libéré. Ensuite, vous devez vous gratter la tête, faire semblant de réfléchir un instant, comme si le résultat suivant était de votre propre initiative, puis répondre : je me souviens que la commande set a des paramètres très complexes. Elle devrait pouvoir définir setnx et expirer à. en même temps. Combiné en une seule instruction à utiliser ! À ce moment-là, l'autre partie affichera un sourire et commencera à penser silencieusement dans son cœur : Appuyez, ce type n'est pas mauvais.
Les points de connaissances pertinents sont résumés dans une carte mentale
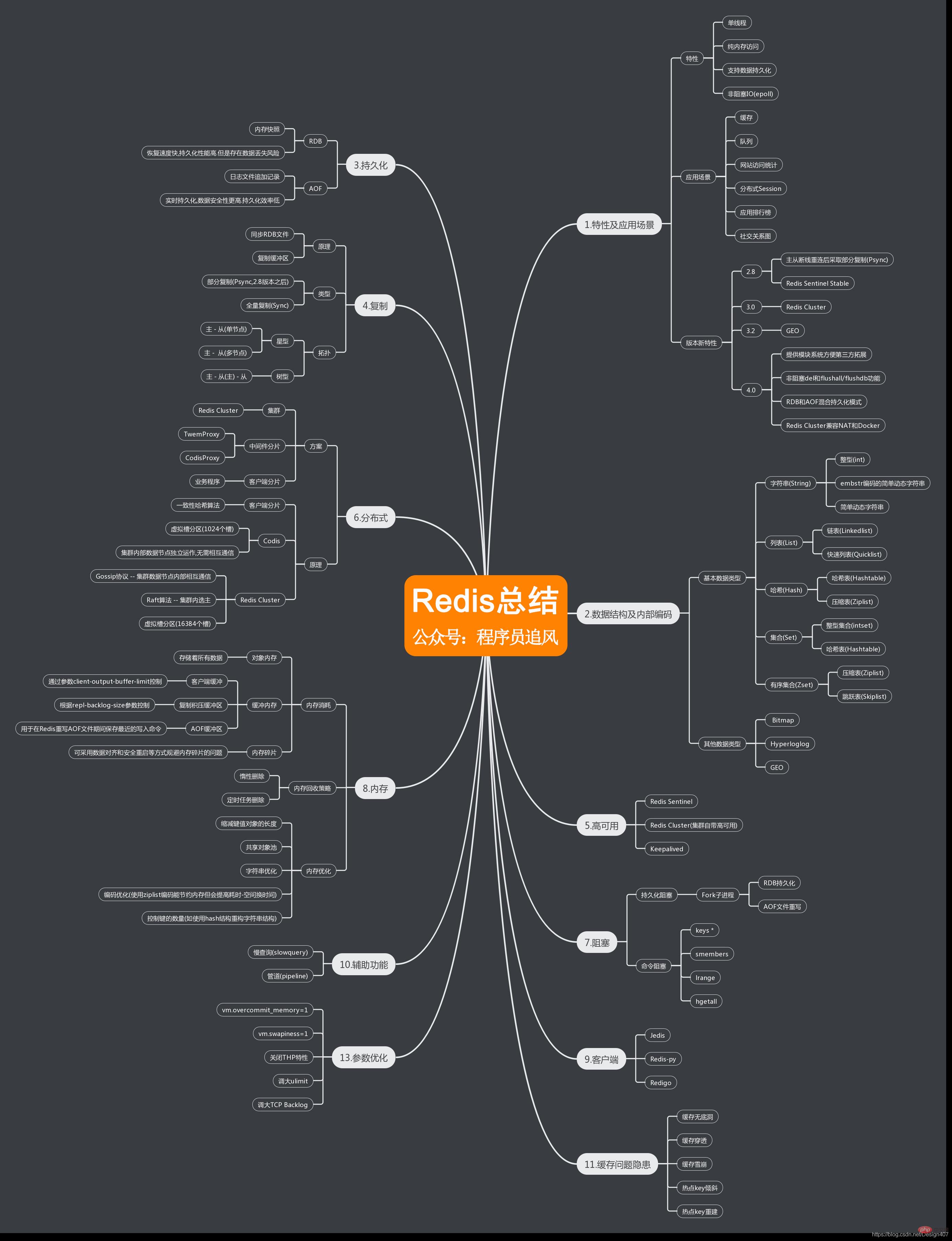
Pour plus de connaissances liées à la programmation, veuillez visiter : Introduction à la programmation ! !
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Résoudre le problème de l'inventaire survendu dans Redis
- Présentation du déploiement du cluster Redis sur les K8
- Présentation de la surveillance des performances Redis
- Explication détaillée du mécanisme de haute disponibilité et de haute concurrence de Redis
- 21 points auxquels vous devez faire attention lors de l'utilisation de Redis (résumé)