
Maison >interface Web >js tutoriel >JavaScript implémente des structures de données communes (pile, file d'attente, liste chaînée, table de hachage, arborescence)
JavaScript implémente des structures de données communes (pile, file d'attente, liste chaînée, table de hachage, arborescence)

- 青灯夜游avant
- 2020-12-31 17:14:296199parcourir
Recommandations associées : "Tutoriel vidéo javascript"
En JavaScript, les structures de données sont généralement ignorées ou peu touchées. Mais pour de nombreuses grandes entreprises, vous devez généralement avoir une compréhension approfondie de la manière de gérer les données. Comprendre les structures de données peut également vous aider dans votre travail lors de la résolution de problèmes.
Dans cet article, les structures de données dont nous discuterons et mettrons en œuvre sont :
- Pile
- File d'attente
- Liste chaînée
- Table de hachage
- Arbre
Pile
La première structure de données est la pile. Cela ressemble beaucoup à une file d'attente, et vous avez peut-être déjà entendu parler de la pile d'appels, qui est la façon dont JavaScript gère les événements.
La pile ressemble à ceci :
Le dernier élément ajouté à la pile sera le premier élément supprimé. C’est ce qu’on appelle le dernier entré, premier sorti (LIFO). Le bouton Précédent d'un navigateur Web en est un bon exemple : chaque page que vous consultez est ajoutée à une pile, et lorsque vous cliquez sur "Retour", la page actuelle (la dernière page ajoutée) est extraite de la pile.
Assez de théories. Regardons du code :
class Stack {
constructor() {
// 创建栈结构,这是一个空对象
this.stack = {}
}
// 把一个值压入栈的顶部
push(value) {
}
// 弹出栈顶的值并返回
pop() {
}
// 读取栈中的最后一个值,但是不删除
peek() {
}
}J'ai commenté le code ci-dessus, implémentons-le maintenant ensemble. La première méthode est push.
Réfléchissez d'abord à ce que nous avons besoin de cette méthode :
- Nous devons accepter une valeur
- puis ajouter cette valeur en haut de la pile
- 🎜> Vous devez également garder une trace de la longueur de la pile afin de connaître l'index de la pile
pushCe serait formidable si vous pouviez d'abord l'essayer vous-même, l'implémentation complète de la méthode
class Stack {
constructor() {
this._storage = {};
this._length = 0; // 这是栈的大小
}
push(value) {
// 将值添加到栈顶
this._storage[this._length] = value;
// 因为增加了一个值,所以也应该将长度加1
this._length++;
}
/// .....
}Je parie que c'est plus facile que vous ne le pensez. Il existe de nombreuses structures comme celle-ci qui semblent beaucoup plus compliquées qu’elles ne le sont en réalité. pop est désormais la méthode pop. Le but de la méthode
class Stack {
constructor() {
this._storage = {};
this._length = 0;
}
pop() {
// we first get the last val so we have it to return
const lastVal = this._storage[--this._length]
// now remove the item which is the length - 1
delete this._storage[--this._length]
// decrement the length
this._length--;
// now return the last value
return lastVal
}
}peekCool ! Presque terminé. La dernière est la fonction , qui examine le dernier élément de la pile. C'est la fonction la plus simple : seule la dernière valeur doit être renvoyée. L'implémentation est : class Stack {
constructor() {
this._storage = {};
this._length = 0;
}
/*
* Adds a new value at the end of the stack
* @param {*} value the value to push
*/
peek() {
const lastVal = this._storage[--this._length]
return lastVal
}
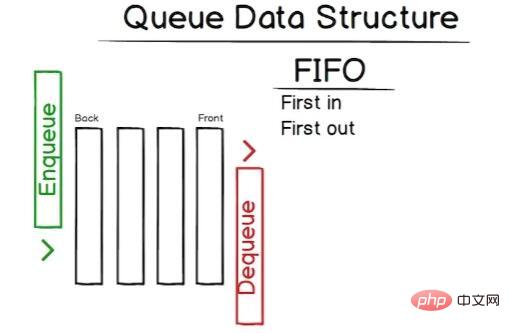
}pop elle est donc très similaire à la méthode mais ne supprime pas le dernier élément. Oui ! La première structure de données a été implémentée. Vient ensuite la file d’attente, qui ressemble beaucoup à une pile. File d'attente Ensuite, nous discuterons des files d'attente – j'espère que les piles sont encore fraîches dans votre esprit, car elles sont très similaires aux files d'attente. La principale différence entre une pile et une file d'attente est que les files d'attente sont du premier entré, premier sorti (FIFO). peut être représenté graphiquement comme ceci :
enqueueLes deux méthodes principales sont donc dequeue et
class Queue {
constructor() {
// 与前面类似,我们为数据结构提供了一个对象
// 并且还有一个变量来保存长度
this.queue = {}
this.length = 0
// 这是一个跟踪头部的新变量
this.head = 0
}
enqueue(value) {
}
dequeue() {
}
peek() {
}
}enqueueImplémentez d'abord la méthode . Son but est d'ajouter un élément à la fin de la file d'attente. enqueue(value) {
// 使用 value 参数将 length + head 的键添加到对象
this.queue[this.length + this.head] = value;
this.length++
}this.queue[this.length + this.head] = value;C'est un moyen très simple d'ajouter une valeur à la fin de la file d'attente, mais vous pourriez être dérouté par . {14 : 'randomVal'}Supposons que la file d'attente ressemble à ceci 15. Lors de l'ajout de ce contenu, la valeur suivante que nous voulons est 15, elle devrait donc être length(1) + head(14), qui est
dequeueLa prochaine chose à implémenter est
dequeue() {
// 获取第一个值的引用,以便将其返回
const firstVal = this.queue[this.head]
// 现在将其从队列中删除
delete this.queue[this.head]
this.length--;
// 最终增加我们的头成为下一个节点
this.head++;
}peekLa dernière chose à implémenter est la méthode , qui est très simple : peek() {
// 只需要把值返回即可
return this.queue[this.head];
}Le la file d'attente est implémentée. Liste chaînéeParlons d'abord de la puissante liste chaînée. C'est beaucoup plus complexe que la structure ci-dessus. Peut-être que votre première question est pourquoi utiliser une liste chaînée ? Les listes chaînées sont principalement utilisées dans les langages qui ne disposent pas de tableaux de taille dynamique. Une liste chaînée organise les éléments dans l’ordre, un élément pointant vers le suivant. dataChaque nœud de la liste chaînée a une valeur next et une valeur 5. Dans la figure ci-dessous, data est la valeur next et la valeur 10 pointe vers le nœud suivant, qui est le nœud avec la valeur
Visuellement, cela ressemble à ceci :

LinkedListDans un objet, le dessus
")
1Vous verrez que la dernière valeur next a une null valeur de LinkedList car c'est la fin de
1Créons un 2 avec les valeurs 37, LinkedList et
const myLinkedList = {
head: {
value: 1
next: {
value: 2
next: {
value: 37
next: null
}
}
}
};现在我们知道了该怎样手动创建 LinkedList,但是还需要编码实现 LinkedList 的方法。
首先要注意的是,LinkedList 只是一堆嵌套对象!
当构造一个 LinkedList 时,我们需要一个 head 和一个 tail,它们最初都会指向头部(因为 head 是第一个也是最后一个)。
class LinkedList {
constructor(value) {
this.head = {value, next: null}
this.tail = this.head
}
}第一个要实现的方法是 insert ,该方法用来在链表的末尾插入一个值。
// insert 将添加到链接列表的末尾
insert(value) {
/* 创建一个节点 */
const node = {value, next: null}
/* 把 tail 的 next 属性设置为新节点的引用 */
this.tail.next = node;
/* 新节点现在是尾节点 */
this.tail = node;
}上面最混乱的一行可能是 this.tail.next = node。之所以这样做,是因为当添加一个新节点时,我们还希望当前的 tail 指向新的 node,该节点将成为新的 tail。第一次插入 node 时,头部的 next 指针将指向新节点,就像在构造函数中那样,在其中设置了 this.tail = this.head。
你还可以到这个网站来查看图形化的演示,这将帮你了解插入的过程(按 esc 摆脱烦人的弹出窗口)。
下一个方法是删除节点。我们首先要决定参数是值( value) 还是对节点(node)的引用(在面试中,最好先问问面试官)。我们的代码中传递了一个“值”。按值从列表中删除节点是一个缓慢的过程,因为必须要遍历整个列表才能找到值。
我这样做是这样的:
removeNode(val) {
/* 从 head 开始 */
let currentNode = this.head
/* 我们需要保留对上一个节点的引用 */
let previousNode
/* 当存在一个节点时,意味着没有到达尾部 */
while(currentNode) {
/* 如果发现自己想要的那个值,那么就退出循环 */
if(currentNode.value === val) {
break;
}
/* 没有找到值就将 currentNode 设置为 previousNode */
previousNode = currentNode
/* 得到下一个节点并将其分配给currentNode */
currentNode = currentNode.next
}
/* 返回undefined,因为没有找到具有该值的节点 */
if (currentNode=== null) {
return false;
}
// 如果节点是 head ,那么将 head 设置为下一个值
头节点的
if (currentNode === this.head) {
this.head = this.head.next;
return;
}
/* 通过将节点设置为前面的节点来删除节点 */
previousNode.next = currentNode.next
}removeNode 方法使我们对 LinkedList 的工作方式有了很好的了解。
所以再次说明一下,首先将变量 currentNode 设置为 LinkedList 的 head,因为这是第一个节点。然后创建一个名为 previousNode 的占位符变量,该变量将在 while 循环中使用。从条件 currentNode 开始 while 循环,只要存在 currentNode,就会一直运行。
在 while 循环中第一步是检查是否有值。如果不是,则将 previousNode 设置为 currentNode,并将 currentNode 设置为列表中的下一个节点。继续进行此过程,直到找到我需要找的值或遍历完节点为止。
在 while 循环之后,如果没有 currentNode,则返回 false,这意味着没有找到任何节点。如果确实存在一个 currentNode,则检查的 currentNode 是否为 head。如果是的话就把 LinkedList 的 head 设置为第二个节点,它将成为 head。
最后,如果 currentNode 不是头,就把 previousNode 设置为指向 currentNode 前面的 node,这将会从对象中删除 currentNode。
另一个常用的方法(面试官可能还会问你)是 removeTail 。这个方法如其所言,只是去掉了 LinkedList 的尾节点。这比上面的方法容易得多,但工作原理类似。
我建议你先自己尝试一下,然后再看下面的代码(为了使其更复杂一点,我们在构造函数中不使用 tail):
removeTail() {
let currentNode = this.head;
let previousNode;
while (currentNode) {
/* 尾部是唯一没有下一个值的节点,所以如果不存在下一个值,那么该节点就是尾部 */
if (!currentNode.next) {
break;
}
// 获取先前节点的引用
previousNode = currentNode;
// 移至下一个节点
currentNode = currentNode.next;
}
// 要删除尾部,将 previousNode.next 设置为 null
previousNode.next = null;
}这些就是 LinkedList 的一些主要方法。链表还有各种方法,但是利用以上学到的知识,你应该能够自己实现它们。
哈希表
接下来是强大的哈希表。
哈希表是一种实现关联数组的数据结构,这意味着它把键映射到值。 JavaScript 对象就是一个“哈希表”,因为它存储键值对。
在视觉上,可以这样表示:
在讨论如何实现哈希表之前,需要讨论讨论哈希函数的重要性。哈希函数的核心概念是它接受任意大小的输入并返回固定长度的哈希值。
hashThis('i want to hash this') => 7
哈希函数可能非常复杂或直接。 GitHub 上的每个文件都经过了哈希处理,这使得每个文件的查找都非常快。哈希函数背后的核心思想是,给定相同的输入将返回相同的输出。
在介绍了哈希功能之后,该讨论一下如何实现哈希表了。
将要讨论的三个操作是 insert、get最后是 remove。
实现哈希表的核心代码如下:
class HashTable {
constructor(size) {
// 定义哈希表的大小,将在哈希函数中使用
this.size = size;
this.storage = [];
}
insert(key, value) { }
get() {}
remove() {}
// 这是计算散列密钥的方式
myHashingFunction(str, n) {
let sum = 0;
for (let i = 0; i < str.length; i++) {
sum += str.charCodeAt(i) * 3;
}
return sum % n;
}
}现在解决第一个方法,即 insert。insert 到哈希表中的代码如下(为简单起见,此方法将简单的处理冲突问题):
insert(key, value) {
// 得到数组中的索引
const index = this.myHashingFunction(key, this.size);
// 处理冲突 - 如果哈希函数为不同的键返回相同的索引,
// 在复杂的哈希函数中,很可能发生冲突
if (!this.storage[index]) {
this.storage[index] = [];
}
// push 新的键值对
this.storage[index].push([key, value]);
}像这样调用 insert 方法:
const myHT = new HashTable(5);
myHT.insert("a", 1);
myHT.insert("b", 2);你认为我们的哈希表会是什么样的?
你可以看到键值对已插入到表中的索引 1 和 4 处。
现在实现从哈希表中删除
remove(key) {
// 首先要获取 key 的索引,请记住,
// 哈希函数将始终为同一 key 返回相同的索引
const index = this.myHashingFunction(key, this.size);
// 记住我们在一个索引处可以有多个数组(不太可能)
let arrayAtIndex = this.storage[index];
if (arrayAtIndex) {
// 遍历该索引处的所有数组
for (let i = 0; i < arrayAtIndex.length; i++) {
// get the pair (a, 1)
let pair = arrayAtIndex[i];
// 检查 key 是否与参数 key 匹配
if (pair[0] === key) {
delete arrayAtIndex[i];
// 工作已经完成,所以要退出循环
break;
}
}
}
}最后是 get 方法。这和 remove 方法一样,但是这次,我们返回 pair 而不是删除它。
get(key) {
const index = this.myHashingFunction(key, this.size);
let arrayAtIndex = this.storage[index];
if (arrayAtIndex) {
for (let i = 0; i < arrayAtIndex.length; i++) {
const pair = arrayAtIndex[i];
if (pair[0] === key) {
return pair[1];
}
}
}
}我认为不需要执行这个操作,因为它的作用与 remove 方法相同。
你可以认为它并不像最初看起来那样复杂。这是一种到处使用的数据结构,也是是一个很好理解的结构!
二叉搜索树
最后一个数据结构是臭名昭著的二叉搜索树。
在二叉搜索树中,每个节点具有零个、一个或两个子节点。左边的称为左子节点,右边的称为右子节点。在二叉搜索树中,左侧的子项必须小于右侧的子项。
你可以像这样描绘一个二叉搜索树:
 "160940586817023JavaScript implémente des structures de données communes (pile, file dattente, liste chaînée, table de hachage, arborescence)")
树的核心类如下:
class Tree {
constructor(value) {
this.root = null
}
add(value) {
// 我们将在下面实现
}
}我们还将创建一个 Node 类来代表每个节点。
class Node {
constructor(value, left = null, right = null) {
this.value = value;
this.left = left;
this.right = right;
}
}下面实现 add 方法。我已经对代码进行了注释,但是如果你发现使你感到困惑,请记住,我们要做的只是从根开始并检查每个节点的 left 和 right。
add(value) {
// 如果没有根,那么就创建一个
if (this.root === null) {
this.root = new Node(value);
return;
}
let current = this.root;
// keep looping
while (true) {
// 如果当前值大于传入的值,则向左
if (current.value > value) {
// 如果存在左子节点,则再次进行循环
if (current.left) {
current = current.left;
} else {
current.left = new Node(value);
return;
}
}
// 值较小,所以我们走对了
else {
// 向右
// 如果存在左子节点,则再次运行循环
if (current.right) {
current = current.right;
} else {
current.right = new Node(value);
return;
}
}
}
}测试新的 add 方法:
const t = new Tree(); t.add(2); t.add(5); t.add(3);
现在树看起来是这样:
 "160940587511415JavaScript implémente des structures de données communes (pile, file dattente, liste chaînée, table de hachage, arborescence)")
为了更好的理解,让我们实现一个检查树中是否包含值的方法。
contains(value) {
// 获取根节点
let current = this.root;
// 当存在节点时
while (current) {
// 检查当前节点是否为该值
if (value === current.value) {
return true; // 退出函数
}
// 通过将我们的值与 current.value 进行比较来决定下一个当前节点
// 如果小则往左,否则往右
current = value < current.value ? current.left : current.right;
}
return false;
}Add 和 Contains 是二进制搜索树的两个核心方法。对这两种方法的了解可以使你更好地解决日常工作中的问题。
总结
我已经在本文中介绍了很多内容,并且掌握这些知识后在面试中将使你处于有利位置。希望你能够学到一些东西,并能够轻松地通过技术面试(尤其是讨厌的白板面试)。
更多编程相关知识,请访问:编程教学!!
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!