
Maison >base de données >SQL >Apprenez à traiter des dizaines de millions d'enregistrements dans SQL Server
Apprenez à traiter des dizaines de millions d'enregistrements dans SQL Server

- coldplay.xixiavant
- 2020-11-27 16:42:299772parcourir
La colonne
sqlTutoriel présente comment traiter des dizaines de millions d'enregistrements.

Recommandé : Tutoriel SQL
Contexte du projet
Ceci est J'ai réalisé un projet pour un certain centre de données. La difficulté du projet était scandaleuse. Ce projet m'a vraiment fait sentir que le centre commercial est comme un champ de bataille, et je n'y suis qu'un soldat. Il y a trop de tactiques et trop de tactiques. conflits entre la haute direction, trop d'histoires internes. Concernant la situation spécifique de ce projet, j'écrirai un article de blog connexe quand j'aurai le temps.
Ce projet nécessite une surveillance environnementale. Pour l'instant, nous appelons l'équipement surveillé un dispositif de collecte, et les attributs de l'équipement de collecte sont appelés indicateurs de surveillance. Exigences du projet : le système prend en charge pas moins de 10w indicateurs de surveillance, la mise à jour des données de chaque indicateur de surveillance ne dure pas plus de 20 secondes et le délai de stockage n'est pas supérieur à 120 secondes . Ensuite, nous pouvons obtenir l'état idéal grâce à des calculs simples - les données à stocker sont : 30w par minute, 1800w par heure, soit 432 millions par jour . En réalité, la quantité de données sera environ 5 % supérieure à cela. (En fait, la plupart sont des déchets d'informations, qui peuvent être traités par compression de données, mais si d'autres veulent vous déranger, que pouvez-vous faire)
Les indicateurs ci-dessus sont requis par le projet I. Je pense qu'il existe de nombreux traitements de Big Data. Les étudiants expérimentés en riront, c'est tout ? Eh bien, j'ai aussi beaucoup lu sur le traitement du Big Data, mais je n'en ai jamais traité auparavant. En regardant les explications claires des autres, il semble qu'il soit vraiment facile de résoudre ce qui est distribué et ce qui sépare la lecture et l'écriture. Cependant, le problème n’est pas si simple. Comme je l’ai dit plus haut, il s’agit d’un très mauvais projet et d’un projet typique de concurrence vicieuse dans l’industrie.
- Il n'y a plus de serveurs, mais en plus de la base de données et du collecteur centralisé (c'est-à-dire le programme d'analyse, d'alarme et de stockage des données), ce serveur prend également en charge l'interface nord de 300 000 points. (SNMP) Avant l'optimisation du programme, le CPU occupait plus de 80 % toute l'année. Étant donné que le projet nécessite l'utilisation d'une veille chaude sur deux machines, afin de gagner du temps et de réduire les problèmes inutiles, nous avons regroupé les services associés afin de pouvoir utiliser pleinement les caractéristiques de HA (système HA acheté en externe)
- Données du système Les exigences de précision sont extrêmement anormales. Du système de collecte inférieur au système de surveillance de niveau supérieur, il ne doit y avoir aucune différence dans les données
Notre architecture système est la suivante. la base de données est très élevée, notamment sur le noeud LevelA :
- La configuration matérielle est la suivante :
CPU : Processeur Intel® Xeon® E5-2609 (4 cœurs, 2,40 GHz, 10 Mo, 6,4 GT/s)
Mémoire : 4 Go (2x2 Go) de mémoire DDR3 RDIMM, 1 333 MHz, ECC
Disque dur : 500 Go 7 200 Disque dur RPM 3,5'' SATA3, Raid5. - Version base de données
utilise la version standard SQL Server 2012 Le logiciel authentique fourni par HP manque de nombreuses fonctions NB de la version entreprise.

Recommandez votre propre groupe de communication LinuxC/C++ : 973961276 ! J'ai compilé des livres d'apprentissage, du matériel vidéo et des interviews avec de grands fabricants que je pense personnellement être meilleurs et je les ai partagés dans les fichiers du groupe. Les amis qui en ont besoin peuvent les ajouter eux-mêmes ! ~
Glot d'étranglement en matière d'écriture
Le premier obstacle que nous avons rencontré était que nous avons constaté que SQL Server ne pouvait pas gérer autant d'entre eux dans le cadre du programme existant. la situation spécifique du volume de données ?
Notre structure de stockage
Généralement afin de stocker une grande quantité de données historiques, nous allons créer une table physique, sinon il y a des millions d'enregistrements chaque jour et des centaines de millions par an. Par conséquent, la structure de notre table d'origine est la suivante :
CREATE TABLE [dbo].[His20140822](
[No] [bigint] IDENTITY(1,1) NOT NULL,
[Dtime] [datetime] NOT NULL,
[MgrObjId] [varchar](36) NOT NULL,
[Id] [varchar](50) NOT NULL,
[Value] [varchar](50) NOT NULL,
CONSTRAINT [PK_His20140822] PRIMARY KEY CLUSTERED (
[No] ASC)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]) ON [PRIMARY]Non comme identifiant unique, identifiant du dispositif de collecte (Guid), identifiant de l'indicateur de surveillance (varchar(50)), durée d'enregistrement et valeur enregistrée. Et utilisez l’ID du dispositif de collecte et l’ID de l’indicateur de surveillance comme index pour faciliter une recherche rapide.
Écriture par lots
J'ai utilisé BulKCopy lors de l'écriture, oui, c'est tout, il prétend écrire des millions d'enregistrements en quelques secondes
public static int BatchInert(string connectionString, string desTable, DataTable dt, int batchSize = 500)
{
using (var sbc = new SqlBulkCopy(connectionString, SqlBulkCopyOptions.UseInternalTransaction)
{
BulkCopyTimeout = 300,
NotifyAfter = dt.Rows.Count,
BatchSize = batchSize,
DestinationTableName = desTable })
{
foreach (DataColumn column in dt.Columns)
sbc.ColumnMappings.Add(column.ColumnName, column.ColumnName);
sbc.WriteToServer(dt);
}
return dt.Rows.Count;
} . Quel est le problème ?
L'architecture ci-dessus convient pour 40 millions de données par jour. Cependant, lorsque la configuration a été ajustée au contexte ci-dessus, le programme de surveillance centralisé a fait déborder la mémoire. L'analyse a révélé que trop de données avaient été reçues et placées dans la mémoire, mais qu'il n'y avait pas de temps pour les écrire dans la base de données, ce qui a finalement abouti à un problème. les données générées Les données plus volumineuses que celles consommées entraîneront un débordement de mémoire et le programme ne fonctionnera pas.
Où est le goulot d'étranglement ?
Est-ce à cause d'un problème de disque RAID ? Est-ce un problème de structure de données ? Est-ce un problème matériel ? Est-ce un problème avec la version SQL Server ? Est-ce un problème qu'il n'y ait pas de table de partition ? Ou est-ce un problème de programme ?
A cette époque, nous n'avions qu'une semaine. Sinon, le chef de projet nous demandait de sortir, nous avions donc la prouesse de travailler en continu pendant 48 heures, et nous devions téléphoner partout pour demander de l'aide. ...
Cependant, ce qu'il faut en ce moment, c'est se calmer, se calmer encore... Version SQL Server ? matériel? Il est peu probable qu'il soit remplacé pour le moment. Baie de disques RAID, probablement pas. Alors qu’est-ce que c’est ? Je n’arrive vraiment pas à me calmer.
Vous ne comprenez peut-être pas l'atmosphère tendue qui règne sur les lieux. En fait, après si longtemps, il m'est difficile de revenir à cette situation. Mais on peut dire que nous avons peut-être différentes méthodes maintenant, ou que nous avons plus de pensées en tant qu'étrangers, mais lorsqu'un projet vous met la pression au point d'abandonner, vos pensées et vos considérations à ce moment-là sont limitées par les facteurs environnementaux sur place. Des écarts majeurs peuvent survenir. Cela peut vous faire réfléchir rapidement ou faire stagner votre réflexion. Dans cet environnement sous haute pression, certains collègues ont même commis davantage d'erreurs de faible niveau, leur réflexion était complètement chamboulée et leur efficacité était encore plus faible... Ils n'ont pas dormi un clin d'œil pendant 36 heures, ou sont simplement restés sur le coup. chantier (il y avait de la boue partout les jours de pluie, sec Si c'est fait, tout sera plâtre d'ici là) Louchez pendant deux ou trois heures, puis continuez à travailler pendant une semaine ! Ou continuez !
Beaucoup de gens ont donné beaucoup d’idées, mais elles semblent utiles et elles ne semblent pas utiles. Attendez, pourquoi est-ce que « cela semble fonctionner, mais cela ne semble pas fonctionner » ? Il me semble vaguement avoir saisi une indication de direction. Qu'est-ce que c'est ? Soit dit en passant, vérification, nous fonctionnons désormais dans un environnement réel. Il n'y a eu aucun problème auparavant, mais cela ne signifie pas qu'il n'y a pas de problèmes sous la pression actuelle. Analyser une si petite fonction dans un grand système a un impact trop important. , nous devrions donc le décomposer. Oui, il s'agit d'un "test unitaire", qui est un test d'une seule méthode. Nous devons vérifier chaque fonction. Où se déroule chaque étape indépendante ?
Test étape par étape pour vérifier les goulots d'étranglement du système
Modifier les paramètres de BulkCopy
Tout d'abord, ce à quoi j'ai pensé était de modifier les paramètres de BulkCopy , BulkCopyTimeout, BatchSize, tests et ajustements constants, les résultats fluctuent toujours dans une certaine plage, mais il n'y a pas d'impact réel. Cela peut affecter certains comptes CPU, mais c'est loin de répondre à mes attentes. La vitesse d'écriture oscille toujours entre 10 000 et 2 000 fois en 5 secondes, ce qui est loin de l'exigence pour écrire 20 000 000 d'enregistrements en 20 secondes.
Stockage par dispositif de collecte
Oui, la structure ci-dessus est un enregistrement pour chaque valeur de chaque indicateur Est-ce trop de déchets ? Alors, est-il possible d'utiliser le dispositif de collecte + l'heure de collecte comme enregistrement ? La question est de savoir comment résoudre le problème des différents attributs des différents dispositifs de collecte ? A cette époque, un collègue a montré ses talents. Les indicateurs de suivi + les valeurs de suivi peuvent être stockés au format XML. Wow, est-ce que ça peut arriver ? Pour les requêtes, vous pouvez utiliser XML.
Nous avons donc cette structure : No、MgrObjId、Dtime、XMLData
Les résultats se révèlent légèrement meilleurs que ceux ci-dessus, mais pas trop évidents.
Partition de table de données ???
Je n'avais pas appris cette compétence à cette époque, je lisais des articles en ligne et cela me paraissait assez compliqué, donc je n'ai pas osé l'essayer.
Arrêter les autres programmes
Je sais que ce n'est définitivement pas possible car l'architecture logicielle et matérielle ne peut pas être modifiée pour le moment. Mais je veux vérifier si ces facteurs l’affectent. Il s'est avéré que l'invite était effectivement évidente, mais elle ne répondait toujours pas aux exigences.
Est-ce le goulot d'étranglement de SQL Server ?
Aucune idée, est-ce le goulot d'étranglement de SQL Server ? J'ai vérifié les informations pertinentes en ligne et j'ai découvert qu'il s'agissait peut-être du goulot d'étranglement d'IO. Bon sang, que puis-je faire d'autre pour mettre à niveau le serveur et remplacer la base de données ? Mais la partie du projet le fournira-t-elle ?
Attendez, il semble y avoir autre chose, index, index ! L'existence de l'index affectera l'insertion et la mise à jour
Suppression de l'index
Oui, la requête sera certainement plus lente après la suppression de l'index, mais je dois d'abord vérifier si la suppression de l'index accélérera l'écriture. Si vous supprimez de manière décisive les index des champs MgrObjId et Id.
Exécutez, et un miracle s'est produit. 100 000 enregistrements sont écrits à chaque fois, et cela peut être écrit en 7 à 9 secondes, répondant ainsi aux exigences du système.
Comment résoudre la requête ?
Une table contient plus de 400 millions d'enregistrements par jour, ce qui est impossible à interroger sans index. ce qu'il faut faire! ? J'ai repensé à notre ancienne méthode, les sous-tables physiques. Oui, à l'origine nous divisons le planning par jours, maintenant nous divisons le planning par heures. Ensuite, il y a 24 tables, chaque table n'a besoin que de stocker environ 18 millions d'enregistrements.
Interrogez ensuite l'historique d'un attribut en une heure ou plusieurs heures. Le résultat est : lentement ! lent! ! lent! ! ! Il est tout simplement inimaginable d’interroger plus de 10 millions d’enregistrements sans indexation. Que peut-on faire d'autre ?
Continuer à diviser le tableau, ai-je pensé, on peut aussi continuer à diviser le tableau en fonction du collecteur sous-jacent, car le matériel de collecte est différent selon les collecteurs, alors quand on interroge la courbe historique, on ne peut que vérifier un seul indicateur La courbe historique peut être dispersée dans différents tableaux.
说干就干,结果,通过按10个采集嵌入式并按24小时分表,每天生成240张表(历史表名类似这样:His_001_2014112615),终于把一天写入4亿多条记录并支持简单的查询这个问题给解决掉了!!!
查询优化
在上述问题解决之后,这个项目的难点已经解决了一半,项目监管也不好意思过来找茬,不知道是出于什么样的战术安排吧。
过了很长一段时间,到现在快年底了,问题又来了,就是要拖死你让你在年底不能验收其他项目。
这次要求是这样的:因为上述是模拟10w个监控指标,而现在实际上线了,却只有5w个左右的设备。那么这个明显是不能达到标书要求的,不能验收。那么怎么办呢?这些聪明的人就想,既然监控指标减半,那么我们把时间也减半,不就达到了吗:就是说按现在5w的设备,那你要10s之内入库存储。我勒个去啊,按你这个逻辑,我们如果只有500个监控指标,岂不是要在0.1秒内入库?你不考虑下那些受监控设备的感想吗?
但是别人要玩你,你能怎么办?接招呗。结果把时间降到10秒之后,问题来了,大家仔细分析上面逻辑可以知道,分表是按采集器分的,现在采集器减少,但是数量增加了,发生什么事情呢,写入可以支持,但是,每张表的记录接近了400w,有些采集设备监控指标多的,要接近600w,怎么破?
于是技术相关人员开会讨论相关的举措。
在不加索引的情况下怎么优化查询?
有同事提出了,where子句的顺序,会影响查询的结果,因为按你刷选之后的结果再处理,可以先刷选出一部分数据,然后继续进行下一个条件的过滤。听起来好像很有道理,但是SQLServer查询分析器不会自动优化吗?原谅我是个小白,我也是感觉而已,感觉应该跟VS的编译器一样,应该会自动优化吧。
具体怎样,还是要用事实来说话:
结果同事修改了客户端之后,测试反馈,有较大的改善。我查看了代码: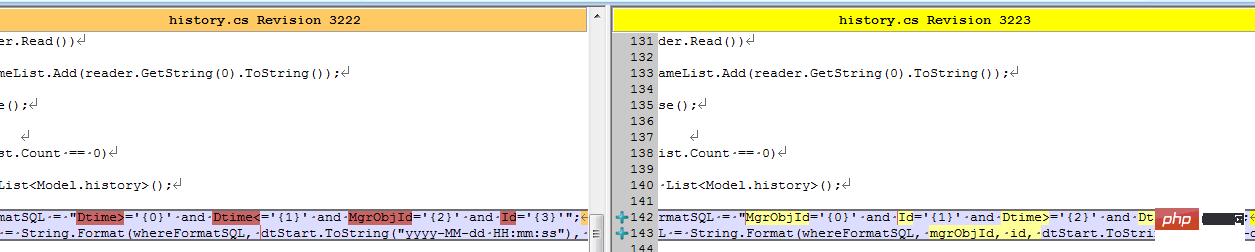
难道真的有这么大的影响?等等,是不是忘记清空缓存,造成了假象?
于是让同事执行下述语句以便得出更多的信息:
--优化之前DBCC FREEPROCCACHEDBCC DROPCLEANBUFFERSSET STATISTICS IO ONselect Dtime,Value from dbo.his20140825 WHERE Dtime>='' AND Dtime<='' AND MgrObjId='' AND Id=''SET STATISTICS IO OFF--优化之后DBCC FREEPROCCACHEDBCC DROPCLEANBUFFERSSET STATISTICS IO ONselect Dtime,Value from dbo.his20140825 WHERE MgrObjId='' AND Id='' AND Dtime>='' AND Dtime<=''SET STATISTICS IO OFF
结果如下: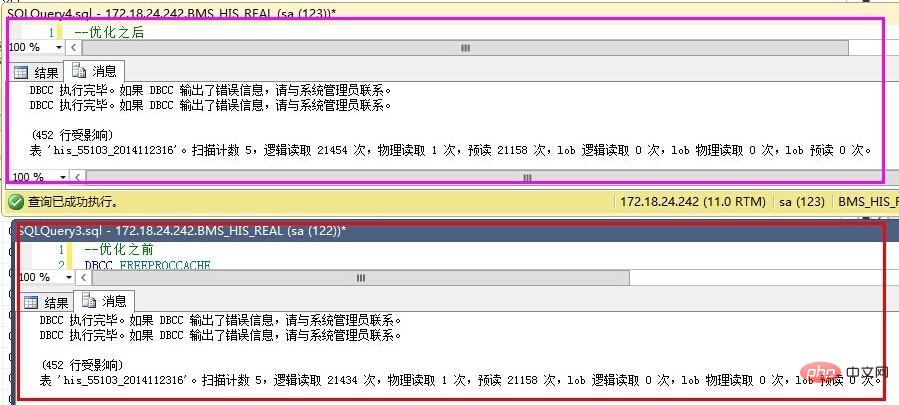
优化之前反而更好了?
仔细查看IO数据,发现,预读是一样的,就是说我们要查询的数据记录都是一致的,物理读、表扫描也是一直的。而逻辑读取稍有区别,应该是缓存命中数导致的。也就是说,在不建立索引的情况下,where子句的条件顺序,对查询结果优化作用不明显。
那么,就只能通过索引的办法了。
建立索引的尝试
建立索引不是简单的事情,是需要了解一些基本的知识的,在这个过程中,我走了不少弯路,最终才把索引建立起来。
下面的实验基于以下记录总数做的验证: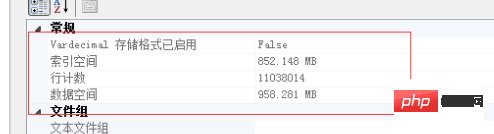
按单个字段建立索引
这个想法,主要是受我建立数据结构影响的,我内存中的数据结构为:Dictionary44c8bf3c168555d7e46180150f40c496>。我以为先建立MgrObjId的索引,再建立Id的索引,SQLServer查询时,就会更快。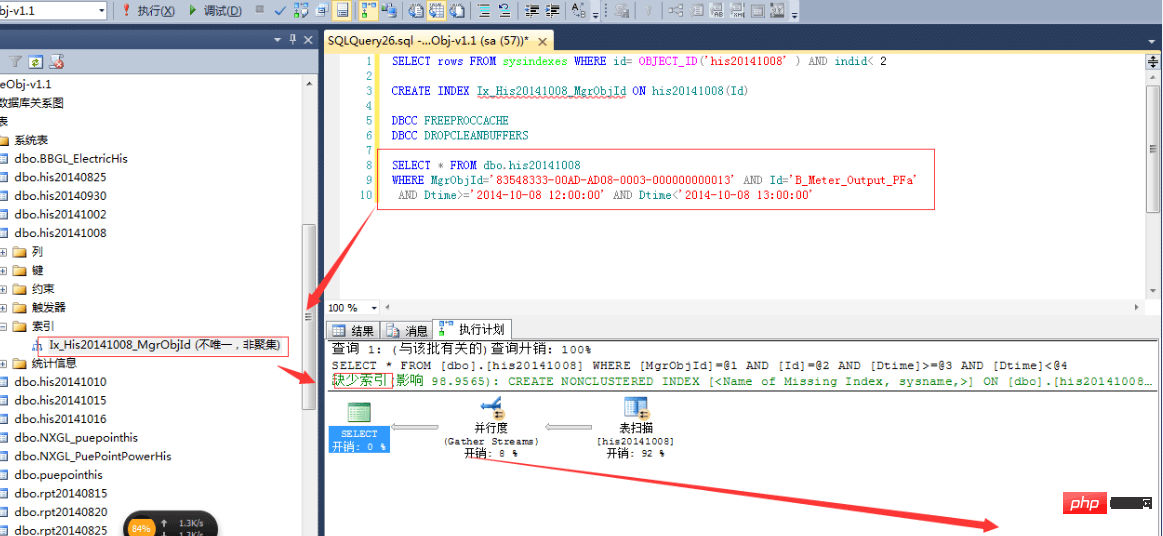
先按MgrObjId建立索引,索引大小为550M,耗时5分25秒。结果,如上图的预估计划一样,根本没有起作用,反而更慢了。
按多个条件建立索引
OK,既然上面的不行,那么我们按多个条件建立索引又如何?CREATE NONCLUSTERED INDEX Idx_His20141008 ON dbo.his20141008(MgrObjId,Id,Dtime)
结果,查询速度确实提高了一倍: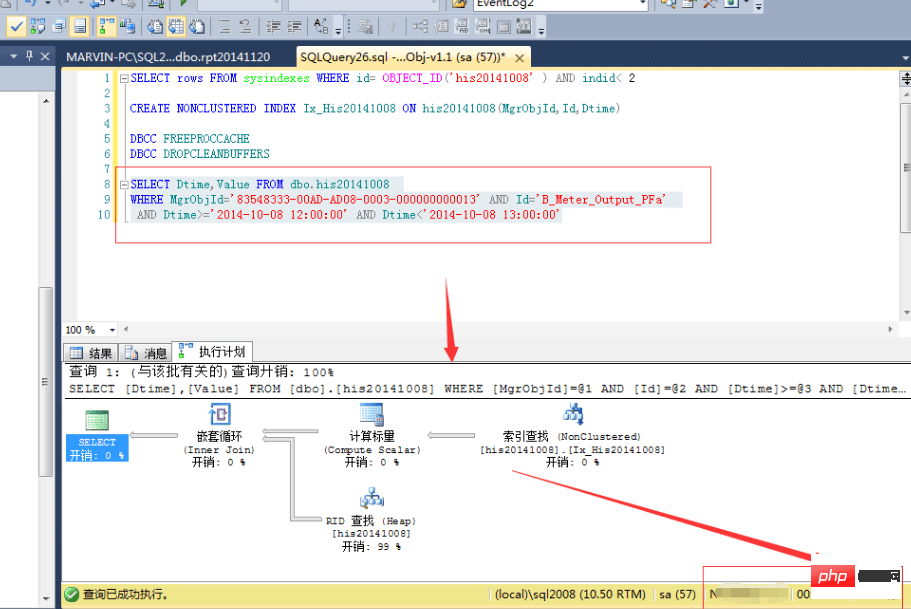
等等,难道这就是索引的好处?花费7分25秒,用1.1G的空间换取来的就是这些?肯定是有什么地方不对了,于是开始翻查资料,查看一些相关书籍,最终,有了较大的进展。
正确的建立索引
首先,我们需要明白几个索引的要点:
- Après l'indexation, le tri par les champs d'index les moins répétés obtiendra l'effet optimal. Pour notre table, si un index clusterisé de No est établi, il est préférable de mettre No en premier dans la clause Where, suivi de Id, puis de MgrObjId et enfin de time. Si l'index de temps est une heure, il est préférable de ne pas le faire. use
-
L'ordre de la clause Where détermine si l'analyseur de requêtes utilise l'index pour interroger . Par exemple, si l'index de MgrObjId et Id est établi, alors
where MgrObjId='' and Id='' and Dtime=''utilisera la recherche par index, maiswhere Dtime='' and MgrObjId='' and Id=''n'utilisera pas nécessairement la recherche par index. - Placez la colonne résultat de la colonne non indexée dans la colonne contenant . Étant donné que notre condition est MgrObjId, Id et Dtime, nous devons uniquement inclure Dtime et Value dans le résultat renvoyé. Par conséquent, placez Dtime et Value dans la colonne incluse et le résultat de l'index renvoyé aura cette valeur. Il n'est pas nécessaire de vérifier. la table physique atteindre une vitesse optimale.
En suivant les principes ci-dessus, nous créons l'index suivant : CREATE NONCLUSTERED INDEX Idx_His20141008 ON dbo.his20141008(MgrObjId,Id) INCLUDE(Value,Dtime)
Le temps pris est : plus de 6 minutes, et la taille de l'index est de 903M.
Regardons le forfait estimé : 
Comme vous pouvez le constater, l'indice est ici entièrement utilisé, sans consommation supplémentaire. Les résultats d'exécution réels ont pris moins d'une seconde, et les résultats ont été filtrés des 11 millions d'enregistrements en moins d'une seconde ! ! Tellement beau ! !
Comment appliquer l'index ?
Maintenant que l'écriture et la lecture sont terminées, comment les combiner ? Nous pouvons indexer les données d'il y a une heure, mais pas les données de l'heure en cours. Autrement dit, ne créez pas d’index lors de la création de tables ! !
Comment pouvez-vous l'optimiser autrement ?
Vous pouvez essayer de séparer la lecture et l'écriture et d'écrire deux bibliothèques, l'une est une bibliothèque en temps réel et l'autre est une bibliothèque en lecture seule. Les données d'une heure sont interrogées dans la base de données en temps réel, et les données d'il y a une heure sont interrogées dans la base de données en lecture seule ; la base de données en lecture seule est stockée régulièrement, puis les données indexées sur une semaine sont analysées, traitées et analysées ; puis stocké. De cette façon, quelle que soit la période pendant laquelle les données sont interrogées, elles peuvent être traitées correctement : interroger la base de données en temps réel dans un délai d'une heure, interroger la base de données en lecture seule dans un délai d'une heure à une semaine et interroger la base de données de rapports une semaine. il y a.
Si le partitionnement physique n'est pas requis, reconstruisez simplement l'index régulièrement dans la bibliothèque en lecture seule.
Résumé
Comment traiter des milliards de données (données historiques) dans SQL Server, vous pouvez procéder comme suit :
- Supprimer tout les index de la table
- sont insérés à l'aide de SqlBulkCopy
- divisés en tables ou partitions pour réduire la quantité totale de données dans chaque table
- Créer un index une fois qu'une table est complètement écrite
- Spécifiez correctement les champs d'index
- Placez les champs dont vous avez besoin dans l'index contenant (tout est inclus dans l'index renvoyé)
- Renvoyer uniquement lors de l'interrogation des champs obligatoires
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!