
Maison > Article > base de données > Explication détaillée de l'utilisation des fonctions Partition By et row_number dans SQL Server
Explication détaillée de l'utilisation des fonctions Partition By et row_number dans SQL Server

- coldplay.xixiavant
- 2020-07-24 17:39:544290parcourir

la partition par mot-clé fait partie de la fonction analytique. La différence entre elle et la fonction d'agrégation est qu'elle peut renvoyer plusieurs enregistrements dans un groupe, alors que la fonction d'agrégation n'en a généralement qu'un. reflètent les statistiques. Enregistrements de valeurs, la partition par est utilisée pour regrouper l'ensemble de résultats. S'il n'est pas spécifié, il traite l'intégralité de l'ensemble de résultats comme un groupe.
J'ai vu une question dans le groupe aujourd'hui, et je vais la résumer ici : interrogez les derniers enregistrements dans différentes catégories. N'est-ce pas très simple à première vue ? Si vous souhaitez classer, utilisez Group By ; si vous voulez le dernier enregistrement, utilisez Order By. Essayez ensuite de le créer dans votre propre tableau :
Recommandations d'apprentissage associées : Tutoriel vidéo MySQL
Tout d'abord, je mets les données dans le tableau Sortez dans l'ordre inverse de l'heure de soumission :
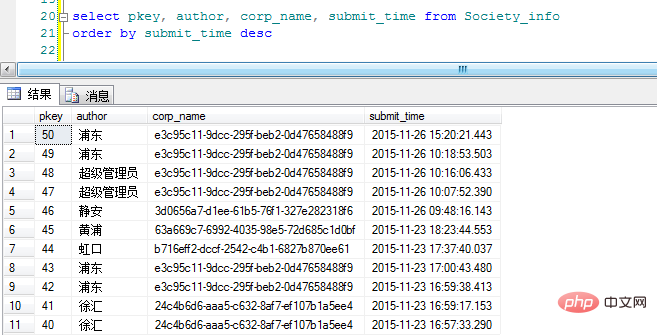
"corp_name" est le GUID de la catégorie (veuillez pardonner l'arbitraire de ma dénomination). OK, voici l'idée originale d'ajouter Group By pour voir l'effet d'affichage :
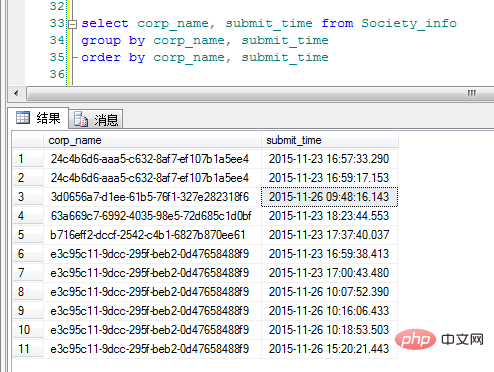
Euh, euh. Ce résultat est différent de ce que j'imaginais. Il semble que lors de l'écriture du code, vous devez toujours analyser le problème de manière rationnelle. Votre esprit ne peut pas contrôler le résultat !
Étant donné que les exigences sont différentes catégories de données, outre l'utilisation de Group By, existe-t-il d'autres fonctions qui peuvent être utilisées ? J'ai fait quelques recherches et découvert qu'il existe effectivement une fonction de sur-(partition par). Alors, quelle est la différence entre elle et le Group By habituellement utilisé ? En plus de simplement regrouper les résultats, Group By est généralement utilisé avec des fonctions d'agrégation. Partition By a également une fonction de regroupement et est une fonction d'analyse Oracle. Je n'entrerai pas dans les détails ici.
Regardez le code :
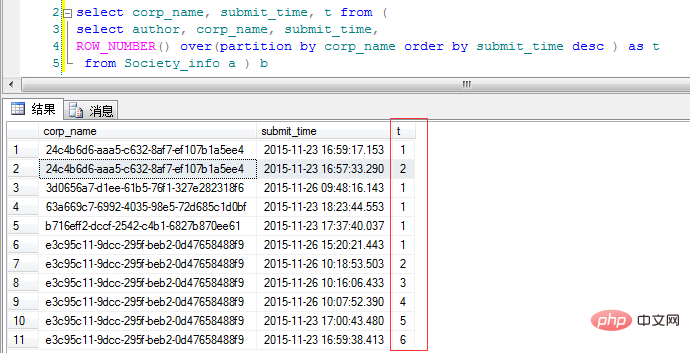
over(partition by corp_name order by submit_time desc ) as t . Il est classé selon corp_name et trié dans l'ordre chronologique inverse. La colonne "t" est ici le nombre d'occurrences des différentes classes corp_name. L'exigence est d'interroger uniquement les dernières données de soumission des différentes catégories, il suffit alors de filtrer. encore une fois pour "t". :
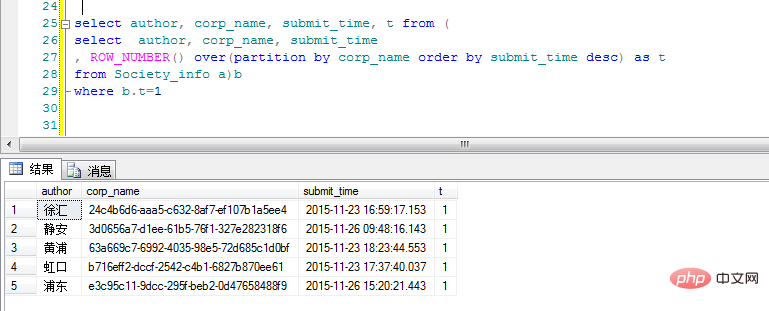
D'accord, les résultats sont sortis, je ne vous demande pas de les aimer, mais je veux juste que vous me donniez un coup de pouce. si vous regardez les seins de mon avatar, je vous souhaite une vie sûre ! ! !
ps : Explication détaillée de l'utilisation des fonctions de partitionnement de base de données SQL Server par et ROW_NUMBER()
Une certaine expérience d'utilisation de la partition par champ dans SQL
Regardez d'abord Exemple :
if object_id('TESTDB') is not null drop table TESTDB create table TESTDB(A varchar(8), B varchar(8)) insert into TESTDB select 'A1', 'B1' union all select 'A1', 'B2' union all select 'A1', 'B3' union all select 'A2', 'B4' union all select 'A2', 'B5' union all select 'A2', 'B6' union all select 'A3', 'B7' union all select 'A3', 'B3' union all select 'A3', 'B4'
-- Toutes les informations
SELECT * FROM TESTDB A B ------- A1 B1 A1 B2 A1 B3 A2 B4 A2 B5 A2 B6 A3 B7 A3 B3 A3 B4
-- Après avoir utilisé la fonction PARTITION BY,
SELECT *,ROW_NUMBER() OVER(PARTITION BY A ORDER BY A DESC) NUM FROM TESTDB A B NUM ------------- A1 B1 1 A1 B2 2 A1 B3 3 A2 B4 1 A2 B5 2 A2 B6 3 A3 B7 1 A3 B3 2 A3 B4 3
peut voir qu'il y a une colonne supplémentaire de NUM dans le résultat. Ce NUM illustre le même nombre de lignes, par exemple, s'il y a 3 A1, il marquera le numéro de chaque A1.
-- Utilisez simplement le résultat de ROW_NUMBER() OVER
SELECT *,ROW_NUMBER() OVER(ORDER BY A DESC)NUM FROM TESTDB A B NUM ------------------------ A3 B7 1 A3 B3 2 A3 B4 3 A2 B4 4 A2 B5 5 A2 B6 6 A1 B1 7 A1 B2 8 A1 B3 9
Vous pouvez voir qu'il marque simplement le numéro de ligne.
--Une application plus approfondie
SELECT A = CASE WHEN NUM = 1 THEN A ELSE '' END,B FROM (SELECT A,NUM = ROW_NUMBER() OVER(PARTITION BY A ORDER BY A DESC) FROM TESTDB) T A B --------- A1 B1 B2 B3 A2 B4 B5 B6 A3 B7 B3 B4
Ensuite, nous présenterons l'utilisation de la fonction ROW_NUMBER() à travers plusieurs exemples.
Les exemples sont les suivants :
1. Utilisez la fonction row_number() pour la numérotation, telle que
select email,customerID, ROW_NUMBER() over(order by psd) as rows from QT_Customer
Principe : Trier par psd d'abord, après le tri, numérotez chaque élément de données.
2. Triez la commande par ordre croissant de prix, et triez chaque enregistrement avec le code suivant :
select DID,customerID,totalPrice,ROW_NUMBER() over(order by totalPrice) as rows from OP_Order
3. chaque foyer est trié par ordre croissant selon le montant de la commande de chaque client, et la commande de chaque client est numérotée. De cette façon, vous saurez combien de commandes chaque client a passées .
Comme indiqué sur l'image :

Le code est le suivant :
select ROW_NUMBER() over(partition by customerID order by totalPrice) as rows,customerID,totalPrice, DID from OP_Order
4. La commande a été passée.

Le code est le suivant :
with tabs as ( select ROW_NUMBER() over(partition by customerID order by totalPrice) as rows,customerID,totalPrice, DID from OP_Order ) select MAX(rows) as '下单次数',customerID from tabs group by customerID
5. Comptez le montant minimum d'achat parmi toutes les commandes de chaque client, et comptez également le montant minimum d'achat. changements dans les commandes. Combien de fois le client a-t-il acheté ?
如图:

上图:rows表示客户是第几次购买。
思路:利用临时表来执行这一操作。
1.先按客户进行分组,然后按客户的下单的时间进行排序,并进行编号。
2.然后利用子查询查找出每一个客户购买时的最小价格。
3.根据查找出每一个客户的最小价格来查找相应的记录。
代码如下:
with tabs as ( select ROW_NUMBER() over(partition by customerID order by insDT) as rows,customerID,totalPrice, DID from OP_Order ) select * from tabs where totalPrice in ( select MIN(totalPrice)from tabs group by customerID )
6.筛选出客户第一次下的订单。

思路。利用rows=1来查询客户第一次下的订单记录。
代码如下:
with tabs as ( select ROW_NUMBER() over(partition by customerID order by insDT) as rows,* from OP_Order ) select * from tabs where rows = 1 select * from OP_Order
7.rows_number()可用于分页
思路:先把所有的产品筛选出来,然后对这些产品进行编号。然后在where子句中进行过滤。
8.注意:在使用over等开窗函数时,over里头的分组及排序的执行晚于“where,group by,order by”的执行。
如下代码:
select ROW_NUMBER() over(partition by customerID order by insDT) as rows, customerID,totalPrice, DID from OP_Order where insDT>'2011-07-22'
以上代码是先执行where子句,执行完后,再给每一条记录进行编号。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!