
Maison >base de données >tutoriel mysql >Base de données relationnelle mysql trois : à partir du cycle de vie d'un sql
Base de données relationnelle mysql trois : à partir du cycle de vie d'un sql

- coldplay.xixiavant
- 2020-11-13 17:16:472921parcourir
La colonne
tutoriel mysql présente le cycle de vie de SQL dans les bases de données relationnelles.
Traitement des requêtes MYSQL
Le processus d'exécution de SQL est fondamentalement le même que l'architecture MySQL
Exécution processus :
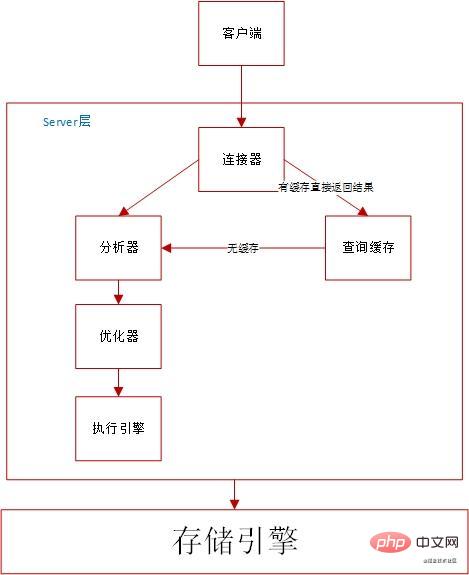
Créez une connexion avec MySQL pour interroger les instructions SQL et juger les autorisations. Cache de requêtes :
- Si l'instruction n'est pas dans le cache de requêtes, elle passera à la phase d'exécution suivante. Une fois l'exécution terminée, les résultats de l'exécution seront stockés dans le cache de requête
- Si la requête atteint le cache, MySQL peut renvoyer directement les résultats sans effectuer d'opérations complexes ultérieures, améliorant ainsi l'efficacité
- Avec index : Le premier appel consiste à obtenir l'interface de la première ligne qui remplit la condition, puis une boucle pour obtenir l'interface de la ligne suivante qui remplit la condition, et enfin les résultats de la requête sont renvoyés au client
- Pas d'index : appelez l'interface du moteur InnoDB pour obtenir la première ligne de cette table, déterminez les conditions de la requête SQL, ignorez si non, si oui, stockez ceci ligne dans l'ensemble de résultats ; appelez l'interface du moteur. Obtenez la ligne suivante et répétez la même logique de jugement jusqu'à ce que vous obteniez la dernière ligne du tableau. L'exécuteur renvoie un ensemble d'enregistrements composé de toutes les lignes qui remplissent les conditions au cours du processus de parcours ci-dessus comme ensemble de résultats au client
Comment va la commande EXPLAIN produit MySQL Exécutez votre instruction SQL, mais ne renverra pas de donnéesComment utiliser
[root@localhost][(none)]> explain select * from 表名 where project_id = 36;
+----+-------------+--------------------------+------------+------+---------------+------------+---------+-------+--------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------------------------+------------+------+---------------+------------+---------+-------+--------+----------+-------+
| 1 | SIMPLE | 表名 | NULL | ref | project_id | project_id | 4 | const | 797964 | 100.00 | NULL |
+----+-------------+--------------------------+------------+------+---------------+------------+---------+-------+--------+----------+-------+复制代码
id
- id même ordre d'exécution à partir du haut vers le bas
- L'identifiant est différent, plus la valeur de l'identifiant est grande, plus la priorité est élevée, plus il est exécuté tôt
- SIMPLE : une simple requête de sélection, la requête ne contient pas de sous-titres Requête ou union
- PRIMARY : La requête contient des sous-parties et la requête la plus externe est marquée comme primaire
- DERIVED : Elle fait partie de la sous-requête de
- SOUS-REQUÊTE DÉPENDANTE : sub Le premier SELECT de la requête, la sous-requête dépend du résultat de la requête externe
- SOUS-REQUÊTE signifie que la sous-requête est incluse dans la liste de sélection ou où,
- MATERIALIZED : signifie la condition dans après où la sous-requête
- UNION : représente la deuxième instruction de sélection ou la suivante dans l'union
- UNION RESULT : le résultat de l'union
- Objet table
système > eq_ref > TOUS (efficacité des requêtes)
- system:表中只有一条数据,这个类型是特殊的const类型
- const:针对于主键或唯一索引的等值查询扫描,最多只返回一个行数据。速度非常快,因为只读取一次即可。
- eq_ref:此类型通常出现在多表的join查询,表示对于前表的每一个结果,都只能匹配到后表的一行结果,并且查询的比较操作通常是=,查询效率较高
- ref:此类型通常出现在多表的join查询,针对于非唯一或非主键索引,或者是使用了最左前缀规则索引的查询
- range:范围扫描 这个类型通常出现在 <>, >, >=, <, <=, IS NULL, <=>, BETWEEN, IN() 操作中
- index:索引树扫描
- ALL:全表扫描(full table scan)
possible_keys
- 可能使用的索引,注意不一定会使用
- 查询涉及到的字段上若存在索引,则该索引将被列出来
- 当该列为NULL时就要考虑当前的SQL是否需要优化了
key
- 显示MySQL在查询中实际使用的索引,若没有使用索引,显示NULL。
- 查询中若使用了覆盖索引(覆盖索引:索引的数据覆盖了需要查询的所有数据),则该索引仅出现在key列表中
key_length
- 索引长度
ref
- 表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值
rows
- 返回估算的结果集数目,并不是准确的值
filtered
- 示返回结果的行数占需读取行数的百分比, filtered 的值越大越好
extra
- Using where:表示优化器需要通过索引回表,之后到server层进行过滤查询数据
- Using index:表示直接访问索引就足够获取到所需要的数据,不需要回表
- Using index condition:在5.6版本后加入的新特性(Index Condition Pushdown)
- Using index for group-by:使用了索引来进行GROUP BY或者DISTINCT的查询
- Using filesort:当 Extra 中有 Using filesort 时, 表示 MySQL 需额外的排序操作, 不不能通过索引顺序达到排序效果. 一般有 Using filesort, 都建议优化去掉, 因为这样的查询 CPU 资源消耗大
- Using temporary 临时表被使用,时常出现在GROUP BY和ORDER BY子句情况下。(sort buffer或者磁盘被使用)
光看 filesort 字面意思,可能以为是要利用磁盘文件进行排序,实则不全然。 当MySQL不能使用索引进行排序时,就会利用自己的排序算法(快速排序算法)在内存(sort buffer)中对数据进行排序,如果内存装载不下,它会将磁盘上的数据进行分块,再对各个 数据块进行排序,然后将各个块合并成有序的结果集(实际上就是外排序)。
当对连接操作进行排序时,如果ORDER BY仅仅引用第一个表的列,MySQL对该表进行filesort操作,然后进行连接处理,此时,EXPLAIN输出“Using filesort”;否则,MySQL必 须将查询的结果集生成一个临时表,在连接完成之后行行filesort操作,此时,EXPLAIN输出“Using temporary;Using filesort”。
提高查询效率
正确使用索引
为解释方便,来一个demo:
DROP TABLE IF EXISTS user; CREATE TABLE user( id int AUTO_INCREMENT PRIMARY KEY, user_name varchar(30) NOT NULL, gender bit(1) NOT NULL DEFAULT b’1’, city varchar(50) NOT NULL, age int NOT NULL )ENGINE=InnoDB DEFAULT CHARSET=utf8; ALTER TABLE user ADD INDEX idx_user(user_name , city , age); 复制代码
什么样的索引可以被使用?
- **全匹配:**SELECT * FROM user WHERE user_name='JueJin'AND age='5' AND city='上海';(与where后查询条件的顺序无关)
- 匹配最左前缀:(user_name )、(user_name, city)、(user_name , city , age)(满足最左前缀查询条件的顺序与索引列的顺序无关,如:(city, user_name)、(age, city, user_name))
- **匹配列前缀:**SELECT * FROM user WHERE user_name LIKE 'W%'
- **匹配范围值:**SELECT * FROM user WHERE user_name BETWEEN 'W%' AND 'Z%'
什么样的索引无法被使用?
- **where查询条件中不包含索引列中的最左索引列,则无法使用到索引: **
SELECT * FROM user WHERE city='上海';
SELECT * FROM user WHERE age='26';
SELECT * FROM user WHERE age='26' AND city=‘上海';
- ** Même si la condition de requête Where est la colonne d'index la plus à gauche, vous ne pouvez pas utiliser l'index pour interroger les utilisateurs dont le nom d'utilisateur se termine par N : **
SELECT * FROM user WHERE user_name LIKE '%N';
- ** S'il existe une requête de plage d'une certaine colonne dans la condition de requête Where, toutes les colonnes de droite ne peuvent pas utiliser la requête d'optimisation d'index : **
SELECT * FROM user WHERE user_name='JueJin' AND city LIKE '上%' AND age=31
- **La colonne d'index ne peut pas faire partie de l'expression, il ne peut pas non plus être utilisé comme paramètre de la fonction, sinon la requête d'index ne peut pas être utilisée : **
SELECT * FROM user WHERE user_name=concat(user_name,'PLUS');
Sélectionnez l'ordre des colonnes d'index approprié
- L'ordre des colonnes d'index est très important dans la création d'un index composite. L'ordre correct de l'index dépend de la méthode de requête de la requête utilisant l'index <.> L'ordre d'indexation de l'index composite peut être le plus sélectif. La colonne est placée au début de l'index. Cette règle est cohérente avec la méthode sélective d'indexation des préfixes
- Cela ne veut pas dire que. l'ordre de tous les index combinés peut être déterminé à l'aide de cette règle. Il doit également être déterminé en fonction du scénario de requête spécifique
- Si. un index contient les valeurs de tous les champs à interroger, on l'appelle un index couvrant
Étant donné que les champs à interroger (user_name, city, age ) sont inclus dans les colonnes d'index de l'index combiné, une requête d'index de couverture est donc utilisée pour vérifier. si un index de couverture est utilisé, la valeur de Extra dans le plan d'exécution estUtiliser l'index pour le tri Si vous pouvez utiliser l'index pour le tri pendant l'opération de tri, vous pouvez considérablement améliorer la vitesse de tri. Pour utiliser l'index pour le tri, vous devez respecter les exigences. suivant deux points C'est tout :Using index, ce qui prouve qu'un index de couverture est utilisé, l'index de couverture peut considérablement améliorer les performances d'accès.
- L'ordre des colonnes après la clause ORDER BY doit être cohérent avec l'ordre des colonnes de l'index combiné, et le sens de tri (ordre avant/arrière) de toutes les colonnes de tri doit être cohérent
- La valeur du champ interrogé doit être incluse dans la colonne d'index et satisfaire l'index de couverture
- SELECT user_name, ville, âge FROM user_test ORDER BY user_name;
- SELECT user_name, ville, âge FROM user_test ORDER BY user_name,city;
- SELECT user_name, ville, âge FROM user_test ORDER BY user_name DESC,city DESC ;
- SELECT nom_utilisateur, ville, âge FROM user_test WHERE nom_utilisateur='Tony' ORDER BY city;
- SELECT nom_utilisateur , ville, âge FROM user_test ORDER BY user_name
- sexe; SELECT user_name, ville, âge,
- sexe FROM user_test ORDER BY user_name SELECT; nom_utilisateur, ville, âge FROM user_test ORDER BY nom_utilisateur
- ASC,ville DESC; SELECT nom_utilisateur, ville, âge FROM user_test WHERE nom_utilisateur LIKE
- 'W% ' ORDER BY city;
Ne pas renvoyer la limite de données qui n'est pas requise par le programme utilisateur
LIMIT : MySQL ne peut pas renvoyer la quantité de données requise, c'est-à-dire que MySQL interrogera toujours toutes les données. L'utilisation de la clause LIMIT vise en fait à réduire la pression de la transmission des données sur le réseau et ne réduira pas le nombre. de lignes de données lues.
Supprimer les colonnes inutiles
- L'instruction SELECT * supprime tous les champs de la table, que les données du champ soient utiles ou non à l'application appelante. Cela entraînera un gaspillage des ressources du serveur et aura même un certain impact sur les performances du serveur
- Si la structure de la table change à l'avenir, l'instruction SELECT * peut obtenir des données incorrectes
- Lors de l'exécution d'une instruction SELECT *, vous devez d'abord découvrir quelles colonnes se trouvent dans le tableau, puis vous pouvez commencer à exécuter l'instruction SELECT * Cela entraînera des problèmes de performances dans certains cas
- Utilisation de l'instruction SELECT *. ne provoquera pas d'écrasement. Les index ne sont pas propices à l'optimisation des performances des requêtes
Les avantages d'une utilisation correcte des index
- Évitez l'analyse complète de la table
- Lors de l'interrogation d'une seule table, une analyse complète de la table doit interroger chaque ligne
- Lors de l'interrogation de plusieurs tables, une analyse complète de la table L'analyse des tables nécessite au moins Récupérer chaque ligne de toutes les tables
- Améliorer la vitesse
- Peut localiser rapidement la première ligne de l'ensemble de résultats
- Exclure le résultat non pertinent
- Pas besoin de vérifier chaque ligne pour les valeurs MIN() ou MAX()
- Améliorer l'efficacité du tri et du regroupement
- Vous pouvez utiliser l'index de couverture Évitez les boucles de lignes
Le coût de l'indexation
- S'il y a trop d'index, la modification des données deviendra lente
- L'index concerné doit être mis à jour
- C'est très stressant pour les environnements gourmands en écriture
- L'index consomme trop d'espace disque
- Le moteur de stockage InnoDB stocke les index et les données ensemble
- L'espace disque doit être surveillé
Meilleures pratiques d'indexation
Envisagez d'utiliser des index pour les
- Colonnes de la clause WHERE
- Colonnes de la clause ORDER BY ou GROUP BY
- Colonnes de condition de jointure de table
Pensez à utiliser des index de préfixe pour les colonnes de chaînes
- pour une comparaison plus rapide et effectuez une boucle
- pour réduire les E/S du disque
instructions SELECT sont inefficaces Lorsque vous envisagez
- évitez l'analyse complète de la table
- essayez d'ajouter l'index
- instruction WHERE
- conditions de connexion à la table
- Utilisez ANALYZE TABLE pour collecter des informations statistiques
- Envisagez l'optimisation de la couche moteur de stockage
Ajustez la méthode de connexion de la table
- Ajouter des index sur les colonnes de la clause ON ou USING
- Utiliser SELECT STRAIGHT_JOIN pour forcer l'ordre de connexion des tables
- Ajouter des index sur les colonnes de ORDER BY et GROUP BY
- join Les jointures ne sont pas nécessairement plus efficaces que les sous-requêtes
Plus de recommandations d'apprentissage gratuites associées : tutoriel mysql (Vidéo)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!