
Maison >base de données >tutoriel mysql >Présentation de points de connaissances importants : le tampon d'insertion d'InnoDB
Présentation de points de connaissances importants : le tampon d'insertion d'InnoDB

- coldplay.xixiavant
- 2020-10-30 17:01:522369parcourir
La colonne
Tutoriel vidéo MySQL présente le tampon d'insertion d'InnoDB.

Le moteur InnoDB possède plusieurs fonctionnalités clés qui lui apportent de meilleures performances et fiabilité :
- Insérer un tampon)
- Double écriture
- Index de hachage adaptatif (Index de hachage adaptatif)
- Async IO (Async IO)
- Actualiser la page de contiguïté (Flush Neighbor Page)
Aujourd'hui notre thème est 插入缓冲(Insert Buffer), car la structure de stockage de données sous-jacente du moteur InnoDB est un arbre B+, et pour les index, nous avons des index clusterisés et des index non clusterisés.
Lors de l'insertion des données, des changements d'index se produiront inévitablement. Inutile de dire que les index clusterisés sont généralement classés par ordre croissant. Les index non clusterisés ne sont pas nécessairement des données et leur nature discrète entraîne des changements continus dans la structure lors de l'insertion, ce qui entraîne une réduction des performances d'insertion.
Ainsi, afin de résoudre le problème des performances d'insertion d'index non clusterisés, le moteur InnoDB a créé le tampon d'insertion.
Stockage du tampon d'insertion
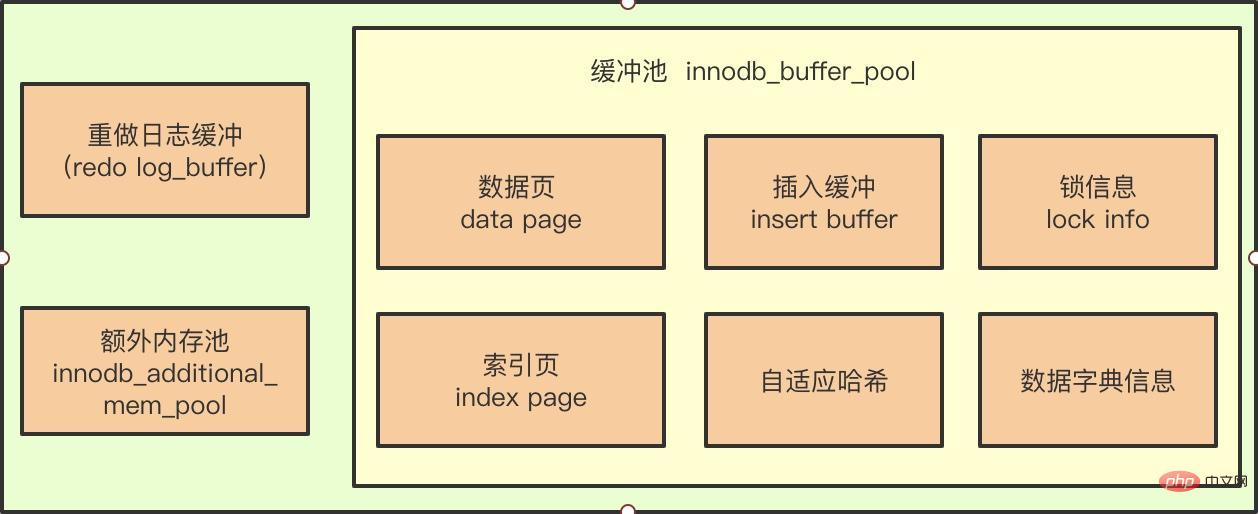
En voyant l'image ci-dessus, vous pensez peut-être que Insert Buffer est un composant du pool de tampons InnoDB.
**Point clé :**En fait, c'est vrai ou faux. Le pool de tampons InnoDB contient les informations du tampon d'insertion, mais le tampon d'insertion existe en réalité physiquement comme la page de données (une table partagée existe sous la forme d'un arbre B+ dans l'espace).
Le rôle d'Insert Buffer
Permettez-moi d'abord de parler de quelques points :
Une table ne peut en avoir qu'un index de clé primaire. C'est parce que son stockage physique est un arbre B+. (N'oubliez pas les données stockées dans les nœuds feuilles d'index clusterisés, et il n'y a qu'une seule copie des données)
Les nœuds feuilles d'index non clusterisés stockent la clé primaire du index clusterisé
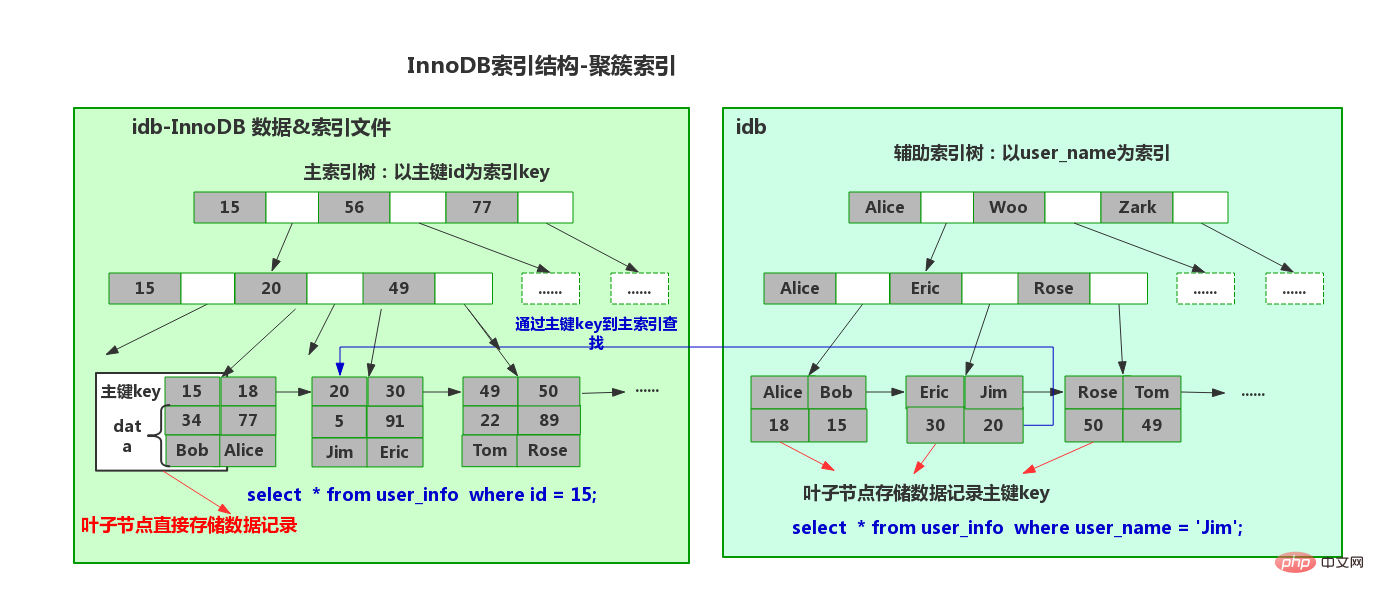
Insertion dans l'index clusterisé
Tout d'abord, nous savons que dans le stockage InnoDB moteur, la clé primaire est l'identifiant unique de la ligne (c'est-à-dire que nous indexons souvent en cluster). Nous insérons généralement les données de manière incrémentielle en fonction de la clé primaire, de sorte que l'index clusterisé est séquentiel et ne nécessite pas de lecture aléatoire sur le disque.
Par exemple, table :
CREATE TABLE test( id INT AUTO_INCREMENT, name VARCHAR(30), PRIMARY KEY(id) );复制代码
Comme ci-dessus, j'ai créé un identifiant de clé primaire, qui a les caractéristiques suivantes :
- La colonne Id est auto-augmentante
- Lorsqu'une valeur NULL est insérée dans la colonne Id, sa valeur sera incrémentée en raison de AUTO_INCREMENT
- En même temps, les enregistrements de ligne dans la page de données sont stockés dans l'ordre selon le valeur d'identification
Généralement, en raison de l'ordre de l'index clusterisé, il ne nécessite pas de lecture aléatoire des données dans la page, car ce type d'insertion séquentielle est très rapide.
Mais si vous insérez l'ID de colonne dans des données comme l'UUID, alors votre insertion sera aussi aléatoire qu'un index non clusterisé. Cela entraînera une modification constante de votre arborescence B+ et les performances en seront inévitablement affectées.
Insertion d'index non clusterisés
Souvent, notre table aura de nombreux index non clusterisés. Par exemple, j'interroge en fonction du champ b et du b. le domaine n’est pas unique. Comme le montre le tableau suivant :
CREATE TABLE test( id INT AUTO_INCREMENT, name VARCHAR(30), PRIMARY KEY(id), KEY(name) );复制代码
Ici, j'ai créé un nom d'index
- Lors de l'insertion de données, les pages de données sont stockées séquentiellement en fonction de l'identifiant de clé primaire
- Les données l'insertion du nom de l'index auxiliaire n'est pas séquentielle
- L'index non clusterisé est également le même. Il s'agit d'un arbre B+, mais les nœuds feuilles stockent la clé primaire et la valeur du nom de l'index clusterisé.
- Étant donné que les données de la colonne de nom ne peuvent pas être garanties comme étant séquentielles, l'insertion de l'arborescence d'index non clusterisée ne doit pas être séquentielle.
L'arrivée d'Insert Buffer
On constate que la nature discrète de l'insertion d'index non clusterisés entraîne une diminution des performances d'insertion, c'est pourquoi le moteur InnoDB a conçu le tampon d'insertion pour améliorer les performances d'insertion.Permettez-moi de voir comment insérer à l'aide d'Insert Buffer :
Tout d'abord, pour l'insertion d'un index non clusterisé ou des opérations de mise à jour, au lieu d'insérer directement dans la page d'index à chaque fois, il détermine d'abord si la page d'index non clusterisée insérée se trouve dans le pool de mémoire tampon.
S'il est là, insérez-le directement ; s'il n'y est pas, placez-le d'abord dans un objet Insert Buffer. 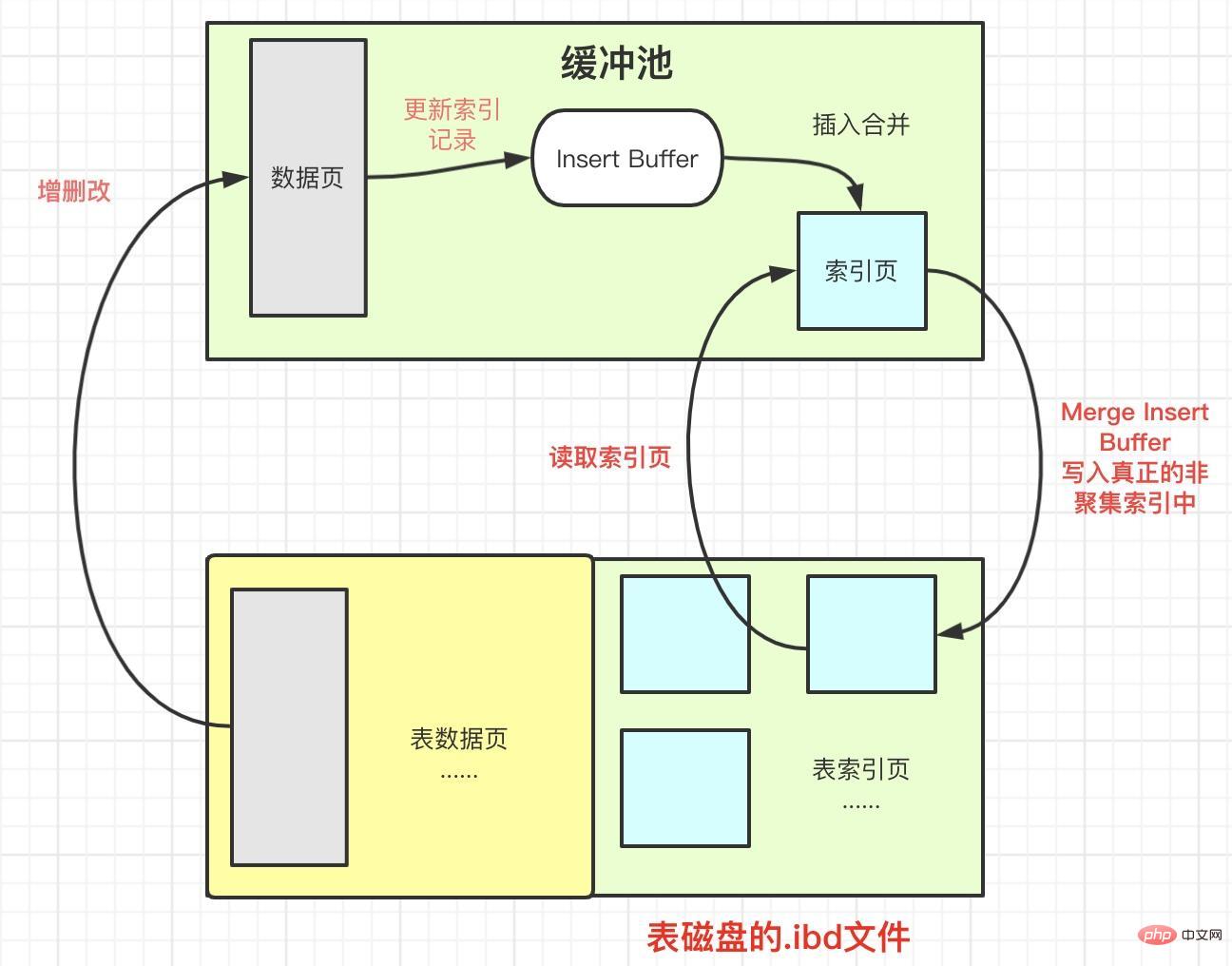
Insert Buffer的使用要求:
- 索引是非聚集索引
- 索引不是唯一(unique)的
只有满足上面两个必要条件时,InnoDB存储引擎才会使用Insert Buffer来提高插入性能。
那为什么必须满足上面两个条件呢?
第一点索引是非聚集索引就不用说了,人家聚集索引本来就是顺序的也不需要你
第二点必须不是唯一(unique)的,因为在写入Insert Buffer时,数据库并不会去判断插入记录的唯一性。如果再去查找肯定又是离散读取的情况了,这样InsertBuffer就失去了意义。
Insert Buffer信息查看
我们可以使用命令SHOW ENGINE INNODB STATUS来查看Insert Buffer的信息:
------------------------------------- INSERT BUFFER AND ADAPTIVE HASH INDEX ------------------------------------- Ibuf: size 7545, free list len 3790, seg size 11336, 8075308 inserts,7540969 merged sec, 2246304 merges ...复制代码
使用命令后,我们会看到很多信息,这里我们只看下INSERT BUFFER 的:
seg size 代表当前Insert Buffer的大小 11336*16KB
free listlen 代表了空闲列表的长度
size 代表了已经合并记录页的数量
Inserts 代表了插入的记录数
merged recs 代表了合并的插入记录数量
merges 代表合并的次数,也就是实际读取页的次数
merges:merged recs大约为1∶3,代表了Insert Buffer 将对于非聚集索引页的离散IO逻辑请求大约降低了2/3
Insert Buffer的问题
说了这么多针对于Insert Buffer的好处,但目前Insert Buffer也存在一个问题:
即在写密集的情况下,插入缓冲会占用过多的缓冲池内存(innodb_buffer_pool),默认最大可以占用到1/2的缓冲池内存。
占用了过大的缓冲池必然会对其他缓冲池操作带来影响
Insert Buffer的优化
MySQL5.5之前的版本中其实都叫做Insert Buffer,之后优化为 Change Buffer 可以看做是 Insert Buffer 的升级版。
插入缓冲( Insert Buffer)这个其实只针对 INSERT 操作做了缓冲,而Change Buffer 对INSERT、DELETE、UPDATE都进行了缓冲,所以可以统称为写缓冲,其可以分为:
Insert Buffer
Delete Buffer
Purgebuffer
总结:
Insert Buffer到底是个什么?
其实Insert Buffer的数据结构就是一棵B+树。
在MySQL 4.1之前的版本中每张表有一棵Insert Buffer B+树
目前版本是全局只有一棵Insert Buffer B+树,负责对所有的表的辅助索引进行Insert Buffer
这棵B+树存放在共享表空间ibdata1中
以下几种情况下 Insert Buffer会写入真正非聚集索引,也就是所说的Merge Insert Buffer
- 当辅助索引页被读取到缓冲池中时
- Insert Buffer Bitmap页追踪到该辅助索引页已无可用空间时
- Master Thread线程中每秒或每10秒会进行一次Merge Insert Buffer的操作
一句话概括下:
Insert Buffer 就是用于提升非聚集索引页的插入性能的,其数据结构类似于数据页的一个B+树,物理存储在共享表空间ibdata1中 。
相关免费学习推荐:mysql视频教程
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!