
Maison >base de données >tutoriel mysql >Comprendre la technologie Checkpoint d'InnoDB
Comprendre la technologie Checkpoint d'InnoDB

- coldplay.xixiavant
- 2020-10-28 17:14:332657parcourir
La colonne
tutoriel mysql amène tout le monde à comprendre la technologie Checkpoint d'InnoDB.

En une phrase, La technologie Checkpoint consiste à vider les pages sales du pool de cache sur le disque à un moment donné
Des problèmes rencontrés ?
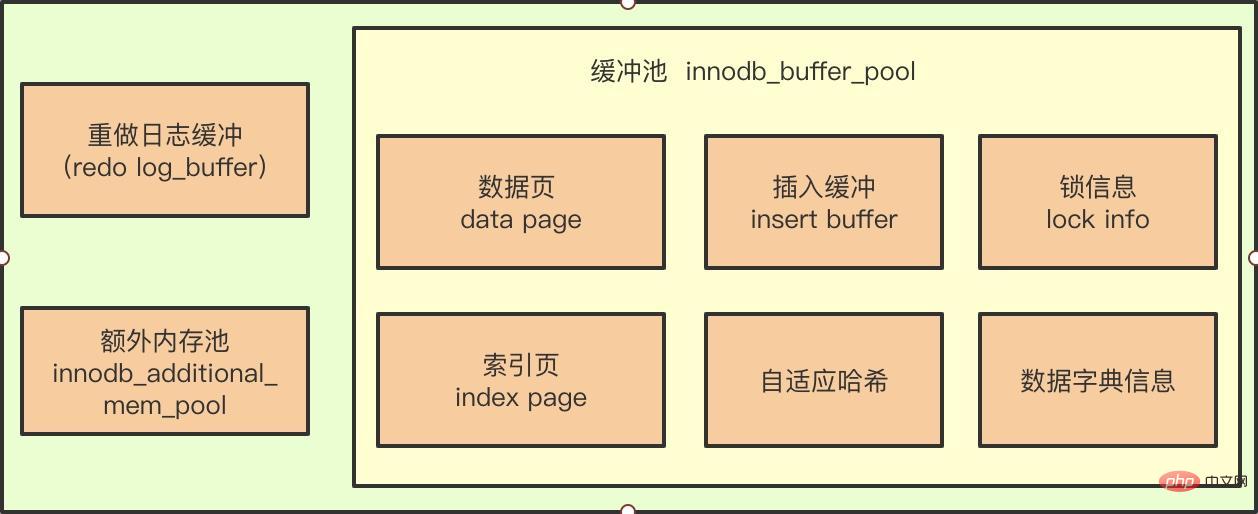
Nous savons tous que l'émergence du pool de mémoire tampon vise à résoudre l'écart entre la vitesse du processeur et celle du disque, de sorte que nous n'ayons pas besoin d'effectuer des opérations d'E/S sur disque lors de la lecture et écrire la base de données. Avec le pool de mémoire tampon, toutes les opérations de page sont d'abord effectuées dans le pool de mémoire tampon.
Par exemple, dans une instruction DML, lors de l'exécution d'une opération de mise à jour ou de suppression de données, l'enregistrement dans la page du pool de mémoire tampon est modifié à ce moment-là, car les données de la page du pool de mémoire tampon sont plus récentes que celles de la page du pool de mémoire tampon. le disque, la page à ce moment est appelée page sale.
Quoi qu'il en soit, les données de la page mémoire après l'assemblée générale doivent être renvoyées sur le disque. Plusieurs problèmes sont impliqués ici :
- Si une page change à chaque fois, la page change. la nouvelle page sera Si la version de la page est vidée sur le disque, alors cette surcharge est très importante
- Si les données chaudes sont concentrées dans certaines pages, les performances de la base de données deviendront très mauvaises
- Si le tampon esclave Un temps d'arrêt s'est produit lorsque le pool a vidé la nouvelle version de la page sur le disque et que les données n'ont pas pu être récupérées
Write Ahead Log (journal d'écriture anticipée)
La politique WAL a résolu le problème de rafraîchissement. Il s'agit d'une série de technologies utilisées dans les systèmes de bases de données relationnelles pour fournir l'atomicité et la durabilité (deux des propriétés ACID).
Le point central de la stratégie WAL est
redo log Chaque fois qu'une transaction est soumise, redo log (redo log) est d'abord écrit, puis la page de données du pool de tampons est modifiée, afin que lorsqu'une transaction se produit En cas de panne de courant, le système peut continuer à fonctionner après le redémarrage
Principe du mécanisme de politique WAL
InnoDB maintient un journal redo pour garantir que les données ne sont pas perdues . Avant que la page de données du pool de mémoire tampon ne soit modifiée, le contenu modifié doit être enregistré dans le journal redo et le journal redo doit être vidé sur le disque avant la page de données correspondante. Il s'agit de la stratégie WAL.
Lorsqu'une panne se produit et que les données de la mémoire sont perdues, InnoDB restaurera les pages de données du pool de tampons à l'état d'avant le crash en rejouant le journal redo lors du redémarrage.
Checkpoint
Il va de soi qu'avec la stratégie WAL, nous pouvons nous asseoir et nous détendre. Mais le problème apparaît à nouveau dans le redo log :
- Le redo log ne peut pas être infini, et nous ne pouvons pas stocker indéfiniment nos données en attendant d'être actualisées sur le disque ensemble
- Lorsque la base de données est inactif et restauré, si le journal de rétablissement est trop volumineux, le coût de récupération sera également très élevé
Donc, afin de résoudre les performances de rafraîchissement des pages sales, quand et dans quelles circonstances devrait être sale les pages doivent-elles être actualisées ? L'actualisation utilise la technologie Checkpoint.
Objectif de Checkpoint
1. Raccourcir le temps de récupération de la base de données
Lorsque la base de données est inactive et restaurée, il n'est pas nécessaire de refaire toutes les informations du journal. Parce que la page de données avant Checkpoint a été renvoyée sur le disque. Restaurez simplement le journal redo après le point de contrôle.
2. Lorsque le pool de tampons n'est pas suffisant, videz les pages sales sur le disque.
Lorsque l'espace du pool de tampons est insuffisant, la page la moins récemment utilisée débordera en fonction de l'algorithme LRU. Si cette page est une page sale, vous devez donc forcer un point de contrôle à vider la page sale, c'est-à-dire la nouvelle version de la page, sur le disque.
3. Lorsque le journal de rétablissement n'est pas disponible, actualisez les pages sales
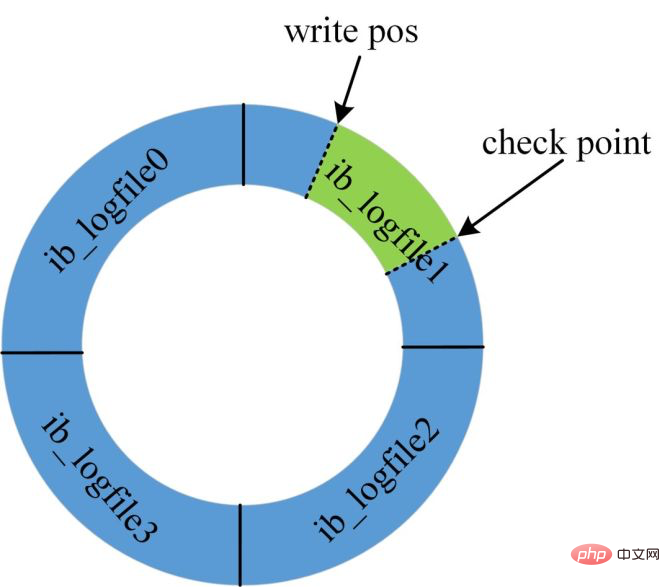
Comme le montre la figure, le journal de rétablissement est indisponible car la base de données actuelle n'est pas disponible pour cela. Les designs sont tous recyclés, donc l'espace n'est pas infini.
Lorsque le journal redo est plein, parce que le système ne peut pas accepter les mises à jour pour le moment, toutes les instructions de mise à jour seront bloquées.
À ce stade, un point de contrôle doit être forcé pour être généré. La position d'écriture doit être poussée vers l'avant et les pages sales dans la plage de poussée doivent être vidées sur le disque.
Type de point de contrôle
Heure à laquelle le point de contrôle se produit, les conditions et la sélection des pages sales sont très complexes.
Combien de pages sales Checkpoint vide-t-il sur le disque à chaque fois ?
D'où Checkpoint obtient-il des pages sales à chaque fois ?
Quand le point de contrôle est-il déclenché ?
Face aux problèmes ci-dessus, le moteur de stockage InnoDB nous fournit deux points de contrôle en interne :
-
Sharp Checkpoint
Lorsque la base de données est arrêtée, toutes les pages sales sont renvoyées sur le disque. Il s'agit de la méthode de travail par défaut. Le paramètre innodb_fast_shutdown=1
-
Fuzzy Checkpoint
À l'intérieur du. Moteur de stockage InnoDB En utilisant ce mode, videz uniquement une partie des pages sales au lieu de vider toutes les pages sales sur le disque
Que se passe-t-il avec FuzzyCheckpoint
-
Master Thread Checkpoint
vide une certaine proportion de pages sur le disque à partir de la liste des pages sales dans le pool de mémoire tampon presque toutes les secondes ou toutes les dix secondes.
Ce processus est asynchrone, c'est-à-dire que le moteur de stockage InnoDB peut effectuer d'autres opérations à ce moment-là, et le fil de requête de l'utilisateur ne sera pas bloqué
-
FLUSH_LRU_LIST Checkpoint
Parce que la liste LRU doit garantir qu'un certain nombre de pages libres peuvent être utilisées, s'il n'y en a pas assez, des pages seront supprimées de la queue. Si les pages supprimées ont des pages sales, ce Checkpoint sera effectué.
Après la version 5.6, ce point de contrôle est placé dans un fil de discussion Page Cleaner séparé, et les utilisateurs peuvent contrôler le nombre de pages disponibles dans la liste LRU via le paramètre innodb_lru_scan_degree. La valeur par défaut est 1024
. -
Async/Sync Flush Checkpoint
fait référence à la situation dans laquelle le fichier de journalisation n'est pas disponible à ce stade, certaines pages doivent être forcées à être renvoyées sur le disque et les pages sales. les pages sont supprimées de la liste des pages sales. La
version 5.6 sélectionnée ne bloquera pas les requêtes des utilisateurs
-
Page sale trop Checkpoint. Autrement dit, le nombre de pages sales est trop important, ce qui oblige le moteur de stockage InnoDB à forcer un point de contrôle.
L'objectif général est de garantir qu'il y a suffisamment de pages disponibles dans le pool tampon.
Il peut être contrôlé par le paramètre innodb_max_dirty_pages_pct. Par exemple, la valeur est de 75, ce qui signifie que lorsque les pages sales dans le pool de tampons occupent 75%, CheckPoint est forcé d'être exécuté
Résumé
En raison de l'écart entre le processeur et le disque, les pages de données du pool de mémoire tampon semblent accélérer les opérations DML de la base de données
Parce que les pages de données du pool de tampons sont cohérentes avec les données du disque. La stratégie WAL (le noyau est le redo log)
En raison du problème de performances de rafraîchissement des pages sales dans le pool de tampons, technologie Checkpoint
InnoDB Afin d'améliorer l'efficacité d'exécution, chaque opération DML n'interagit pas avec le disque pour la persistance. Au lieu de cela, écrivez d'abord le journal de rétablissement via le journal Write Ahead pour garantir la persistance des choses.
Pour les pages sales du pool de mémoire tampon modifiées lors des transactions, le disque sera vidé de manière asynchrone et la disponibilité des pages libres de mémoire et des journaux de rétablissement est garantie grâce à la technologie Checkpoint.
Plus de recommandations d'apprentissage gratuites connexes : tutoriel MySQL(vidéo)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!