
Maison >développement back-end >Tutoriel Python >Résumer plusieurs méthodes d'exploitation de PDF avec Python
Résumer plusieurs méthodes d'exploitation de PDF avec Python

- coldplay.xixiavant
- 2020-10-08 17:50:244162parcourir
La colonne
tutoriel Python résume aujourd'hui plusieurs façons d'utiliser Python pour faire fonctionner PDF.

01
Avant-propos
Bonjour à tous, le cas concernant le fonctionnement du PDF avec Python a été rédigé avant Avez-vous déjà fait l'expérience d'une fusion par lots de PDF ? L'intention initiale de ce cas est simplement de vous fournir un script pratique, sans beaucoup d'explications sur les principes. Il s'agit d'un module très pratique pour le traitement de PDF PyPDF2. Cet article analysera attentivement ce module, impliquant principalement l'application complète du module
- os
- glob. application
- PyPDF2Fonctionnement du module
Fonctionnement de base
Code du module d'importation PyPDF2 est souvent :from PyPDF2 import PdfFileReader, PdfFileWriter复制代码Deux méthodes sont importées ici :
- PdfFileReader peut être compris comme lecteur
- PdfFileWriter peut être compris Pour l'écrivain
03
FusionnerLa première page consiste à
fusionner 5 pdf de facture en 10 pages. Comment le lecteur et l’écrivain devraient-ils coopérer ici ? La logique est la suivante :
Le lecteur lit tous les PDF une fois- Le lecteur remet le contenu lu à l'écrivain
- Le l'écrivain produit uniformément un nouveau pdf
- Il y a ici un autre point de connaissance important : le lecteur ne peut transmettre le contenu lu à l'écrivain que page par page.
Par conséquent, les étapes 1 et 2 de la logique ne sont en fait
pas des étapes indépendantes, mais une fois que le lecteur a lu un pdf, il parcourt toutes les pages du pdf. Une fois, page par page est remis à l'écrivain. Enfin, attendez que tous les travaux de lecture soient terminés avant de sortir. Regarder le code peut rendre l'idée plus claire :
from PyPDF2 import PdfFileReader, PdfFileWriter
path = r'C:\Users\xxxxxx'
pdf_writer = PdfFileWriter()
for i in range(1, 6):
pdf_reader = PdfFileReader(path + '/INV{}.pdf'.format(i))
for page in range(pdf_reader.getNumPages()):
pdf_writer.addPage(pdf_reader.getPage(page))
with open(path + r'\合并PDF\merge.pdf', 'wb') as out:
pdf_writer.write(out)复制代码Puisque tout le contenu doit être remis au même écrivain et finalement sorti ensemble, l'initialisation de l'écrivain doit être dans le corps de boucle Externe.
Si à l'intérieur du corps de boucle, il deviendra
Chaque fois qu'un pdf est accédé, un nouveau rédacteurest généré, de sorte que chaque lecteur soit remis au rédacteur Le contenu sera écrasé à plusieurs reprises par , et nos besoins de fusion ne peuvent pas être réalisés Le code au début du corps de la boucle :
for i in range(1, 6):
pdf_reader = PdfFileReader(path + '/INV{}.pdf'.format(i))复制代码Le but est de lire un nouveau ! un à chaque boucle. Le fichier pdf est remis au lecteur pour les opérations ultérieures. En fait, cette façon d'écrire n'est pas très recommandée. Comme la dénomination de chaque PDF s'avère être très régulière, vous pouvez directement préciser les numéros de bouclage. Une meilleure façon est d'utiliser le module
glob : import glob
for file in glob.glob(path + '/*.pdf'):
pdf_reader = PdfFileReader(path)复制代码 Dans le code,
peut obtenir le nombre de pages dans le lecteur, combiné avec la plage parcourra toutes les pages du lecteur.
pdf_writer.addPage(pdf_reader.getPage(page))peut transmettre la page actuelle à l'écrivain. Enfin, utilisez
withpour créer un nouveau pdf et sortez-le via la méthode pdf_writer.write(out) de l'écrivain. 04
SplitSi vous comprenez la coopération des lecteurs et des écrivains dans l'opération de fusion, alors la scission est facile à comprendre. D'accord, ici nous Prenons comme exemple la division de
INV1.pdfen 2 documents PDF distincts. Examinons également d'abord la logique :
Le lecteur lit le PDF Le document- est remis. page par page par le lecteur vers l'écrivain
- L'écrivain sort immédiatement chaque page qu'il obtient
- Grâce à cette logique de code, nous pouvons également comprendre que les positions d'initialisation et de sortie de le rédacteur doit être dans le corps de la boucle de chaque page de la boucle de lecture PDF, pas en dehors de la boucle
Le code est très simple :
from PyPDF2 import PdfFileReader, PdfFileWriter
path = r'C:\Users\xxx'
pdf_reader = PdfFileReader(path + '\INV1.pdf')
for page in range(pdf_reader.getNumPages()):
# 遍历到每一页挨个生成写入器
pdf_writer = PdfFileWriter()
pdf_writer.addPage(pdf_reader.getPage(page))
# 写入器被添加一页后立即输出产生pdf
with open(path + '\INV1-{}.pdf'.format(page + 1), 'wb') as out:
pdf_writer.write(out)复制代码05
FiligraneCette fois, le travail consiste à ajouter l'image suivante en filigrane à
INV1.pdf
 Le premier L'étape est la préparation.
Le premier L'étape est la préparation. . Ensuite, vous pouvez coder. Vous devez utiliser le module copie supplémentaire. L'explication spécifique est présentée dans la figure ci-dessous :
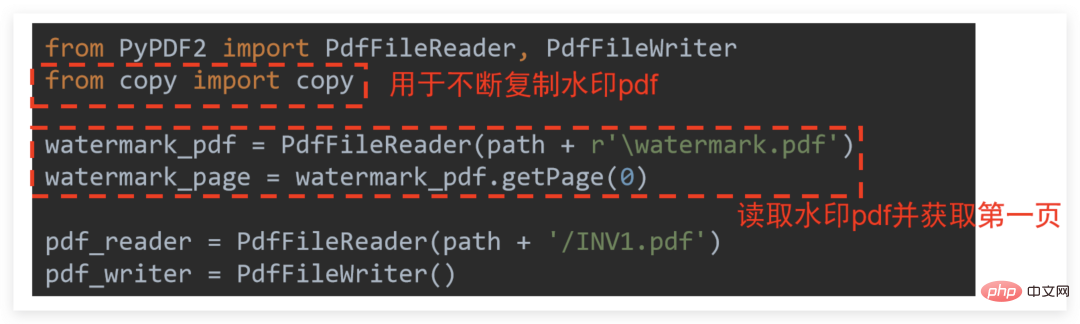 consiste à combiner le lecteur. et écrivain Initialisez et lisez d'abord la page PDF filigranée pour une utilisation ultérieure. Le code de base est un peu difficile à comprendre :
consiste à combiner le lecteur. et écrivain Initialisez et lisez d'abord la page PDF filigranée pour une utilisation ultérieure. Le code de base est un peu difficile à comprendre : 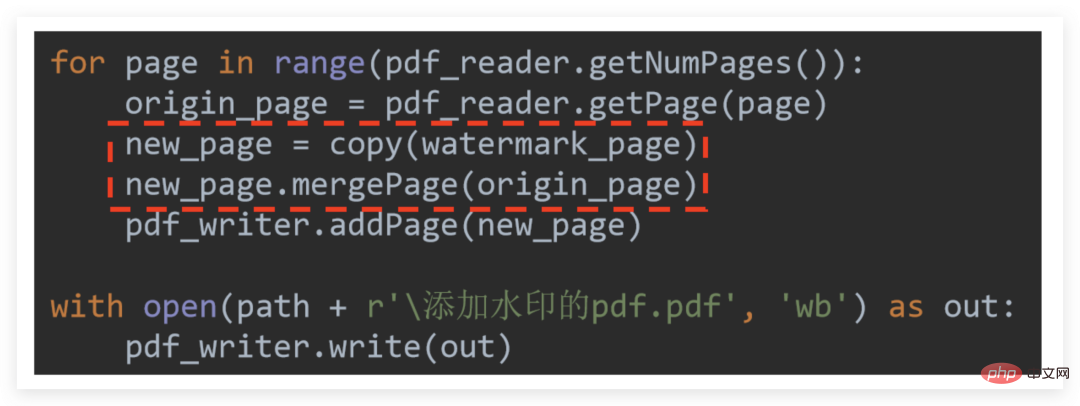
Le filigrane consiste essentiellement à fusionner la page PDF filigranée avec chaque page qui doit être filigranée
Parce que le PDF doit être filigrané, il peut y avoir plusieurs pages, mais le PDF filigrané n'a qu'une seule page, donc si les PDF filigranés sont fusionnés directement, cela peut être compris abstraitement comme qu'après l'ajout de la première page, la page PDF filigranée disparaîtra .
Par conséquent ne peut pas être fusionné directement , mais la page PDF filigranée doit être copier continuellement dans une nouvelle page pour une utilisation ultérieure nouvelle_page puis utilisée La méthode .mergePage termine la fusion avec chaque page et remet la page fusionnée au rédacteur pour une sortie finale unifiée !
À propos de l'utilisation de .mergePage :La page qui apparaît en dessous.mergePage (la page qui apparaît au dessus), l'effet final est le suivant :
06
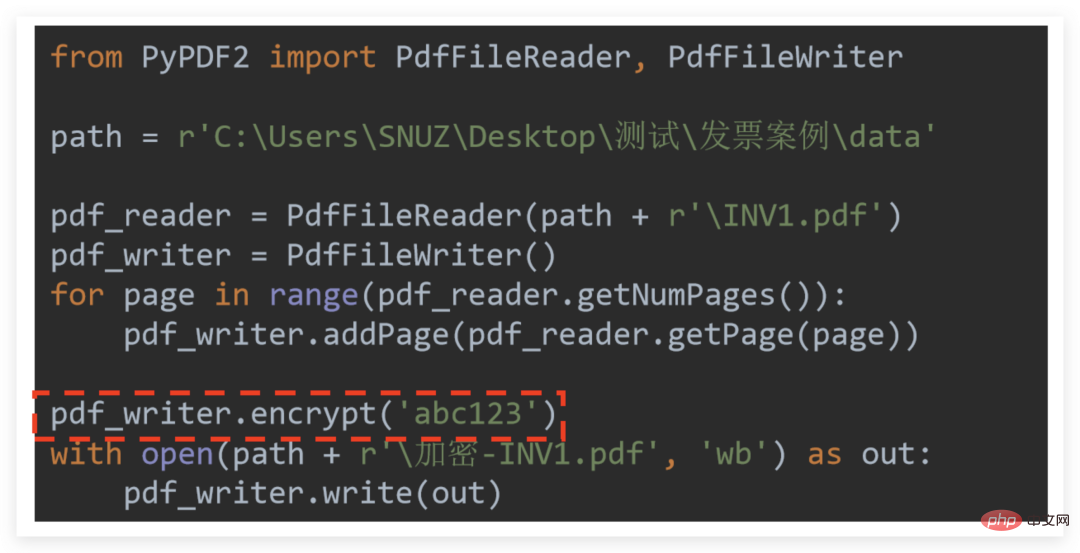
Cryptage
Le cryptage est très simple, n'oubliez pas : "Le cryptage est destiné au cryptage de l'écrivain"
Il vous suffit donc d'appeler pdf_writer.encrypt (mot de passe) après l'opération concernée est terminé
Prenons comme exemple le cryptage d'un seul PDF :
écrit à la fin
Bien sûr, à l'exception du PDF Pour la fusion, le fractionnement, le cryptage et le filigrane, nous pouvons également utiliser Python combiné avec Excel et Word pour répondre à davantage de besoins d'automatisation Ceux-ci sont laissés aux lecteurs à développer. eux-mêmes. Partage de ressources Python Junyang 1075110200, qui contient des packages d'installation, des PDF et des vidéos d'apprentissage. Il s'agit d'un lieu de rassemblement pour les apprenants Python, les bases zéro et les avancés sont les bienvenus
Enfin, j'espère que tout le monde pourra comprendre la bureautique Python. . Un noyau est le fonctionnement par lots - libérez vos mains, automatisez les travaux complexes !
Autres recommandations d'apprentissage gratuites associées : tutoriel Python (vidéo)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!