
Maison >développement back-end >Tutoriel Python >Conseils Pandas pour obtenir efficacement des données grâce à l'indexation dans DataFrame
Conseils Pandas pour obtenir efficacement des données grâce à l'indexation dans DataFrame

- coldplay.xixiavant
- 2020-09-16 16:15:142302parcourir

Recommandations d'apprentissage associées : tutoriel Python
Dans l'article précédent, nous avons présenté l'utilisation de certains index couramment utilisés dans les structures de données DataFrame, tels que iloc, loc, les index logiques, etc. Dans l'article d'aujourd'hui, examinons quelques opérations de base de DataFrame.
Alignement des données
Nous pouvons calculer la somme de deux DataFrames, les pandas feront automatiquement les deux DataFrames effectuer l'alignement des données Si les données ne correspondent pas, elles seront définies sur Nan (pas un nombre).
Nous créons d'abord deux DataFrames :
import numpy as npimport pandas as pddf1 = pd.DataFrame(np.arange(9).reshape((3, 3)), columns=list('abc'), index=['1', '2', '3'])df2 = pd.DataFrame(np.arange(12).reshape((4, 3)), columns=list('abd'), index=['2', '3', '4', '5'])复制代码
Les résultats obtenus sont conformes à nos attentes. En fait, il s'agit simplement de créer le DataFrame via le tableau numpy, puis. en spécifiant l'index et les colonnes, cela doit être considéré comme une utilisation très basique.
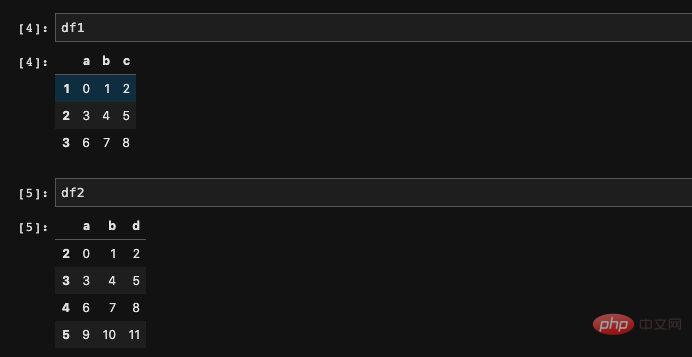
Ensuite, nous ajoutons les deux DataFrames et nous obtiendrons :
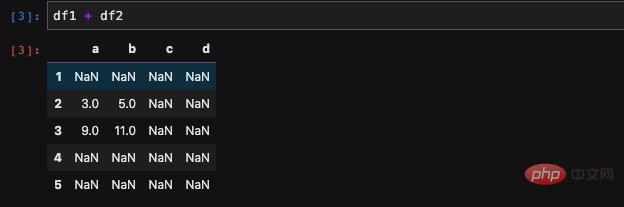
Nous constatons que pandas ajoute les deux DataFrames après en les fusionnant, toute position où n'apparaît pas dans les deux DataFrames sera définie sur Nan. Cela a du sens. En fait, pas seulement l'addition, nous pouvons calculer les quatre opérations arithmétiques d'addition, de soustraction, de multiplication et de division de deux DataFrames. Si vous calculez la division de deux DataFrames, en plus des données qui ne lui correspondent pas seront fixées à Nan, le fait de diviser par zéro provoquera également l'apparition de valeurs aberrantes (qui ne peuvent pas nécessairement être Nan, mais c'est inf).
fill_value
Si nous allons opérer sur deux DataFrames, alors bien sûr nous ne voulons pas de null valeurs à apparaître. À ce stade, nous devons remplir les valeurs nulles. Si nous utilisons directement des opérateurs pour effectuer des opérations, nous ne pouvons pas transmettre de paramètres à remplir. À ce stade, nous devons utiliser la méthode arithmétique qui nous est fournie dans. DataFrame.
Il existe plusieurs opérateurs couramment utilisés dans DataFrame :
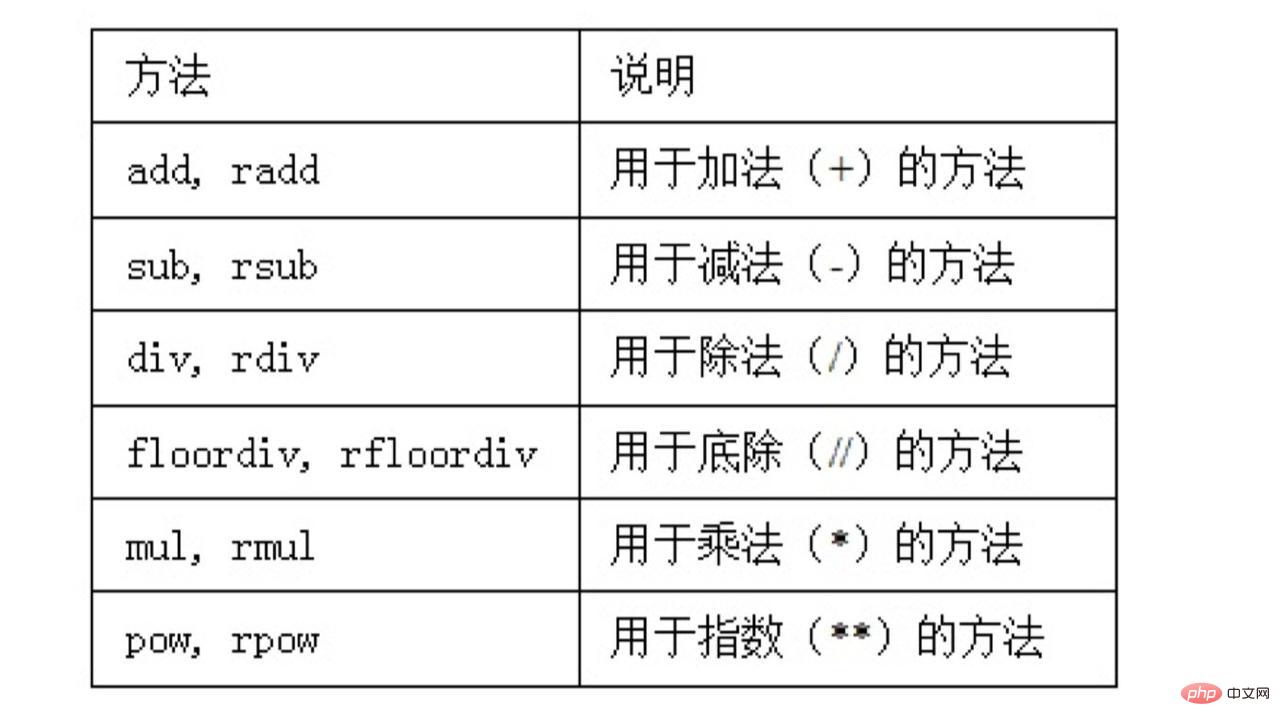
Nous comprenons tous très bien add, sub et p, alors que signifient les méthodes radd et rsub ici Pourquoi y a-t-il un r devant ?
Cela semble déroutant, mais pour parler franchement, radd est utilisé pour inverser les paramètres . Par exemple, si nous voulons obtenir l’inverse de tous les éléments du DataFrame, nous pouvons l’écrire sous la forme 1/df. Puisque 1 lui-même n'est pas un DataFrame, nous ne pouvons pas utiliser 1 pour appeler des méthodes dans le DataFrame, et nous ne pouvons pas transmettre de paramètres. Afin de résoudre cette situation, nous pouvons écrire 1/df sous la forme df.rp(1) pour que nous puissions y passer des paramètres.
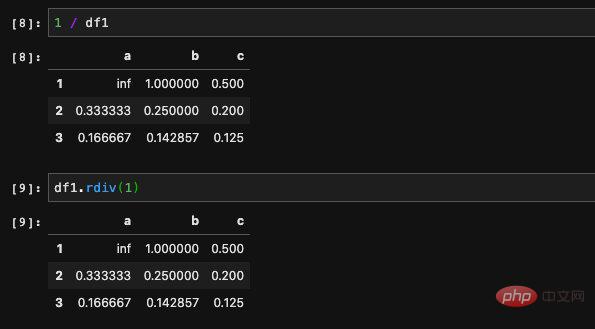
remplir les valeurs manquantes d'un côté avant le calcul. C'est-à-dire que la position manquante dans un seul DataFrame sera remplacée par la valeur que nous spécifions. Si est manquant dans les deux DataFrames, ce sera toujours Nan.
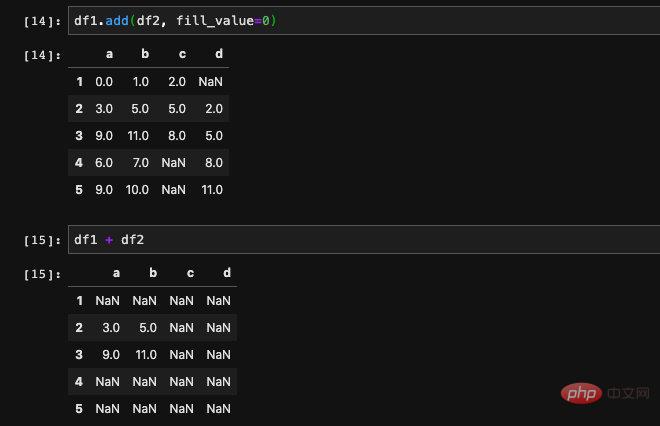
Le paramètre fill_value apparaît dans de nombreuses API, comme la réindexation, etc. L'utilisation est la même. Nous pouvons y prêter attention lors de la vérification de la documentation de l'API.
Alors que faire de ce genre de valeur vide qui apparaît encore après remplissage ? Puis-je rechercher ces emplacements uniquement manuellement et les renseigner ? Bien sûr, c'est irréaliste. Pandas nous fournit également une API qui résout spécifiquement les valeurs nulles.API de valeur nulle
Avant de remplir la valeur nulle, la première chose que nous devons faire est trouvez la valeur nulle . Pour résoudre ce problème, nous avons l'API isna, qui renverra un DataFrame booléen. Chaque position dans le DataFrame indique si la position correspondante du DataFrame d'origine est une valeur nulle. 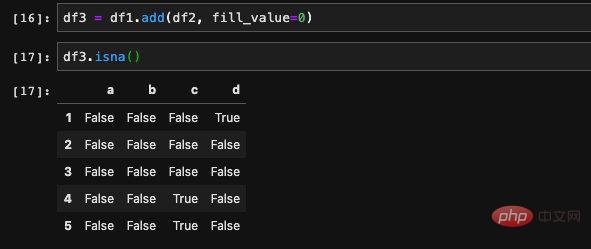
dropna
Bien sûr, il suffit de savoir s'il s'agit d'une valeur nulle pas assez, on espère parfois que les valeurs nulles n'apparaîtront pas. Dans ce cas, on peut choisir de supprimer les valeurs nulles . Pour cette situation, nous pouvons utiliser la méthode dropna dans DataFrame.
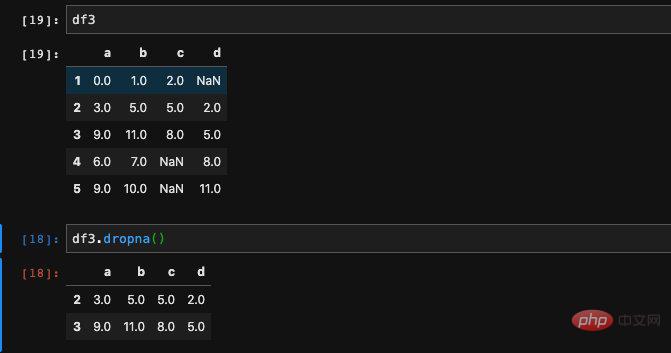
Nous avons constaté qu'après avoir utilisé dropna, les lignes avec des valeurs nulles étaient supprimées. Seules les lignes sans valeurs nulles sont conservées. Parfois, nous souhaitons supprimer les colonnes au lieu des lignes. À ce stade, nous pouvons le contrôler en passant le paramètre axis.
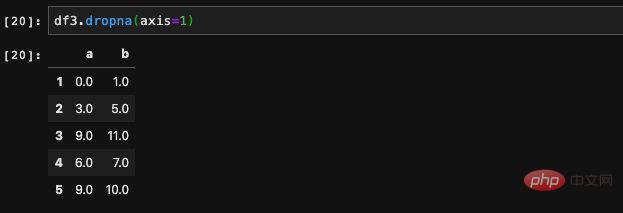
De cette façon, nous obtenons une colonne qui ne contient pas de valeurs nulles. En plus de contrôler les lignes et les colonnes, nous pouvons également contrôler la rigueur. d'exécuter drop . Nous pouvons juger par le paramètre how. How prend en charge la transmission de deux valeurs, l'une est « tout » et l'autre est « tout ». Tout signifie qu'il ne sera supprimé que lorsqu'une certaine ligne ou colonne contient toutes des valeurs nulles, et correspondant à n'importe laquelle, elle sera supprimée tant que des valeurs nulles apparaissent. S'il n'est pas renseigné par défaut, il est considéré comme quelconque. Dans des circonstances normales, nous n'utilisons pas ce paramètre, et il suffit d'avoir une impression.
fillna
En plus de supprimer des données contenant des valeurs nulles, les pandas peuvent également être utilisés Remplir vide valeurs, en fait c'est aussi la méthode la plus couramment utilisée.
Nous pouvons simplement transmettre une valeur spécifique à remplir :
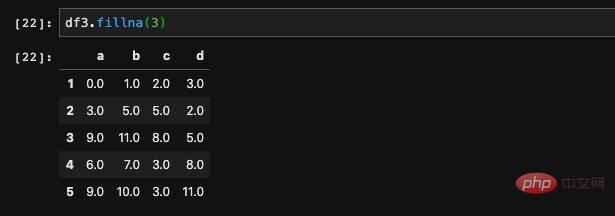
fillna renverra un nouveau DataFrame, toutes les valeurs Nan sera remplacé par les valeurs que nous spécifions. Si nous ne voulons pas qu'il renvoie un nouveau DataFrame, mais modifie directement les données d'origine, nous pouvons utiliser le paramètre inplace pour indiquer qu'il s'agit d'une opération inplace, alors les pandas modifieront le DataFrame d'origine.
df3.fillna(3, inplace=True)复制代码
除了填充具体的值以外,我们也可以和一些计算结合起来算出来应该填充的值。比如说我们可以计算出某一列的均值、最大值、最小值等各种计算来填充。fillna这个函数不仅可以使用在DataFrame上,也可以使用在Series上,所以我们可以针对DataFrame中的某一列或者是某些列进行填充:
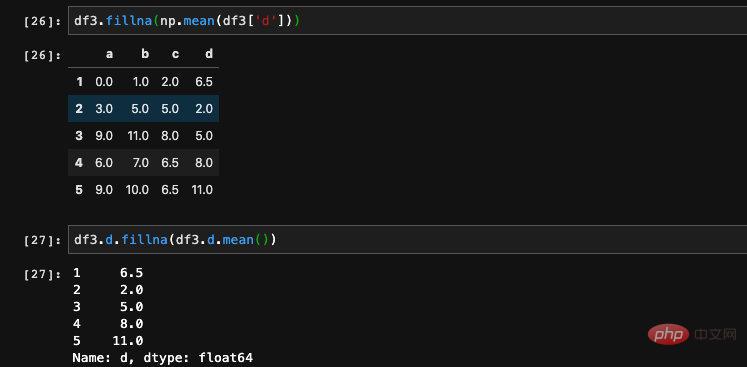
除了可以计算出均值、最大最小值等各种值来进行填充之外,还可以指定使用缺失值的前一行或者是后一行的值来填充。实现这个功能需要用到method这个参数,它有两个接收值,ffill表示用前一行的值来进行填充,bfill表示使用后一行的值填充。
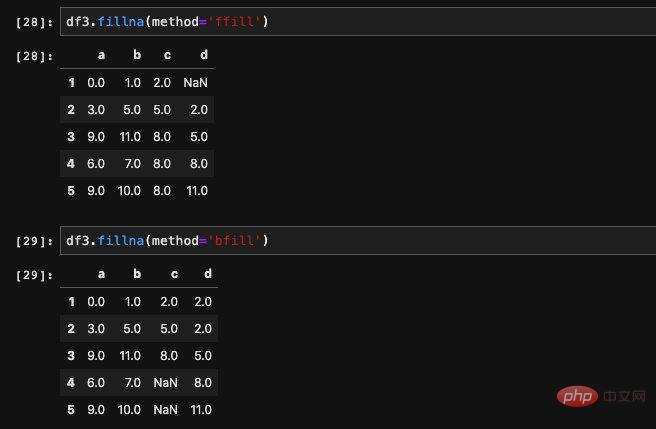
我们可以看到,当我们使用ffill填充的时候,对于第一行的数据来说由于它没有前一行了,所以它的Nan会被保留。同样当我们使用bfill的时候,最后一行也无法填充。
总结
今天的文章当中我们主要介绍了DataFrame的一些基本运算,比如最基础的四则运算。在进行四则运算的时候由于DataFrame之间可能存在行列索引不能对齐的情况,这样计算得到的结果会出现空值,所以我们需要对空值进行处理。我们可以在进行计算的时候通过传入fill_value进行填充,也可以在计算之后对结果进行fillna填充。
在实际的运用当中,我们一般很少会直接对两个DataFrame进行加减运算,但是DataFrame中出现空置是家常便饭的事情。因此对于空值的填充和处理非常重要,可以说是学习中的重点,大家千万注意。
想了解更多编程学习,敬请关注php培训栏目!
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!