
Maison >développement back-end >Tutoriel Python >Série de traitements de données utilisant des pandas
Série de traitements de données utilisant des pandas

- coldplay.xixiavant
- 2020-09-15 16:10:372401parcourir

Recommandations d'apprentissage associées : Tutoriel Python
En python, nous commençons aujourd'hui à introduire un nouveau A La bibliothèque d'outils informatiques couramment utilisée est la célèbre Pandas.
Le nom complet de Pandas est Python Data Analysis Library, qui est un outil de calcul scientifique basé sur Numpy. Sa plus grande caractéristique est qu'il peut exploiter des données structurées tout comme les tables d'exploitation dans une base de données, il prend donc en charge de nombreuses opérations complexes et avancées et peut être considéré comme une version améliorée de Numpy. Il peut facilement créer des données complètes à partir d'un tableau CSV ou Excel et prend en charge de nombreuses interfaces de calcul de données par lots au niveau des tables.
Installation à l'aide de
Comme presque tous les packages Python, les pandas peuvent également être installés via pip. Si vous avez installé la suite Anaconda, des bibliothèques telles que numpy et pandas ont été automatiquement installées. Si vous ne les avez pas installées, cela n'a pas d'importance Nous pouvons terminer l'installation avec une seule ligne de commandes.
pip install pandas复制代码
Comme Numpy, nous lui donnons généralement un alias lorsque nous utilisons des pandas. L'alias des pandas est pd. Par conséquent, la convention d'utilisation des pandas est :
import pandas as pd复制代码
Si vous exécutez cette ligne sans erreur, cela signifie que vos pandas ont été installés. Il existe deux autres packages généralement utilisés avec les pandas. L'un d'eux est également un package de calcul scientifique appelé Scipy, et l'autre est un package d'outils de visualisation de données, appelé Matplotlib. Nous pouvons également utiliser pip pour installer ces deux packages ensemble. Dans les articles suivants, lorsque ces deux packages seront utilisés, leur utilisation sera brièvement présentée.
pip install scipy matplotlib复制代码
Indice des séries
Il existe deux structures de données les plus couramment utilisées dans les pandas, l'une est la série et l'autre L'un est un DataFrame. Parmi eux, la série est une structure de données unidimensionnelle , qui peut être simplement comprise comme un tableau unidimensionnel ou un vecteur unidimensionnel. DataFrame est naturellement une structure de données bidimensionnelle, qui peut être comprise comme un tableau ou un tableau bidimensionnel.
Jetons d'abord un coup d'œil à Series. Il existe deux principaux types de données stockées dans Series. L'un est un tableau composé d'un ensemble de données et l'autre est l'index ou l'étiquette de cet ensemble de données. Nous créons simplement une série et l’imprimons pour comprendre.
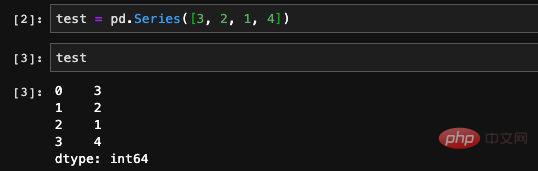
Ici, nous avons créé au hasard une série contenant quatre éléments, puis nous l'avons imprimée. Vous pouvez voir qu'il y a deux colonnes dans les données imprimées. La deuxième colonne est les données que nous avons saisies lorsque nous venons de les créer La première colonne est son index . Comme nous n'avons pas spécifié d'index lors de sa création, les pandas créeront automatiquement un index de numéro de ligne pour nous. Nous pouvons afficher les données et les index stockés dans la série via les valeurs et les attributs d'index dans le type Series :
.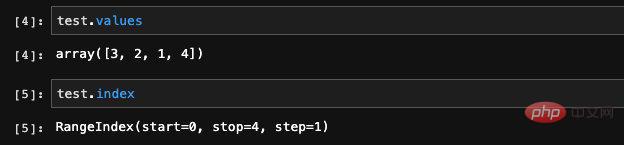
La valeurs de sortie ici est un tableau Numpy Ce n'est pas surprenant, car comme nous l'avons dit plus tôt, pandas est une bibliothèque de calcul scientifique développée sur la base de Numpy. . Numpy est sa couche sous-jacente. À partir des informations d'index imprimées, nous pouvons voir qu'il s'agit d'un index de type Range, sa plage et la taille de son pas.
Index est un paramètre par défaut dans la fonction de construction de séries. Si nous ne le remplissons pas, il générera pour nous un index de plage par défaut, qui est en fait le numéro de ligne de données. . Nous pouvons également spécifier nous-mêmes l'index des données. Par exemple, si nous ajoutons le paramètre index au code tout à l'heure, nous pouvons spécifier l'index nous-mêmes.

Quand on précise l'index du type de caractère, le résultat renvoyé par index n'est plus RangeIndex mais Index. Notez que pandas fait la distinction en interne entre les index numériques et les index de caractères.
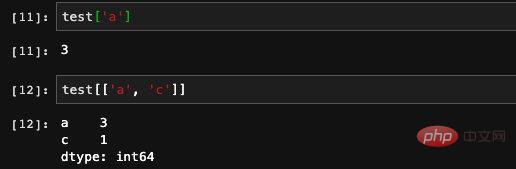
Avec l'index, on l'utilise naturellement pour retrouver des éléments. Nous pouvons utiliser directement l'index comme indice du tableau , et l'effet des deux est le même. De plus, les tableaux d'index sont également acceptables et nous pouvons directement interroger les valeurs de plusieurs index.
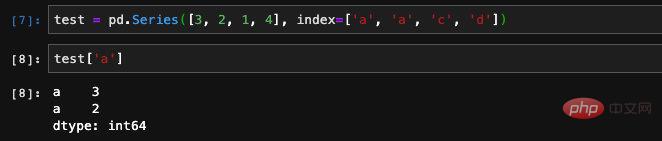
De plus, lors de la création d'une série, les index en double sont également autorisés. De même, lorsque nous utilisons des requêtes d’index, nous obtiendrons également plusieurs résultats.
Non seulement cela, les index booléens comme Numpy sont toujours pris en charge :

Calculs de séries
Les séries prennent en charge de nombreux types de calculs, nous pouvons directement utiliser les opérations d'addition, de soustraction, de multiplication et de division Effectuer opérations sur l'ensemble de la Série :
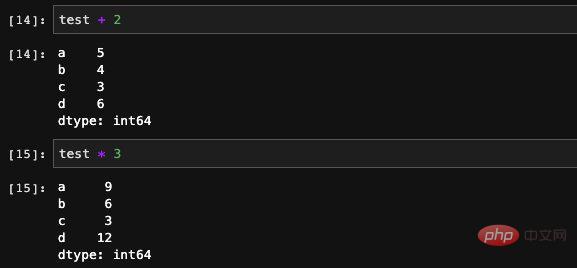
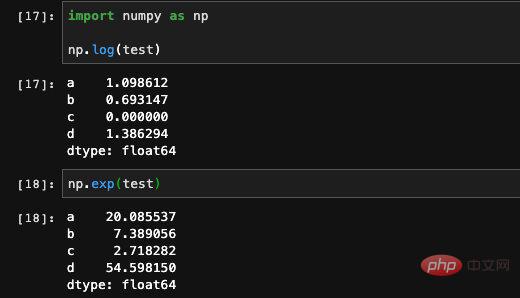
Vous pouvez également utiliser la fonction d'opération dans Numpy pour effectuer certaines opérations mathématiques complexes, mais le résultat de ce calcul sera un tableau Numpy.
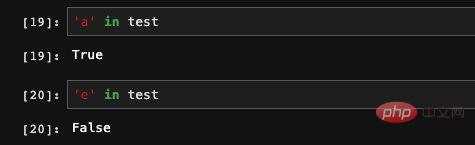
Comme il existe un index dans la série, nous pouvons également utiliser la méthode dict pour déterminer si l'index est dans la série :
La série a des index et des valeurs. En fait, la structure de stockage est la même que celle d'un dict, donc Seires prend également en charge l'initialisation via un dict :
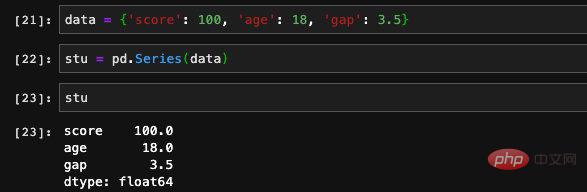
spécifier l'index lors de la création, afin de pouvoir contrôler son ordre.
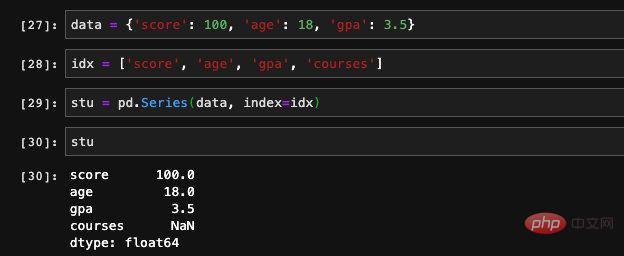
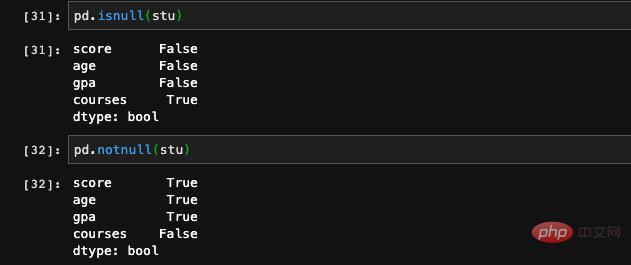
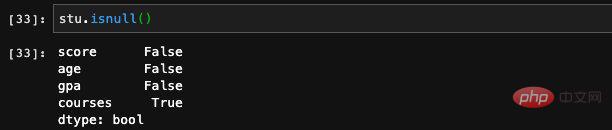
valeur illégale ou valeur nulle Lorsque nous traitons des fonctionnalités ou des données d'entraînement, nous rencontrons souvent des situations où une certaine caractéristique des données avec certaines entrées est vide. Nous pouvons utiliser des pandas isnull et notnull. les fonctions vérifient les postes vacants.
index en Série peut également être modifié , on peut lui attribuer directement une nouvelle valeur : 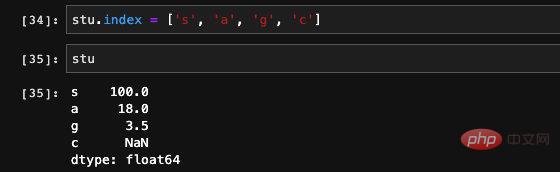
Résumé
À la base, la série sur les pandas est Une couche d'encapsulation sur un tableau unidimensionnel Numpy , en ajoutant quelques fonctions associées telles que l'indexation. Nous pouvons donc imaginer que DataFrame est en fait une encapsulation d'un tableau Series, avec davantage de fonctions liées au traitement des données ajoutées. Une fois que l’on a saisi la structure de base, il est bien plus utile de comprendre toute la fonction des pandas que de mémoriser ces API une à une.
pandas est un outil puissant pour le traitement de données Python En tant qu'ingénieur en algorithmes qualifié, il est presque nécessaire de savoir que c'est aussi la base pour nous d'utiliser Python pour l'apprentissage automatique et le deep. apprentissage. Selon les données d'une enquête, 70 % du travail quotidien des ingénieurs en algorithmes est investi dans le traitement des données, et moins de 30 % est réellement utilisé pour implémenter et entraîner des modèles. On voit donc l’importance du traitement des données. Si l’on veut évoluer dans l’industrie, il ne suffit pas d’apprendre le modèle. Cet article utilise mdnice pour la composition
Formation php
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!