
Maison >base de données >Redis >À propos de l'implémentation de Java par liste de classement basée sur la collection ordonnée Redis
À propos de l'implémentation de Java par liste de classement basée sur la collection ordonnée Redis

- 藏色散人avant
- 2020-09-11 13:22:502171parcourir
La colonne suivante vous présentera la liste de classement des implémentations de collection ordonnée Redis basée sur Java. J'espère qu'elle vous sera utile. aux amis dans le besoin !
Avant-propos Élément presque indispensable dans les applications Internet, les classements peuvent susciter le désir de comparaison des êtres humains. Les produits d'un certain trésor sont nombreux. des moyens de mettre en œuvre des classements tels que les classements des ventes, les classements de réputation des magasins, etc. Vous pouvez utiliser l'algorithme de tri rapide + implémenter l'interface Comparator pour trier selon un certain poids. Désormais, de nombreuses entreprises utilisent Redis, une base de données NoSQL, pour implémenter la fonction de classement.
Élément presque indispensable dans les applications Internet, les classements peuvent susciter le désir de comparaison des êtres humains. Les produits d'un certain trésor sont nombreux. des moyens de mettre en œuvre des classements tels que les classements des ventes, les classements de réputation des magasins, etc. Vous pouvez utiliser l'algorithme de tri rapide + implémenter l'interface Comparator pour trier selon un certain poids. Désormais, de nombreuses entreprises utilisent Redis, une base de données NoSQL, pour implémenter la fonction de classement.
Mise en œuvre de classements basés sur Redis
Ce que nous devons faire maintenant, c'est classer les entreprises. Le critère de classement est le nombre de fois que les utilisateurs recherchent l'entreprise et établissent un classement des dix premières. entreprises
1. Connaissances redis pertinentes
La structure de données redis liée à la mise en œuvre de la fonction de classement est un ensemble de tri (ensemble ordonné)
À propos de l'ensemble de tri
Nous savons que l'ensemble est une sorte d'ensemble. L'une des caractéristiques d'un ensemble est qu'il n'a pas d'éléments en double, un ensemble de tri a également une autre caractéristique qui est l'ordre.
Composition de la structure des données :
Clé : l'identifiant unique de l'ensemble de tri Poids : également appelé score (score) redis trie les éléments de l'ensemble en ordre croissant par poids Tri (par défaut), les poids peuvent être répétés- valeur : définir les éléments, les éléments ne peuvent pas être répétés
String(set key),double(权重),String(value)
l'ensemble de tri est implémenté via une table de hachage, donc en ajoutant, fonction et temps de recherche La complexité est O(1), et chaque collection peut stocker plus de 4 milliards d'éléments- Commandes de base
ZADD "KEY" SCORE "VALUE" [ SCORE "VALUE"]
Effet :MyRedis:0>ZADD test 1 "one""1"MyRedis:0>zadd test 4 "four" 5 "five""2"
ZCARD "key"
EffetMyRedis:0>ZCARD test"5"
ZSCORE "KEY" "VALUE"
EffetMyRedis:0>ZSCORE "test" "one""2"
ZINCRBY "key" score "value"
Effet : MyRedis:0>ZSCORE "test" "one""2"MyRedis:0>ZINCRBY "test" 1 "one""3"MyRedis:0>ZSCORE "test" "one" "3"
ZRANGE "key" 开始下标 结束下标
EffetMyRedis:0>ZRANGE "test" 0 1
1) "two"
2) "one"
Il faut environ tellement de nombreuses commandes pour remplir cette exigence, commençons à implémenter la nôtre Exigences
2 implémentation springboot + redis
Importer la dépendance redis
<dependency> <groupid>org.springframework.boot</groupid> <artifactid>spring-boot-starter-data-redis</artifactid> </dependency>
Classe d'outils d'écriture
//=============================== sort set =================================
/**
* 添加指定元素到有序集合中
* @param key
* @param score
* @param value
* @return
*/
public boolean sortSetAdd(String key,double score,String value){
try{
return redisTemplate.opsForZSet().add(key,value,score);
}catch (Exception e){
e.printStackTrace();
return false;
}
}
/**
* 有序集合中对指定成员的分数加上增量 increment
* @param key
* @param value
* @param i
* @return
*/
public double sortSetZincrby(String key,String value,double i){
try {
//返回新增元素后的分数
return redisTemplate.opsForZSet().incrementScore(key, value, i);
}catch(Exception e){
e.printStackTrace();
return -1;
}
}
/**
* 获得有序集合指定范围元素 (从大到小)
* @param key
* @param start
* @param end
* @return
*/
public Set sortSetRange(String key,int start,int end){
try {
return redisTemplate.opsForZSet().reverseRange(key, start, end);
}catch (Exception e){
e.printStackTrace();
return null;
}
}
Implémentation commerciale :
Étant donné que le classement a des exigences élevées en temps réel, je pense personnellement qu'il n'est pas nécessaire de le conserver dans la base de données /**
* 根据公司名找到指定公司
* @param companyName
* @return
*/
@Override
public AjaxResult selectCompanyName(String companyName) {
Set<object> set = redisUtils.sGet("company");
for(Object i : set){
String json = JSONObject.toJSONString(i);
JSONObject jsonObject = JSONObject.parseObject(json);
if(jsonObject.getString("companyName").equals(companyName)){
//搜索次数 + 1
redisUtils.sortSetZincrby("companyRank",companyName,1);
log.info("直接缓存中返回");
return new AjaxResult().ok(jsonObject);
}
}
log.error("缓存中没有,查数据库");
TbCommpanyExample tbCommpanyExample = new TbCommpanyExample();
tbCommpanyExample.createCriteria().andCompanyNameEqualTo(companyName);
List<tbcommpany> list = tbCommpanyMapper.selectByExample(tbCommpanyExample);
if(list.size() != 0){
//放入缓存中
redisUtils.sSet("company",list.get(0));
//数据库中存在
//搜索次数 + 1
redisUtils.sortSetZincrby("companyRank",companyName,1);
log.info("sql");
return new AjaxResult().ok(list.get(0));
}else{
return new AjaxResult().error("没有找到该公司:"+companyName);
}
}</tbcommpany></object>
 Obtenez le classement
Obtenez le classement /**
* 获得公司排行榜(前十)
* @return
*/
@Override
public AjaxResult getCompanyRank() {
Set set = redisUtils.sortSetRange("companyRank",0,9);
if(set.size() == 0){
return new AjaxResult().error("公司排行榜为空");
}
return new AjaxResult().ok(set);
}
3. Test et résumé
test du facteur :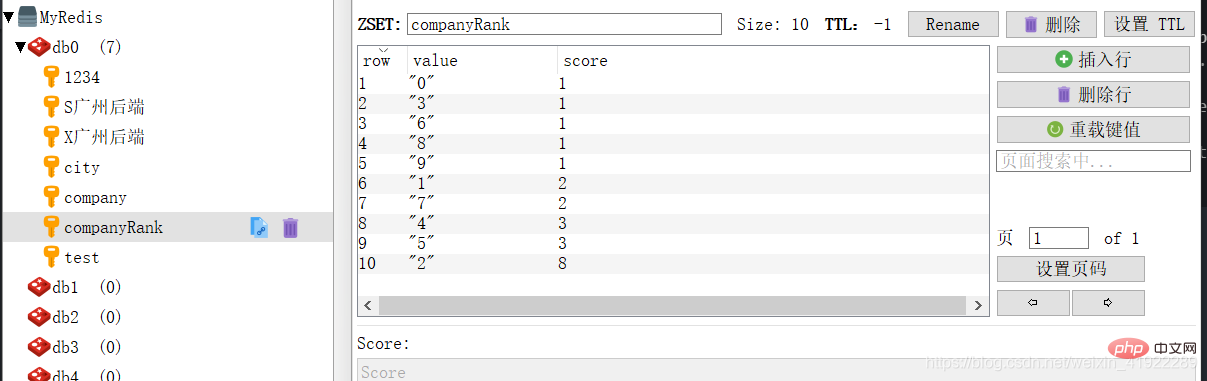
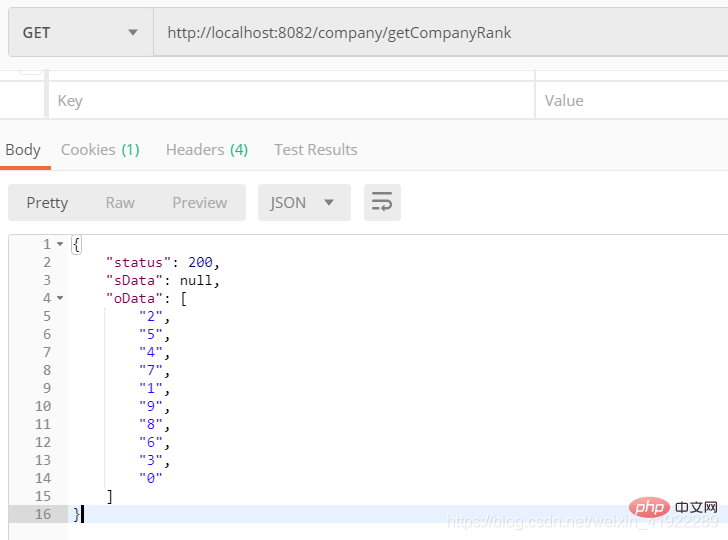 Si je veux A Celui qui est arrivé le premier est classé devant B qui a le même score mais est arrivé plus tard Comment résoudre ce problème ?
Si je veux A Celui qui est arrivé le premier est classé devant B qui a le même score mais est arrivé plus tard Comment résoudre ce problème ?
Pour résoudre ce problème, on peut envisager d'ajouter un horodatage au score. La formule de calcul est :
带时间戳的分数 = 实际分数*10000000000 + (9999999999 – timestamp)
Cette entreprise avec le temps peut l'écrire elle-même pour réduire au maximum l'erreur.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!