Principe de réplication maître-esclave Redis et problèmes courants
咔咔original
2020-08-28 17:20:512008parcourir
❝
Je crois que de nombreux amis ont configuré la réplication maître-esclave, mais ils n'ont pas une compréhension approfondie du flux de travail et des problèmes courants de la réplication maître-esclave Redis Kaka. ici Il m'a fallu deux jours pour compiler tous les points de connaissances sur la réplication maître-esclave Redis >
❝
Kaka a compilé une feuille de route pour créer un guide d'entretien, et prêt à écrire des articles selon une telle feuille de route. Plus tard, j'ai découvert qu'aucun point de connaissance n'était ajouté. Nous avons également hâte de vous voir dans la zone de commentaires ! > 1. Qu'est-ce que la réplication maître-esclave Redis ?
La réplication maître-esclave signifie qu'il existe désormais deux serveurs Redis et que les données d'un Redis sont synchronisées avec l'autre base de données Redis. Le premier est appelé nœud maître et le second est le nœud esclave. Les données ne peuvent être synchronisées que dans un seul sens, du maître vers l'esclave.
Mais dans le processus réel, il est impossible d'avoir seulement deux serveurs Redis pour la réplication maître-esclave, ce qui signifie que chaque serveur Redis peut être appelé le nœud maître (maître)
Comme indiqué ci-dessous dans le Dans ce cas, notre esclave3 est à la fois le nœud esclave du maître et le nœud maître de l'esclave.
Comprenez d'abord ce concept et continuez à lire ci-dessous pour des explications plus détaillées.
2. Pourquoi la réplication maître-esclave Redis est-elle nécessaire ?
Supposons que nous ayons maintenant un serveur Redis, qui est un état autonome.
Le premier problème qui se posera dans ce cas est l'indisponibilité du serveur, qui entraîne directement une perte de données. Si le projet est lié au RMB, les conséquences peuvent être imaginées.
La deuxième situation est le problème de mémoire. Lorsqu'il n'y a qu'un seul serveur, la mémoire atteindra certainement son maximum. Il est impossible de mettre à niveau un serveur à l'infini. Donc, en réponse aux deux problèmes ci-dessus, nous allons préparer quelques serveurs supplémentaires et configurer la réplication maître-esclave. Stockez les données sur plusieurs serveurs. Et assurez-vous que les données de chaque serveur sont synchronisées. Même si un serveur tombe en panne, cela n'affectera pas l'utilisation des utilisateurs. Redis peut continuer à assurer une haute disponibilité et une sauvegarde redondante des données.
Il devrait y avoir beaucoup de questions en ce moment. Comment connecter le maître et l'esclave ? Comment synchroniser les données ? Et si le serveur maître tombe en panne ? Ne vous inquiétez pas, résolvez vos problèmes petit à petit.
3. Le rôle de la réplication maître-esclave Redis
Ci-dessus, nous avons expliqué pourquoi Redis est utilisé la réplication maître-esclave, alors le rôle de la réplication maître-esclave est d'expliquer pourquoi elle est utilisée.
Continuons à utiliser ce diagramme pour parler de
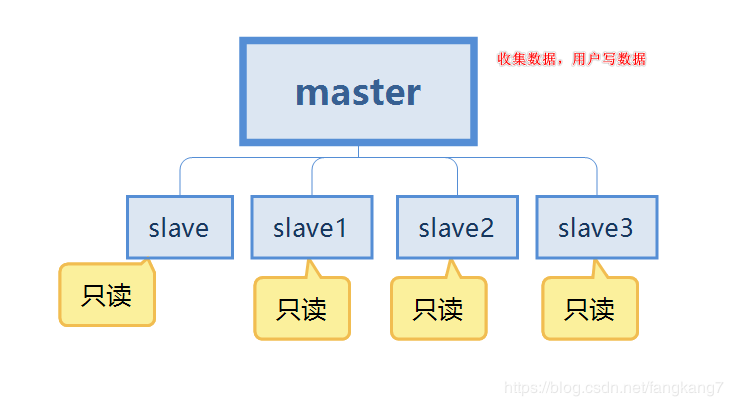
Le premier point est la redondance des données, qui met en œuvre une sauvegarde à chaud des données, en plus de la persistance. chemin.
Le deuxième point concerne la panne d'une seule machine. Lorsqu'il y a un problème avec le nœud maître, le service peut être fourni par le nœud esclave, qui est l'esclave, permettant une récupération rapide après les pannes, ce qui constitue une redondance du service.
Le troisième point est la séparation de la lecture et de l'écriture. Le serveur maître est principalement utilisé pour l'écriture, et l'esclave est principalement utilisé pour la lecture des données, ce qui peut améliorer la capacité de charge du serveur. Dans le même temps, le nombre de nœuds esclaves peut être ajouté en fonction de l'évolution de la demande.
Le quatrième point est l'équilibrage de charge. En conjonction avec la séparation de la lecture et de l'écriture, le nœud maître fournit des services d'écriture et les nœuds esclaves fournissent des services de lecture pour partager la charge du serveur, notamment lorsque écrire moins et lire plus, partager la charge de lecture via plusieurs nœuds esclaves peut considérablement améliorer la concurrence et la charge du serveur Redis.
Le cinquième point est la pierre angulaire de la haute disponibilité. La réplication maître-esclave est la base de la mise en œuvre de Sentinel et du cluster, nous pouvons donc dire que la réplication maître-esclave est la pierre angulaire de la haute disponibilité. .
Insérer la description de l'image ici
4. Configuration Redis réplication maître-esclave
Cela dit, commençons simplement par configurer un cas de réplication maître-esclave, puis parlons des principes de mise en œuvre.
Le chemin de stockage Redis est : usr/local/redis
Les fichiers journaux et de configuration sont stockés dans : usr/local/redis/data
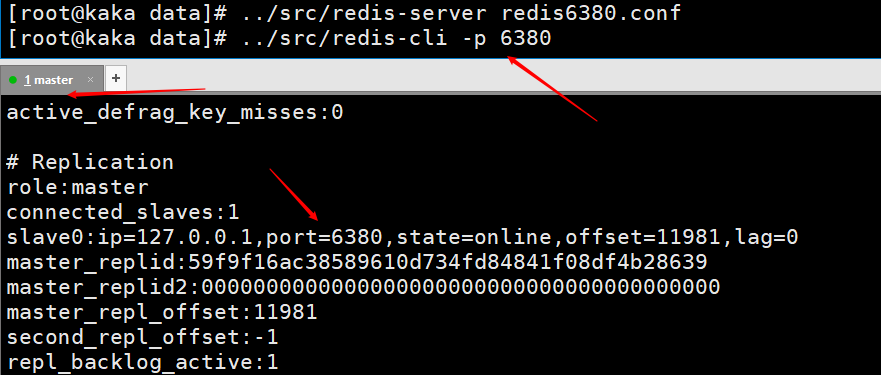
Nous configurons d'abord deux fichiers de configuration, à savoir redis6379.conf et redis6380.confModifions les fichiers de configuration, principalement pour modifier le port. Pour faciliter la visualisation, les noms des fichiers journaux et des fichiers persistants sont identifiés avec leurs ports respectifs. Ensuite, ouvrez respectivement deux services Redis, un avec le port 6379 et un avec le port 6380. Exécutez la commande redis-server redis6380.conf, puis utilisez redis-cli -p 6380 pour vous connecter. Étant donné que le port par défaut de redis est 6379, nous pouvons démarrer un autre serveur Redis et utiliser directement redis-server redis6379.conf, puis utiliser redis-cli pour nous connecter directement. À l'heure actuelle, nous avons configuré avec succès deux services Redis, l'un est 6380 et l'autre est 6379. Ceci est juste à titre de démonstration. Dans la réalité, il doit être configuré sur deux serveurs différents.
Insérer la description de l'image ici
1. Commencez à utiliser la ligne de commande client
Nous devons d'abord avoir un concept, c'est-à-dire que lors de la configuration de la réplication maître-esclave, toutes les opérations sont effectuées sur le nœud esclave, c'est-à-dire l'esclave.
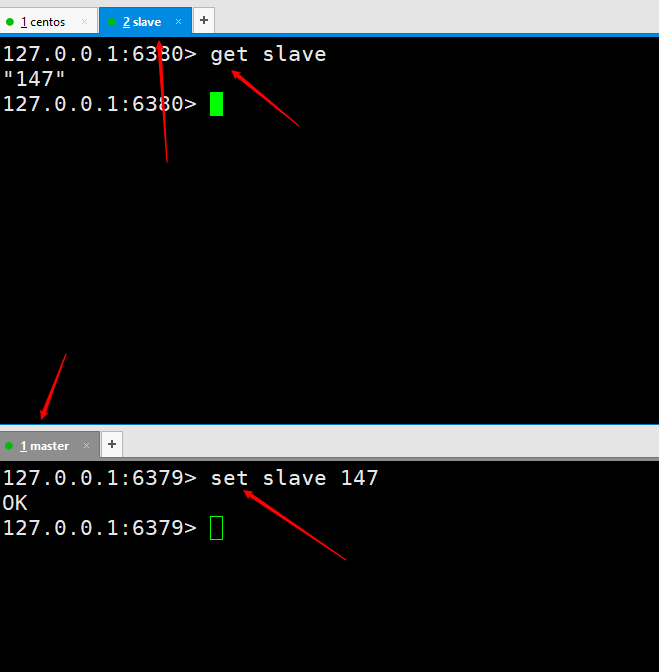
Ensuite, nous exécutons une commande sur le nœud esclave comme slaveof 127.0.0.1 6379 Après exécution, cela signifie que nous sommes connectés. Testons d'abord pour voir si la réplication maître-esclave est implémentée. Exécutez deux set kaka 123 和 set master 127.0.0.1 sur le serveur maître, puis le port slave6380 pourra être obtenu avec succès, ce qui signifie que notre réplication maître-esclave a été configurée. Cependant, la mise en œuvre de l'environnement de production n'est pas la fin du monde. Plus tard, la réplication maître-esclave sera encore optimisée jusqu'à ce qu'une haute disponibilité soit atteinte.
Insérer la description de l'image ici
Utiliser le fichier de configuration pour activer
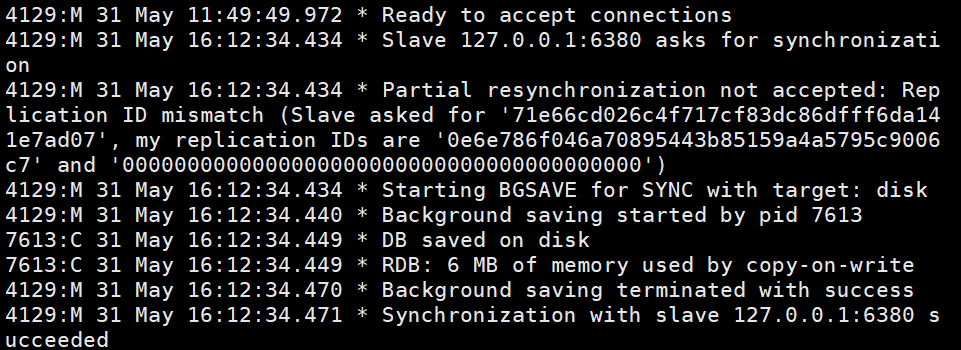
Avant d'utiliser le fichier de configuration pour démarrer la réplication maître-esclave ! Tout d'abord, vous devez déconnecter la connexion précédente à l'aide de la ligne de commande client et exécuter slaveof no one sur l'hôte esclave pour déconnecter la réplication maître-esclave. Où puis-je vérifier que le nœud esclave s'est déconnecté du nœud maître ? Entrez la ligne de commande info sur le client du nœud maître pour afficher
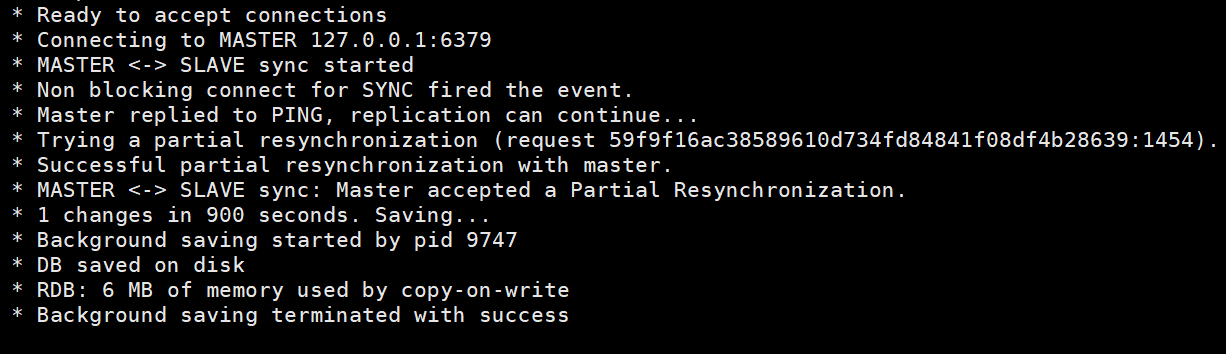
Cette image montre les informations imprimées en saisissant info sur le client du nœud maître après avoir utilisé le nœud esclave pour vous connecter au nœud maître à l'aide de la ligne de commande client. Vous pouvez voir qu'il y a une information sur slave0. . Cette image est imprimée sur le nœud maître après l'exécution de slaveof no one sur le nœud esclave, indiquant que le nœud esclave a été déconnecté du nœud maître. infoAprès avoir démarré le service Redis selon le fichier de configuration, redis-server redis6380.conf
Après le redémarrage du nœud esclave, les informations de connexion du nœud esclave peuvent être directement visualisées sur le nœud maître.
Les données de test, les éléments écrits par le nœud maître, seront toujours automatiquement synchronisés par le nœud esclave.
3. Démarrer au démarrage du serveur Redis
Cette méthode de configuration est également très simple. Lorsque vous utilisez le serveur Redis, démarrez directement la réplication maître-esclave et exécutez la commande :
. redis-server --slaveof host port
4. Afficher les informations du journal après le démarrage de la réplication maître-esclave
Il s'agit des informations du journal du nœud maître
4. 🎜>Il s'agit d'informations sur le nœud esclave, y compris les informations de connexion au nœud maître et le stockage des instantanés RDB. 5. Principe de fonctionnement de la réplication maître-esclave
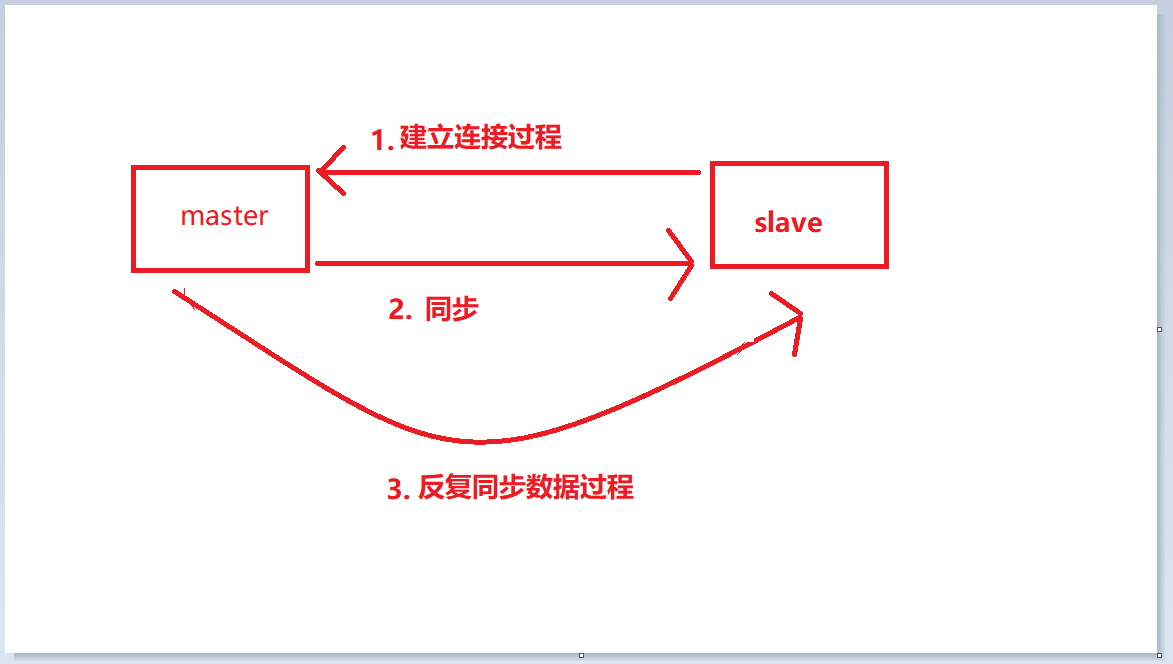
1 . Trois étapes de réplication maître-esclave
Le flux de travail complet de la réplication maître-esclave est divisé en trois étapes suivantes. Chaque segment a son propre flux de travail interne, nous parlerons donc de ces trois processus.
Processus d'établissement de connexion : ce processus est le processus de connexion de l'esclave au maître
Processus de synchronisation des données : c'est le processus de synchronisation du maître avec les données de l'esclave
Processus de propagation des commandes : synchronisation répétée des données
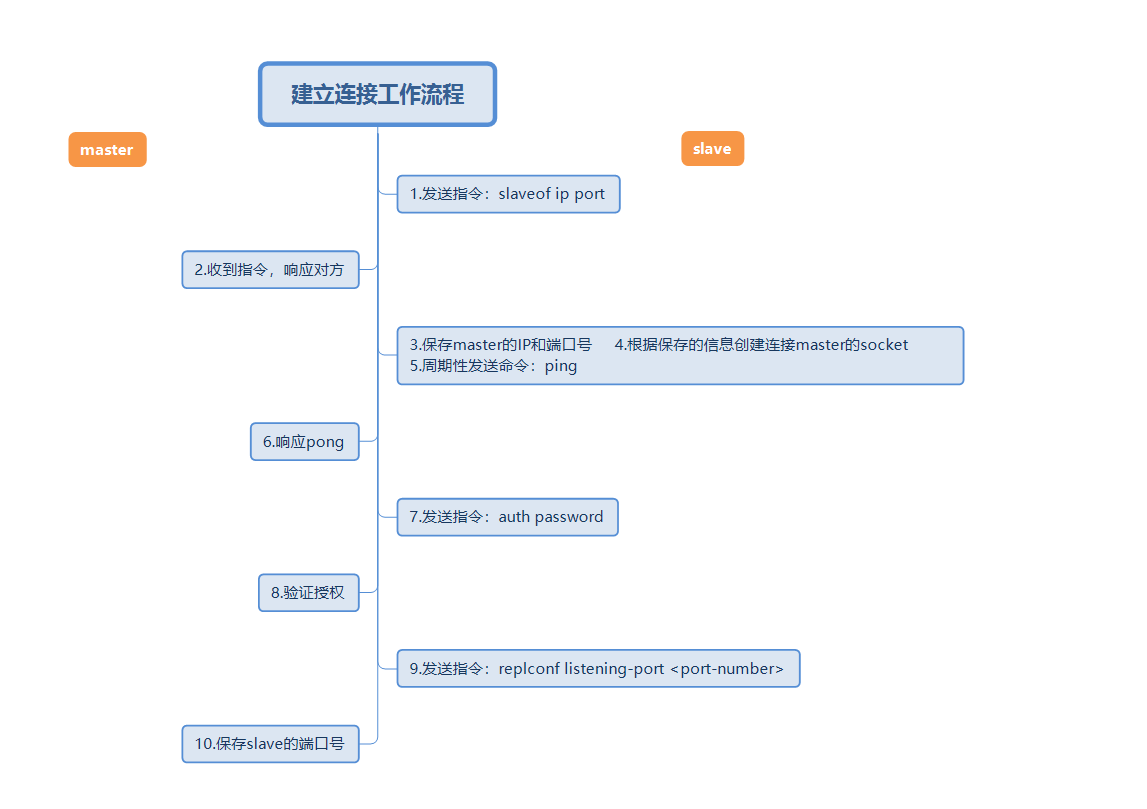
La première étape : l'établissement de la connexion. processus
L'image ci-dessus est un flux de travail complet d'établissement de connexion de réplication maître-esclave. Utilisez ensuite des mots courts pour décrire le flux de travail ci-dessus.
Définissez l'adresse et le port du maître, et enregistrez les informations du maître
Établissez une connexion socket (le rôle de cette connexion sera décrit ci-dessous)
Envoyer en continu la commande ping
Authentification
Envoyer les informations du port esclave
Pendant le processus d'établissement d'une connexion, le nœud esclave enregistrera l'adresse et le port du maître, et le nœud maître enregistrera le port du nœud esclave.
3. La deuxième étape : processus de synchronisation des données
Cette image est une description détaillée. processus de synchronisation des données lorsqu'un nœud esclave se connecte au nœud maître.
Lorsque le nœud esclave se connecte au nœud maître pour la première fois, il effectuera d'abord une copie complète. Cette copie complète est inévitable.
Une fois la réplication complète terminée, le nœud maître enverra les données dans le tampon du backlog de réplication, puis le nœud esclave exécutera bgrewriteaof pour restaurer les données, ce qui est également une réplication partielle.
Trois nouveaux points sont évoqués à ce stade, la copie complète, la copie partielle et le retard du tampon de copie. Ces points seront expliqués en détail dans la FAQ ci-dessous.
4. La troisième phase : phase de propagation des commandes
Lorsque la base de données maître est modifiée, le maître et l'esclave serveurs Une fois les données incohérentes, les données maître-esclave seront synchronisées pour être cohérentes. Ce processus est appelé propagation de commande.
Le maître enverra la commande de modification des données reçue à l'esclave, et l'esclave exécutera la commande après avoir reçu la commande pour rendre les données maître-esclave cohérentes.
"Réplication partielle dans l'étape de propagation des commandes"
Pendant l'étape de propagation des commandes, il y aura une déconnexion ou une gigue du réseau . Provoque la déconnexion de la connexion (connexion perdue)
À ce moment, le nœud maître continuera à écrire des données dans le replbackbuffer (zone de retard du tampon de réplication). )
Le nœud esclave continuera d'essayer de se connecter au maître
Quand le nœud esclave met son propre runid et le décalage de réplication est envoyé au nœud maître, et la commande pysnc est exécutée pour synchroniser
Si le maître détermine que le offset est dans la plage du tampon de réplication, il renverra l'ordre continu. Et envoyez les données dans le tampon de copie au nœud esclave.
Recevoir les données du nœud et exécuter bgrewriteaof, restaurer les données
6. Introduction détaillée au principe de la réplication maître-esclave (copie complète + copie partielle)
Ce processus est l'explication la plus complète du processus maître-esclave. réplication. Alors présentons brièvement chaque étape du processus
Envoyez la commande psync ? 1 psync runid offset depuis le nœud et recherchez le runid correspondant pour demander des données. Mais ici vous pouvez considérer que lorsque le nœud esclave se connecte pour la première fois, il ne connaît pas du tout le runid 和 offset du nœud maître. Donc la commande envoyée pour la première fois est psync ? 1, ce qui signifie que je veux toutes les données du nœud maître.
Le nœud maître commence à exécuter bgsave pour générer un fichier RDB et enregistrer le décalage de réplication actuel
Le nœud maître stockera son runid à cette fois et offset envoient le fichier RDB au nœud esclave via le socket via la commande +FULLRESYNC runid offset.
Le nœud esclave reçoit +FULLRESYNC, enregistre le runid et le décalage du nœud maître, puis efface toutes les données actuelles, reçoit le fichier RDB via le socket et commence à restaurer les données RDB. .
Après la réplication complète, le nœud esclave a obtenu le runid et le décalage du nœud maître et a commencé à envoyer des instructions psync runid offset
Le maître Le nœud reçoit des instructions pour déterminer si le runid correspond et si le décalage se trouve dans le tampon de copie.
Le nœud maître détermine que l'un des runid et offset n'est pas satisfait et reviendra à l'étape 2 pour continuer à effectuer la réplication complète. L'inadéquation du runid ici peut être uniquement due au redémarrage du nœud esclave. Ce problème sera résolu plus tard. L'inadéquation du décalage (offset) est le dépassement du tampon du retard de réplication. Si la vérification runid ou offset réussit, si le décalage du nœud esclave est le même que celui du nœud maître, il sera ignoré. Si la vérification runid ou offset réussit et que le décalage du nœud esclave est différent du décalage, +CONTINUE offset (ce décalage appartient au nœud maître) sera envoyé, et les données du décalage du nœud esclave vers le décalage du nœud maître dans le tampon de réplication sera envoyé via le socket.
Recevez +CONTINUE du nœud et enregistrez le décalage du maître Après avoir reçu les informations via le socket, exécutez bgrewriteaof pour restaurer les données.
"1 à 4 sont des copies complètes, 5 à 8 sont des copies partielles"
À l'étape 3 du nœud maître, le nœud maître a reçu des données client pendant la période de réplication maître-esclave et le décalage du nœud maître a changé. Seules les modifications seront envoyées à chaque esclave. Ce processus d'envoi est appelé mécanisme de battement de coeur
7. Mécanisme de battement de coeur
Dans l'étape de propagation des commandes, l'échange d'informations entre le nœud maître et le nœud esclave est toujours requis, et le mécanisme de battement de cœur est utilisé pour la maintenance afin de maintenir la connexion entre le nœud maître et le nœud esclave en ligne.
battement cardiaque principal
Commande : ping
La valeur par défaut est de 10 secondes. Il est déterminé par le paramètre repl-ping-slave-period
La principale chose qu'il fait est de déterminer si le nœud esclave est en ligne
Vous pouvez utiliser la réplication des informations Pour vérifier l'intervalle de temps de connexion après la location depuis le nœud esclave, si le décalage est de 0 ou 1, c'est normal.
tâche de battement de coeur esclave
Commande : replconf ack {offset}
Exécuté une fois par seconde
La principale chose qu'il fait est d'envoyer son propre décalage de réplication au nœud maître et d'obtenir la dernière commande de modification de données du maître node , une autre chose qu'il fait est de déterminer si le nœud maître est en ligne.
"Précautions pendant la phase de battement de coeur"Afin d'assurer la stabilité des données, le nœud maître attendra que le nombre de les nœuds esclaves se bloquent ou lorsque la latence est trop élevée. Toute synchronisation des informations sera refusée.
Il existe deux paramètres pour l'ajustement de la configuration : min-slaves-to-write 2min-slaves-max-lag 8 Ces deux Les paramètres indiquent qu'il ne reste que 2 nœuds esclaves, ou lorsque le délai du nœud esclave est supérieur à 8 secondes, le nœud maître éteindra de force la fonction maître et arrêtera la synchronisation des données.
Alors, comment le nœud maître connaît-il le nombre et le délai des pannes du nœud esclave ? Dans le mécanisme de battement de cœur, l'esclave enverra la commande perlconf ack toutes les secondes. Cette commande peut transporter le décalage, le temps de retard du nœud esclave et le nombre de nœuds esclaves.
8. Trois éléments essentiels de la réplication partielle
1. running id (run id)
Jetons d'abord un coup d'œil à ce qu'est cet identifiant d'exécution. Vous pouvez le voir en exécutant la commande info. Nous pouvons également le voir lorsque nous examinons les informations du journal de démarrage ci-dessus.
Redis générera automatiquement un identifiant aléatoire au démarrage (il convient de noter ici que l'identifiant sera différent à chaque démarrage), qui est composé de 40 chaînes hexadécimales aléatoires utilisées pour. identifier de manière unique un nœud Redis.
Lorsque la réplication maître-esclave est démarrée pour la première fois, le maître enverra son runid à l'esclave, et l'esclave enregistrera l'identifiant du maître. Nous pouvons utiliser la commande info pour afficher
<.>Insérer la description de l'image iciLorsqu'il est déconnecté et reconnecté, l'esclave envoie cet identifiant au maître si le runid enregistré par l'esclave est le même que celui. runid actuel du maître, le maître essaiera d'utiliser une copie partielle (un autre facteur déterminant si ce bloc peut être copié avec succès est le décalage). Si le runid enregistré par l'esclave est différent du runid actuel du maître, la copie complète sera effectuée directement.
2. Tampon du backlog de réplication
Le backlog du tampon de réplication est une file d'attente premier entré, premier sorti dans laquelle l'utilisateur stocke données collectées par l'enregistrement de commande principal. L'espace de stockage par défaut du tampon de copie est de 1 Mo.
Vous pouvez modifier repl-backlog-size 1mb dans le fichier de configuration pour contrôler la taille du tampon. Ce ratio peut être modifié en fonction de la mémoire de votre propre serveur que Kaka a réservée environ 30%.
"Qu'est-ce qui est exactement stocké dans le tampon de copie ?"
Lors de l'exécution d'une commande en tant que set name kaka, nous pouvons visualiser le fichier de persistance pour afficher puis Le tampon du backlog de copie est la quantité stockée de données persistantes, séparées par des octets, et chaque octet a son propre décalage. Ce décalage est également le décalage de copie (offset) "Alors pourquoi dit-on que l'arriéré du tampon de copie peut provoquer une copie complète
Dans la phase de propagation des commandes, Le maître ?" Le nœud stockera les données collectées dans le tampon de réplication, puis les enverra au nœud esclave. C'est là que le problème se pose. Lorsque la quantité de données sur le nœud maître est extrêmement importante en un instant et dépasse la mémoire du tampon de réplication, certaines données seront supprimées, entraînant une incohérence des données entre le nœud maître et l'esclave. nœud. Pour en faire une copie complète. Si la taille du tampon est définie de manière déraisonnable, cela peut provoquer une boucle infinie. Le nœud esclave copiera toujours intégralement, effacera les données et copiera intégralement.
3. Décalage de réplication (offset)
Le décalage de réplication du nœud maître est envoyé au nœud esclave Enregistrez une fois , et le nœud esclave reçoit l'enregistrement une fois.
est utilisé pour synchroniser les informations, comparer les différences entre le nœud maître et le nœud esclave et restaurer l'utilisation des données lorsque l'esclave est déconnecté.
Cette valeur est le décalage par rapport au retard du tampon de copie.
9. Problèmes courants avec la réplication maître-esclave
1. Problème de redémarrage du nœud maître (optimisation interne)
Lorsque le nœud maître est redémarré, la valeur de runid changera, ce qui entraînera la réplication complète de tous les nœuds esclaves.
Nous n’avons pas besoin de considérer cette question, nous avons juste besoin de savoir comment le système est optimisé.
Une fois la réplication maître-esclave établie, le nœud maître créera la variable maître-réplid. La stratégie générée est la même que celle du runid, la longueur est de 41 bits et la longueur du runid est de 40 bits. puis envoyé au nœud esclave.
Lorsque la commande shutdown save est exécutée sur le nœud maître, une persistance RDB est effectuée et le runid et le offset sont enregistrés dans le fichier RDB. Vous pouvez utiliser la commande redis-check-rdb pour afficher ces informations.
Chargez le fichier RDB après le redémarrage du nœud maître, et chargez le repl-id et le repl-offset dans le fichier en mémoire. Même si tous les nœuds esclaves sont considérés comme les nœuds maîtres précédents.
2. Le réseau de nœuds esclaves a été interrompu et le décalage a dépassé la limite, ce qui a entraîné une réplication complète
En raison d'un réseau médiocre. environnement, le réseau de nœuds esclaves a été interrompu. La mémoire tampon du retard de réplication est trop petite, ce qui entraîne un débordement de données. Parallèlement au décalage du nœud esclave dépassant la limite, une réplication complète se produit. Cela peut entraîner des copies complètes répétées.
Solution : modifier la taille du tampon du backlog de réplication : repl-backlog-size
Suggestions de paramètres : tester le temps nécessaire à la connexion du nœud maître au nœud esclave et obtenir le total moyen nombre de commandes générées par le nœud maître par seconde. Quantité write_size_per_second
Paramètre d'espace tampon de copie = 2 * Temps de connexion maître-esclave * Quantité totale de données générées par le nœud maître par seconde
3. Réseau fréquent Le chemin est interrompu
car l'utilisation du processeur du nœud maître est trop élevée ou le nœud esclave est fréquemment connecté. . Le résultat de cette situation est que diverses ressources du nœud maître sont sérieusement occupées, notamment, mais sans s'y limiter, les tampons, la bande passante, les connexions, etc.
Pourquoi les ressources du nœud maître sont-elles fortement occupées ?
Dans le mécanisme de battement de cœur, le nœud esclave enverra une commande replconf ack au nœud maître toutes les secondes.
Une requête lente a été exécutée sur le nœud esclave, occupant une grande quantité de CPU.
Le nœud maître appelle la fonction de synchronisation de réplication replicationCron toutes les secondes, puis le nœud esclave ne répond pas pendant une longue période.
Solution :
Définir la libération du délai d'expiration du nœud esclave
Définir le paramètre : repl-timeout
Ce paramètre est défini par défaut sur 60 secondes. Après 60 secondes, relâchez l'esclave.
4. Problème d'incohérence des données
En raison de facteurs de réseau, les données de plusieurs nœuds esclaves seront incohérentes. Il n'y a aucun moyen d'éviter ce facteur.
Il existe deux solutions à ce problème :
Les premières données nécessitent une configuration hautement cohérente d'un serveur Redis, et un serveur est utilisé à la fois pour la lecture et l'écriture. Cette méthode est limitée à un. petite quantité de données, et les données doivent être très cohérentes.
Le second surveille le décalage des nœuds maître et esclave. Si le délai du nœud esclave est trop important, l'accès du client au nœud esclave est temporairement bloqué. Définissez le paramètre sur slave-serve-stale-data yes|no. Une fois ce paramètre défini, il ne peut répondre qu'à quelques commandes telles que info slaveof.
5. Défaillance du nœud esclave
Ce problème maintient directement une liste des nœuds disponibles côté client. le nœud esclave En cas de panne, passez à d'autres nœuds pour le travail. Ce problème sera abordé plus tard dans le cluster.
10. Résumé
Cet article explique principalement ce qu'est la réplication maître-esclave et les trois aspects majeurs du maître. -réplication esclave Étapes, flux de travail et trois composants principaux de la réplication partielle. Mécanisme de battement de coeur pendant la phase de propagation des commandes. Enfin, les problèmes courants liés à la réplication maître-esclave sont expliqués.
Cet article a pris deux jours pour être écrit. C'est aussi l'article le plus long que Kaka a récemment écrit. On estime que les articles publiés par Kaka à l'avenir seront comme celui-ci. un problème séparément. Je l'expliquerai dans un article, et j'expliquerai tout dans un seul article. Les points de connaissance incomplets ou erronés seront améliorés à mesure que les points de connaissance de Kaka augmenteront. L'article est principalement destiné à la commodité de la revue Kaka. Si vous avez des questions, consultez la section commentaires.
Kaka espère que tout le monde pourra communiquer et apprendre ensemble. Si quelque chose ne va pas, vous pouvez le signaler. Si vous ne l'aimez pas, ne le critiquez pas.
❝
La persévérance dans l'apprentissage, la persévérance dans les blogs et la persévérance dans le partage sont les convictions auxquelles Kaka a toujours adhéré depuis sa carrière. J'espère que les articles de Kaka sur l'immense Internet pourront vous apporter. un peu d'aide. A la prochaine fois
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Déclaration:
Le contenu de cet article est volontairement contribué par les internautes et les droits d'auteur appartiennent à l'auteur original. Ce site n'assume aucune responsabilité légale correspondante. Si vous trouvez un contenu suspecté de plagiat ou de contrefaçon, veuillez contacter admin@php.cn


Donc, en réponse aux deux problèmes ci-dessus, nous allons préparer quelques serveurs supplémentaires et configurer la réplication maître-esclave. Stockez les données sur plusieurs serveurs. Et assurez-vous que les données de chaque serveur sont synchronisées. Même si un serveur tombe en panne, cela n'affectera pas l'utilisation des utilisateurs. Redis peut continuer à assurer une haute disponibilité et une sauvegarde redondante des données.
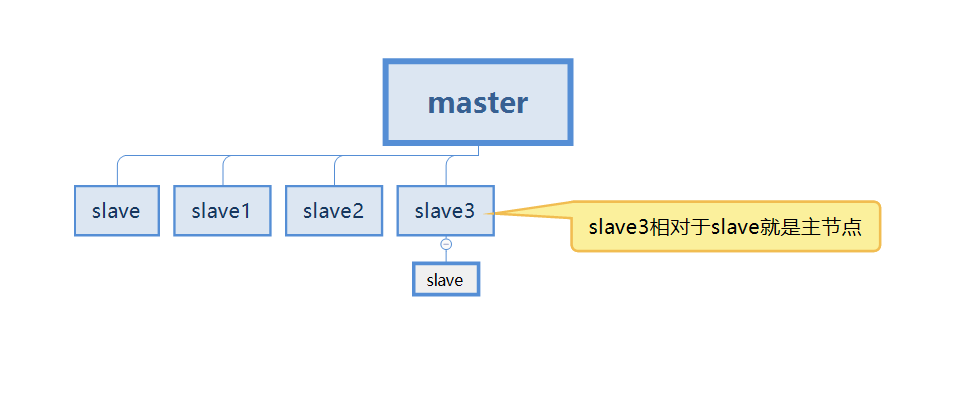
 Donc, en réponse aux deux problèmes ci-dessus, nous allons préparer quelques serveurs supplémentaires et configurer la réplication maître-esclave. Stockez les données sur plusieurs serveurs. Et assurez-vous que les données de chaque serveur sont synchronisées. Même si un serveur tombe en panne, cela n'affectera pas l'utilisation des utilisateurs. Redis peut continuer à assurer une haute disponibilité et une sauvegarde redondante des données.
Donc, en réponse aux deux problèmes ci-dessus, nous allons préparer quelques serveurs supplémentaires et configurer la réplication maître-esclave. Stockez les données sur plusieurs serveurs. Et assurez-vous que les données de chaque serveur sont synchronisées. Même si un serveur tombe en panne, cela n'affectera pas l'utilisation des utilisateurs. Redis peut continuer à assurer une haute disponibilité et une sauvegarde redondante des données. 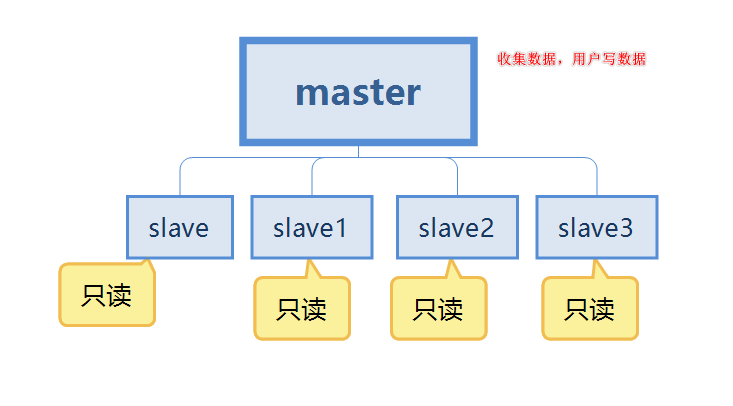
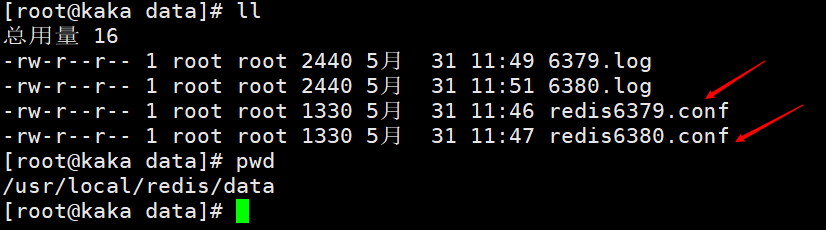 Modifions les fichiers de configuration, principalement pour modifier le port. Pour faciliter la visualisation, les noms des fichiers journaux et des fichiers persistants sont identifiés avec leurs ports respectifs.
Modifions les fichiers de configuration, principalement pour modifier le port. Pour faciliter la visualisation, les noms des fichiers journaux et des fichiers persistants sont identifiés avec leurs ports respectifs. 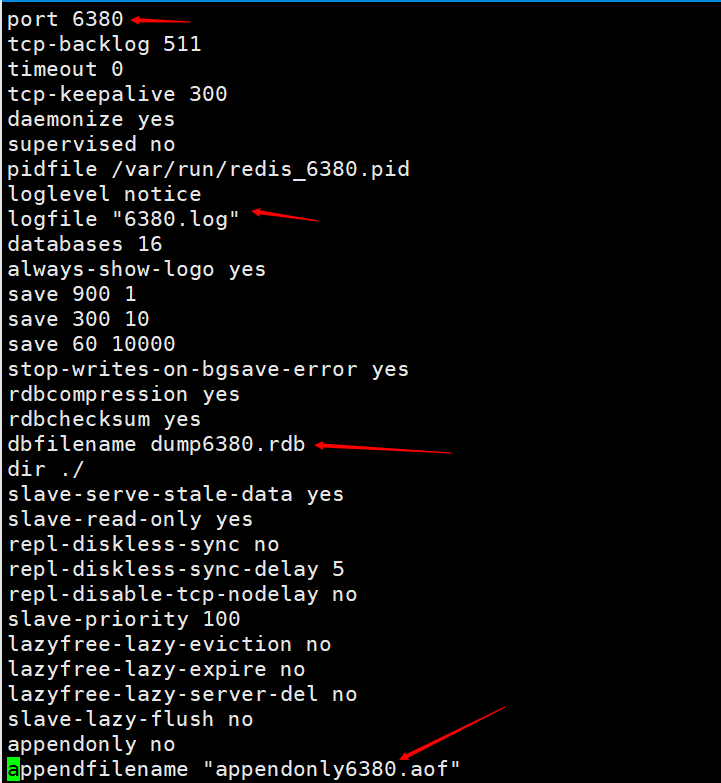 Ensuite, ouvrez respectivement deux services Redis, un avec le port 6379 et un avec le port 6380. Exécutez la commande
Ensuite, ouvrez respectivement deux services Redis, un avec le port 6379 et un avec le port 6380. Exécutez la commande  À l'heure actuelle, nous avons configuré avec succès deux services Redis, l'un est 6380 et l'autre est 6379. Ceci est juste à titre de démonstration. Dans la réalité, il doit être configuré sur deux serveurs différents.
À l'heure actuelle, nous avons configuré avec succès deux services Redis, l'un est 6380 et l'autre est 6379. Ceci est juste à titre de démonstration. Dans la réalité, il doit être configuré sur deux serveurs différents. 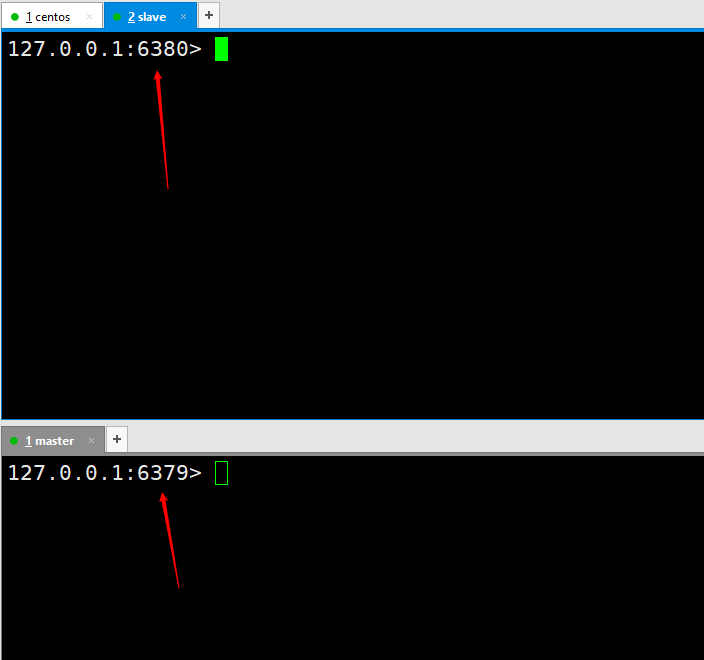
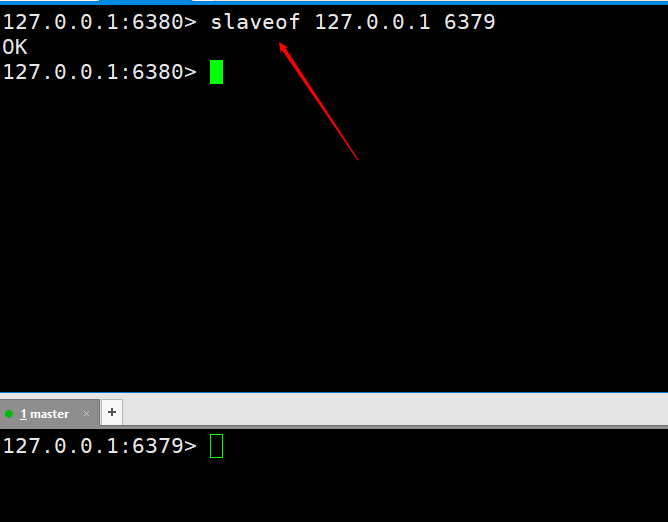 Testons d'abord pour voir si la réplication maître-esclave est implémentée. Exécutez deux
Testons d'abord pour voir si la réplication maître-esclave est implémentée. Exécutez deux 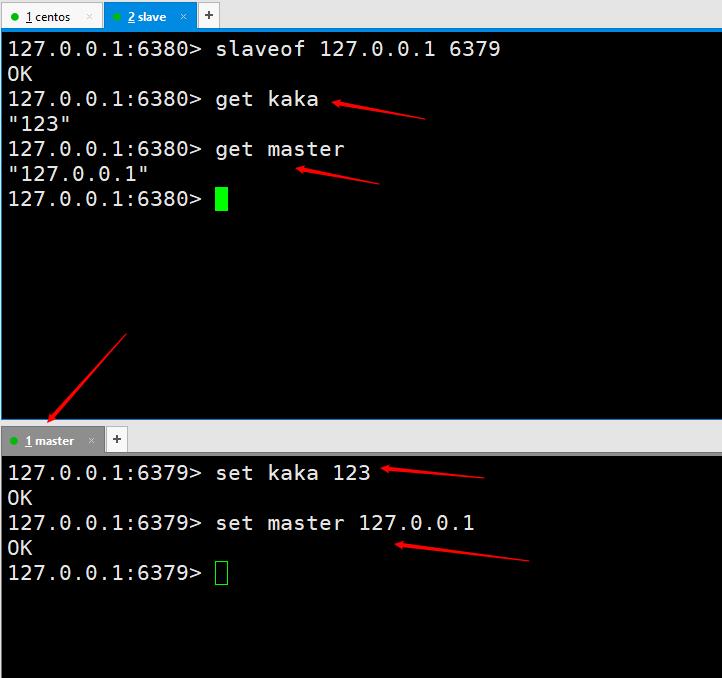
 Où puis-je vérifier que le nœud esclave s'est déconnecté du nœud maître ? Entrez la ligne de commande
Où puis-je vérifier que le nœud esclave s'est déconnecté du nœud maître ? Entrez la ligne de commande 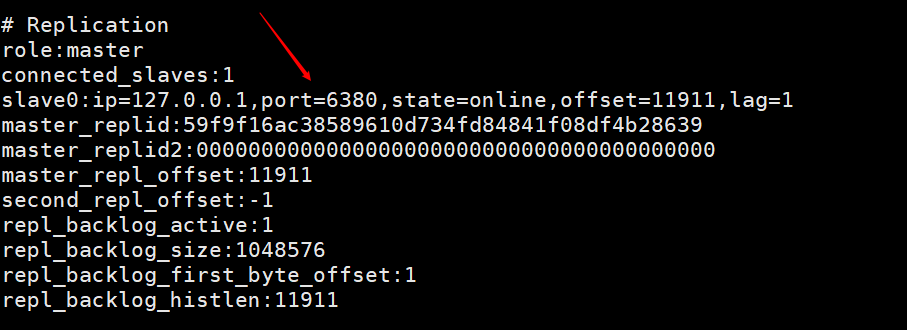 Cette image est imprimée sur le nœud maître après l'exécution de
Cette image est imprimée sur le nœud maître après l'exécution de 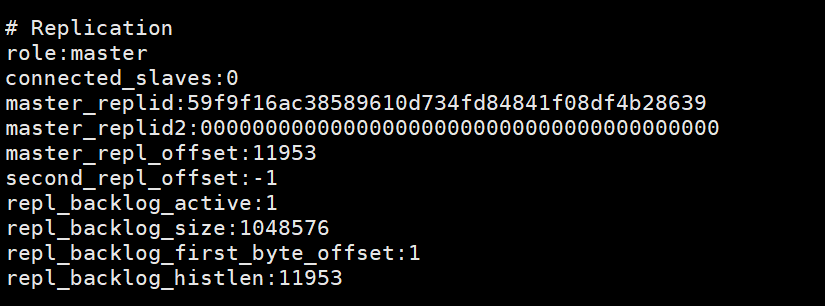
 L'image ci-dessus est un flux de travail complet d'établissement de connexion de réplication maître-esclave. Utilisez ensuite des mots courts pour décrire le flux de travail ci-dessus.
L'image ci-dessus est un flux de travail complet d'établissement de connexion de réplication maître-esclave. Utilisez ensuite des mots courts pour décrire le flux de travail ci-dessus. 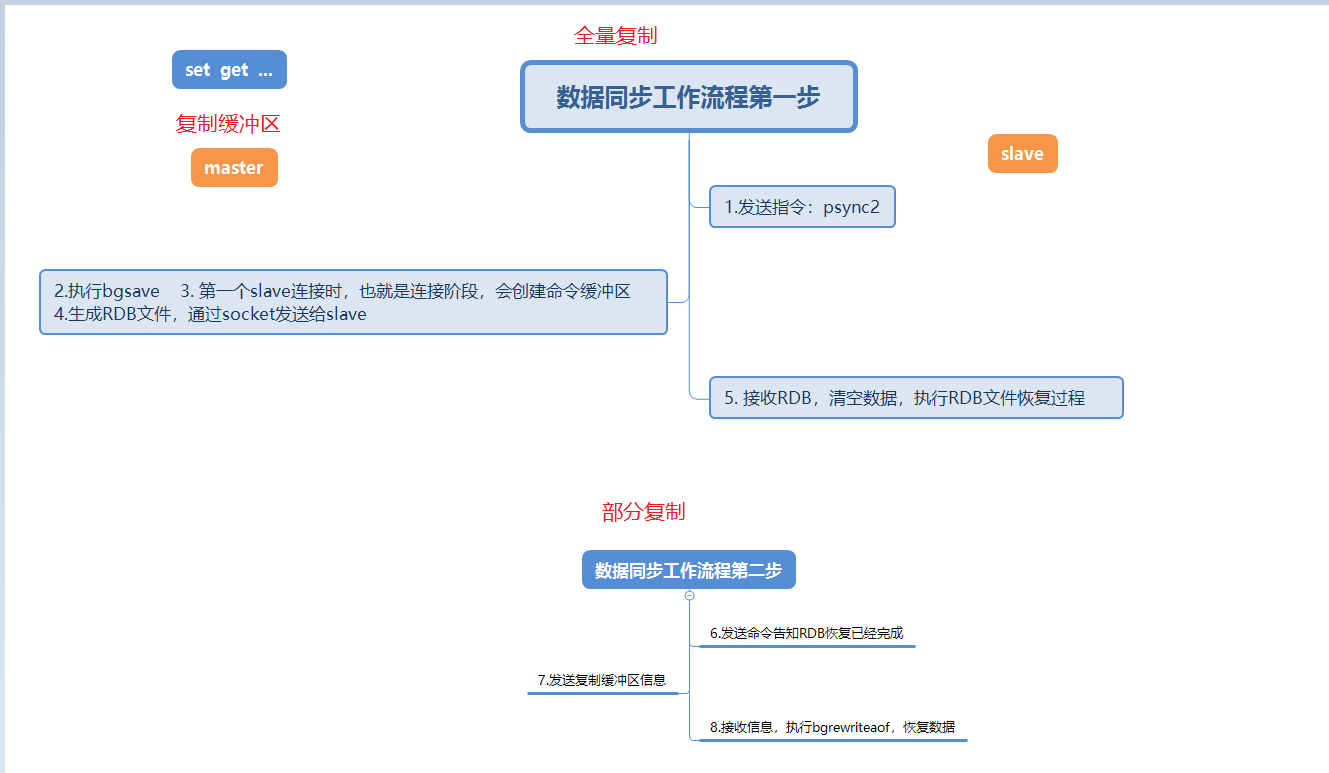 Cette image est une description détaillée. processus de synchronisation des données lorsqu'un nœud esclave se connecte au nœud maître.
Cette image est une description détaillée. processus de synchronisation des données lorsqu'un nœud esclave se connecte au nœud maître.  Ce processus est l'explication la plus complète du processus maître-esclave. réplication. Alors présentons brièvement chaque étape du processus
Ce processus est l'explication la plus complète du processus maître-esclave. réplication. Alors présentons brièvement chaque étape du processus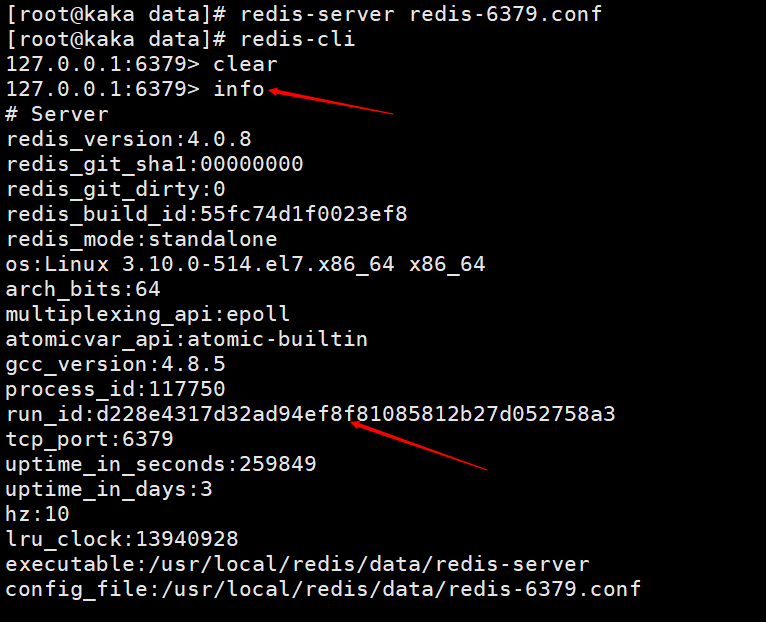 Redis générera automatiquement un identifiant aléatoire au démarrage (il convient de noter ici que l'identifiant sera différent à chaque démarrage), qui est composé de 40 chaînes hexadécimales aléatoires utilisées pour. identifier de manière unique un nœud Redis.
Redis générera automatiquement un identifiant aléatoire au démarrage (il convient de noter ici que l'identifiant sera différent à chaque démarrage), qui est composé de 40 chaînes hexadécimales aléatoires utilisées pour. identifier de manière unique un nœud Redis. 
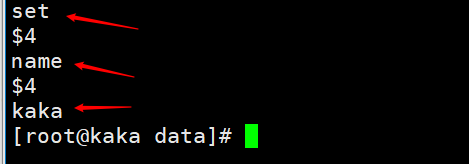 puis Le tampon du backlog de copie est la quantité stockée de données persistantes, séparées par des octets, et chaque octet a son propre décalage. Ce décalage est également le décalage de copie (offset)
puis Le tampon du backlog de copie est la quantité stockée de données persistantes, séparées par des octets, et chaque octet a son propre décalage. Ce décalage est également le décalage de copie (offset)  "Alors pourquoi dit-on que l'arriéré du tampon de copie peut provoquer une copie complète
"Alors pourquoi dit-on que l'arriéré du tampon de copie peut provoquer une copie complète 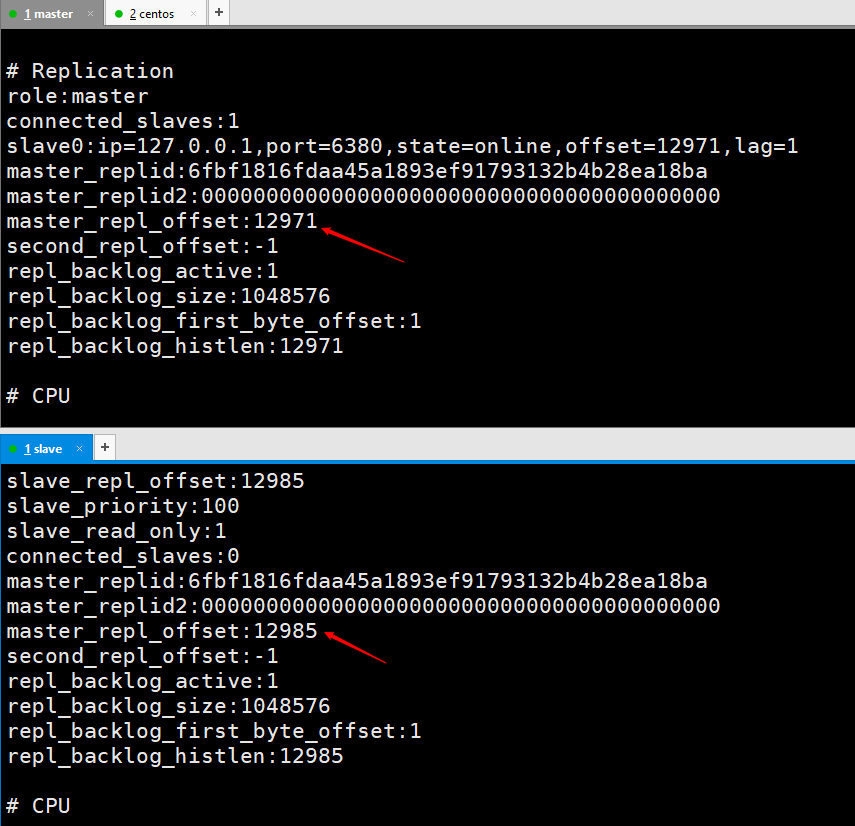 Le décalage de réplication du nœud maître est envoyé au nœud esclave Enregistrez une fois , et le nœud esclave reçoit l'enregistrement une fois.
Le décalage de réplication du nœud maître est envoyé au nœud esclave Enregistrez une fois , et le nœud esclave reçoit l'enregistrement une fois. 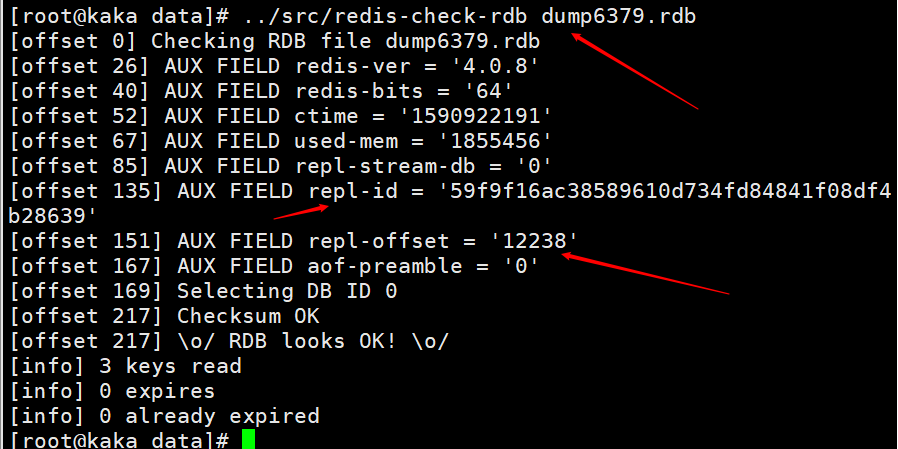 Chargez le fichier RDB après le redémarrage du nœud maître, et chargez le repl-id et le repl-offset dans le fichier en mémoire. Même si tous les nœuds esclaves sont considérés comme les nœuds maîtres précédents.
Chargez le fichier RDB après le redémarrage du nœud maître, et chargez le repl-id et le repl-offset dans le fichier en mémoire. Même si tous les nœuds esclaves sont considérés comme les nœuds maîtres précédents.