
Maison >base de données >Redis >Un article pour comprendre les cinq principaux types de données et scénarios d'application de Redis
Un article pour comprendre les cinq principaux types de données et scénarios d'application de Redis

- 咔咔original
- 2020-08-28 17:16:172230parcourir
❝Points de connaissance d'apprentissage dans cet article Redis cinq types de données principaux : chaîne, hachage, liste, ensemble, sorted_set Scénarios d'application des cinq grands types
❞
Avant-propos
❝Kaka a compilé une feuille de route pour créer un guide d'entretien et s'est préparé à écrire des articles selon cette feuille de route. Plus tard, j'ai découvert qu'il n'y avait aucun point de connaissances supplémentaire à ajouter. J'attends également avec impatience que vos partenaires se joignent à nous pour nous aider à ajouter des informations. Rendez-vous dans la section commentaires !
❞

1. type
1-1 Opérations de base des données de type chaîne
Ajouter /modifier les données : set key value
Obtenir des données : get key
Supprimer des données : del key
Ajouter/modifier plusieurs données : mset key value key1 value1
Obtenez plusieurs données : mget key key1
Ajouter des informations à la fin des données d'origine (ajoutez-les si elles n'existent pas) : append key value
Opérations d'augmentation et de diminution de type chaîne 1-2
Définissez la valeur pour augmenter la valeur dans la plage spécifiée : incr key 默认每次加1 | incrby key value 每次新增valueDéfinissez les données pour diminuer la plage spécifiée : decr key | decrby key value 跟新增是一回事
"Scénario d'application"
Contrôlez l'ID de clé primaire de la table de base de données, fournissez une stratégie de génération de clé primaire pour la table de base de données et assurez la cohérence de la clé primaire de la table de données.
Opérations de vieillissement de type chaîne 1-3
Définir l'heure d'expiration : setex key seconds value
「Scénario d'application」
Implémenter une fonction de vote à durée limitée : par exemple, un compte WeChat peut voter une fois par heure Réalisez des informations d'actualité : telles que les produits populaires dans l'industrie du commerce électronique et les actualités populaires sur les sites d'information
Scénarios d'application de type 1 à 4 chaînes
Visites à haute fréquence de la page d'accueil de Weibo big V, pour le nombre de fans et abonnés, les numéros Weibo doivent être mis à jour de temps en temps. Il s'agit d'informations à haute fréquence, et nous pouvons utiliser le type chaîne de redis pour les résoudre 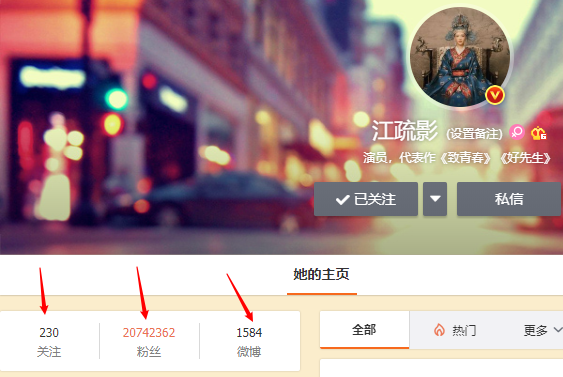 Définir les informations utilisateur pour big V dans redis, en utilisant la clé primaire et les attributs de l'utilisateur comme valeurs de clé. Ce qui suit est un cas d'implémentation.
Définir les informations utilisateur pour big V dans redis, en utilisant la clé primaire et les attributs de l'utilisateur comme valeurs de clé. Ce qui suit est un cas d'implémentation. 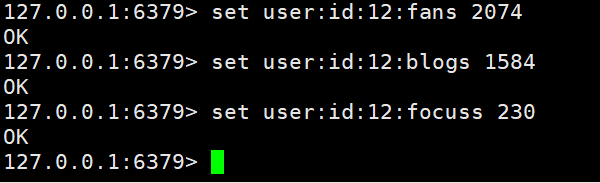 Ici, nous devons parler brièvement des règles de dénomination des clés : nom de la table + clé primaire + valeur de la clé primaire + champ : valeur du champ. Nommer selon de telles règles peut très bien gérer nos valeurs clés.
Ici, nous devons parler brièvement des règles de dénomination des clés : nom de la table + clé primaire + valeur de la clé primaire + champ : valeur du champ. Nommer selon de telles règles peut très bien gérer nos valeurs clés.
Nous pouvons également utiliser une autre façon d'y parvenir, qui consiste à suivre directement la clé avec une structure, par exemple 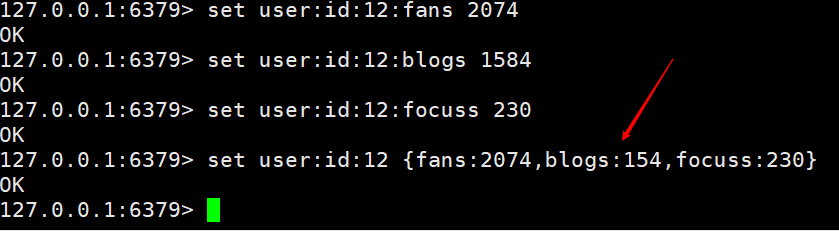 Les deux méthodes ci-dessus peuvent être implémentées, mais la première peut être très pratique pour n'importe qui Une valeur est gérée, et la seconde est que vous devez la modifier une fois à chaque fois. En fonction du scénario commercial, il suffit de l'actualiser régulièrement.
Les deux méthodes ci-dessus peuvent être implémentées, mais la première peut être très pratique pour n'importe qui Une valeur est gérée, et la seconde est que vous devez la modifier une fois à chaque fois. En fonction du scénario commercial, il suffit de l'actualiser régulièrement.
2. Type de hachage
2-1 Données de type de hachage De base opérations
Ajouter/modifier des données : hset key field value
Obtenir des données : hget key field | hgetall key
Supprimer des données : hdel key field field1
Ajouter/modifier plusieurs données : hmset key field value field1 value1
Obtenir plusieurs données : hmget key field field1
Obtenez le nombre de champs dans le tableau : hlen key
Obtenez si un champ existe dans le tableau : hexists key field
2-2 Opérations étendues pour les données de type de hachage
Obtenir toutes les valeurs de champ dans la table de hachage : hkeys key
Obtenez toutes les valeurs de champ dans la table de hachage : hvals key
Définissez la valeur du champ spécifié pour augmenter la valeur de la plage spécifiée : hincrby key field increment | 🎜>hincrbyfloat key field increment
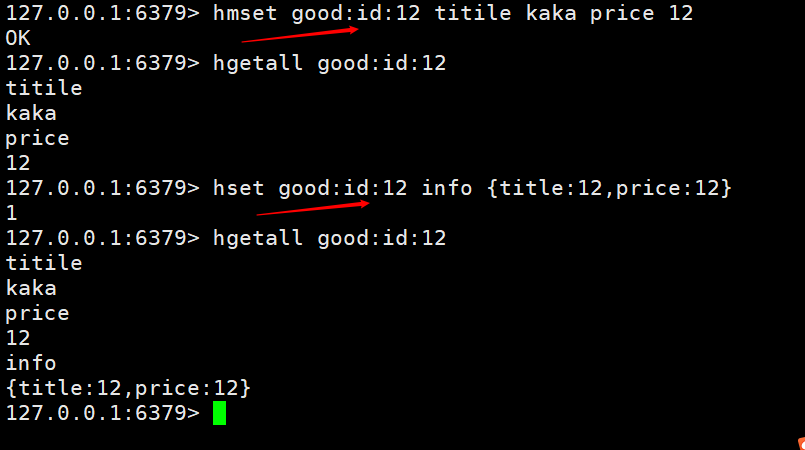
2-3 Panier d'achat du scénario commercial de hachageCette image n'est pas faite maison à partir d'Internet, elle simule simplement le panier scénarioDans l'image ci-dessus, nous pouvons voir les informations dans le panier. Utilisons redis pour implémenter le panier.
Ici, nous implémentons l'ajout d'un panier et l'obtention d'un panier. Les clés sont nommées nom de la table + clé primaire + valeur de la clé primaire 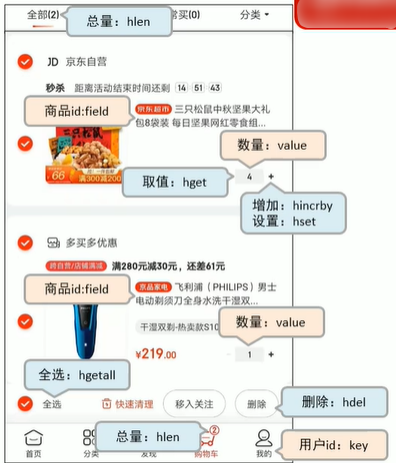 Dans l'image ci-dessus, nous aurons un problème de stockage des informations sur le produit. sera répété beaucoup, nous devons donc également hacher le produit séparément. Comme le montre l'image ci-dessous, seul l'ID du produit est stocké
Dans l'image ci-dessus, nous aurons un problème de stockage des informations sur le produit. sera répété beaucoup, nous devons donc également hacher le produit séparément. Comme le montre l'image ci-dessous, seul l'ID du produit est stocké
pour fournir une méthode 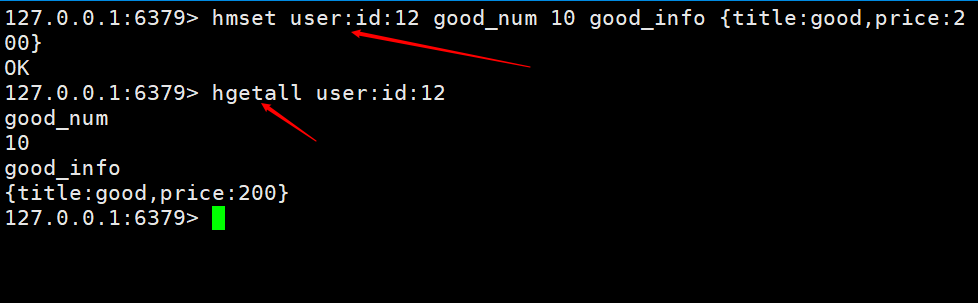 pour tout le monde. Si elle existe, elle ne sera pas ajoutée, sinon, elle sera ajoutée. Cette fonction est utilisée pour éviter l'écrasement et les opérations inutiles lorsque différents utilisateurs ajoutent le même produit
pour tout le monde. Si elle existe, elle ne sera pas ajoutée, sinon, elle sera ajoutée. Cette fonction est utilisée pour éviter l'écrasement et les opérations inutiles lorsque différents utilisateurs ajoutent le même produit
3. Type de liste
Exigences de stockage des données : stocker plusieurs données et différencier l'ordre de l'espace de stockage pour les données. Structure de données requise : un espace de stockage stocke plusieurs données et la séquence de saisie peut être reflétée à travers les données Type de liste : enregistrez plusieurs données. La couche inférieure utilise une structure de stockage de liste doublement liée pour implémenter
3-1 Opérations de base des données de type liste
Ajouter/modifier des données : lpush key value value1 rpush key value value1
Obtenir des données : lrange key start end lindex key indexllen key
| rpop keylpop key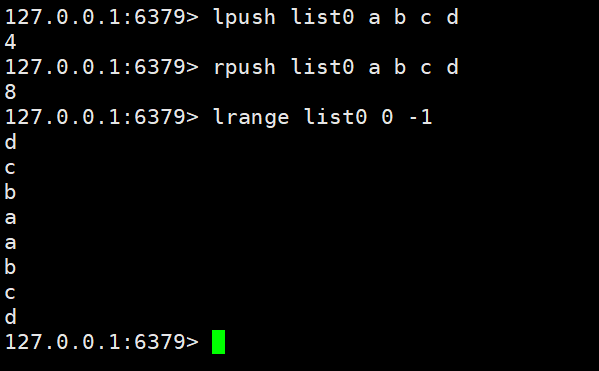
3-2 Opérations étendues pour les données de type liste
Obtenir et supprimer des données dans le délai spécifié : blpop key1 key2 timeout | brpop key1 key2 timeout
Cette fonction est simple pour rédiger un cas et facile à comprendre
Le terminal sur la gauche Une fois l'instruction exécutée, elle attendra 30 secondes pour renvoyer les données supprimées
Lorsque l'instruction d'ajout à droite est exécutée, le côté gauche renverra directement les données supprimées
Scénario commercial de liste 3-3
Ci-dessus, nous connaissons les opérations de base de la liste Exécuter la touche lpop ou la touche rpop pour supprimer. de faire ou de droite, mais maintenant il y a Le premier scénario est le cercle d'amis comme les affaires, puis annuler les données du milieu. Le cas est le suivant
Nous ajoutons d'abord a b c d à la liste5
Puis supprimez c
Après vérification, il ne reste plus qu'un bd 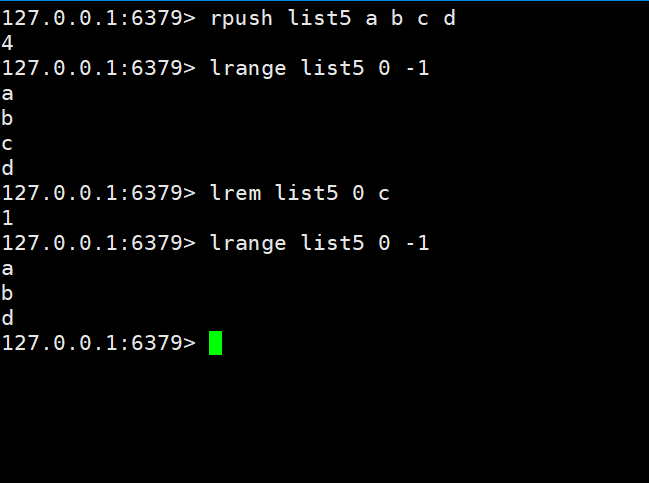
4. Type d'ensemble
Nouvelles exigences de stockage : stockez de grandes quantités de données et offrez une plus grande efficacité pour faciliter les requêtes. Structure de stockage requise : capable de sauvegarder de grandes quantités de données, mécanisme de stockage interne efficace, facile à interroger type d'ensemble : exactement la même chose que la structure de stockage de hachage, stocke uniquement les clés, pas les valeurs (néant), et les valeurs ne peuvent pas être répétées
4-1 Opérations de base des données de type ensemble
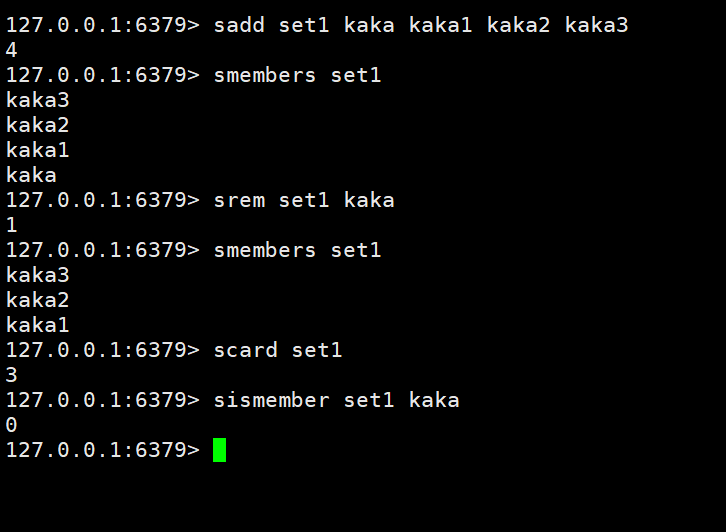
Ajouter/modifier données : sadd key member member1
Obtenir des données : smembers key
Supprimer des données : srem key member1
Obtenir la quantité totale de données collectées : scard key
Déterminez si les données spécifiées sont incluses dans la collection : sismember key member
4-2 opérations d'expansion des données de type ensemble
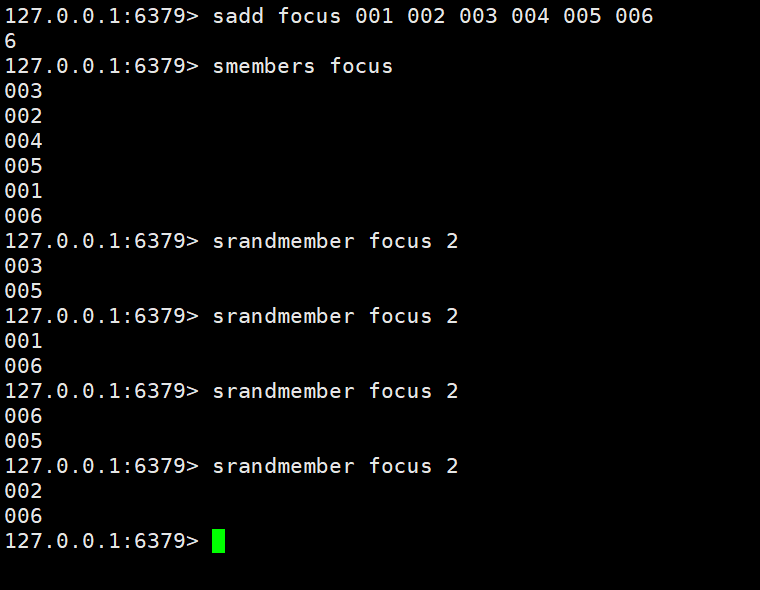
Obtenir aléatoirement le nombre spécifié de données dans l'ensemble : srandmember key count
Obtenez aléatoirement la quantité spécifiée de données dans l'ensemble. Certaines données seront supprimées de l'ensemble : spop key
4-3 informations recommandées sur le scénario commercial de type ensemble
Poussez au hasard des informations brûlantes, des actualités brûlantes, des voyages à succès, des recommandations d'applications, suivez les recommandations, etc.
Puisque Kaka écrit Discuz récemment, cette affaire est utilisé pour mettre en œuvre les recommandations suivantes.
Cas 1 : stocker les utilisateurs correspondants dans l'ensemble selon un certain mécanisme de recommandation, puis obtenir au hasard 2 utilisateurs qui doivent être recommandés à chaque fois
Cas 2 : stockez les utilisateurs correspondants dans l'ensemble selon un certain mécanisme de recommandation, puis les utilisateurs recommandés chaque jour en fonction de la date ne peuvent pas être répétés

4-4 types de scénarios commerciaux pour exploiter les relations avec les utilisateurs
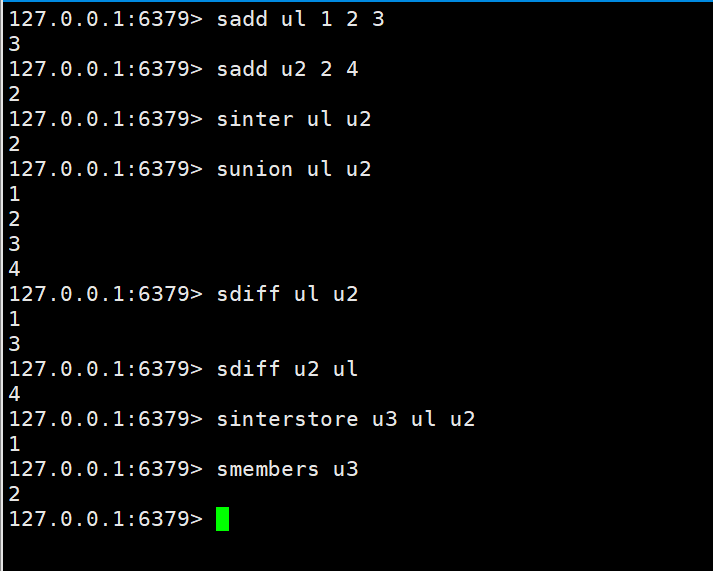
L'intersection, l'union et la différence de deux ensembles
<span style="display: block; background: url(https://my-wechat.mdnice.com/point.png); height: 30px; width: 100%; background-size: 40px; background-repeat: no-repeat; background-color: #272822; margin-bottom: -7px; border-radius: 5px; background-position: 10px 10px;"></span><code class="hljs" style="overflow-x: auto; padding: 16px; color: #ddd; display: -webkit-box; font-family: Operator Mono, Consolas, Monaco, Menlo, monospace; font-size: 12px; -webkit-overflow-scrolling: touch; letter-spacing: 0px; padding-top: 15px; background: #272822; border-radius: 5px;"><span class="hljs-selector-tag" style="color: #f92672; font-weight: bold; line-height: 26px;">sinter</span> <span class="hljs-selector-tag" style="color: #f92672; font-weight: bold; line-height: 26px;">key</span> <span class="hljs-selector-tag" style="color: #f92672; font-weight: bold; line-height: 26px;">key1</span><br/><span class="hljs-selector-tag" style="color: #f92672; font-weight: bold; line-height: 26px;">sunion</span> <span class="hljs-selector-tag" style="color: #f92672; font-weight: bold; line-height: 26px;">key</span> <span class="hljs-selector-tag" style="color: #f92672; font-weight: bold; line-height: 26px;">key1</span><br/><span class="hljs-selector-tag" style="color: #f92672; font-weight: bold; line-height: 26px;">sdiff</span> <span class="hljs-selector-tag" style="color: #f92672; font-weight: bold; line-height: 26px;">key</span> <span class="hljs-selector-tag" style="color: #f92672; font-weight: bold; line-height: 26px;">key1</span><br/></code>
L'intersection, l'union et la différence de deux ensembles sont stockées dans l'ensemble spécifié
<span style="display: block; background: url(https://my-wechat.mdnice.com/point.png); height: 30px; width: 100%; background-size: 40px; background-repeat: no-repeat; background-color: #272822; margin-bottom: -7px; border-radius: 5px; background-position: 10px 10px;"></span><code class="hljs" style="overflow-x: auto; padding: 16px; color: #ddd; display: -webkit-box; font-family: Operator Mono, Consolas, Monaco, Menlo, monospace; font-size: 12px; -webkit-overflow-scrolling: touch; letter-spacing: 0px; padding-top: 15px; background: #272822; border-radius: 5px;"><span class="hljs-selector-tag" style="color: #f92672; font-weight: bold; line-height: 26px;">sinterstore</span> <span class="hljs-selector-tag" style="color: #f92672; font-weight: bold; line-height: 26px;">destination</span> <span class="hljs-selector-tag" style="color: #f92672; font-weight: bold; line-height: 26px;">key1</span> <span class="hljs-selector-tag" style="color: #f92672; font-weight: bold; line-height: 26px;">key2</span><br/><span class="hljs-selector-tag" style="color: #f92672; font-weight: bold; line-height: 26px;">sunionstore</span> <span class="hljs-selector-tag" style="color: #f92672; font-weight: bold; line-height: 26px;">destination</span> <span class="hljs-selector-tag" style="color: #f92672; font-weight: bold; line-height: 26px;">key1</span> <span class="hljs-selector-tag" style="color: #f92672; font-weight: bold; line-height: 26px;">key2</span><br/><span class="hljs-selector-tag" style="color: #f92672; font-weight: bold; line-height: 26px;">sdiffstore</span> <span class="hljs-selector-tag" style="color: #f92672; font-weight: bold; line-height: 26px;">destination</span> <span class="hljs-selector-tag" style="color: #f92672; font-weight: bold; line-height: 26px;">key1</span> <span class="hljs-selector-tag" style="color: #f92672; font-weight: bold; line-height: 26px;">key2</span><br/></code>
 Cas : Nous devons rechercher des informations auprès d'un ami commun. Par exemple, le nombre d'amis suivis conjointement sur les comptes publics WeChat, le mécanisme de recommandation de QQ pour ajouter de nouveaux amis et l'exploration approfondie des contacts directs des utilisateurs
Cas : Nous devons rechercher des informations auprès d'un ami commun. Par exemple, le nombre d'amis suivis conjointement sur les comptes publics WeChat, le mécanisme de recommandation de QQ pour ajouter de nouveaux amis et l'exploration approfondie des contacts directs des utilisateurs
Sur la base des cas ci-dessus, nous pouvons utiliser des ensembles de différences pour réalisez les amis de QQ qui sont susceptibles de se connaître.
4-5 scénarios commerciaux de type défini pour implémenter l'enregistrement PV UV IP du site Web
PV utilise directement le type de chaîne incr les statistiques C'est-à-dire
UV et IP sont indépendants et non répétés, utilisez set pour fonctionner.
Nous savons ci-dessus que cet ensemble a une caractéristique qui ne peut pas être répété. Nous pouvons facilement implémenter cette fonction sur cette base. Utilisez ensuite la clé cicatrice pour compter la quantité.
Quant à UV en tant que visiteur indépendant, vous pouvez utiliser des cookies locaux pour y parvenir. De la même manière, transmettez le cookie à redis pour l'enregistrement 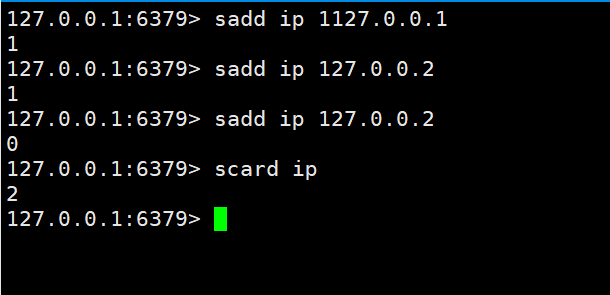
. 5. Le type sorted_set
ne prend pas en charge le tri parmi les quatre types précédents. Le type sorted_set que nous examinerons ci-dessous prend en charge à la fois le stockage du Big Data et le. fonction de tri
5-1 Opérations de base de type sorted_set
Ajouter des données : zadd key score member
Obtenir des données : zrange key start stop | zrevrange key start stop
Supprimer les données : zrem key member
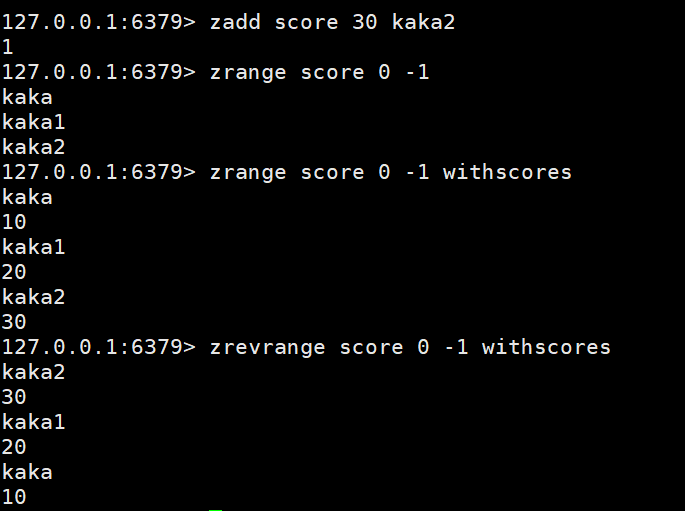 Obtenir les données par condition :
Obtenir les données par condition : zrangebyscore key min max limit | zrevrangescore key max min
Supprimer les données par condition : zremrangebyrank key start stop | zremrangebyscore key min max
Obtenir le montant total des données de collecte :zcard key | zcount key min max
Définir l'opération d'intersection et d'union : zinterstore destination numkeys key | zunionstore destination numkeys key(Cette commande ne sera pas démontrée, vous pouvez vérifier le document vous-même. Elle est similaire à définir, sauf que la somme de toutes les intersections sera additionné. Ensuite, il y a un paramètre numkeys ici, qui est un total de plusieurs clés pour le calcul (combien de clés seront nécessaires plus tard)
Obtenez l'index correspondant aux données : zrank key member | zrevrank key member
Acquisition et modification de la valeur Socre : zscore key member | zincrby key increment member
相关推荐:《<a href="https://www.php.cn/redis/" target="_blank">redis教程</a>》
Résumé
Ce qui précède est une brève introduction et une application spécifique du type de données redis. Dans l'article suivant, nous allons. mener des opérations pratiques en fonction de besoins spécifiques.
❝La persévérance dans l'apprentissage, la persévérance dans les blogs et la persévérance dans le partage sont les convictions auxquelles Kaka adhère depuis sa carrière. J'espère que les articles de Kaka dans l'immense Internet. peut vous apporter un peu d'aide Silk. A la prochaine fois
❞
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!