
Maison >base de données >Redis >Explication détaillée de la table de saut de la structure de données Redis
Explication détaillée de la table de saut de la structure de données Redis

- 藏色散人avant
- 2020-08-28 11:55:532705parcourir
La colonne suivante du Tutoriel Redis vous donnera une explication détaillée de la table de saut de la structure de données Redis. J'espère qu'elle sera utile aux amis dans le besoin !

Préface
Une liste de sauts est une structure de données ordonnée qui maintient plusieurs pointeurs vers d'autres nœuds dans chaque nœud pour atteindre l'objectif d'accéder rapidement aux nœuds. De cette façon, cela peut être difficile pour nous de comprendre, nous pouvons d'abord rappeler la liste chaînée.
1. Examen de la table de sauts
1.1 Qu'est-ce qu'une table de sauts
Pour une liste chaînée unique, même si les données stockées dans la liste chaînée sont ordonnées, si nous souhaitez y trouver certaines données, vous ne pouvez parcourir la liste chaînée que du début à la fin. De cette façon, l'efficacité de la recherche sera très faible et la complexité temporelle sera très élevée, ce qui est O(n).
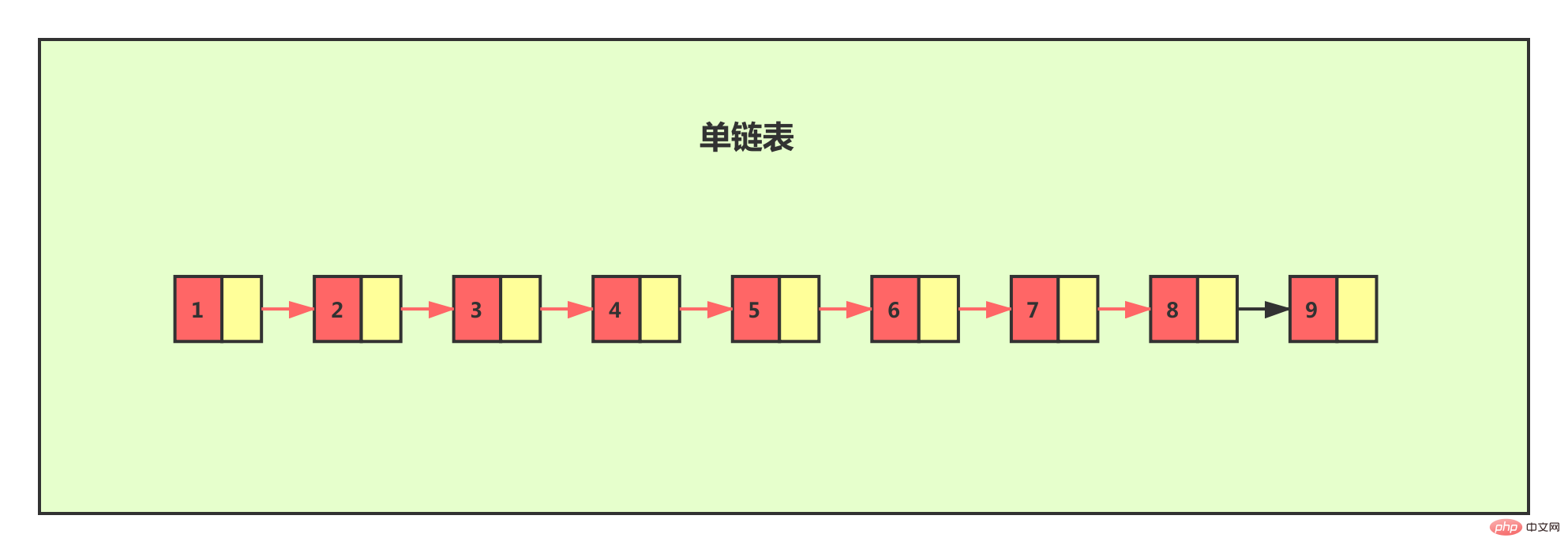
Si nous souhaitons améliorer son efficacité de recherche, nous pouvons envisager de construire un index sur la liste chaînée. Extrayez un nœud tous les deux nœuds jusqu'au niveau précédent, et nous appelons le niveau extrait l'index. 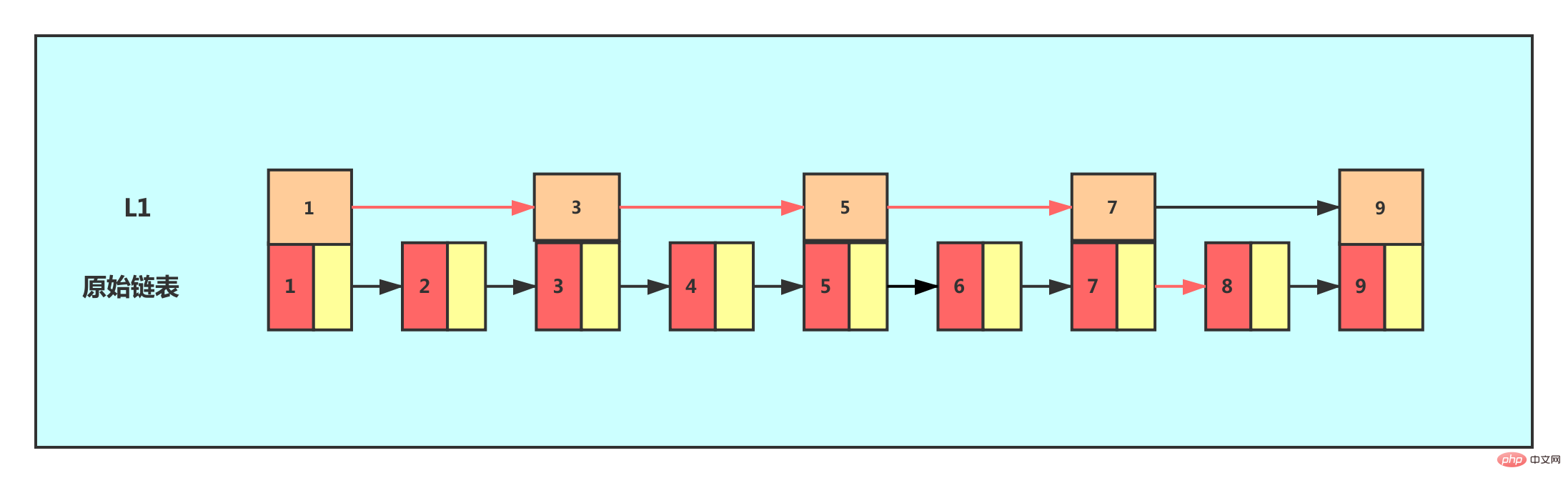
À ce stade, nous supposons que nous voulons trouver le nœud 8. Nous pouvons d'abord traverser dans la couche d'index. Lorsque nous traversons vers le nœud avec une valeur de 7 dans la couche d'index, nous trouvons. que le nœud suivant est 9, alors nous devons Le nœud 8 recherché doit être entre ces deux nœuds. Nous sommes descendus au niveau de la liste chaînée et avons continué à parcourir pour trouver le nœud 8. À l'origine, nous devions parcourir 8 nœuds pour trouver le nœud 8 dans une liste à chaînage unique, mais maintenant, avec l'index de premier niveau, nous n'avons besoin de parcourir que cinq nœuds.
À partir de cet exemple, nous pouvons voir qu'après l'ajout d'une couche d'index, le nombre de nœuds à parcourir pour trouver un nœud est réduit, ce qui signifie que l'efficacité de la recherche est améliorée de la même manière. , un autre niveau est ajouté.
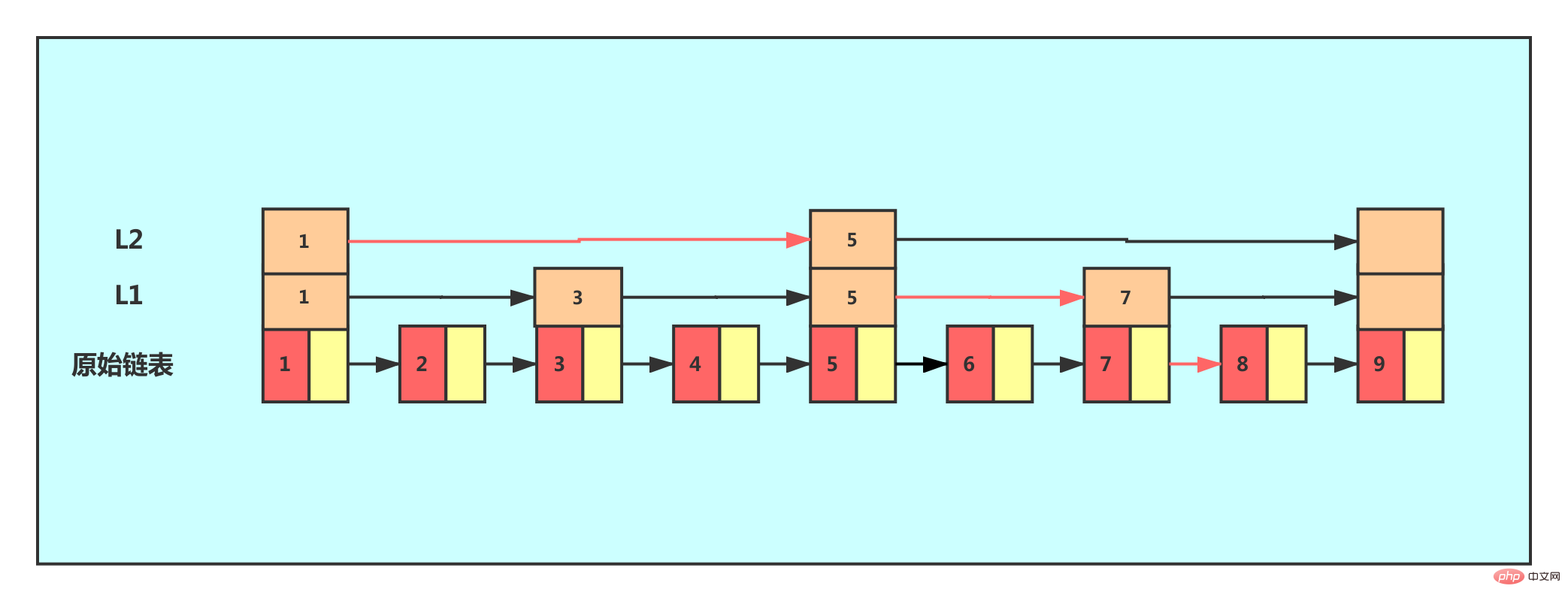
Sur la photo, nous pouvons voir que l'efficacité de la recherche s'est encore améliorée. Dans notre exemple, nous avons très peu de données. Lorsqu'il y a une grande quantité de données, nous pouvons ajouter des index multi-niveaux et l'efficacité de la recherche peut être considérablement améliorée.
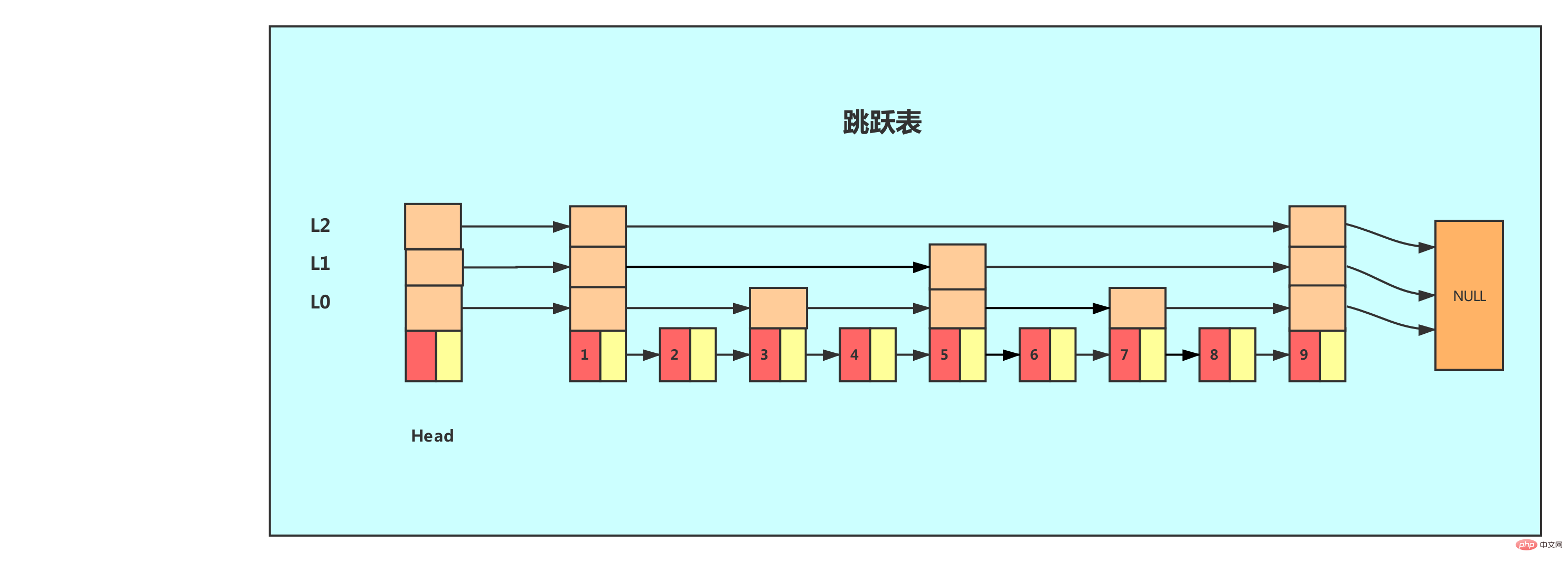
Une structure comme cette liste chaînée plus un index multi-niveaux est une liste de sauts !
2. Table de saut Redis
Redis utilise la table de saut comme l'une des implémentations sous-jacentes des clés d'ensemble ordonnées si un ensemble ordonné contient un grand nombre de éléments, ou lorsque le membre d'un élément dans un ensemble ordonné est une chaîne relativement longue , Redis utilisera une liste de raccourcis comme implémentation sous-jacente de la clé de l'ensemble ordonné.
Ici, nous devons réfléchir à une question : pourquoi Redis utilise-t-il une table de saut pour l'implémenter lorsqu'il y a un grand nombre d'éléments ou que les membres sont des chaînes relativement longues ? De ce qui précède, nous pouvons savoir que la liste de sauts ajoute un index multi-niveaux à la liste chaînée pour améliorer l'efficacité de la recherche, mais c'est une solution espace-temps, qui entraînera inévitablement un problème - l'index est Il prend de la mémoire. La liste chaînée d'origine peut stocker des objets très volumineux, mais le nœud d'index n'a besoin de stocker que des valeurs clés et quelques pointeurs, et n'a pas besoin de stocker des objets. Par conséquent, lorsque le nœud lui-même est relativement grand ou que le nombre d'éléments l'est. relativement grand, son avantage est qu'il sera inévitablement amplifié, tandis que ses inconvénients peuvent être ignorés. 2.1 Implémentation de skip table dans Redis La table skip de Redis est définie par deux structures, Explication détaillée de la table de saut de la structure de données Redis et skiplist La structure Explication détaillée de la table de saut de la structure de données Redis est utilisée pour représenter le nœud de table skip, tandis que la structure zskiplist. est utilisé pour enregistrer les sauts. Informations relatives aux nœuds de la table, telles que le nombre de nœuds, les pointeurs vers le nœud principal et le nœud final, etc.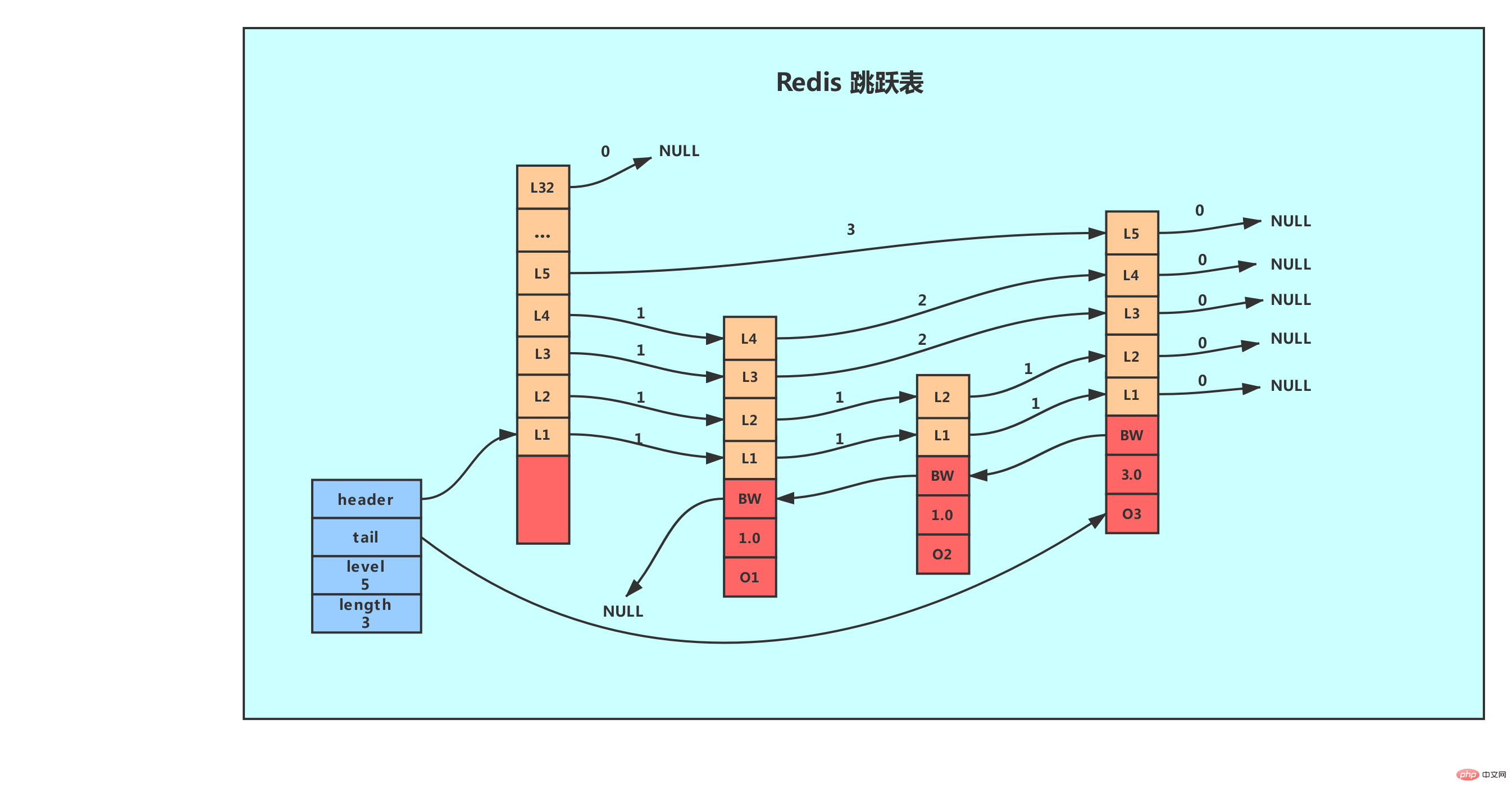
- en-tête : pointe vers le nœud d'en-tête de la table de saut. La complexité temporelle de la localisation du nœud d'en-tête via ce programme de pointeur est O(1)
- queue : pointe vers le nœud de queue de la table de saut. La complexité temporelle de la localisation du nœud de queue de la table via ce programme de pointeur est O(1)
- niveau : enregistrements. la table de saut actuelle, le nombre de couches du nœud avec le plus grand nombre de couches (le nombre de couches du nœud d'en-tête n'est pas inclus). Grâce à cet attribut, le nombre de couches du nœud avec la meilleure hauteur de couche peut être). obtenu en complexité temporelle O(1).
-
longueur : enregistrez la longueur de la table de sauts, c'est-à-dire le nombre de nœuds actuellement contenus dans la table de sauts (les nœuds principaux ne sont pas inclus). Grâce à cet attribut, le programme peut être O(). 1) Renvoie la longueur de la liste de sauts en complexité temporelle. Sur le côté droit de la structure
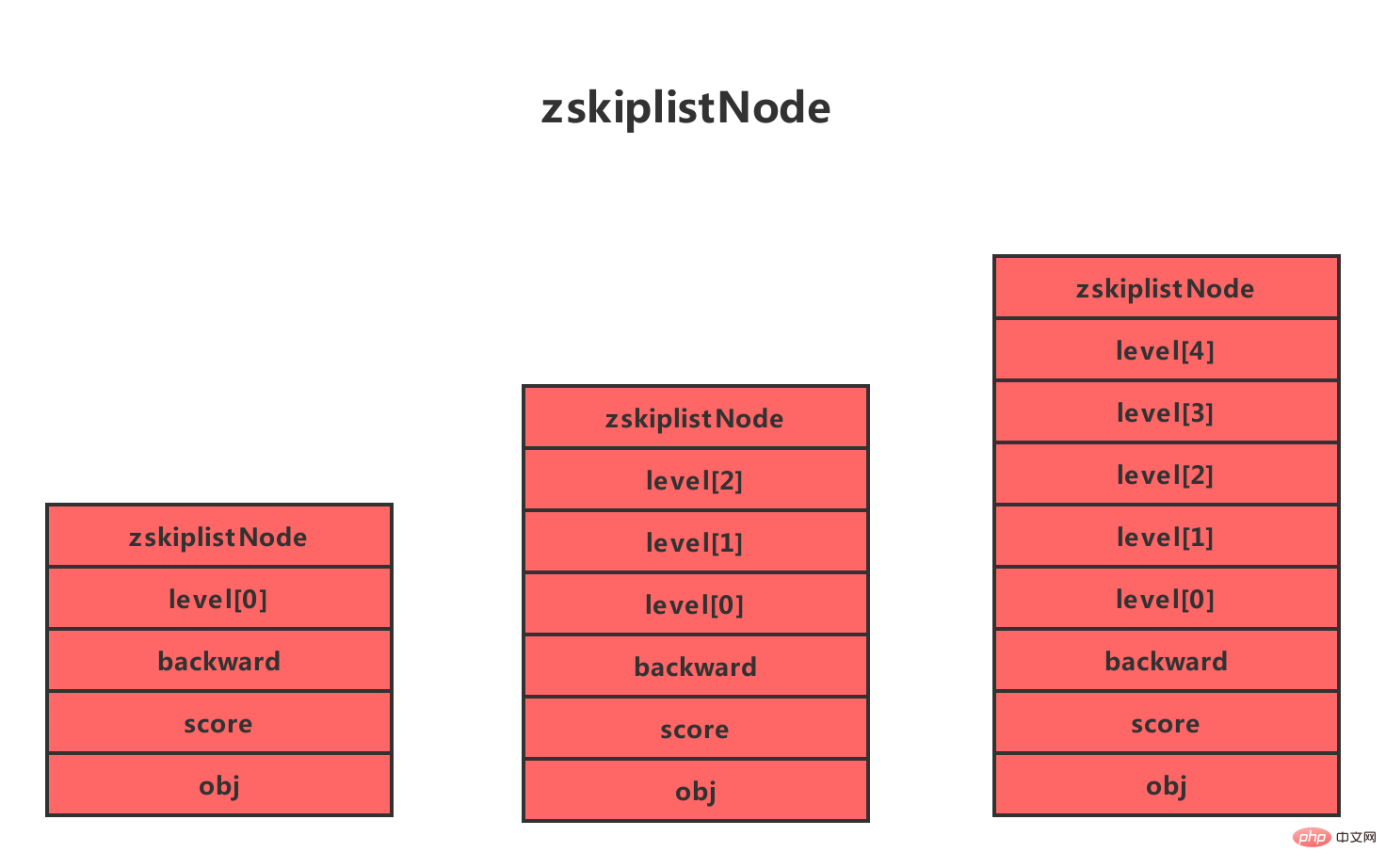
se trouvent quatre structures Explication détaillée de la table de saut de la structure de données Redis, qui contiennent les attributs suivants :
-
Niveau :
Utilisez 1, 2 dans le Les nœuds, L3 et d'autres mots marquent chaque couche du nœud, L1 représente la première couche, L représente la deuxième couche, et ainsi de suite.
Chaque couche a deux attributs : le pointeur vers l'avant et la durée. Le pointeur avant est utilisé pour accéder aux autres nœuds situés à la fin du tableau, tandis que le span enregistre la distance entre le nœud pointé par le pointeur avant et le nœud actuel (plus le span est grand, plus la distance est grande). Dans l'image ci-dessus, la flèche avec un numéro sur la ligne de connexion représente le pointeur vers l'avant, et ce numéro est la durée. Lorsque le programme parcourt le début du tableau jusqu'à la fin du tableau, l'accès se fera le long du pointeur vers l'avant de la couche.
Chaque fois qu'un nouveau nœud de table de saut est créé, le programme génère aléatoirement une valeur comprise entre 1 et 32 comme niveau basé sur la loi de puissance (loi de puissance, plus le nombre est grand, plus la probabilité d'occurrence est faible). taille du tableau, cette taille est la "hauteur" du calque.
-
Pointeur arrière :
Le pointeur arrière du nœud marqué par BW dans le nœud pointe vers le nœud précédent situé au nœud actuel. Le pointeur arrière est utilisé lorsque le programme passe de la fin du tableau au début. La différence avec le pointeur avant est que chaque nœud n'a qu'un seul pointeur vers l'arrière, il ne peut donc reculer que d'un nœud à la fois.
-
Score :
1.0, 2.0 et 3.0 dans chaque nœud sont les scores enregistrés par le nœud. Dans le tableau des sauts, les nœuds sont classés du plus petit au plus grand en fonction de leurs scores enregistrés.
-
Objet membre (oj) :
Les o1, o2 et o3 de chaque nœud sont les objets membres enregistrés par le nœud. Dans la même table de sauts, les objets membres enregistrés par chaque nœud doivent être uniques, mais les scores enregistrés par plusieurs nœuds peuvent être les mêmes : les nœuds avec le même score seront triés en fonction de la taille des objets membres par ordre lexicographique. les nœuds avec des objets membres plus petits seront disposés à l'avant (direction la plus proche de la tête de la table), tandis que les nœuds avec des objets membres plus grands seront disposés à l'arrière (direction la plus proche de la fin de la table).
2.2 Complexité temporelle des opérations courantes dans la table de saut Redis
| 操作 | 时间复杂度 |
|---|---|
| 创建一个Explication détaillée de la table de saut de la structure de données Redis | O(1) |
| 释放给定Explication détaillée de la table de saut de la structure de données Redis以及其中包含的节点 | O(N) |
| 添加给定成员和分值的新节点 | 平均O(logN),最坏O(logN)(N为Explication détaillée de la table de saut de la structure de données Redis的长度) |
| 删除除Explication détaillée de la table de saut de la structure de données Redis中包含给定成员和分值的节点 | 平均O(logN),最坏O(logN)(N为Explication détaillée de la table de saut de la structure de données Redis的长度) |
| 返回给定成员和分值的节点再表中的排位 | 平均O(logN),最坏O(logN)(N为Explication détaillée de la table de saut de la structure de données Redis的长度) |
| 返回在给定排位上的节点 | 平均O(logN),最坏O(logN)(N为Explication détaillée de la table de saut de la structure de données Redis的长度) |
| 给定一个分值范围,返回Explication détaillée de la table de saut de la structure de données Redis中第一个符合这个范围的节点 | O(1) |
| 给定一个分值范围,返回Explication détaillée de la table de saut de la structure de données Redis中最后一个符合这个范围的节点 | 平均O(logN),最坏O(logN)(N为Explication détaillée de la table de saut de la structure de données Redis的长度) |
| 给定一个分值范围,除Explication détaillée de la table de saut de la structure de données Redis中所有在这个范围之内的节点 | 平均O(logN),最坏O(logN)(N为Explication détaillée de la table de saut de la structure de données Redis的长度) |
| 给定一个排位范围,鼎除Explication détaillée de la table de saut de la structure de données Redis中所有在这个范围之内的节点 | O(N),N为被除节点数量 |
| 给定一个分值范固(range),比如0到15,20到28,诸如此类,如果跳氏表中有至少一个节点的分值在这个范間之内,那么返回1,否则返回0 | O(N),N为被除节点数量 |
Les points clés de cet article
- La table de sauts est implémentée sur la base d'une liste à chaînage unique plus un index
- La table de sauts améliore la vitesse de recherche en échangeant de l'espace contre du temps
- Redis a L'ensemble de séquences utilise une liste à sauter lorsque les éléments du nœud sont grands ou que le nombre d'éléments est grand
- L'implémentation de la liste à sauter de Redis se compose de deux structures, zskiplist et zskiplistnode, où zskiplist est utilisé pour enregistrer les informations de saut de table (telles que les nœuds d'en-tête, le nœud de queue de table, la longueur), et zskiplistnode est utilisé pour représenter le nœud de liste de sauts
- La hauteur de couche de chaque nœud de liste de sauts Redis est un nombre aléatoire compris entre 1 et 32
- dans le même Dans la table de sauts, plusieurs nœuds peuvent contenir le même score, mais l'objet membre de chaque nœud doit être unique. Les nœuds de la table de sauts sont triés en fonction de la taille du score. Lorsque les scores sont identiques, les nœuds sont triés en fonction de la taille de l'objet membre Tri.
Résumé
La table de saut peut être une structure de données légèrement inconnue pour nous. Cet article présente brièvement la structure des données de la table de saut et analyse l'utilisation de la table de saut dans Redis. Le prochain article continuera à partager la collection d'entiers de structure de données utilisée dans Redis. Restez à l'écoute !
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!