
Maison >Problème commun >La dernière version des 68 questions d'entretien Redis 2023 (collection)
La dernière version des 68 questions d'entretien Redis 2023 (collection)

- coldplay.xixioriginal
- 2020-08-05 15:49:0911470parcourir
L'article est trop long, il est recommandé de le sauvegarder d'abord et de le lire lentement !
Redis (Remote Dictionary Server) est une base de données clé-valeur open source (sous licence BSD) hautes performances non relationnelle (NoSQL) écrite en langage C.

Redis peut stocker des mappages entre les clés et cinq types de valeurs différents. Le type de clé ne peut être qu'une chaîne et seuls cinq types de données sont pris en charge : chaîne, liste, ensemble, table de hachage et ensemble ordonné.
Contrairement aux bases de données traditionnelles, les données Redis sont stockées en mémoire, la vitesse de lecture et d'écriture est donc très rapide. Par conséquent, Redis est largement utilisé dans le sens du cache et peut gérer plus de 100 000 lectures et écritures. par seconde, il s'agit de la base de données clé-valeur la plus rapide connue. De plus, Redis est également souvent utilisé pour les verrous distribués. De plus, Redis prend en charge les transactions, la persistance, les scripts LUA, les événements pilotés par LRU et diverses solutions de cluster.

Aujourd'hui, parlons des questions d'entretien Redis pour préparer l'entretien après la reprise du travail.
1. Présentation
1. Quels sont les avantages et les inconvénients de Redis
Avantages
Performances de lecture et d'écriture Excellentes, Redis peut lire à une vitesse de 110 000 fois/s et écrire à une vitesse de 81 000 fois/s.
Prend en charge la persistance des données et prend en charge deux méthodes de persistance : AOF et RDB.
Prend en charge les transactions. Toutes les opérations de Redis sont atomiques. En même temps, Redis prend également en charge l'exécution atomique après la fusion de plusieurs opérations.
Structures de données riches, en plus de prendre en charge la valeur de type chaîne, il prend également en charge les structures de hachage, set, zset, list et autres.
Prend en charge la réplication maître-esclave. L'hôte synchronisera automatiquement les données avec l'esclave, permettant la séparation en lecture et en écriture.
Inconvénients
La capacité de la base de données est limitée par la mémoire physique et ne peut pas être utilisée pour une lecture et une écriture hautes performances de données massives. Par conséquent, les scénarios adaptés à Redis sont les suivants. principalement limité à de petites quantités de données. Opérations et calculs hautes performances.
Redis n'a pas de fonctions automatiques de tolérance aux pannes et de récupération. Le temps d'arrêt des machines hôtes et esclaves entraînera l'échec de certaines requêtes de lecture et d'écriture frontales. Vous devez attendre que la machine redémarre ou bascule manuellement. l'adresse IP frontale à récupérer.
La machine hôte est en panne. Certaines données n'ont pas pu être synchronisées avec la machine esclave à temps avant que la machine ne tombe en panne. Après le changement d'IP, une incohérence des données sera introduite, ce qui réduit la disponibilité du système.
Redis est difficile à prendre en charge l'expansion en ligne. Lorsque la capacité du cluster atteint la limite supérieure, l'expansion en ligne deviendra très compliquée. Pour éviter ce problème, le personnel d'exploitation et de maintenance doit s'assurer qu'il y a suffisamment d'espace lorsque le système est mis en ligne, ce qui entraîne un gaspillage important de ressources.
2. Pourquoi utiliser Redis/Pourquoi utiliser le cache
Nous examinons principalement ce problème sous les deux points de « haute performance » et de « haute simultanéité ».
Hautes performances :
Si l'utilisateur accède à certaines données de la base de données pour la première fois. Ce processus sera plus lent car il est lu à partir du disque dur. Stockez les données consultées par l'utilisateur dans le cache, de sorte que lors du prochain accès aux données, elles puissent être obtenues directement à partir du cache. Le cache d'opération consiste à faire fonctionner directement la mémoire, donc la vitesse est assez rapide. Si les données correspondantes dans la base de données changent, modifiez simplement les données correspondantes dans le cache de manière synchrone !
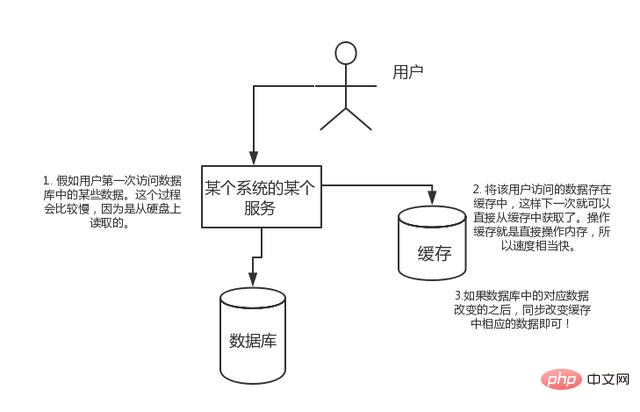
Concurrence élevée :
Les demandes auxquelles le cache d'opération directe peut résister sont bien supérieures à l'accès direct à la base de données, on peut donc envisager de transférer certaines données de la base de données vers le cache, afin que certaines requêtes de l'utilisateur aillent directement dans le cache sans passer par la base de données.
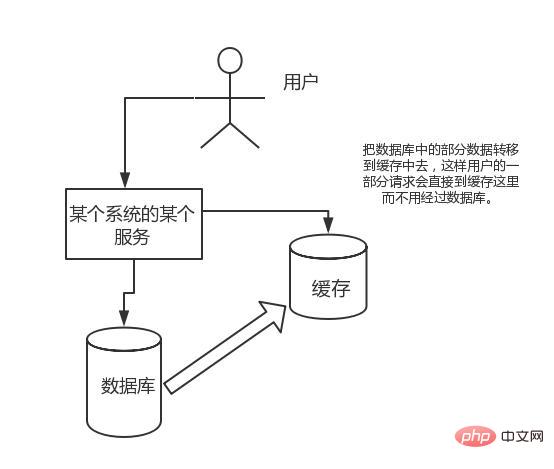
3. Pourquoi utiliser Redis au lieu de map/guava pour la mise en cache ?
Le cache est divisé en cache local et cache distribué. En prenant Java comme exemple, la mise en cache locale est implémentée à l'aide de la carte intégrée ou de la goyave. Les principales fonctionnalités sont légères et rapides. Le cycle de vie se termine par la destruction de la machine virtuelle Java et, dans le cas de plusieurs instances, de chaque cache. doit être sauvegardé et le cache n'est pas cohérent.
L'utilisation de redis ou memcached est appelée cache distribué. Dans le cas de plusieurs instances, chaque instance partage un cache de données, et le cache est cohérent. L'inconvénient est que le service Redis ou Memcached doit rester hautement disponible et que l'ensemble de l'architecture du programme est relativement complexe.
4. Pourquoi Redis est-il si rapide
1) Entièrement basées sur la mémoire, la plupart des requêtes sont des opérations de mémoire pure, très rapides. Les données sont stockées en mémoire, comme HashMap. L'avantage de HashMap est que la complexité temporelle de la recherche et de l'opération est O(1)
2) La structure des données est simple et l'opération des données l'est également. simple.La structure des données dans Redis Il est spécialement conçu
3) L'utilisation d'un seul thread évite les changements de contexte inutiles et les conditions de concurrence, et il n'est pas nécessaire de basculer entre plusieurs processus ou threads pour consommer le processeur. Il n'est pas nécessaire de prendre en compte divers problèmes de verrouillage, et il n'est pas nécessaire de le faire. opération de verrouillage ou de libération des verrous, il n'y a pas de consommation de performances causée par un éventuel blocage ;
4) Utiliser un modèle de multiplexage d'E/S multicanal, IO non bloquante
5 utiliser différents sous-jacents ; Modèles.La méthode d'implémentation sous-jacente et le protocole d'application pour la communication avec le client sont différents.Redis construit directement son propre mécanisme de VM, car si le système général appelle les fonctions système, il perdra un certain temps à se déplacer et à demander ; >
2. Types de données5. Quels types de données Redis possède-t-il
Redis a 5 types de données principaux, dont String, List, Set, Zset ? , et Hash, qui peuvent satisfaire la plupart des utilisateurs
6. Résumé 1
Compteur : Vous pouvez effectuer des opérations d'incrémentation et de décrémentation sur String pour réaliser la fonction de compteur. Redis, une base de données en mémoire, offre des performances de lecture et d'écriture très élevées et est très adaptée au stockage des décomptes de lectures et d'écritures fréquentes.
Cache : mettez les données chaudes en mémoire, définissez l'utilisation maximale de la mémoire et la stratégie d'élimination pour garantir le taux de réussite du cache.
Cache de session : Redis peut être utilisé pour stocker uniformément les informations de session de plusieurs serveurs d'applications. Lorsque le serveur d'applications ne stocke plus les informations de session de l'utilisateur, il n'a plus d'état. Un utilisateur peut demander n'importe quel serveur d'applications, ce qui facilite l'obtention d'une haute disponibilité et d'une évolutivité.
Cache pleine page (FPC) : En plus des jetons de session de base, Redis fournit également une plate-forme FPC très simple. En prenant Magento comme exemple, Magento fournit un plugin pour utiliser Redis comme backend de cache pleine page. De plus, pour les utilisateurs de WordPress, Pantheon dispose d’un très bon plug-in wp-redis, qui pourra vous aider à charger le plus rapidement possible les pages que vous avez parcourues.
Table de recherche : Par exemple, les enregistrements DNS conviennent au stockage à l'aide de Redis. La table de recherche est similaire au cache et profite également de la fonctionnalité de recherche rapide de Redis. Mais le contenu de la table de recherche ne peut pas être invalidé, alors que le contenu du cache peut être invalidé, car le cache ne sert pas de source de données fiable.
File d'attente des messages (fonction de publication/abonnement) : La liste est une liste doublement chaînée qui peut écrire et lire des messages via lpush et rpop. Cependant, il est préférable d’utiliser des middlewares de messagerie tels que Kafka et RabbitMQ.
Implémentation de verrous distribués : Dans un scénario distribué, les verrous dans un environnement autonome ne peuvent pas être utilisés pour synchroniser des processus sur plusieurs nœuds. Vous pouvez utiliser la commande SETNX fournie avec Redis pour implémenter des verrous distribués. De plus, vous pouvez également utiliser l'implémentation de verrouillage distribué RedLock officiellement fournie.
Autres : Set peut mettre en œuvre des opérations telles que l'intersection et l'union, réalisant ainsi des fonctions telles que des amis communs. ZSet peut implémenter des opérations ordonnées pour réaliser des fonctions telles que des classements.
Résumé 2
Redis a un très gros avantage par rapport aux autres caches, c'est-à-dire qu'il prend en charge plusieurs types de données.Chaîne de chaîne de description du type de données, le format de hachage de stockage k-v le plus simple, la valeur est un champ et une valeur, adaptée aux scénarios tels que ID-Detail. list est une liste simple, une liste séquentielle, prend en charge l'insertion de données à la première ou à la dernière position, une liste non ordonnée, une vitesse de recherche rapide, adaptée au traitement des intersections, des unions et des différences ensemble trié ensemble ordonné
En fait, via les données ci-dessus Sur la base des caractéristiques du type, vous pouvez essentiellement penser à des scénarios d'application appropriés. chaîne - adaptée au stockage k-v le plus simple, similaire à la structure de stockage memcached, au code de vérification SMS, aux informations de configuration, etc., utilisez ce type pour stocker.hash
- Généralement la clé est un identifiant ou un identifiant unique, et la valeur correspond aux détails. Tels que les détails du produit, les informations personnelles, les actualités, etc.list - Parce que la liste est ordonnée, elle est plus adaptée au stockage de certaines données ordonnées et relativement fixes. Tels que le tableau des provinces et des villes, le tableau du dictionnaire, etc. Étant donné que la liste est ordonnée, elle peut être triée en fonction de l'heure d'écriture, telle que : les derniers ***, la file d'attente des messages, etc.
ensemble - peut être simplement compris comme un modèle de liste d'identification, par exemple les amis qu'une personne a sur Weibo. La meilleure chose à propos de l'ensemble est qu'il peut fournir une intersection entre deux ensembles, opérations d’union et de différence. Par exemple : Trouver des amis communs entre deux personnes, etc.
Ensemble trié - est une version améliorée de l'ensemble, ajoutant un paramètre de score, qui triera automatiquement en fonction de la valeur du score. Il est plus adapté aux données telles que le top 10 qui ne sont pas triées en fonction du temps d'insertion.
Comme mentionné ci-dessus, bien que Redis ne soit pas une structure de données aussi complexe qu'une base de données relationnelle, il peut également convenir à de nombreux scénarios, y compris plus que les structures de données de cache générales. Comprendre les scénarios commerciaux adaptés à chaque structure de données contribuera non seulement à améliorer l'efficacité du développement, mais également à utiliser efficacement les performances de Redis.3. Persistance
7. Qu'est-ce que la persistance Redis ?
La persistance consiste à écrire les données de mémoire sur le disque pour éviter que les données de mémoire ne soient perdues lorsque le service tombe en panne.8. Quel est le mécanisme de persistance de Redis ? Quels sont les avantages et les inconvénients de chacun ?
Redis fournit deux mécanismes de persistance RDB (par défaut) et AOF :
RDB : est l'abréviation de Redis DataBase snapshot
RDB Il s'agit de la méthode de persistance par défaut de Redis. Les données de la mémoire sont enregistrées sur le disque dur sous la forme d'un instantané selon une certaine période de temps, et le fichier de données correspondant généré est dump.rdb. La période d'instantané est définie via le paramètre save dans le fichier de configuration.
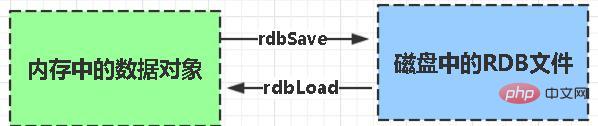
Avantages :
1 Il n'y a qu'un seul fichier dump.rdb, ce qui est pratique pour la persistance.
2. Bonne tolérance aux catastrophes, un fichier peut être enregistré sur un disque sécurisé.
3. Pour maximiser les performances, forkez le processus enfant pour terminer l'opération d'écriture et laissez le processus principal continuer à traiter les commandes, afin que les E/S soient maximisées. Utilisez un sous-processus distinct pour la persistance, et le processus principal n'effectuera aucune opération d'E/S, garantissant les hautes performances de redis
4 Lorsque l'ensemble de données est volumineux, l'efficacité de démarrage est supérieure à AOF.
Inconvénients :
1. Faible sécurité des données. RDB est conservé à intervalles réguliers. Si Redis échoue entre les persistances, une perte de données se produira. Par conséquent, cette méthode est plus adaptée lorsque les exigences en matière de données ne sont pas strictes)
2. Méthode de persistance AOF (Append-only file) : fait référence à tous les enregistrements de ligne de commande stockés de manière complètement persistante au format de la commande redis. request protocol ) est enregistré sous forme de fichier aof.
AOF : Persistance
La persistance AOF (c'est-à-dire la persistance Append Only File) enregistre chaque commande d'écriture exécutée par Redis dans un fichier journal distinct, lorsque vous redémarrez Redis, les données dans les fichiers journaux persistants seront restaurés.
Lorsque les deux méthodes sont activées en même temps, la récupération de données Redis donnera la priorité à la récupération AOF.
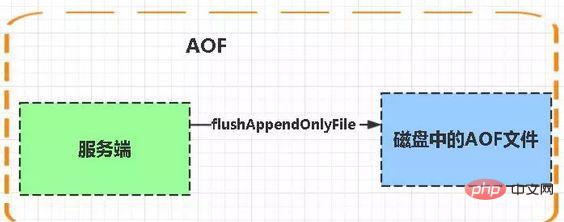
Avantages :
1 La sécurité des données, la persistance peut être configurée avec l'attribut appendfsync, toujours, à chaque opération de commande. est effectué. Enregistrez-le simplement dans le fichier aof une fois.
2. Écrivez des fichiers en mode ajout. Même si le serveur tombe en panne au milieu, vous pouvez utiliser l'outil redis-check-aof pour résoudre le problème de cohérence des données.
3. Le mode de réécriture du mécanisme AOF. Avant que le fichier AOF ne soit réécrit (les commandes seront fusionnées et réécrites lorsque le fichier est trop volumineux), vous pouvez supprimer certaines commandes (comme flushall par erreur))
Inconvénients :
1. Les fichiers AOF sont plus volumineux que les fichiers RDB et la vitesse de récupération est lente.
2. Lorsque l'ensemble de données est volumineux, l'efficacité du démarrage est inférieure à celle de rdb.
Quels sont les avantages et les inconvénients ?
Les fichiers AOF sont mis à jour plus fréquemment que RDB, donc AOF est utilisé en premier pour restaurer les données.
AOF est plus sûr et plus grand que RDB
Les performances de RDB sont meilleures que AOF
Si les deux sont configurés, AOF est chargé en premier
9 , Comment choisir la méthode de persistance appropriée
De manière générale, si vous souhaitez obtenir une sécurité des données comparable à PostgreSQL, vous devez utiliser les deux fonctions de persistance en même temps. Dans ce cas, au redémarrage de Redis, le fichier AOF sera chargé en premier pour restaurer les données d'origine, car dans des circonstances normales, l'ensemble de données enregistré par le fichier AOF est plus complet que l'ensemble de données enregistré par le fichier RDB.
Si vous vous souciez profondément de vos données mais que vous pouvez toujours vous permettre une perte de données en quelques minutes, vous pouvez simplement utiliser la persistance RDB.
De nombreux utilisateurs utilisent uniquement la persistance AOF, mais cette méthode n'est pas recommandée car la génération régulière d'instantanés RDB est très pratique pour la sauvegarde de la base de données, et RDB restaure les ensembles de données plus rapidement que la restauration AOF. De plus, l'utilisation de RDB est plus rapide. peut également éviter les bugs dans les programmes AOF.
Si vous souhaitez que vos données existent uniquement pendant que le serveur est en cours d'exécution, vous ne pouvez pas non plus utiliser de méthode de persistance.
10. Comment étendre les données persistantes et le cache Redis ?
Si Redis est utilisé comme cache, utilisez un hachage cohérent pour obtenir une expansion et une contraction dynamiques.
Si Redis est utilisé comme stockage persistant, une relation de mappage clés-nœuds fixe doit être utilisée et le nombre de nœuds ne peut pas être modifié une fois déterminé. Sinon (c'est-à-dire lorsque les nœuds Redis doivent changer dynamiquement), un système capable de rééquilibrer les données au moment de l'exécution doit être utilisé, et actuellement seul le cluster Redis peut le faire.
4. Liés à la mémoire
14. Il y a 20 millions de données dans MySQL, mais seulement 200 000 données sont stockées dans Redis. Comment s'assurer que les données dans Redis sont des données chaudes ?
Lorsque la taille de l'ensemble de données de la mémoire Redis augmente jusqu'à une certaine taille, la stratégie d'élimination des données sera mise en œuvre.
15. Quelles sont les stratégies d'élimination de mémoire pour Redis ?
La stratégie d'élimination de la mémoire de Redis fait référence à la façon de gérer les données qui doivent être nouvellement écrites et nécessitent une application d'espace supplémentaire lorsque la mémoire de Redis pour la mise en cache est insuffisante.
Suppression globale sélective de l'espace clé
noeviction : lorsque la mémoire n'est pas suffisante pour accueillir les données nouvellement écrites, la nouvelle opération d'écriture signalera une erreur.
allkeys-lru : Lorsque la mémoire est insuffisante pour accueillir les données nouvellement écrites, dans l'espace clé, supprimez la clé la moins récemment utilisée. (C'est le plus couramment utilisé)
allkeys-random : Lorsque la mémoire est insuffisante pour accueillir les données nouvellement écrites, une clé est supprimée de manière aléatoire de l'espace clé.
Suppression sélective de l'espace clé avec délai d'expiration défini
volatile-lru : lorsque la mémoire n'est pas suffisante pour accueillir les données nouvellement écrites, dans le espace clé avec un délai d’expiration défini, supprimez la clé la moins récemment utilisée.
volatile-aléatoire : Lorsque la mémoire est insuffisante pour accueillir les données nouvellement écrites, une clé est supprimée de manière aléatoire de l'espace clé avec un délai d'expiration défini.
volatile-ttl : Lorsque la mémoire est insuffisante pour accueillir les données nouvellement écrites, dans l'espace clé avec un délai d'expiration défini, les clés avec un délai d'expiration antérieur seront supprimées en premier.
Résumé
La sélection de la stratégie d'élimination de la mémoire de Redis n'affectera pas le traitement des clés expirées. La stratégie d'élimination de mémoire est utilisée pour gérer les données qui nécessitent de l'espace supplémentaire lorsque la mémoire est insuffisante ; la stratégie d'expiration est utilisée pour gérer les données mises en cache expirées.
16. Quelles ressources physiques Redis consomme-t-il principalement ?
Mémoire.
17. Que se passera-t-il si Redis manque de mémoire ?
Si la limite supérieure définie est atteinte, la commande d'écriture Redis renverra un message d'erreur (mais la commande de lecture peut toujours revenir normalement.) Ou vous pouvez configurer le mécanisme d'élimination de la mémoire, et Redis videra lorsqu'il atteint la limite supérieure de la mémoire. Ancien contenu.
18. Comment Redis optimise-t-il la mémoire ?
Vous pouvez faire bon usage des données de type collection telles que le hachage, la liste, l'ensemble trié, l'ensemble, etc., car généralement de nombreuses petites valeurs-clés peuvent être stockées ensemble de manière plus compacte . Utilisez les hachages autant que possible. Les tables de hachage (ce qui signifie que le nombre stocké dans une table de hachage est petit) utilisent très peu de mémoire, vous devez donc autant que possible résumer votre modèle de données dans une table de hachage. Par exemple, si vous avez un objet utilisateur dans votre système Web, ne définissez pas de clé distincte pour le nom, le prénom, l'adresse e-mail et le mot de passe de l'utilisateur. Stockez plutôt toutes les informations de l'utilisateur dans une table de hachage.
5. Modèle de thread
19. Modèle de thread Redis
Redis a développé un processeur d'événements réseau basé sur le mode Reactor. Gestionnaire d'événements de fichier. Sa structure est composée de 4 parties : plusieurs sockets, un multiplexeur IO, un répartiteur d'événements de fichiers et un processeur d'événements. Étant donné que la consommation de la file d'attente du répartiteur d'événements de fichier est monothread, Redis est appelé un modèle monothread.
Le gestionnaire d'événements de fichier utilise des procédures de multiplexage d'E/S (multiplexage) pour écouter plusieurs sockets en même temps et associer différents gestionnaires d'événements aux sockets en fonction des tâches actuellement effectuées par le périphérique sockets.
Lorsque le socket surveillé est prêt à effectuer des opérations telles que la réponse de connexion (accepter), la lecture (lire), l'écriture (écrire), la fermeture (fermer), etc., l'événement de fichier correspondant à l'opération sera se produisent, le gestionnaire d'événements de fichier appellera le gestionnaire d'événements précédemment associé au socket pour gérer ces événements.
Bien que le gestionnaire d'événements de fichier s'exécute dans un seul thread, en utilisant un multiplexeur d'E/S pour écouter plusieurs sockets, le gestionnaire d'événements de fichier implémente un modèle de communication réseau haute performance avec lequel il peut également être bien connecté. d'autres modules du serveur Redis qui s'exécutent également de manière monothread, ce qui préserve la simplicité de la conception monothread au sein de Redis.
6. Modèle de thread
19. Modèle de thread Redis
Redis a développé un processeur d'événements réseau basé sur le mode Reactor. Gestionnaire d'événements de fichier. Sa structure est composée de 4 parties : plusieurs sockets, un multiplexeur IO, un répartiteur d'événements de fichiers et un processeur d'événements. Étant donné que la consommation de la file d'attente du répartiteur d'événements de fichier est monothread, Redis est appelé un modèle monothread.
Le gestionnaire d'événements de fichier utilise des procédures de multiplexage d'E/S (multiplexage) pour écouter plusieurs sockets en même temps et associer différents gestionnaires d'événements aux sockets en fonction des tâches actuellement effectuées par le périphérique sockets.
Lorsque le socket surveillé est prêt à effectuer des opérations telles que la réponse de connexion (accepter), la lecture (lire), l'écriture (écrire), la fermeture (fermer), etc., l'événement de fichier correspondant à l'opération sera se produisent, le gestionnaire d'événements de fichier appellera le gestionnaire d'événements précédemment associé au socket pour gérer ces événements.
Bien que le gestionnaire d'événements de fichier s'exécute dans un seul thread, en utilisant un multiplexeur d'E/S pour écouter plusieurs sockets, le gestionnaire d'événements de fichier implémente un modèle de communication réseau haute performance avec lequel il peut également être bien connecté. d'autres modules du serveur Redis qui s'exécutent également de manière monothread, ce qui préserve la simplicité de la conception monothread au sein de Redis.
7. Affaires
20. Qu'est-ce qu'une transaction ?
Une transaction est une opération unique et isolée : toutes les commandes de la transaction sont sérialisées et exécutées dans l'ordre. Lors de l'exécution de la transaction, celle-ci ne sera pas interrompue par les demandes de commandes envoyées par d'autres clients.
Une transaction est une opération atomique : soit toutes les commandes de la transaction sont exécutées, soit aucune d'entre elles n'est exécutée.
21. Le concept de transaction Redis
L'essence des transactions Redis est un ensemble de commandes telles que MULTI, EXEC et WATCH. Les transactions prennent en charge l'exécution de plusieurs commandes à la fois, et toutes les commandes d'une transaction seront sérialisées. Pendant le processus d'exécution de la transaction, les commandes dans la file d'attente seront sérialisées et exécutées dans l'ordre, et les demandes de commandes soumises par d'autres clients ne seront pas insérées dans la séquence de commandes d'exécution de la transaction.
Pour résumer : une transaction Redis est une exécution unique, séquentielle et exclusive d'une série de commandes dans une file d'attente.
Trois étapes de la transaction Redis
La transaction démarre MULTI
Mise en file d'attente des commandes
Exécution de la transaction EXEC
Pendant le processus d'exécution de la transaction, si le serveur reçoit une requête autre que EXEC, DISCARD, WATCH et MULTI, il mettra la requête en file d'attente dans file d'attente.
23. Commandes liées aux transactions Redis
La fonction de transaction Redis est implémentée via quatre primitives : MULTI, EXEC, DISCARD et WATCH.
Redis sérialisera toutes les commandes d'une transaction, puis les exécutera dans l'ordre.
1) redis ne prend pas en charge la restauration, "Redis n'annule pas lorsqu'une transaction échoue, mais continue d'exécuter les commandes restantes", afin que les composants internes de Redis puissent rester simples et rapides.
2) Si une erreur se produit dans la commande dans une transaction, alors toutes les commandes ne seront pas exécutées
.3) Si dans Si une erreur d'exécution se produit dans une transaction, la commande correcte sera exécutée.
La commande WATCH est un verrou optimiste qui fournit un comportement de vérification et de définition (CAS) pour les transactions Redis. Une ou plusieurs clés peuvent être surveillées. Une fois l'une des clés modifiée (ou supprimée), les transactions suivantes ne seront pas exécutées et la surveillance se poursuit jusqu'à la commande EXEC.
La commande MULTI est utilisée pour démarrer une transaction, et elle renvoie toujours OK. Une fois MULTI exécuté, le client peut continuer à envoyer n'importe quel nombre de commandes au serveur. Ces commandes ne seront pas exécutées immédiatement, mais seront placées dans une file d'attente. Lorsque la commande EXEC est appelée, toutes les commandes de la file d'attente seront exécutées. .
EXEC : exécute des commandes dans tous les blocs de transaction. Renvoie les valeurs de retour de toutes les commandes du bloc de transaction, classées dans l'ordre d'exécution des commandes. Lorsque l'opération est interrompue, la valeur vide nil est renvoyée.
En appelant DISCARD, le client peut vider la file d'attente des transactions et abandonner l'exécution de la transaction, et le client quittera l'état de transaction.
La commande UNWATCH peut annuler la surveillance de toutes les touches par la montre.
24. Présentation de la gestion des transactions (ACID)
Atomicité : L'atomicité signifie qu'une transaction est une unité de travail indivisible, soit toutes les opérations dans la transaction se produisent ou aucun ne se produit.
Cohérence : L'intégrité des données avant et après la transaction doit être cohérente.
Isolement : Lorsque plusieurs transactions sont exécutées simultanément, l'exécution d'une transaction ne doit pas affecter l'exécution des autres transactions.
Durabilité : La durabilité signifie qu'une fois qu'une transaction est validée, ses modifications apportées aux données dans la base de données sont permanentes et les modifications ultérieures apportées aux données dans la base de données ne devraient pas se produire même si la base de données échoue. Cela a un impact
Les transactions Redis ont toujours une cohérence et une isolation ACID, les autres fonctionnalités ne sont pas prises en charge. Les transactions sont également durables lorsque le serveur s'exécute en mode de persistance AOF et que la valeur de l'option appendfsync est toujours.
25. La transaction Redis prend-elle en charge l'isolement ?
Redis est un programme à processus unique et il garantit que la transaction ne sera pas interrompue lors de l'exécution de la transaction. La transaction peut s'exécuter jusqu'à ce que toutes les commandes de la file d'attente des transactions soient exécutées. Par conséquent, les transactions Redis sont toujours isolées.
26. La transaction Redis garantit-elle l'atomicité et prend-elle en charge la restauration ?
Dans Redis, une seule commande est exécutée de manière atomique, mais il n'est pas garanti que les transactions soient atomiques et il n'y a pas de restauration. Si une commande de la transaction ne parvient pas à s'exécuter, les commandes restantes seront quand même exécutées.
27. Autres implémentations de transactions Redis
Basé sur les scripts Lua, Redis peut garantir que les commandes du script sont exécutées une fois et dans l'ordre, et ce n'est pas le cas. fournir l'exécution de la transaction en même temps. Annulation d'erreur. Si certaines commandes ne s'exécutent pas correctement pendant l'exécution, les commandes restantes continueront à s'exécuter
Sur la base de la variable de marque intermédiaire, une autre variable de marque est utilisée pour identifier si la transaction. est terminé.Lors de la lecture des données, lisez d'abord la variable de marque pour déterminer si l'exécution de la transaction est terminée. Mais cela nécessitera l’implémentation de code supplémentaire, ce qui est plus fastidieux.
8. Solution Cluster
28. Mode Sentinelle
Présentation de Sentinelle :
sentinelle, le nom chinois est sentinelle. Sentinel est un composant très important dans l'organisation du cluster redis. Il a principalement les fonctions suivantes :
Surveillance du cluster : Responsable de surveiller si les processus redis maître et esclave fonctionnent normalement.
Notification de message : Si une instance Redis échoue, la sentinelle est chargée d'envoyer des messages sous forme de notifications d'alarme à l'administrateur.
Failover : Si le nœud maître se bloque, il sera automatiquement transféré vers le nœud esclave.
Centre de configuration : en cas de basculement, informez le client de la nouvelle adresse principale.
Sentinel est utilisé pour atteindre la haute disponibilité du cluster Redis Il est également distribué et fonctionne comme un cluster sentinelle et fonctionne ensemble.
Lors du basculement, déterminer si un nœud maître est en panne nécessite le consentement de la majorité des sentinelles, ce qui implique la question de l'élection distribuée.
Même si certains nœuds sentinelles échouent, le cluster sentinelle peut toujours fonctionner normalement, car si un système de basculement, qui est une partie importante du mécanisme de haute disponibilité, est un seul point, ce sera très déroutant.
Connaissance de base de Sentinel
Sentinel nécessite au moins 3 instances pour garantir sa robustesse.
L'architecture de déploiement maître-esclave Sentinel + redis ne garantit pas zéro perte de données, mais ne peut garantir que la haute disponibilité du cluster redis.
Pour l'architecture de déploiement complexe de Sentinel + redis maître-esclave, essayez d'effectuer suffisamment de tests et d'exercices à la fois dans l'environnement de test et dans l'environnement de production.
29. Solution officielle Redis Cluster (requête de routage côté serveur)
Pouvez-vous me parler du principe de fonctionnement de redis mode cluster ? En mode cluster, comment la clé de redis est-elle adressée ? Quels sont les algorithmes d’adressage distribué ? Connaissez-vous l’algorithme de hachage cohérent ?
Introduction
Redis Cluster est une technologie de Sharding côté serveur, officiellement disponible en version 3.0. Redis Cluster n'utilise pas de hachage cohérent, mais utilise le concept de slot, qui est divisé en 16 384 emplacements au total. Envoyez la demande à n'importe quel nœud, et le nœud qui reçoit la demande enverra la demande de requête au nœud correct pour exécution
Description du programme
Par hachage, partage de données , chaque nœud stocke uniformément les données dans une certaine plage d'emplacements de hachage (valeur de hachage), avec 16 384 emplacements alloués par défaut
Chaque fragment de données sera stocké dans plusieurs maîtres-esclaves mutuels sur plusieurs nœuds
Les données sont d'abord écrites sur le nœud maître, puis synchronisées sur le nœud esclave (prend en charge la configuration de la synchronisation bloquante)
Les données entre plusieurs nœuds dans la même partition ne maintiennent pas la cohérence
Lors de la lecture des données , lorsque la clé exploitée par le client n'est pas allouée sur le nœud, redis renverra une commande de pilotage pour pointer vers le bon nœud
Lors du développement, il est nécessaire de migrer les données de l'ancienne partie. une partie va au nouveau nœud
Dans l'architecture du cluster Redis, chaque Redis doit ouvrir deux numéros de port, par exemple l'un est 6379, et l'autre est le numéro de port plus 1w, par exemple 16379.
Le numéro de port 16379 est utilisé pour la communication entre les nœuds, c'est-à-dire la communication sur le bus de cluster. Il est utilisé pour la détection des pannes, les mises à jour de configuration et l'autorisation de basculement. Le bus de cluster utilise un autre protocole binaire, le protocole gossip, pour un échange de données efficace entre les nœuds, consommant moins de bande passante réseau et de temps de traitement.
Mécanisme de communication interne entre les nœuds
(Principe de communication de base) Il existe deux manières de conserver les métadonnées du cluster : le protocole centralisé et le protocole de potins. Le protocole gossip est utilisé pour communiquer entre les nœuds du cluster Redis.
Algorithme d'adressage distribué
Algorithme de hachage (reconstruction de cache de masse)
Algorithme de hachage cohérent (migration automatique du cache) + nœud virtuel (équilibrage de charge automatique)
Algorithme de slot de hachage du cluster Redis
Avantages
Pas d'architecture centrale, prend en charge l'expansion dynamique et est transparent pour l'entreprise
Possède les capacités de surveillance et de basculement automatique de Sentinel
Le client n'a pas besoin de se connecter à tous les nœuds du cluster, il suffit de se connecter à n'importe quel nœud disponible du cluster
Connexion client directe hautes performances. Le service Redis élimine la perte d'agents proxy
Inconvénients
Le fonctionnement et la maintenance sont également très complexes, et la migration des données nécessite une intervention manuelle
Seulement 0 peut être utilisé No. base de données
ne prend pas en charge les opérations par lots (opérations de pipeline pipeline)
Logique distribuée et couplage de modules de stockage, etc.
30, basé sur le client allocation
Introduction
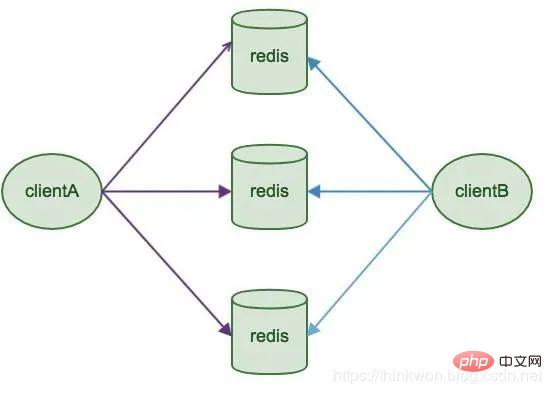
Redis Sharding est une méthode de clustering d'instances multi-Redis couramment utilisée dans l'industrie avant Redis Cluster est sorti. L'idée principale est d'utiliser un algorithme de hachage pour hacher la clé des données Redis. Grâce à la fonction de hachage, une clé spécifique sera mappée à un nœud Redis spécifique. Le client Java Redis pilote Jedis et prend en charge la fonction Redis Sharding, c'est-à-dire ShardedJedis et ShardedJedisPool combinés avec le pool de cache
Avantages
L'avantage est qu'il est très simple et les instances Redis sur le serveur sont indépendantes les unes des autres, indépendantes les unes des autres, chaque instance Redis fonctionne comme un seul serveur, très facile à développer linéairement, le système est très flexible
Inconvénients
En raison du traitement de fragmentation Du côté client, une expansion ultérieure entraînera des défis en matière d'exploitation et de maintenance.
Le partitionnement côté client ne prend pas en charge l'ajout et la suppression dynamiques de nœuds. Lorsque la topologie du groupe d'instances Redis côté serveur change, chaque client doit être mis à jour et ajusté. Les connexions ne peuvent pas être partagées. Lorsque l'échelle de l'application augmente, le gaspillage des ressources limite l'optimisation
Basé sur le partitionnement du serveur proxy
.
Introduction
Le client envoie une requête à un composant proxy, le proxy analyse les données du client et transmet la requête au bon nœud, et enfin Répondre aux résultats au client
Caractéristiques
Accès transparent, le programme métier n'a pas besoin de se soucier de l'instance Redis back-end et du coût de commutation est faible
Logique proxy Il est isolé de la logique de stockage
La couche proxy a un transfert supplémentaire et les performances sont perdues
La solution open source de l'industrie
Twemproxy open source de Twitter
Codis open source de Wandoujia
32. Architecture maître-esclave Redis
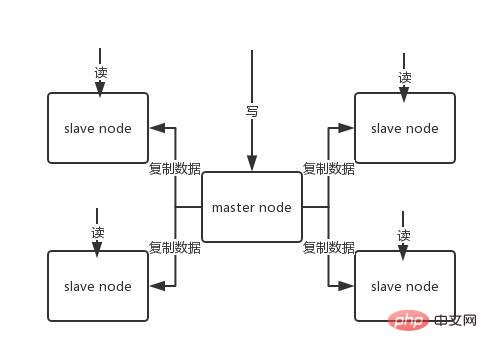
Le QPS ce qu'une seule machine peut transporter est probablement de plusieurs dizaines de milliers à des dizaines de milliers. Pas d'attente. Pour les caches, ils sont généralement utilisés pour prendre en charge une concurrence de lecture élevée. Par conséquent, l'architecture est transformée en une architecture maître-esclave, avec un maître et plusieurs esclaves. Le maître est responsable de l'écriture et de la copie des données vers d'autres nœuds esclaves, et les nœuds esclaves sont responsables de la lecture. Toutes les demandes de lecture vont aux nœuds esclaves. Cela peut également facilement réaliser une expansion horizontale, prenant en charge une concurrence de lecture élevée.
Réplication Redis -> Architecture maître-esclave -> Séparation en lecture et en écriture -> 🎜> Le mécanisme de base de la réplication redis
redis réplique les données sur le nœud esclave de manière asynchrone, mais à partir de redis2.8, le nœud esclave confirmera périodiquement la quantité de données qu'il copie à chaque fois Un nœud maître peut être configuré avec plusieurs nœuds esclaves ;
Le nœud esclave peut également se connecter à d'autres nœuds esclaves
Lorsque le nœud esclave se réplique, il ne bloquera pas le travail normal ; du nœud maître. ;
Le nœud esclave ne bloquera pas ses propres opérations de requête lors de la copie. Il utilisera l'ancien ensemble de données pour fournir des services, mais une fois la copie terminée, il devra supprimer l'ancien ensemble de données ; et chargez le nouveau. Ensemble de données, les services externes seront suspendus à ce moment ;
le nœud esclave est principalement utilisé pour l'expansion horizontale et la séparation de la lecture et de l'écriture.
Notez que si une architecture maître-esclave est adoptée, il est recommandé que la persistance du nœud maître soit activée. Il n'est pas recommandé d'utiliser le nœud esclave comme sauvegarde à chaud des données du nœud maître. , car dans ce cas, si vous désactivez la persistance du maître, les données peuvent être vides lorsque le maître plante et redémarre, puis les données du nœud esclave peuvent être perdues dès qu'elles sont répliquées.
De plus, divers plans de sauvegarde pour le maître doivent également être réalisés. En cas de perte de tous les fichiers locaux, sélectionnez un rdb dans la sauvegarde pour restaurer le maître, de manière à
garantir qu'il y a des données au démarrage, même si le mécanisme de haute disponibilité expliqué plus loin est adopté, l'esclave nœud Le nœud maître peut être automatiquement pris en charge, mais il est également possible que le nœud maître redémarre automatiquement avant que Sentinel ne détecte la panne du maître, ou que toutes les données du nœud esclave ci-dessus soient effacées.
Le principe de base de la réplication maître-esclave Redis
Lorsqu'un nœud esclave est démarré, il enverra une commande PSYNC au nœud maître. Si c'est la première fois que le nœud esclave se connecte au nœud maître, une copie complète de resynchronisation complète sera déclenchée. À ce moment-là, le maître démarrera un thread en arrière-plan et commencera à générer un fichier instantané RDB.
En même temps, toutes les commandes d'écriture nouvellement reçues du client client sont mises en cache en mémoire. Une fois le fichier RDB généré, le maître enverra le RDB à l'esclave, et l'esclave
l'écrira d'abord sur le disque local, puis le chargera du disque local dans la mémoire.Ensuite, le maître enverra les commandes d'écriture mises en cache dans la mémoire à l'esclave, et l'esclave synchronisera également les données. S'il y a une panne de réseau entre le nœud esclave et le nœud maître et que la connexion est déconnectée, il se reconnectera automatiquement après la connexion, le nœud maître copiera uniquement les données manquantes sur l'esclave.
Principe du processus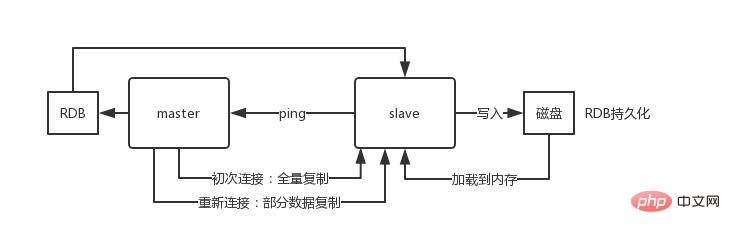
Lorsque la base de données esclave et la base de données maître établissent une relation MS, la commande SYNC sera envoyée au master database Après avoir reçu la commande SYNC, la bibliothèque principale commencera à enregistrer l'instantané en arrière-plan (processus de persistance RDB) et mettra en cache les commandes d'écriture reçues pendant la période
Lorsque l'instantané est terminé, le Redis principal enregistrera le fichier d'instantané et toutes les commandes d'écriture mises en cache seront envoyées au Redis esclave
Après réception de Redis, le fichier d'instantané sera chargé et la commande mise en cache reçue
sera exécuté.Après cela, le Redis maître recevra une commande d'écriture à chaque fois. La commande sera envoyée depuis Redis pour assurer la cohérence des données
InconvénientsRéplication de toutes les données des nœuds esclaves. et la synchronisation sont gérées par le nœud maître. Si le nœud maître est soumis à trop de pression, utilisez la structure maître-esclave pour le résoudre
33. Quel est le modèle de réplication maître-esclave de Redis grappe?Afin de rendre le cluster toujours disponible lorsque certains nœuds échouent ou que la plupart des nœuds ne peuvent pas communiquer, le cluster utilise un modèle de réplication maître-esclave, et chaque nœud aura N-1 répliques
34. Comment redis est-il déployé dans l'environnement de production ?Cluster Redis, 10 machines, 5 machines sont déployées avec des instances maître Redis et les 5 autres machines sont déployées avec des instances esclaves Redis, et 5 nœuds fournissent des services de lecture et d'écriture externes. et le pic de qps d'écriture d'un nœud peut atteindre 50 000 par seconde, et la ou les requêtes maximales de lecture et d'écriture pour 5 machines sont de 250 000.
Quelle est la configuration de la machine ? Mémoire 32 Go + CPU 8 cœurs + disque 1 To, mais la mémoire allouée au processus Redis est de 10 Go. Dans les environnements de production en ligne généraux, la mémoire de Redis ne doit pas dépasser 10 Go. Si elle dépasse 10 Go, il peut y avoir des problèmes.
5 machines assurent la lecture et l'écriture externe, avec un total de 50g de mémoire.
Étant donné que chaque instance maître possède une instance esclave, elle est hautement disponible. Si une instance maître tombe en panne, elle basculera automatiquement. L'instance esclave Redis deviendra automatiquement l'instance maître et continuera à fournir des services de lecture et d'écriture. .
Quelles données écrivez-vous dans la mémoire ? Quelle est la taille de chaque élément de données ? Données du produit, chaque élément de données fait 10 Ko. 100 éléments de données correspondent à 1 Mo et 100 000 éléments de données correspondent à 1 Go. Il y a 2 millions de données produit résidant dans la mémoire et la mémoire occupée est de 20 g, ce qui ne représente que moins de 50 % de la mémoire totale. La période de pointe actuelle est d'environ 3 500 requêtes par seconde.
En fait, les grandes entreprises disposeront d'une équipe d'infrastructure responsable du fonctionnement et de la maintenance du cluster de cache.
35. Parlez-nous du concept du slot de hachage Redis ?
Le cluster Redis n'utilise pas de hachage cohérent, mais introduit le concept d'emplacement de hachage. Le cluster Redis dispose de 16 384 emplacements de hachage. Chaque clé est déterminée en prenant modulo 16 384 après vérification CRC16. Le nœud du cluster est responsable d’une partie de l’emplacement de hachage.
36. Les opérations d'écriture seront-elles perdues dans le cluster Redis ? Pourquoi?
Redis ne garantit pas une forte cohérence des données, ce qui signifie qu'en pratique, le cluster peut perdre des opérations d'écriture sous certaines conditions.
37. Comment les clusters Redis sont-ils répliqués ?
Réplication asynchrone
38. Quel est le nombre maximum de nœuds dans un cluster Redis ?
16384
39. Comment choisir une base de données pour le cluster Redis ?
Le cluster Redis ne peut actuellement pas sélectionner la base de données et est par défaut la base de données 0.
9. Partition
40. Redis est monothread, comment améliorer l'utilisation du processeur multicœur ?
Vous pouvez déployer plusieurs instances Redis sur le même serveur et les utiliser comme serveurs différents. À un moment donné, un seul serveur ne suffit pas de toute façon, donc si vous le souhaitez avec plusieurs processeurs, vous pouvez envisager le partitionnement.
41. Pourquoi avez-vous besoin d'un partitionnement Redis ?
Le partitionnement permet à Redis de gérer une mémoire plus grande, et Redis pourra utiliser la mémoire de toutes les machines. Sans partitions, vous ne pouvez utiliser que la mémoire d'une seule machine. Le partitionnement permet de doubler la puissance de calcul de Redis en ajoutant simplement des ordinateurs, et la bande passante réseau de Redis augmentera également de façon exponentielle avec l'ajout d'ordinateurs et de cartes réseau.
42. Savez-vous quelles solutions d'implémentation de partition Redis sont disponibles ?
Le partitionnement côté client signifie que le client a déjà décidé dans quel nœud Redis les données seront stockées ou lues. La plupart des clients implémentent déjà le partitionnement côté client.
Le partitionnement du proxy signifie que le client envoie la requête au proxy, puis le proxy décide sur quel nœud écrire ou lire les données. L'agent décide quelles instances Redis demander en fonction des règles de partition, puis les renvoie au client en fonction des résultats de la réponse Redis. Une implémentation proxy de redis et memcached est Twemproxy
Query Routing (Query Routing), ce qui signifie que le client demande de manière aléatoire n'importe quelle instance Redis, puis Redis transmet la demande au bon nœud Redis. Redis Cluster implémente une forme hybride de routage des requêtes, mais au lieu de transmettre les requêtes directement d'un nœud Redis à un autre, il redirige directement vers le nœud Redis correct avec l'aide du client.
43. Quels sont les inconvénients du partitionnement Redis ?
Les opérations impliquant plusieurs clés ne sont généralement pas prises en charge. Par exemple, vous ne pouvez pas croiser deux collections car elles peuvent être stockées dans des instances Redis différentes (en fait, il existe un moyen pour cette situation, mais la commande intersection ne peut pas être utilisée directement).
Si vous utilisez plusieurs clés en même temps, vous ne pouvez pas utiliser de transactions Redis.
La granularité utilisée dans le partitionnement est essentielle, et vous ne pouvez pas utiliser une clé de tri très longue pour stocker un ensemble de données (La granularité du partitionnement est la clé, il n'est donc pas possible de partitionner un ensemble de données avec une seule clé énorme comme un très grand ensemble trié)
Lors de l'utilisation de partitions, le traitement des données sera très compliqué, par exemple dans Pour effectuer une sauvegarde, vous devez démarrer à partir de différentes instances Redis. Collectez les fichiers RDB/AOF simultanément avec l'hôte.
L'expansion ou la contraction dynamique lors du cloisonnement peut être très complexe. Le cluster Redis ajoute ou supprime des nœuds Redis au moment de l'exécution, ce qui permet d'obtenir un rééquilibrage des données qui est le plus transparent possible pour les utilisateurs. Cependant, certaines autres méthodes de partitionnement client ou de partitionnement proxy ne prennent pas en charge cette fonctionnalité. Cependant, il existe une technologie de pré-partage qui peut également mieux résoudre ce problème.
10. Problèmes distribués
44. Redis implémente des verrous distribués
Redis est un mode mono-thread et utilise le mode file d'attente pour accéder. simultanément, cela devient un accès série et il n'y a pas de concurrence entre les connexions de plusieurs clients à Redis. Vous pouvez utiliser la commande SETNX pour implémenter des verrous distribués dans Redis.
Si et seulement si la clé n'existe pas, définissez la valeur de la clé sur value. Si la clé donnée existe déjà, SETNX ne fait rien.
SETNX est l'abréviation de "SET if Not eXists" (s'il n'existe pas, alors SET).
Valeur de retour : si le réglage est réussi, 1 sera renvoyé. L'installation échoue et renvoie 0.
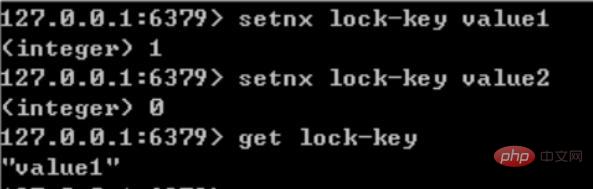
Le processus et les éléments d'utilisation de SETNX pour effectuer le verrouillage de synchronisation sont les suivants :
Utilisez la commande SETNX pour obtenir le lock. S'il renvoie 0 (la clé existe, le verrou existe déjà), l'acquisition échoue, sinon l'acquisition réussit.
Afin d'éviter les exceptions dans le programme après l'acquisition du verrou, provoquant le retour 0 des autres threads/processus lors de l'appel de la commande SETNX et l'entrée dans un état de blocage, un délai d'expiration "raisonnable" doit être défini pour la clé.
Relâchez le verrou et utilisez la commande DEL pour supprimer les données du verrou.
45. Comment résoudre le problème de concurrence simultanée pour Key in Redis
Le soi-disant problème de concurrence concurrente pour Key in Redis est que plusieurs systèmes fonctionnent sur une clé en même temps, mais au final L'ordre d'exécution est différent de l'ordre attendu, ce qui conduit à des résultats différents !
Recommander une solution : le verrouillage distribué (zookeeper et redis peuvent implémenter des verrous distribués). (S'il n'y a pas de concurrence simultanée pour Key dans Redis, n'utilisez pas de verrous distribués, car cela affecterait les performances)
Verrous distribués basés sur les nœuds ordonnés temporaires de zookeeper. L'idée générale est la suivante : lorsque chaque client verrouille une certaine méthode, un nœud ordonné instantané unique est généré dans le répertoire du nœud spécifié correspondant à la méthode sur zookeeper. La manière de déterminer s'il faut acquérir un verrou est très simple. Il vous suffit de déterminer le plus petit numéro de séquence parmi les nœuds ordonnés. Lorsque le verrou est libéré, supprimez simplement le nœud transitoire. Dans le même temps, cela peut éviter les problèmes de blocage causés par des verrous qui ne peuvent pas être libérés en raison d'un temps d'arrêt du service. Une fois le processus métier terminé, supprimez le nœud enfant correspondant pour libérer le verrou.
En pratique, la fiabilité est bien sûr la priorité principale. Par conséquent, Zookeeper est recommandé en premier.
46. Les Redis distribués doivent-ils être effectués à un stade précoce ou à un stade ultérieur lorsque l'échelle est augmentée ? Pourquoi?
Étant donné que Redis est si léger (une seule instance n'utilise que 1 Mo de mémoire), le meilleur moyen d'empêcher une expansion future est de démarrer plusieurs instances au début. Même si vous ne disposez que d'un seul serveur, vous pouvez faire exécuter Redis de manière distribuée dès le début, en utilisant des partitions pour démarrer plusieurs instances sur le même serveur.
Configurez quelques instances Redis supplémentaires au début, par exemple 32 ou 64 instances. Cela peut être fastidieux pour la plupart des utilisateurs, mais cela vaut le sacrifice à long terme.
Dans ce cas, lorsque vos données continuent de croître et que vous avez besoin de plus de serveurs Redis, il vous suffit de migrer l'instance Redis d'un service vers un autre serveur (sans considérer le problème de répartition). Une fois que vous avez ajouté un autre serveur, vous devez migrer la moitié de vos instances Redis de la première machine vers la deuxième machine.
47. Qu'est-ce que RedLock
Le site officiel de Redis a proposé une méthode faisant autorité pour implémenter des verrous distribués basés sur Redis appelé Redlock. L'approche -node est plus sécurisée. Il peut garantir les fonctionnalités suivantes :
Fonctions de sécurité : Accès mutuellement exclusif, c'est-à-dire qu'un seul client peut toujours obtenir le verrou
Éviter les impasses : En fin de compte, le client peut obtenir le verrou, et il n'y aura pas de blocage, même si le client qui a initialement verrouillé une ressource plante ou si une partition réseau se produit
Tolérance aux pannes : Tant que la plupart des Redis Tant que le nœud est vivant, il peut fournir des services normalement
11. Exception de cache
48. Avalanche de cache
L'avalanche de cache fait référence à la mise en cache d'une grande zone en même temps. Échec, par conséquent, les requêtes ultérieures tomberont sur la base de données, obligeant la base de données à résister à un grand nombre de requêtes en peu de temps et à s'effondrer.
Solution :
Définissez le délai d'expiration des données mises en cache de manière aléatoire pour éviter qu'un grand nombre de données n'expirent en même temps.
Généralement, lorsque le degré de concurrence n'est pas particulièrement important, la solution la plus couramment utilisée est la mise en file d'attente de verrouillage.
Ajoutez une balise de cache correspondante à chaque donnée mise en cache, enregistrez si le cache est invalide et mettez à jour le cache de données si la balise de cache n'est pas valide.
49. Pénétration du cache
La pénétration du cache fait référence aux données qui ne sont ni dans le cache ni dans la base de données, ce qui fait que toutes les requêtes tombent sur la base de données, provoquant ainsi la base de données. pour être bref. Il s'est écrasé en raison d'un grand nombre de demandes dans un court laps de temps.
Solution :
Ajouter une vérification au niveau de la couche d'interface, telle que la vérification de l'authentification de l'utilisateur, la vérification de base de l'identifiant et l'interception directe de l'identifiant
Les données qui ne peuvent pas être obtenues à partir du cache ne sont pas obtenues dans la base de données. À ce stade, la paire clé-valeur peut également être écrite comme clé-nulle. La durée de validité du cache peut être définie plus courte, par exemple 30 secondes. (le réglage est trop long) Cela rendra impossible son utilisation dans des circonstances normales). Cela peut empêcher les utilisateurs attaquants d'utiliser à plusieurs reprises le même identifiant pour des attaques par force brute
Utilisez un filtre Bloom pour hacher toutes les données possibles dans un bitmap suffisamment grand. Les données qui ne doivent pas exister seront incluses dans ce bitmap. Interceptez-le, évitant ainsi la pression des requêtes sur le système de stockage sous-jacent
Supplémentaire :
L'utilisation ultime de l'espace est Bitmap et Bloom Filter.
Bitmap : La table typique est une table de hachage
L'inconvénient est que Bitmap ne peut enregistrer qu'un seul bit d'information pour chaque élément si vous souhaitez remplir des fonctions supplémentaires. , j'ai peur que cela ne puisse être accompli qu'en sacrifiant plus d'espace et de temps.
Filtre Bloom (recommandé)
introduit k(k>1)k(k>1) fonctions de hachage indépendantes pour garantir que, dans un espace et un taux d'erreur de jugement donnés, le le processus de détermination du poids des éléments est terminé.
Son avantage est que l'efficacité spatiale et le temps de requête sont bien supérieurs à ceux de l'algorithme général, mais son inconvénient est qu'il présente un certain taux de mauvaise reconnaissance et des difficultés de suppression.
L'idée principale de l'algorithme Bloom-Filter est d'utiliser plusieurs fonctions de hachage différentes pour résoudre les « conflits ».
Hash a un problème de conflit (collision), et les valeurs de deux URL obtenues en utilisant le même Hash peuvent être les mêmes. Afin de réduire les conflits, nous pouvons introduire plusieurs valeurs de hachage supplémentaires. Si nous concluons à partir de l'une des valeurs de hachage qu'un élément n'est pas dans l'ensemble, alors l'élément n'est certainement pas dans l'ensemble. Ce n'est que lorsque toutes les fonctions de hachage nous indiquent que l'élément est dans l'ensemble que nous pouvons être sûrs que l'élément existe dans l'ensemble. C'est l'idée de base de Bloom-Filter.
Bloom-Filter est généralement utilisé pour déterminer si un élément existe dans une grande collection de données.
50. Panne du cache
Panne du cache fait référence aux données qui ne sont pas dans le cache mais dans la base de données (généralement le temps de cache a expiré ), à ce moment-là, en raison du grand nombre d'utilisateurs simultanés, le cache de lecture n'a pas lu les données en même temps et s'est en même temps rendu à la base de données pour récupérer les données, provoquant une augmentation instantanée de la pression de la base de données , provoquant une pression excessive. Contrairement à l'avalanche de cache, la panne du cache fait référence à une requête simultanée des mêmes données. L'avalanche de cache signifie que différentes données ont expiré et qu'un grand nombre de données sont introuvables, la base de données est donc recherchée.
Solution
Définissez les données du point d'accès pour qu'elles n'expirent jamais.
Ajouter un verrouillage mutex, un verrouillage mutex
51. Préchauffage du cache
Le préchauffage du cache signifie qu'une fois le système mis en ligne, les données de cache pertinentes se chargent directement. dans le système de cache. De cette façon, vous pouvez éviter le problème d’interroger d’abord la base de données, puis de mettre les données en cache lorsque l’utilisateur le demande ! Les utilisateurs interrogent directement les données mises en cache qui ont été préchauffées !
Solution :
Écrivez directement une page d'actualisation du cache, et faites-le manuellement lors de la connexion
La quantité de données n'est pas importante, et cela peut être fait au démarrage du projet. Charger automatiquement en cas de besoin
Actualiser régulièrement le cache
52. Le nombre de visites augmente fortement et des problèmes de service surviennent (tels que le temps de réponse). Lorsque des services lents ou ne répondent pas) ou des services non essentiels affectent les performances des processus principaux, il est toujours nécessaire de s'assurer que le service est toujours disponible, même s'il est altéré. Le système peut automatiquement rétrograder en fonction de certaines données clés, ou configurer des commutateurs pour réaliser une rétrogradation manuelle. ,
Le but ultime de la rétrogradation du cache
est de garantir que les services de base sont disponibles, même s'ils entraînent des pertes. Et certains services ne peuvent pas être rétrogradés (comme l'ajout au panier, le paiement).Avant de déclasser, vous devez trier le système pour voir si le système peut perdre des soldats et conserver des commandants, triant ainsi ce qui doit être protégé jusqu'à la mort et ce qui peut être déclassé par exemple ; au plan de configuration du niveau de journalisation :
Général : par exemple, certains services expirent occasionnellement en raison de la gigue du réseau ou lorsque le service est en ligne et peuvent être automatiquement rétrogradésAvertissement ;
: Certains services ont des taux de réussite fluctuants sur une période de temps (comme 95 ~ 100 %), vous pouvez automatiquement rétrograder ou rétrograder manuellement et envoyer une alarmeErreur
; : Par exemple, le taux de disponibilité est inférieur à 90 %, ou le pool de connexions à la base de données est épuisé, ou le nombre de visites augmente soudainement jusqu'au seuil maximum que le système peut supporter. À ce moment, il peut être automatiquement rétrogradé ou manuellement. selon la situation ;Erreur grave :
Par exemple, si les données sont erronées pour des raisons particulières, ce déclassement manuel d'urgence est requis.Le but de la rétrogradation du service est d'empêcher une défaillance du service Redis de provoquer des problèmes d'avalanche dans la base de données. Par conséquent, pour les données mises en cache sans importance, une stratégie de rétrogradation du service peut être adoptée. Par exemple, une approche courante consiste à renvoyer directement la valeur par défaut à l'utilisateur en cas de problème avec Redis.
53. Données chaudes et données froides
Le cache n'a de valeur que pour les données chaudes.
Pour les données froides, la plupart des données peuvent avoir été extraites de la mémoire avant d'être consultées à nouveau, ce qui non seulement occupe de la mémoire, mais a également peu de valeur. Pour les données fréquemment modifiées, pensez à utiliser le cache en fonction de la situation Pour les données chaudes, comme l'un de nos produits de messagerie instantanée, le module de voeux d'anniversaire et la liste des anniversaires du jour, le cache peut être lu des centaines de milliers de fois. Pour un autre exemple, dans un produit de navigation, nous mettons en cache les informations de navigation et pouvons les lire des millions de fois dans le futur. Le cache n'a de sens que si les données sont lues au moins deux fois avant la mise à jour. Il s'agit de la stratégie la plus élémentaire. Si le cache échoue avant de prendre effet, il n'aura pas beaucoup de valeur.Qu'en est-il du scénario dans lequel le cache n'existe pas et la fréquence de modification est très élevée, mais où la mise en cache doit être prise en compte ? avoir! Par exemple, cette interface de lecture exerce beaucoup de pression sur la base de données, mais il s'agit également de données chaudes. À ce stade, vous devez envisager des méthodes de mise en cache pour réduire la pression sur la base de données, comme le nombre de likes, de collections et. partages de l'un de nos produits assistants. Il s'agit de données chaudes très typiques, mais elles changent constamment. À l'heure actuelle, les données doivent être enregistrées de manière synchrone dans le cache Redis pour réduire la pression sur la base de données.
54. Clé du hotspot du cache
Une clé dans le cache (comme un produit promotionnel) expire à un certain moment. Cette clé contient un grand nombre de. requêtes simultanées. Lorsque ces requêtes constatent que le cache a expiré, elles chargent généralement les données de la base de données back-end et les réinitialisent dans le cache. À ce stade, des requêtes simultanées volumineuses peuvent instantanément submerger la base de données back-end.
Solution :
Verrouillez la requête de cache. Si la CLÉ n'existe pas, verrouillez-la, puis enregistrez la base de données dans le cache, puis déverrouillez-la si elle est autre ; les processus trouvent qu'il y a Il suffit d'attendre le verrou, puis de renvoyer les données ou de saisir la requête DB après le déverrouillage
Outils communs
55. Quels sont les clients Java pris en charge par Redis ? Lequel est officiellement recommandé ?
Redisson, Jedis, laitue, etc. Le Redisson est officiellement recommandé.
56. Quelle est la relation entre Redis et Redisson ?
Redisson est un client Redis de coordination distribuée avancé qui peut aider les utilisateurs à implémenter facilement certains objets Java (filtre Bloom, BitSet, Set, SetMultimap, ScoredSortedSet, SortedSet, Map) dans un environnement distribué, ConcurrentMap, List , ListMultimap, Queue, BlockingQueue, Deque, BlockingDeque, Semaphore, Lock, ReadWriteLock, AtomicLong, CountDownLatch, Publier/Abonnez-vous, HyperLogLog).
57. Quels sont les avantages et les inconvénients des Jedis et Redisson ?
Jedis est un client implémenté par Redis en Java. Son API fournit un support relativement complet pour les commandes Redis ; Redisson implémente une structure de données Java distribuée et évolutive. Par rapport à Jedis, ses fonctions sont relativement simples, ne prend pas en charge les opérations sur les chaînes et ne prend pas en charge les fonctionnalités Redis telles que le tri, les transactions, les pipelines et les partitions. Le but de Redisson est de promouvoir la séparation des préoccupations des utilisateurs de Redis, afin que les utilisateurs puissent se concentrer davantage sur le traitement de la logique métier
Autres problèmes
58. Redis et La différence entre Memcached
Les deux sont des bases de données clé-valeur à mémoire non relationnelle. Les entreprises utilisent désormais généralement Redis pour implémenter la mise en cache, et Redis lui-même devient de plus en plus puissant ! Les principales différences entre Redis et Memcached sont les suivantes :
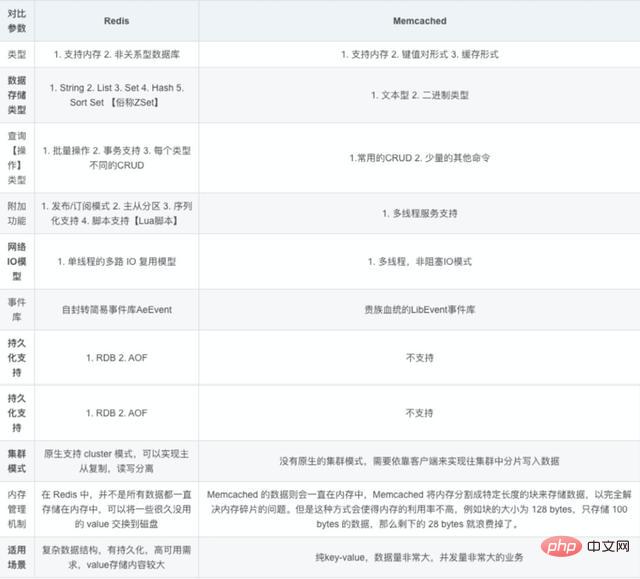
(1) Toutes les valeurs de memcached sont des chaînes simples et redis, en remplacement, prend en charge des types de données plus riches.
(2) Redis est beaucoup plus rapide que Memcached
(3) Redis peut conserver ses données
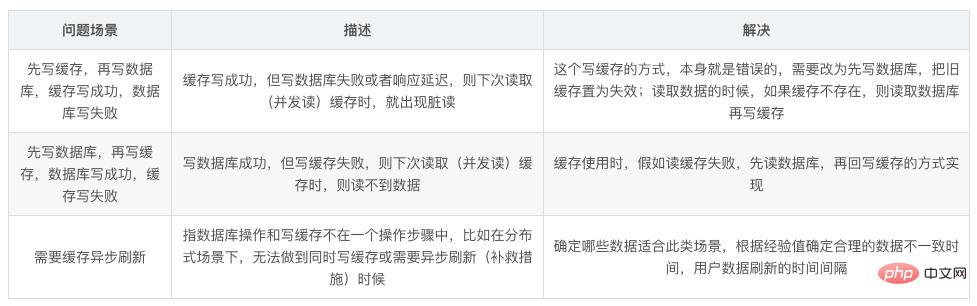
Comment assurer la double écriture des données du cache et de la base de données. cohérence?
Tant que vous utilisez le cache, cela peut impliquer un double stockage et une double écriture du cache et de la base de données. Tant que vous utilisez la double écriture, il y aura certainement des problèmes de cohérence des données. le problème de cohérence ?
De manière générale, si votre système n'exige pas strictement que le cache + la base de données soient cohérents, le cache peut parfois être légèrement incohérent avec la base de données. Il est préférable de ne pas utiliser cette solution, de lire les requêtes et d'écrire les requêtes. et enchaînez-le dans une file d'attente mémoire, afin de garantir qu'il n'y aura pas d'incohérence
Après la sérialisation, le débit du système sera considérablement réduit et l'utilisation sera nettement inférieure à la normale dans ce cas. , plusieurs fois plus de machines sont nécessaires pour prendre en charge une demande en ligne.
Une autre méthode consiste à produire temporairement des incohérences, mais la probabilité qu'elles se produisent est très faible, ce qui consiste à mettre d'abord à jour la base de données, puis à supprimer le cache.
60. Problèmes de performances courants et solutions de Redis ?
Il est préférable que Master n'effectue aucun travail de persistance, y compris les instantanés de mémoire et les fichiers journaux AOF. En particulier, n'activez pas les instantanés de mémoire pour la persistance.
Si les données sont critiques, un esclave permet la sauvegarde des données AOF, et la stratégie est de synchroniser une fois par seconde.
Pour la rapidité de réplication maître-esclave et la stabilité de la connexion, il est préférable que l'Esclave et le Maître soient dans le même LAN.
Essayez d'éviter d'ajouter des bibliothèques esclaves à la bibliothèque maître stressée
Le maître appelle BGREWRITEAOF pour réécrire le fichier AOF qui occupera une grande quantité de ressources CPU et mémoire pendant la réécriture, provoquant une panne de service. la charge est trop élevée et le service est temporairement suspendu.
Pour la stabilité du Maître, n'utilisez pas de structure graphique pour la réplication maître-esclave. Il est plus stable d'utiliser une structure de liste chaînée unidirectionnelle, c'est-à-dire que la relation maître-esclave est : Maître<. ;–Slave1
61. Pourquoi Redis ne fournit-il pas officiellement une version Windows ?
Étant donné que la version actuelle de Linux est assez stable et compte un grand nombre d'utilisateurs, il n'est pas nécessaire de développer une version Windows, ce qui entraînerait des problèmes de compatibilité et autres.
62. Quelle est la capacité maximale qu'une valeur de type chaîne peut stocker ?
512M
63. Comment Redis effectue-t-il l'insertion d'une grande quantité de données ?
À partir de Redis 2.6, redis-cli prend en charge un nouveau mode appelé mode pipe pour effectuer de grandes quantités de travaux d'insertion de données.
64. S'il y a 100 millions de clés dans Redis et que 100 000 d'entre elles commencent par un préfixe fixe et connu, et si vous les trouviez toutes ?
Utilisez la commande keys pour parcourir la liste des clés du modèle spécifié.
L'autre partie a ensuite demandé : si ce redis fournit des services aux entreprises en ligne, quels sont les problèmes liés à l'utilisation de la commande key ?
À ce stade, vous devez répondre à une fonctionnalité clé de Redis : le monothreading de Redis. L'instruction key entraînera le blocage du thread pendant un certain temps et le service en ligne sera mis en pause. Le service ne pourra pas être restauré tant que l'instruction n'est pas exécutée. À ce stade, vous pouvez utiliser la commande scan. La commande scan peut extraire la liste des clés du mode spécifié sans blocage, mais il y aura une certaine probabilité de duplication. Il suffit de le faire une fois sur le client, mais le temps global passé sera le même. être plus long que de l'utiliser directement. La commande key est longue.
65. Avez-vous déjà créé une file d'attente asynchrone avec Redis ? Comment a-t-elle été implémentée ?
Utilisez le type de liste pour enregistrer les informations sur les données, rpush produit des messages et lpop consomme des messages. Lorsque lpop n'a pas de messages, vous pouvez dormir pendant un certain temps, puis vérifier s'il y a des informations. . Si vous ne voulez pas dormir, vous pouvez utiliser blpop , lorsqu'il n'y a aucune information, il se bloquera jusqu'à ce que l'information arrive. Redis peut implémenter un producteur et plusieurs consommateurs via le modèle d'abonnement au sujet pub/sub. Bien sûr, il existe certains inconvénients lorsque le consommateur se déconnecte, les messages produits seront perdus.
66. Comment Redis implémente-t-il la file d'attente différée ?
Utilisez sortedset, utilisez l'horodatage comme score, le contenu du message comme clé, appelez zadd pour produire des messages et le consommateur utilise zrangbyscore pour obtenir des données il y a n secondes pour le traitement de l'interrogation.
67. Comment fonctionne le processus de recyclage Redis ?
Un client a exécuté une nouvelle commande et ajouté de nouvelles données.
Redis vérifie l'utilisation de la mémoire si elle est supérieure à la limite maxmemory, elle sera recyclée conformément à la politique définie.
Une nouvelle commande est exécutée, etc.
Nous franchissons donc constamment la limite de la mémoire en atteignant constamment la limite, puis en recyclant constamment en dessous de la limite.
Si le résultat d'une commande entraîne l'utilisation d'une grande quantité de mémoire (comme par exemple l'enregistrement de l'intersection d'un grand ensemble sur une nouvelle clé), il ne faudra pas longtemps pour que la limite de mémoire soit dépassée par cette utilisation de la mémoire.
68. Quel algorithme est utilisé pour le recyclage Redis ?
Algorithme LRU.
D'accord, Les questions d'entretien Redis sont partagées ici Si cela vous est utile, veuillez lui donner un "j'aime" pour l'encourager~
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!