
Maison >interface Web >js tutoriel >qu'est-ce qu'Unicode
qu'est-ce qu'Unicode

- 清浅original
- 2019-01-26 10:56:1439571parcourir
Unicode est un système de codage de caractères qui définit un codage binaire unifié et unique pour chaque caractère dans chaque langue afin de répondre aux exigences de conversion et de traitement de texte multilingue et multiplateforme
Signification Unicode
Unicode fournit un numéro unique pour chaque caractère, quelle que soit la plateforme, quel que soit le programme, quelle que soit la langue. Il a été officiellement annoncé en 1994 et constitue une norme industrielle dans le domaine informatique, y compris les jeux de caractères, les schémas de codage, etc. Unicode a été créé pour résoudre les limites des schémas de codage de caractères traditionnels. Il définit un codage binaire unifié et unique pour chaque caractère dans chaque langue afin de répondre aux exigences de conversion et de traitement de texte multilingue et multiplateforme.

Le développement du codage Unicode
Les ordinateurs sont conçus en utilisant 8 bits comme octet. Par conséquent, un octet peut représenter jusqu'à. 256 caractères. Au début, pour les pays occidentaux qui utilisaient l'anglais, un octet pouvait stocker les lettres anglaises majuscules et minuscules, les mathématiques et certains symboles, donc un octet était utilisé pour créer la table de codes (ASCII). Plus tard, les ordinateurs se sont répandus dans d'autres pays, et de nombreux pays ont utilisé leurs propres langues, comme le chinois, le japonais, le coréen... Les langues étaient compliquées. Afin de résoudre ce problème, chaque pays a formulé sa propre table de codes. formulé GB2312 en 1980 Dans le jeu de caractères de codage des caractères chinois, il y a beaucoup plus de caractères chinois que l'anglais. Un octet n'est évidemment pas suffisant, donc 2 octets sont utilisés pour le codage. Cependant, bien que les codages de caractères définis par différents pays puissent être utilisés, ils sont souvent incompatibles entre les différents pays. Si l'ordinateur souhaite gérer plusieurs environnements linguistiques (en utilisant le chinois ou d'autres langues), il ne pourra peut-être pas prendre en charge plusieurs environnements linguistiques en même temps. Afin d'unifier l'encodage de tous les textes, Unicode a été créé pour unifier toutes les langues en un seul ensemble d'encodages afin qu'il n'y ait pas de caractères tronqués.

Le codage Unicode représente
Lors de la représentation de caractères Unicode, U+ est généralement utilisé suivi d'un ensemble de chiffres hexadécimaux Représente un caractère, le codage va de U+0000 à U+FFFF, prenant en charge plus de 60 000 caractères au total. Les caractères autres que BMP
doivent être représentés par un hexadécimal à 5 ou 6 chiffres.
Actuellement, les caractères Unicode sont divisés en 17 groupes, de 0x0000 à 0x10FFFF. Chaque groupe est appelé un avion. Chaque avion possède 65 536 points de code, soit un total de 1114112.
Unicode est comme un tableau. Tous les caractères sont écrits dans le tableau. Chaque caractère correspond à un nombre, appelé point de code. Ce numéro n'est généralement pas utilisé directement. Il est transmis via
. Utilisez différentes méthodes d'encodage
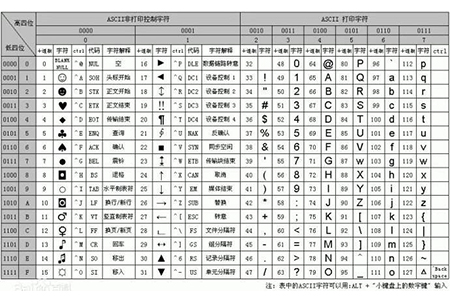
UTF-8, UTF-16 et UTF-32 sont des schémas d'encodage permettant de convertir des nombres en données de programme. UTF est l'abréviation de "UnicodeTransformation Format", qui peut être traduit en
format de conversion de jeu de caractères Unicode, c'est-à-dire comment convertir les nombres définis par Unicode en données de programme
Décimal
|
Encodage Unicode | Flux d'octets UTF-8 | |||||||||||||||
| 0-127 bits | 0x000000-0x00007F | 0xxxxxxx(7 chiffres) | |||||||||||||||
| 128- 2047 bits | 0x000080-0x0007FF | 110xxxxx 10xxxxxx (11 chiffres) | |||||||||||||||
| 2048-65535 bits | 0x000800-0x00FFFF td> | 1110xxxx 10xxxxxx 10xxxxxx (16 bits) | |||||||||||||||
| 65536-1114111 bits | 0x010000-0x10FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx (21 bits) |
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Une analyse approfondie du composant de groupe de liste Bootstrap
- Explication détaillée du currying de la fonction JavaScript
- Exemple complet de génération de mot de passe JS et de détection de force (avec téléchargement du code source de démonstration)
- Angularjs intègre l'interface utilisateur WeChat (weui)
- Comment basculer rapidement entre le chinois traditionnel et le chinois simplifié avec JavaScript et l'astuce permettant aux sites Web de prendre en charge le basculement entre les compétences en chinois simplifié et traditionnel_javascript