
Maison >développement back-end >Tutoriel Python >Comment implémenter pivot() dans pandas.DataFrame pour convertir des lignes en colonnes (code)
Comment implémenter pivot() dans pandas.DataFrame pour convertir des lignes en colonnes (code)

- 不言avant
- 2018-10-13 14:34:006477parcourir
Le contenu de cet article explique comment pivot() dans pandas.DataFrame implémente la conversion de lignes (code). Il a une certaine valeur de référence. Les amis dans le besoin peuvent s'y référer.
Exemple :
Le tableau suivant nécessite une conversion de lignes :
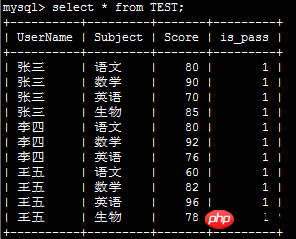
Le code est le suivant :
# -*- coding:utf-8 -*-
import pandas as pd
import MySQLdb
from warnings import filterwarnings
# 由于create table if not exists总会抛出warning,因此使用filterwarnings消除
filterwarnings('ignore', category = MySQLdb.Warning)
from sqlalchemy import create_engine
import sys
if sys.version_info.major<3:
reload(sys)
sys.setdefaultencoding("utf-8")
# 此脚本适用于python2和python3
host,port,user,passwd,db,charset="192.168.1.193",3306,"leo","mysql","test","utf8"
def get_df():
global host,port,user,passwd,db,charset
conn_config={"host":host, "port":port, "user":user, "passwd":passwd, "db":db,"charset":charset}
conn = MySQLdb.connect(**conn_config)
result_df=pd.read_sql('select UserName,Subject,Score from TEST',conn)
return result_df
def pivot(result_df):
df_pivoted_init=result_df.pivot('UserName','Subject','Score')
df_pivoted = df_pivoted_init.reset_index() # 将行索引也作为DataFrame值的一部分,以方便存储数据库
return df_pivoted_init,df_pivoted
# 返回的两个DataFrame,一个是以姓名作index的,一个是以数字序列作index,前者用于unpivot,后者用于save_to_mysql
def unpivot(df_pivoted_init):
# unpivot需要进行df_pivoted_init二维表格的行、列索引遍历,需要拼SQL因此不能使用save_to_mysql存数据,这里使用SQL和MySQLdb接口存
insert_sql="insert into test_unpivot(UserName,Subject,Score) values "
# 处理值为NaN的情况
df_pivoted_init=df_pivoted_init.add(0,fill_value=0)
for col in df_pivoted_init.columns:
for index in df_pivoted_init.index:
value=df_pivoted_init.at[index,col]
if value!=0:
insert_sql=insert_sql+"('%s','%s',%s)" %(index,col,value)+','
insert_sql = insert_sql.strip(',')
global host, port, user, passwd, db, charset
conn_config = {"host": host, "port": port, "user": user, "passwd": passwd, "db": db, "charset": charset}
conn = MySQLdb.connect(**conn_config)
cur=conn.cursor()
cur.execute("create table if not exists test_unpivot like TEST")
cur.execute(insert_sql)
conn.commit()
conn.close()
def save_to_mysql(df_pivoted,tablename):
global host, port, user, passwd, db, charset
"""
只有使用sqllite时才能指定con=connection实例,其他数据库需要使用sqlalchemy生成engine,engine的定义可以添加?来设置字符集和其他属性
"""
conn="mysql://%s:%s@%s:%d/%s?charset=%s" %(user,passwd,host,port,db,charset)
mysql_engine = create_engine(conn)
df_pivoted.to_sql(name=tablename, con=mysql_engine, if_exists='replace', index=False)
# 从TEST表读取源数据至DataFrame结构
result_df=get_df()
# 将源数据行转列为二维表格形式
df_pivoted_init,df_pivoted=pivot(result_df)
# 将二维表格形式的数据存到新表test中
save_to_mysql(df_pivoted,'test')
# 将被行转列的数据unpivot,存入test_unpivot表中
unpivot(df_pivoted_init)Le résultat est le suivant :
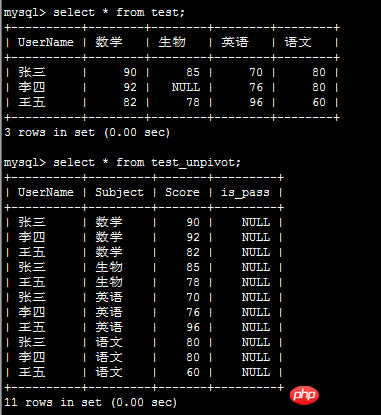
À propos de la méthode pivot fournie avec la classe Pandas DataFrame :
DataFrame.pivot (index=Aucun, colonnes =Aucun, valeurs=Aucun) :
Renvoie le DataFrame remodelé organisé par valeurs d'index/colonne données.
Il y a il n'y a que 3 paramètres ici, qui sont Parce que le résultat après pivot doit être un tableau bidimensionnel, qui ne nécessite que des lignes et des colonnes et leurs valeurs correspondantes, et parce qu'il s'agit d'un tableau bidimensionnel, la colonne is_pass sera définitivement perdue après unpivot, donc je n'ai pas vérifié cette colonne au début.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Explication détaillée de l'exemple de code de la méthode pandas.DataFrame d'exclusion de lignes spécifiques en python
- Introduction aux méthodes de fonctionnement simples de pandas.DataFrame (créer, indexer, ajouter et supprimer) en python
- Exemple de code pour additionner les lignes et les colonnes et ajouter de nouvelles lignes et colonnes dans pandas.DataFrame en python
- À propos des opérations de base de pandas.DataFrame en python
- Comment utiliser pandas.DataFrame ? Résumé de l'utilisation de l'instance pandas.DataFrame
- Méthode pandas.DataFrame pour créer de nouvelles colonnes et attribuer des valeurs en fonction des conditions