
Maison >base de données >tutoriel mysql >L'éditeur vous guide dans une analyse approfondie des principes des index SQL Server
L'éditeur vous guide dans une analyse approfondie des principes des index SQL Server

- 无忌哥哥original
- 2018-07-12 14:11:262475parcourir
En fait, vous pouvez comprendre l'index comme un répertoire spécial. L'article suivant vous présente principalement les informations pertinentes sur le principe de l'index SQL Server. L'article le présente en détail à travers un exemple de code. votre étude ou Le travail a une certaine valeur de référence et d'apprentissage. Amis qui en ont besoin, veuillez suivre l'éditeur pour apprendre ensemble
Avant-propos
Dans cet article, j'ai compilé mes notes précédentes et utilisé l'index comme point d'entrée pour discuter des connaissances pertinentes sur la base de données (et je l'ai modifié pour le rendre plus facile à digérer par les gens). Les amis qui sont nouveaux sur SQL Server peuvent simplement lire la police bleue suivante, ce qui est simple et utile pour gagner du temps ; si vous êtes un ami avec une bonne base de données, vous pouvez tout lire et n'hésitez pas à en discuter.
Le concept d'index
Le but de l'index : Notre vitesse d'interrogation et de traitement des données est devenue la norme pour mesurer le succès ou l'échec des systèmes d'application, et les index sont utilisés pour accélérer les données. La vitesse de traitement est souvent la méthode d'optimisation la plus couramment utilisée.
Qu'est-ce qu'un index : L'index dans la base de données est similaire à la table des matières d'un livre. L'utilisation de la table des matières d'un livre permet de trouver rapidement les informations souhaitées sans lire le livre en entier. Dans une base de données, les programmes de base de données utilisent des index pour récupérer les données d'une table sans avoir à analyser l'intégralité de la table. La table des matières du livre est une liste de mots et les numéros de page où se trouve chaque mot, et l'index dans la base de données est une liste de valeurs dans la table et l'emplacement de stockage de chaque valeur.
Avantages et inconvénients des index : la majeure partie de la surcharge d'exécution des requêtes est liée aux E/S. L'un des principaux objectifs de l'utilisation des index pour améliorer les performances est d'éviter les analyses de tables complètes, car les analyses de tables complètes nécessitent la lecture de toutes les données. de la table à partir de la page disque, s'il existe un index pointant vers la valeur des données, la requête n'a besoin que de lire le disque plusieurs fois. Par conséquent, une utilisation raisonnable des index peut accélérer les requêtes de données. Cependant, les index n'améliorent pas toujours les performances du système. Les tables indexées nécessitent plus d'espace de stockage dans la base de données. Les mêmes commandes utilisées pour ajouter et supprimer des données prennent plus de temps à s'exécuter et le temps de traitement requis pour maintenir l'index sera plus long. Par conséquent, nous devons utiliser les index de manière rationnelle et les mettre à jour en temps opportun pour supprimer les index sous-optimaux.
1. Index clusterisé et index non clusterisé
L'index est divisé en index clusterisé et index non clusterisé
1.1 Index clusterisé
Les données de la table sont stockées dans la page de données (la marque PageType de la page de données est 1. Une page de SqlServer fait 8k). . Si la page est pleine, elle sera ouverte. Si la table possède un index clusterisé, alors les données physiques une par une sont stockées dans la page par ordre croissant/décroissant en fonction de la taille du champ d'index clusterisé. Lorsque le champ d'index clusterisé est mis à jour ou que des données sont insérées/supprimées au milieu, les données de la table seront déplacées (ce qui aura un certain impact sur les performances) car elles doivent maintenir le tri ascendant/décroissant.
Notez que la clé primaire n'est qu'un index clusterisé par défaut. Elle peut également être définie comme un index non clusterisé, ou elle peut être définie comme un index clusterisé sur un index non primaire. champs clés. La table entière ne peut avoir qu'un seul index clusterisé.
Un excellent champ d'index clusterisé contient généralement les 4 caractéristiques suivantes :
(A) L'incrémentation automatique
est toujours au niveau. end Augmentez les enregistrements et réduisez la pagination et la fragmentation des index.
(B). Pas modifié
Réduire le mouvement des données.
(C). Unicité
L'unicité est la caractéristique la plus idéale de tout index, qui peut clarifier la position de la valeur de la clé d'index dans le tri.
Plus important encore, si la clé d'index est unique, elle peut pointer correctement vers la ligne de données source RID dans chaque enregistrement. Si la valeur de la clé d'index clusterisée n'est pas unique, SqlServer doit générer en interne une combinaison de colonnes uniquifier en tant que clé clusterisée pour garantir l'unicité de la « valeur de clé » si la valeur de la clé d'index non clusterisée n'est pas unique, une colonne RID ( clé d'index clusterisé ou table de tas) sera ajouté (pointeur de ligne) pour garantir l'unicité de la "valeur clé".
Réflexion (peut être ignorée) : La "valeur clé" de l'index est également garantie d'être unique dans les nœuds non-feuilles. La raison devrait être de clarifier la position de l'enregistrement d'index dans le nœud non-feuille. nœuds feuilles. Par exemple, il existe un champ d'index non clusterisé Name2. Il existe de nombreux enregistrements de Name2='a' dans la table, ce qui fait que Name2='a' a plusieurs enregistrements d'index (nœuds) sur des nœuds non-feuilles. , insérez Name2='a' record, vous pouvez déterminer rapidement quel enregistrement d'index (nœud) insérer en fonction du RID du nœud non-feuille et du RID du nouvel enregistrement s'il n'y a pas de RID du nœud non-feuille. , vous devez parcourir tous les Name2=' Seuls les nœuds feuilles de a' peuvent déterminer la position. De plus, lorsque nous sélectionnons * dans le tableau 1 où Name2<='a', les données renvoyées sont triées par index non clusterisé Name2 et RID. Il est facile de comprendre que les données renvoyées sont triées ici par ordre de stockage d'index. . Ceci est le résultat de l'utilisation de l'index Name2 dans cette requête SQL. Si le plan de requête de la base de données sélectionne l'analyse directe des données de la table en raison du problème du « point critique », les données renvoyées seront triées par défaut dans l'ordre des données de la table.
Pour l'unicité de la "valeur clé", pour les index clusterisés, la colonne uniquifier n'est incrémentée que lorsque la valeur de l'index est dupliquée. Pour les index non clusterisés, si l'unicité n'est pas définie lors de la création de l'index, RID sera incrémenté dans tous les enregistrements, même si la valeur de l'index est unique si l'unicité est définie lors de la création de l'index, RID ne sera incrémenté qu'au niveau feuille ; , qui est utilisé pour rechercher des lignes de données source, c'est-à-dire une opération de recherche de signets.
(D) Petite longueur de champ
Plus la longueur de la clé d'index clusterisé est petite, une page d'index peut accueillir plus d'enregistrements d'index, réduisant ainsi la profondeur de la structure de l'arbre B d'index. Par exemple, une table contenant des millions d'enregistrements a un index clusterisé int et peut nécessiter uniquement une structure B-tree à 3 niveaux. Si l'index clusterisé est défini sur une colonne plus large (par exemple, la colonne uniqueidentifier nécessite 16 octets), la profondeur de l'index passera à 4 niveaux. Toute recherche d'index clusterisé nécessite 4 opérations d'E/S (4 lectures logiques pour être exact), au lieu de seulement 3 opérations d'E/S.
De même, l'index non clusterisé contiendra la valeur de la clé d'index clusterisé. Plus la longueur de la clé d'index clusterisé est petite, plus l'enregistrement d'index non clusterisé sera petit. Une page d'index peut accueillir plus d'enregistrements d'index.
1.2 L'index non clusterisé
est également stocké dans les pages (les pages marquées de PageType 2 sont appelées pages d'index). Par exemple, la table T a établi un index non clusterisé Index_A. Si la table T contient 100 éléments de données, alors l'index Index_A aura également 100 éléments de données (100 éléments de données de nœud feuille pour être précis, et l'index est une structure B-tree. Si si la hauteur de l'arborescence est supérieure à 0, alors il y a des données de page de nœud racine ou de page de nœud intermédiaire, puis les données d'index dépassent 100). Index_B, alors Index_B a également au moins 100 données, donc l'index est construit plus. Plus il y en a, plus le coût est élevé.
La mise à jour des champs d'index, l'insertion d'une donnée et la suppression d'une donnée entraîneront la maintenance de l'index et auront un certain impact sur les performances. L'impact sur les performances est différent selon les situations. Par exemple, lorsque vous avez un index clusterisé, les données insérées sont toutes à la fin, ce qui ne provoquera presque jamais de mouvement de données et a un faible impact si les données insérées sont au milieu, cela provoquera généralement un mouvement de données, et peut le faire ; provoquera la pagination et la fragmentation, l'impact sera légèrement plus grand (si la page du milieu insérée a suffisamment d'espace restant pour accueillir les données insérées et que la position est à la fin de la page, cela ne provoquera pas de mouvement de données)
.
2. Structure d'index
On dit que l'index de SqlServer est une structure B-tree (on suppose que vous avez une certaine compréhension de la structure B-tree), alors de quoi s'agit-il exactement ? À quoi ressemble-t-il ? Vous pouvez utiliser des instructions SQL pour visualiser sa présentation logique.
Nouvelle syntaxe d'exécution des requêtes : DBCC IND(Test,OrderBo,-1) --La table OrderBo de la bibliothèque Test contient 10 000 éléments de données et possède un champ de clé primaire Id d'index clusterisé
(Autant créer vous-même une table, avec des champs d'index clusterisés, insérer 10 000 données de table, puis exécuter cette syntaxe pour voir. Vous gagnerez beaucoup, et il vaut mieux la voir que l'entendre cent fois)
Résultats de l'exécution :
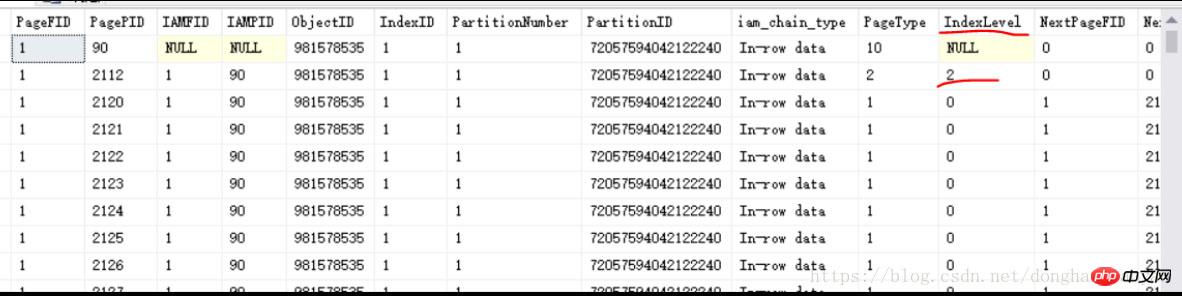
Comme le montre l'image ci-dessus, vous pouvez voir une page d'index 2112 avec IndexLevel=2 (ici, est le nœud racine de l'arbre B, et le plus grand IndexLevel est le nœud racine, et en dessous se trouve le sous-niveau, le sous-sous-niveau... il n'y a qu'une seule page racine comme point d'entrée d'accès du B-tree. arborescence), indiquant qu'il doit y avoir une page d'index avec IndexLevel=1 et une page feuille avec IndexLevel=0. Puisqu'il s'agit d'un index clusterisé, la page feuille lorsque IndexLevel=0 est la page de données, qui stocke les données physiques une par une. Comme vous pouvez le voir dans la figure ci-dessus, le PageType de la ligne avec IndexLevel=0 est égal à 1, ce qui représente la page de données. Lorsqu'on parle de l'index clusterisé au chapitre 1.1 ci-dessus, PageType=1 est également mentionné ; est un index non clusterisé, la page feuille avec IndexLevel=0 , PageType est égal à 2, qui est toujours une page d'index.
De même, nous utilisons la commande SQL DBCC PAGE pour y jeter un œil
-- DBCC TRACEON(3604,-1) DBCC PAGE(Test,1,2112,3) --根节点2112,可以查出它的两个子节点2280和2448,然后对这两个子节点再作DBCC PAGE查询 DBCC PAGE(Test,1,2280,3) DBCC PAGE(Test,1,2448,3)

Comme indiqué ci-dessus, la page 2112 avec IndexLevel=2 a deux nœuds enfants 2280 et 2448 avec IndexLevel=1. Il y a des nœuds enfants sous les nœuds enfants. Chaque nœud est responsable d'un index différent. plage de valeurs de clé (c'est-à-dire que dans le champ "Id(key)" de la figure ci-dessus, la valeur de la première ligne est Null, ce qui signifie la valeur minimale ou la valeur maximale dans l'ordre inverse). Une telle relation hiérarchique est-elle une structure B-tree, où IndexLevel est en fait la hauteur dans la structure B-tree.
Lorsque SqlServer recherche un certain enregistrement dans l'index, il trouve les nœuds feuilles à partir du nœud racine vers le bas, car toutes les adresses de données ont des nœuds feuilles. C'est en fait l'une des caractéristiques de l'arborescence B+. (La caractéristique de B-tree est que si la valeur que vous recherchez se trouve dans un nœud non-feuille, elle peut être renvoyée directement. Évidemment, SqlServer ne le fait pas. Pour vérifier cela, vous pouvez activer les statistiques io pour activer sur les statistiques, puis sélectionnez pour voir le nombre de lectures logiques).
Étant donné que le nœud feuille sera définitivement trouvé, l'index contenant les colonnes ne doit être enregistré qu'au niveau des nœuds feuilles, c'est-à-dire que les nœuds non-feuille n'enregistrent pas les colonnes contenant. "index contenant des colonnes".
Les caractéristiques de l'arbre B+ (les nœuds feuilles existent dans toutes les adresses de données) sont également propices aux requêtes par intervalles entre valeur1 et valeur2. Tant que vous trouvez valeur1 et valeur2 (au niveau des nœuds feuilles), alors. enchaînez-les ensemble. Le résultat était.
La structure de l'index SqlServer ressemble plus à un arbre B+, et finalement à une version hybride d'un arbre B et d'un arbre B+. La structure des données est déterminée par les personnes, et ne l'est pas. nécessairement un arbre B pur ou un arbre B+ pur.
3. L'index contient des colonnes et une recherche de signets
En parlant d'index, voici un autre "index contenant une colonne" ajouté depuis SqlServer2005 Fonctionnel, très pratique.
Par exemple, lors de l'interrogation de données dans un rapport volumineux, la condition Where utilise le champ d'index Nom2, mais le champ à sélectionner est Nom1. À ce stade, vous pouvez utiliser "index. "Colonne incluse" pour inclure Nom1 dans le champ d'index Nom2, les performances des requêtes sont grandement améliorées.
Syntaxe : Créer [UNIQUE] Index non clusterisé/clustérisé IndexName On dbo.Table1(Name2) Include(Name1);
Analyser ensuite pourquoi l'index contient Les colonnes peuvent grandement améliorer les performances. Utilisez toujours la commande DBCC PAGE pour afficher un index non clusterisé avec des données d'index contenant des colonnes :

Comme le montre la figure ci-dessus, la colonne contenant Name1 est également stocké dans l'index des données. Par conséquent, lorsque la base de données utilise le champ d'index Name2 pour localiser une certaine ligne à rechercher, elle peut renvoyer directement la valeur de Name1 sans avoir à la localiser dans la page de données basée sur le RID (l'image ci-dessus est le [HEAP RID ( Clé)] colonne) Pour obtenir la valeur, cela réduit la recherche de signets. Bien sûr, cela n'a pas d'importance lorsque la requête ne renvoie qu'une seule donnée et une seule recherche de signets. Si les données renvoyées par la requête sont volumineuses, vous devez accéder à la page de données pour rechercher les données et les récupérer. les enregistrements signifient 1 000 recherches de signets. Vous pouvez imaginer la consommation de performances très importante, à ce moment-là, la valeur de « l'index contient des colonnes » est grandement reflétée.
Concernant une recherche de favoris, lorsque la table a un index clusterisé (tel que Id), cela revient à exécuter une sélection Name1 from Table1 où Id=1, en utilisant la clé d'index clusterisé Id pour rechercher (la méthode de recherche est la recherche de structure d'arbre B d'ID d'index), et si la table n'a pas d'index clusterisé, elle est recherchée en fonction du pointeur de ligne de données (composé de "numéro de fichier 2 octets : numéro de page 4 octets : numéro d'emplacement 2 octets "). Les clés d'index groupées et les pointeurs de ligne sont généralement appelés pointeurs RID (Row ID). À partir de là, nous pouvons penser : Si votre table n'a pas un bon champ d'index clusterisé, il est recommandé d'utiliser le champ Id à croissance automatique comme clé primaire de l'index clusterisé (les champs Id redondants sont également acceptables), ce qui est compatible avec l'auto-croissance et ne sera pas modifié. Son caractère unique et sa petite longueur en font un bon choix pour les index groupés.
L'ID auto-augmentation est applicable dans la plupart des cas. Dans des cas particuliers, cela dépend des besoins spécifiques. Il existe également un défaut à prendre en compte dans l'ID auto-croissant. Lors de l'insertion simultanée d'enregistrements contenant une grande quantité de données dans la table, il est concevable que chaque thread doive insérer jusqu'à la dernière page, ce qui entraînerait une concurrence et une attente. Pour résoudre cette situation, vous pouvez utiliser des champs de type identifiant unique (16 octets, ce que je ne recommande pas) ou un partitionnement par hachage (c'est-à-dire qu'une table est divisée en plusieurs tables. Il est normal de diviser les bases de données et les tables dans le traitement du Big Data), etc. Mais je recommande d'abord d'optimiser l'efficacité de votre insertion (les performances d'insertion elles-mêmes sont très rapides) et de tester si le nombre d'insertions simultanées par seconde correspond à l'environnement de production, afin de conserver la méthode d'identification à auto-augmentation simple, stable et efficace.
L'identifiant auto-croissant ne signifie pas nécessairement utiliser celui auto-croissant fourni par la base de données. Vous pouvez également écrire votre propre algorithme pour générer un identifiant unique dans des situations concurrentes (le. la longueur générale à l'heure actuelle est de bitint, mise en forme de 8 octets), cette situation convient au scénario où le champ Id ne doit pas être exempt d'erreurs lors de la réplication maître-esclave dans une base de données distribuée (dans le mode général de réplication maître-esclave, l'identifiant de la base de données maître augmente en fonction de la base de données maître et de la base de données esclave. L'identifiant augmente également en fonction de la bibliothèque esclave elle-même. Si la réplication maître-esclave est désynchronisée en raison d'un blocage ou d'autres raisons, l'identifiant de l'esclave. la bibliothèque ne correspondra pas à l'ID de la bibliothèque principale.) Si l'ID à croissance automatique est une clé primaire redondante, il n'y aura aucun impact si l'ID de la base de données maître-esclave ne correspond pas au numéro.
De plus, la dernière colonne [Row Size] dans l'image ci-dessus nous indique également, La taille de la colonne d'index ou de la colonne contenant l'index ne doit pas être trop longue, sinon, une page ne pourra pas contenir plusieurs enregistrements. Cela augmente considérablement le nombre de pages d'index, et l'espace occupé par les données d'index est également considérablement augmenté.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!