
Maison >base de données >tutoriel mysql >Le principe sous-jacent de mise en œuvre de l'index mysql
Le principe sous-jacent de mise en œuvre de l'index mysql

- 无忌哥哥original
- 2018-07-12 10:14:291534parcourir
La structure des données et les principes de l'algorithme derrière les index MySQL
1 Définition
Définition de l'index : l'index (index) doit aider MySQL. Être efficace Obtenez la structure des données.
Essence : L'index est une structure de données.
2. B-Tree
B-Tree d'ordre m satisfait aux conditions suivantes :
1. Chaque nœud peut avoir au plus m sous-arbres.
2. Le nœud racine n'a qu'au moins 2 nœuds (ou dans les cas extrêmes, un arbre n'a qu'un seul nœud racine, un organisme unicellulaire est une racine, une feuille et un arbre).
3. Les nœuds non racines et non feuilles ont au moins des sous-arbres Ceil (m/2) (Ceil signifie arrondir, comme un arbre B d'ordre 5, chaque nœud a au moins 3 sous-arbres, c'est-à-dire il y a au moins 3 fourchettes).
4. Les informations dans les nœuds non-feuilles incluent [n,A0,K1,A1,K2,A2,…,Kn,An], où n représente le nombre de mots-clés enregistrés dans le nœud et K est le mot-clé. Et Ki
Caractéristiques du B-Tree :
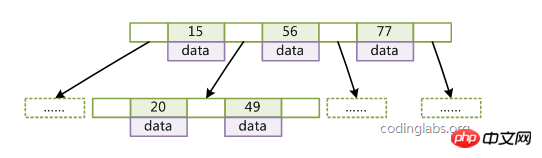
1. L'ensemble de mots-clés est distribué dans l'arborescence ;
2. Tout mot-clé apparaît et n'apparaît que dans un seul nœud
3. un nœud non-feuille ;
5. Les clés d'un nœud sont disposées de manière non décroissante de gauche à droite
6. Tous les nœuds feuilles ont la même profondeur, qui est égale à la hauteur de l'arbre h.

3.
La différence entre B+Tree et B-Tree est :1. Les nœuds non-feuilles B+Tree ne stockent pas de données, seules les clés  2. sur les nœuds feuilles
2. sur les nœuds feuilles
4. et contient uniquement le mot-clé le plus grand (ou le plus petit) dans son sous-arbre (nœud racine
4. Analyse des performances de l'index de l'arborescence B/B+
Base ; : Utilisez le nombre d'E/S de disque pour évaluer la qualité de la structure d'index Données d'échange de mémoire principale et de disque en unités de page Définissez la taille d'un nœud sur une page, de sorte que chaque nœud n'ait besoin que d'une seule E/S. . Entièrement chargé. Selon la définition du B-tree, on peut voir qu'il faut accéder à un maximum de h nœuds pour une récupération
Complexité asymptotique : O(h)=O(logdN) dmax=floor (pagesize/(keysize+datasize+pointsize) )
Dans les applications pratiques générales, le degré extérieur d est un très grand nombre, généralement supérieur à 100, donc h est très petit (généralement pas plus de 3, et la couche 3 peut stocker environ un million de données)
Une fois dans B-Tree, la récupération nécessite au plus h-1 E/S (mémoire résidente du nœud racine)
Les nœuds de B+Tree ne contiennent pas de champs de données, donc le degré sortant d est plus grand, h est plus petit, le nombre d'E/S est inférieur et l'efficacité est plus élevée, donc B+Tree est plus adapté aux index de stockage externes.
5. Implémentation de l'index MySQL
2. d'InnoDB lui-même est le fichier d'index et le nœud feuille contient les enregistrements de données complets, cet index est appelé index clusterisé. Étant donné que les fichiers de données d'InnoDB eux-mêmes sont agrégés par clé primaire, InnoDB exige que la table ait une clé primaire (MyISAM peut ne pas en avoir une). Si cela n'est pas explicitement spécifié, le système MySQL sélectionnera automatiquement une colonne qui peut identifier de manière unique la table. enregistrement de données comme clé primaire. Si une telle colonne n'existe pas, MySQL génère automatiquement un champ implicite comme clé primaire pour la table InnoDB.
Le champ de données d'index auxiliaire d'InnoDB stocke la valeur de la clé primaire de l'enregistrement correspondant au lieu de l'adresse
La recherche d'index auxiliaire doit récupérer l'index deux fois : récupérez d'abord l'index auxiliaire pour obtenir la clé primaire, et puis utilisez la clé primaire pour récupérer l'enregistrement dans l'index primaire ;
3. Problème de fractionnement de page
Si la clé primaire augmente de manière monotone, chaque nouvelle. l'enregistrement sera inséré dans la page de manière séquentielle. Lorsque la page est pleine, continuez Insérer dans une nouvelle page
Si les écritures sont dans le désordre, InnoDB doit effectuer des fractionnements de page fréquemment pour allouer de l'espace pour de nouvelles lignes. Le fractionnement des pages entraîne le déplacement de grandes quantités de données ; une insertion nécessite la modification d'au moins trois pages au lieu d'une. 
6. Résumé
Comprendre les méthodes de mise en œuvre des index des différents moteurs de stockage est très utile pour une utilisation correcte et l'optimisation des index1. ce n'est pas recommandé ? Utiliser un champ trop long comme clé primaire ?
2. Pourquoi choisir un champ à incrémentation automatique comme clé primaire ?
3. Pourquoi n'est-il pas recommandé de créer un index pour les champs fréquemment mis à jour ?
4. Pourquoi choisir une colonne hautement différenciée comme index ? La formule de distinction est count(distinct col)/count(*)
5. Utilisez l'index de couverture autant que possible
Optimisez la requête de pagination LIMIT
SELECT * FROM table where condition LIMIT offset , rows ;Le mécanisme d'implémentation de l'instruction SQL ci-dessus est :
1. Lisez les enregistrements de ligne offset+rows de la table "table".
2. Abandonnez l'enregistrement de ligne décalé précédent et renvoyez l'enregistrement de ligne des lignes suivantes comme résultat final.
Index couvert :
select a.id, sid, parent_s_id from cashpool_account_relationship a join (select id from cashpool_account_relationship LIMIT 1000000,10)b on a.id = b.id; select id, sid, parent_s_id from cashpool_account_relationship where id >=(select id from cashpool_account_relationship LIMIT 1000000,1) LIMIT 10;
8 Questions et réponses
1. --Ma XinInnoDB prend en charge l'index de hachage, mais l'index de hachage qu'il prend en charge est adaptatif. Le moteur de stockage InnoDB générera automatiquement un index de hachage pour la table en fonction de l'utilisation de la table. dans un index.
2. Les nœuds feuilles de l'index de clé primaire InnoDB contiennent des enregistrements de données complets. Le fichier d'index de clé primaire est-il plus grand que le fichier de données ? --Xu Caihou
1). Dans le moteur Innodb, les nœuds feuilles de l'index de clé primaire contiennent des données d'enregistrement et le fichier d'index de clé primaire est le fichier de données.
2). Les données data_length comptées dans la table tables sont la taille de l'index de clé primaire, et index_length est la taille comptée de tous les index auxiliaires (index secondaires) dans cette table. 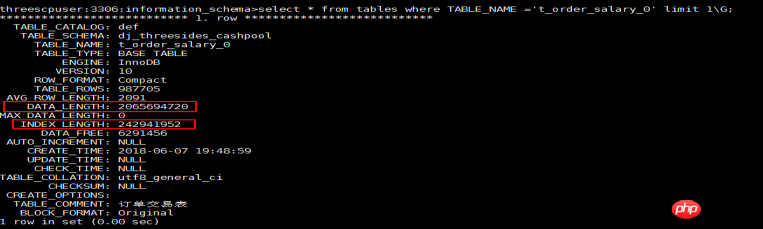
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!