
Maison >développement back-end >Tutoriel Python >pytorch + visdom Méthode CNN de traitement des ensembles de données d'image auto-construits
pytorch + visdom Méthode CNN de traitement des ensembles de données d'image auto-construits

- 不言original
- 2018-06-04 16:19:004077parcourir
Cet article présente principalement la méthode de pytorch + visdom CNN pour traiter les ensembles de données d'images auto-construits. Il a une certaine valeur de référence. Maintenant, je le partage avec vous. Les amis dans le besoin peuvent s'y référer
<.> Environnement
Système : win10cpu : i7-6700HQgpu : gtx965mpython : 3.6 pytorch : 0.3Téléchargement de données
Provenant du didacticiel de Sasank Chilamkurthy Données : lien de téléchargement. 
Importation de données
Vous pouvez utiliser le module torchvision.datasets.ImageFolder(root,transforms) pour convertir des images en tenseurs.ata_transforms = {
'train': transforms.Compose([
# 随机切成224x224 大小图片 统一图片格式
transforms.RandomResizedCrop(224),
# 图像翻转
transforms.RandomHorizontalFlip(),
# totensor 归一化(0,255) >> (0,1) normalize channel=(channel-mean)/std
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
]),
"val" : transforms.Compose([
# 图片大小缩放 统一图片格式
transforms.Resize(256),
# 以中心裁剪
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
}Importez et chargez les données :
data_dir = './hymenoptera_data'
# trans data
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x), data_transforms[x]) for x in ['train', 'val']}
# load data
data_loaders = {x: DataLoader(image_datasets[x], batch_size=BATCH_SIZE, shuffle=True) for x in ['train', 'val']}
data_sizes = {x: len(image_datasets[x]) for x in ['train', 'val']}
class_names = image_datasets['train'].classes
print(data_sizes, class_names){'train': 244, 'val': 153} ['ants', 'bees']L'ensemble de formation contient 244 images et l'ensemble de test contient 153 images. Jetez un œil à la partie visuelle de l'image puisque visdom prend en charge la saisie du tenseur, vous n'avez pas besoin de la changer en numpy. Vous pouvez directement utiliser le calcul du tenseur :
.
inputs, classes = next(iter(data_loaders['val'])) out = torchvision.utils.make_grid(inputs) inp = torch.transpose(out, 0, 2) mean = torch.FloatTensor([0.485, 0.456, 0.406]) std = torch.FloatTensor([0.229, 0.224, 0.225]) inp = std * inp + mean inp = torch.transpose(inp, 0, 2) viz.images(inp)

Create CNN
net a modifié les spécifications en fonction du traitement de cifar10 par l'article précédent :class CNN(nn.Module):
def __init__(self, in_dim, n_class):
super(CNN, self).__init__()
self.cnn = nn.Sequential(
nn.BatchNorm2d(in_dim),
nn.ReLU(True),
nn.Conv2d(in_dim, 16, 7), # 224 >> 218
nn.BatchNorm2d(16),
nn.ReLU(inplace=True),
nn.MaxPool2d(2, 2), # 218 >> 109
nn.ReLU(True),
nn.Conv2d(16, 32, 5), # 105
nn.BatchNorm2d(32),
nn.ReLU(True),
nn.Conv2d(32, 64, 5), # 101
nn.BatchNorm2d(64),
nn.ReLU(True),
nn.Conv2d(64, 64, 3, 1, 1),
nn.BatchNorm2d(64),
nn.ReLU(True),
nn.MaxPool2d(2, 2), # 101 >> 50
nn.Conv2d(64, 128, 3, 1, 1), #
nn.BatchNorm2d(128),
nn.ReLU(True),
nn.MaxPool2d(3), # 50 >> 16
)
self.fc = nn.Sequential(
nn.Linear(128*16*16, 120),
nn.BatchNorm1d(120),
nn.ReLU(True),
nn.Linear(120, n_class))
def forward(self, x):
out = self.cnn(x)
out = self.fc(out.view(-1, 128*16*16))
return out
# 输入3层rgb ,输出 分类 2
model = CNN(3, 2)perte, fonction d'optimisation :
line = viz.line(Y=np.arange(10)) loss_f = nn.CrossEntropyLoss() optimizer = optim.SGD(model.parameters(), lr=LR, momentum=0.9) scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)Paramètres :
BATCH_SIZE = 4 LR = 0.001 EPOCHS = 10Courez pendant 10 époques et voyez :
[9/10] train_loss:0.650|train_acc:0.639|test_loss:0.621|test_acc0.706 [10/10] train_loss:0.645|train_acc:0.627|test_loss:0.654|test_acc0.686 Training complete in 1m 16s Best val Acc: 0.712418
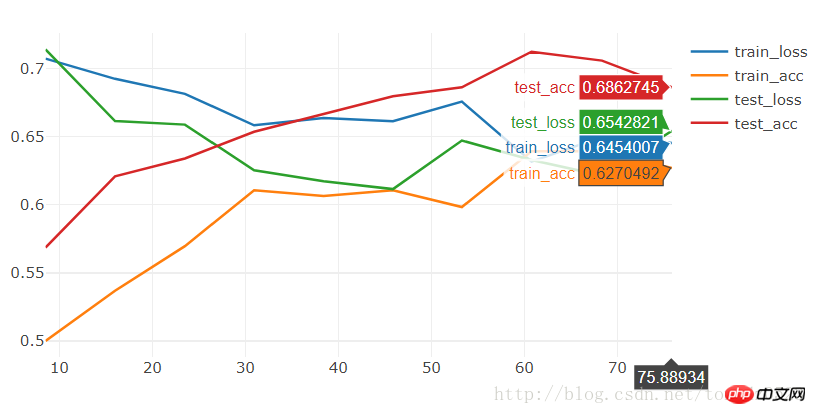
[19/20] train_loss:0.592|train_acc:0.701|test_loss:0.563|test_acc0.712 [20/20] train_loss:0.564|train_acc:0.721|test_loss:0.571|test_acc0.706 Training complete in 2m 30s Best val Acc: 0.745098
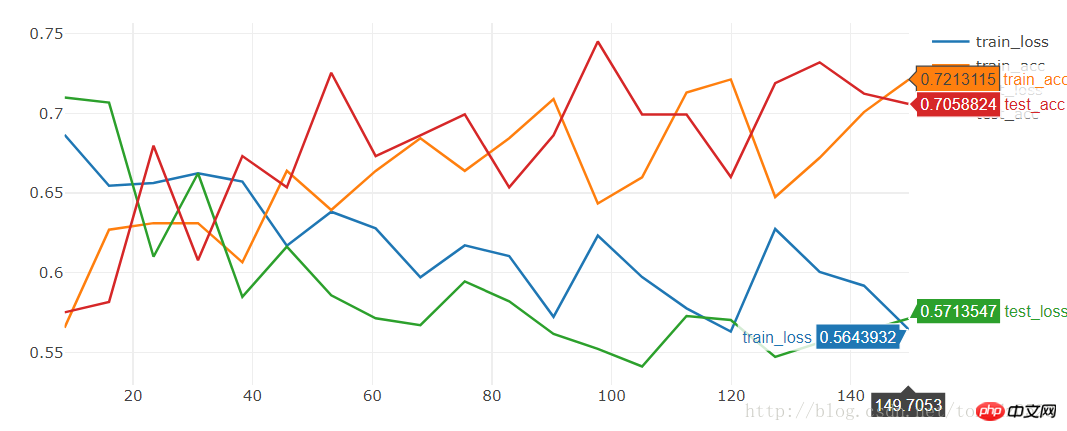
model = torchvision.models.resnet18(True) num_ftrs = model.fc.in_features model.fc = nn.Linear(num_ftrs, 2)
[9/10] train_loss:0.621|train_acc:0.652|test_loss:0.588|test_acc0.667 [10/10] train_loss:0.610|train_acc:0.680|test_loss:0.561|test_acc0.667 Training complete in 1m 24s Best val Acc: 0.686275L'effet est également très moyen. Si nous voulons former des modèles avec de bons résultats en peu de temps, nous pouvons télécharger l'état formé et nous entraîner sur cette base :
model = torchvision.models.resnet18(pretrained=True) num_ftrs = model.fc.in_features model.fc = nn.Linear(num_ftrs, 2)
[9/10] train_loss:0.308|train_acc:0.877|test_loss:0.160|test_acc0.941 [10/10] train_loss:0.267|train_acc:0.885|test_loss:0.148|test_acc0.954 Training complete in 1m 25s Best val Acc: 0.95424810 époques atteignent directement une précision de 95%.
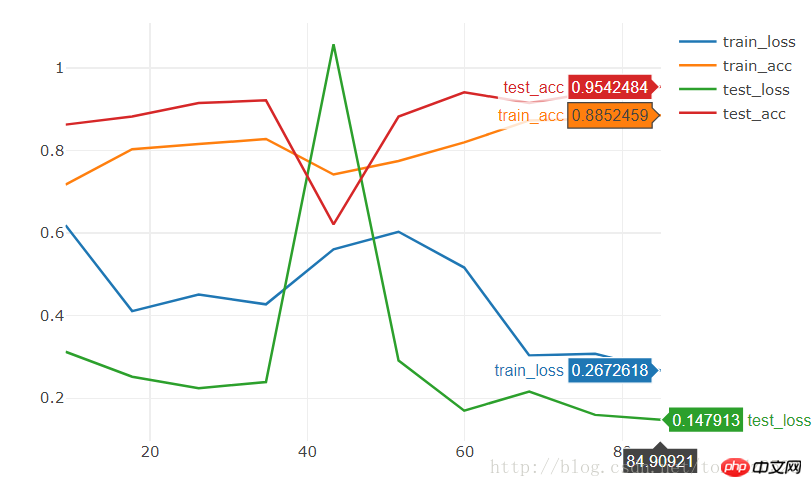
pytorch
+ Visdom gère des problèmes de classification simples
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Déclaration:
Le contenu de cet article est volontairement contribué par les internautes et les droits d'auteur appartiennent à l'auteur original. Ce site n'assume aucune responsabilité légale correspondante. Si vous trouvez un contenu suspecté de plagiat ou de contrefaçon, veuillez contacter admin@php.cn