
Maison >développement back-end >Tutoriel Python >Comment utiliser le package Requests de Python pour implémenter une connexion simulée
Comment utiliser le package Requests de Python pour implémenter une connexion simulée

- 不言original
- 2018-05-02 14:22:202988parcourir
Cet article présente principalement en détail l'utilisation du package Requests de Python pour simuler la connexion. Il a une certaine valeur de référence. Les amis intéressés peuvent s'y référer
J'ai aimé utiliser Python pour récupérer certaines pages il y a quelque temps. Jouez, mais ils utilisent essentiellement get pour demander certaines pages, puis les filtrer selon les règles habituelles.
Je l'ai essayé aujourd'hui et j'ai simulé une connexion à mon site Web personnel. La découverte est également relativement simple. La lecture de cet article nécessite une certaine compréhension du protocole http et des sessions http.
Remarque : Étant donné que la connexion simulée est mon site Web personnel, le code suivant gère le site Web personnel et le mot de passe du compte.
Analyse du site Web
La première étape essentielle pour les robots d'exploration est d'analyser le site Web cible. Ici, nous utilisons les outils de développement de Google Chrome pour l'analyse.
Récupérez via la connexion et voyez une telle demande.
La partie supérieure est l'en-tête de la requête, et la partie inférieure est les paramètres transmis par la requête. Comme le montre l'image, la page soumet trois paramètres via le formulaire. Il s'agit respectivement de _csrf, usermane et password.
Le csrf vise à empêcher la falsification de scripts inter-domaines. Le principe est très simple, c'est à dire que pour chaque requête, le serveur génère une chaîne cryptée. Placez-le dans un formulaire de saisie masqué. Lorsque vous effectuez une autre demande, transmettez cette chaîne ensemble pour vérifier s'il s'agit d'une demande du même utilisateur.
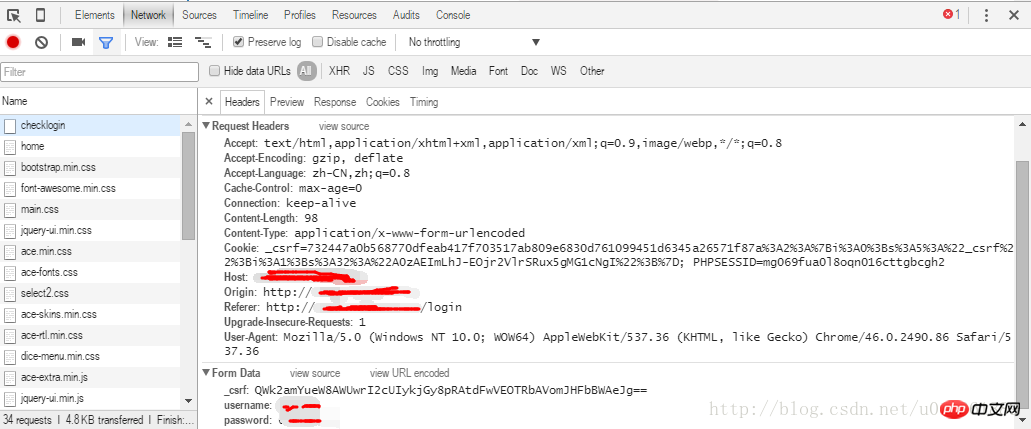
Donc, notre logique de code est là. Commencez par demander une page de connexion. Analysez ensuite la page et récupérez la chaîne csrf. Enfin, cette chaîne et le mot de passe du compte sont transmis au serveur pour la connexion.
Le premier code
#!/usr/bin/env python2.7
# -*- coding: utf-8 -*-
import requests
import re
# 头部信息
headers = {
'Host':"localhost",
'Accept-Language':"zh-CN,zh;q=0.8",
'Accept-Encoding':"gzip, deflate",
'Content-Type':"application/x-www-form-urlencoded",
'Connection':"keep-alive",
'Referer':"http://localhost/login",
'User-Agent':"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.86 Safari/537.36"
}
# 登陆方法
def login(url,csrf):
data = {
"_csrf" : csrf,
"username": "xiedj",
"password": "***"
}
response = requests.post(url, data=data, headers=headers)
return response.content
# 第一次访问获取csrf值
def get_login_web(url):
page = requests.get('http://localhost/login')
reg = r'<meta name="csrf-token" content="(.+)">'
csrf = re.findall(reg,page.content)[0]
login_page = login(url,csrf)
print login_page
if __name__ == "__main__":
url = "http://localhost/login/checklogin"
get_login_web(url)
Le code semble n'avoir aucun problème. Cependant, une erreur s'est produite lors de l'exécution. Après vérification, la raison de l'erreur est que la vérification CSRF a échoué !
Après avoir confirmé à plusieurs reprises que le csrf obtenu et la chaîne csrf demandée pour se connecter étaient OK, j'ai pensé à une question.
Si vous ne connaissez toujours pas la cause de l'erreur, vous pouvez faire une pause et réfléchir à un problème ici. "Comment le serveur sait-il que la première demande de csrf et la deuxième demande de post-connexion proviennent du même utilisateur ?"
À ce stade, cela devrait être clair. Si vous souhaitez vous connecter avec succès, vous devez le faire. pour résoudre comment faire croire au service que les deux demandes proviennent du même utilisateur. Vous devez utiliser la session http ici (si vous n'êtes pas sûr, vous pouvez Baidu vous-même, voici une brève introduction).
Le protocole http est un protocole sans état. Pour que cet apatride devienne avec état, des sessions ont été introduites. Pour faire simple, enregistrez ce statut tout au long de la session. Lorsqu'un utilisateur demande un service Web pour la première fois, le serveur génère une session pour enregistrer les informations de l'utilisateur. Parallèlement, lors du retour à l'utilisateur, l'identifiant de session est enregistré dans des cookies. Lorsque l'utilisateur redemande, le navigateur apportera ce cookie avec lui. Par conséquent, le serveur peut savoir si plusieurs requêtes concernent le même utilisateur.
Par conséquent, notre code doit obtenir cet ID de session lors de la première requête. Transmettez cet ID de session avec la deuxième requête. L’avantage des requêtes est que vous pouvez utiliser cet objet de session avec une simple requête.Session().
Le deuxième code
#!/usr/bin/env python2.7
# -*- coding: utf-8 -*-
import requests
import re
# 头部信息
headers = {
'Host':"localhost",
'Accept-Language':"zh-CN,zh;q=0.8",
'Accept-Encoding':"gzip, deflate",
'Content-Type':"application/x-www-form-urlencoded",
'Connection':"keep-alive",
'Referer':"http://localhost/login",
'User-Agent':"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.86 Safari/537.36"
}
# 登陆方法
def login(url,csrf,r_session):
data = {
"_csrf" : csrf,
"username": "xiedj",
"password": "***"
}
response = r_session.post(url, data=data, headers=headers)
return response.content
# 第一次访问获取csrf值
def get_login_web(url):
r_session = requests.Session()
page = r_session.get('http://localhost/login')
reg = r'<meta name="csrf-token" content="(.+)">'
csrf = re.findall(reg,page.content)[0]
login_page = login(url,csrf,r_session)
print login_page
if __name__ == "__main__":
url = "http://localhost/login/checklogin"
get_login_web(url)
La page après une connexion réussie
Vous pouvez savoir grâce au code qu'après le démarrage de la requête.Session() de l'objet de session, la deuxième requête transmettra automatiquement le dernier ID de session ensemble.
Recommandations associées :
Comment utiliser Python pour exporter des graphiques Excel et les exporter sous forme d'images
Analyse de l'open fonction utilisant python Raisons de l'erreur No Such File or DIr
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!