
Maison >développement back-end >Tutoriel Python >Explication détaillée des indicateurs d'évaluation de classification et des indicateurs d'évaluation de régression et mise en œuvre du code Python
Explication détaillée des indicateurs d'évaluation de classification et des indicateurs d'évaluation de régression et mise en œuvre du code Python

- 零到壹度original
- 2018-04-16 11:11:1711553parcourir
Le contenu de cet article est une explication détaillée des indicateurs d'évaluation de classification et des indicateurs d'évaluation de régression ainsi que de l'implémentation du code Python. Il a une certaine valeur de référence. Maintenant, je le partage avec vous. .
1. Concept
Les indicateurs de mesure de performance (évaluation) sont principalement divisés en deux catégories :
1) Les indicateurs d'évaluation de classification (classification), principalement d'analyse, discrets, entiers. Ses indicateurs spécifiques incluent l'exactitude (exactitude), la précision (précision), le rappel (rappel), la valeur F, la courbe P-R, la courbe ROC et l'AUC.
2) Indice d'évaluation de régression (régression), analyse principalement la relation entre les nombres entiers et les nombres réels. Ses indicateurs spécifiques incluent explianed_variance_score, erreur absolue moyenne MAE (mean_absolute_error), erreur quadratique moyenne MSE (mean-squared_error), différence quadratique moyenne RMSE, perte d'entropie croisée (perte de log, perte d'entropie croisée), valeur R carré (coefficient de détermination , r2_score).
1.1. Prémisse
Supposons qu'il n'y ait que deux catégories - positive et négative. Habituellement, la catégorie préoccupante est la catégorie positive et les autres catégories sont les catégories négatives (par conséquent, plusieurs types de problèmes peuvent également être résumés en deux catégories)
La matrice de confusion est la suivante
| Catégorie réelle | Catégorie prédite | |||||||||||||||||||||||
|
Positif | Négatif | Résumé | td > |
||||||||||||||||||||
| Positif | TP | FN | P (réellement positif) | |||||||||||||||||||||
| Négatif | FP | TN | N (réellement négatif) | |||||||||||||||||||||
Mode AB dans le tableau : le premier indique si le résultat de la prédiction est bon ou faux, et le second indique la catégorie de prédiction. Par exemple, TP signifie Vrai Positif, c'est-à-dire que la prédiction correcte est la classe positive ; FN signifie Faux Négatif, c'est-à-dire que la mauvaise prédiction est la classe négative.
2. Indicateurs d'évaluation (mesure des performances)2.1. Indicateurs d'évaluation de classification| 度量 | Accuracy(准确率) | Precision(精确率) | Recall(召回率) | F值 |
| 定义 | 正确分类的样本数与总样本数之比(预测为垃圾短信中真正的垃圾短信的比例) | 判定为正例中真正正例数与判定为正例数之比(所有真的垃圾短信被分类求正确找出来的比例) | 被正确判定为正例数与总正例数之比 | 准确率与召回率的调和平均F-score |
| 表示 | accuracy=
|
precision=
|
recall=
|
F - score =
|
| Métrique | Précision | Précision | Rappel (taux de rappel) td> | Valeur F |
| Définition | Le rapport entre le nombre d'échantillons correctement classés et le nombre total d'échantillons (la prédiction est la proportion de vrais messages texte de spam parmi les messages texte de spam) | Le rapport entre le nombre d'exemples vrais positifs parmi les exemples positifs et le nombre d'exemples positifs (tous les vrais messages texte de spam sont classés et la proportion de messages corrects est trouvée ) | Le rapport entre le nombre de cas positifs correctement jugés et le nombre total de cas positifs | La moyenne harmonique F-score td> |
| Représentation | accuracy=
|
precision= td> |
rappel=
|
F - score = |
1. La précision est aussi souvent appelée taux de précision, et le rappel est appelé taux de rappel
2. Le plus couramment utilisé est F1,
Code Python3.6 mise en œuvre :
#调用sklearn库中的指标求解from sklearn import metricsfrom sklearn.metrics import precision_recall_curvefrom sklearn.metrics import average_precision_scorefrom sklearn.metrics import accuracy_score#给出分类结果y_pred = [0, 1, 0, 0]
y_true = [0, 1, 1, 1]
print("accuracy_score:", accuracy_score(y_true, y_pred))
print("precision_score:", metrics.precision_score(y_true, y_pred))
print("recall_score:", metrics.recall_score(y_true, y_pred))
print("f1_score:", metrics.f1_score(y_true, y_pred))
print("f0.5_score:", metrics.fbeta_score(y_true, y_pred, beta=0.5))
print("f2_score:", metrics.fbeta_score(y_true, y_pred, beta=2.0))2.1.2 Courbe de corrélation-courbe P-R, courbe ROC et valeur AUC
1) Courbe P-R
Étapes :
1. Définir le score à partir de haut aux valeurs "faibles" sont triées et utilisées tour à tour comme seuils ;
2. Pour chaque seuil, les échantillons de test avec une valeur de "score" supérieure ou égale à ce seuil sont considérés comme des exemples positifs, et les autres sont des exemples négatifs. Formant ainsi un ensemble de chiffres prévisionnels.
par exemple. 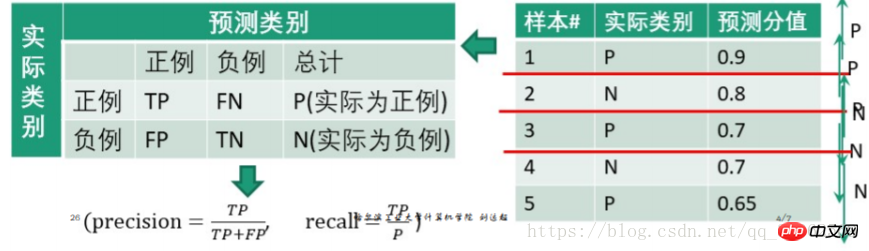
Définissez 0,9 comme seuil, puis le premier échantillon test est un exemple positif, et 2, 3, 4 et 5 sont des exemples négatifs
Obtenez
| 预测为正例 | 预测为负例 | 总计 | |
| 正例(score大于阈值) | 0.9 | 0.1 | 1 |
| 负例(score小于阈值) | 0.2+0.3+0.3+0.35 = 1.15 | 0.8+0.7+0.7+0.65 = 2.85 | 4 |
| precision= recall=
| |||
#precision和recall的求法如上
#主要介绍一下python画图的库
import matplotlib.pyplot ad plt
#主要用于矩阵运算的库
import numpy as np#导入iris数据及训练见前一博文
...
#加入800个噪声特征,增加图像的复杂度
#将150*800的噪声特征矩阵与150*4的鸢尾花数据集列合并
X = np.c_[X, np.random.RandomState(0).randn(n_samples, 200*n_features)]
#计算precision,recall得到数组
for i in range(n_classes):
#计算三类鸢尾花的评价指标, _作为临时的名称使用
precision[i], recall[i], _ = precision_recall_curve(y_test[:, i], y_score[:,i])#plot作图plt.clf()
for i in range(n_classes):
plt.plot(recall[i], precision[i])
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel("Recall")
plt.ylabel("Precision")
plt.show()
rappel=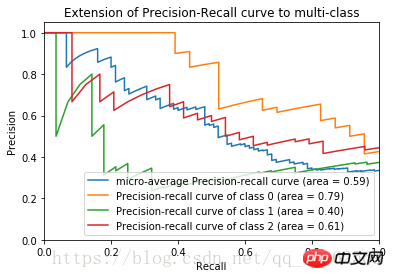
La partie en dessous du seuil, à titre d'exemple négatif, la valeur de l'exemple négatif prédit est la valeur prédite correcte, c'est-à-dire que s'il s'agit d'un exemple positif, TP est pris s'il s'agit d'un exemple négatif, TN est pris ; , qui sont tous deux des scores de prédiction.
Python implémente le pseudo-code
Après avoir terminé le code ci-dessus, la courbe P-R de l'ensemble de données sur la fleur d'iris est obtenue
2) Courbe ROC
Horizontale axe : Taux de faux positifs taux fp = FP/NAxe vertical : taux vrai taux tp = TP/N
Étapes :  1. Trier les valeurs du « score » de haut en bas et les utiliser comme seuils dans l'ordre ;
1. Trier les valeurs du « score » de haut en bas et les utiliser comme seuils dans l'ordre ;
2. Pour chaque seuil, les échantillons de test dont la valeur "score" est supérieure ou égale à ce seuil sont considérés comme des exemples positifs, et les autres sont des exemples négatifs. Formant ainsi un ensemble de chiffres prévisionnels. 
Il est similaire au calcul de la courbe P-R et ne sera pas décrit à nouveau
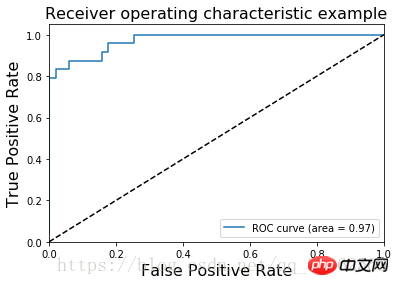
L'image ROC de l'ensemble de données sur la fleur d'iris est 
 L'AUC (Area Under Curve) est définie comme l'aire sous la courbe ROC
L'AUC (Area Under Curve) est définie comme l'aire sous la courbe ROC
La valeur AUC fournit une valeur numérique globale pour le classificateur. Habituellement, plus l'AUC est grande, meilleur est le classificateur et la valeur est [0, 1]
2.2 Indice d'évaluation de régression 1) Score de variance explicative
1) Score de variance explicative
<.>
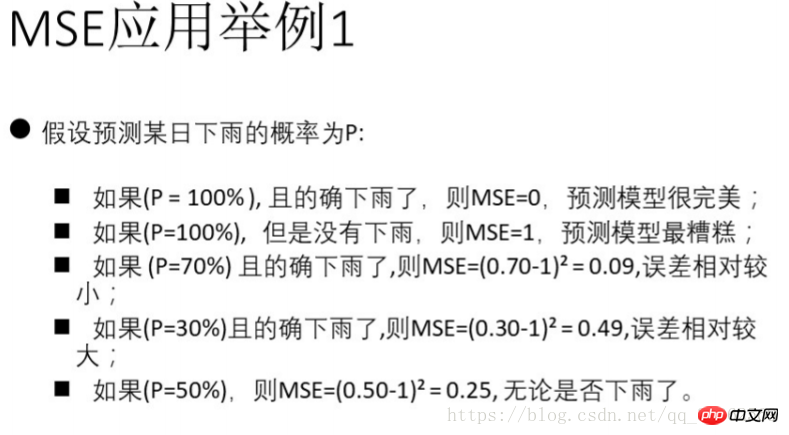
from sklearn.metrics import log_loss log_loss(y_true, y_pred)from scipy.stats import pearsonr pearsonr(rater1, rater2)from sklearn.metrics import cohen_kappa_score cohen_kappa_score(rater1, rater2)3) Erreur quadratique moyenne MSE (Erreur quadratique moyenne) 4) Perte de régression logistique5) Évaluation de la cohérence - méthode du coefficient de corrélation de PearsonImplémentation du code Python
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!