
Maison >interface Web >tutoriel CSS >Comment implémenter l'analyse des champs de sélection CSS
Comment implémenter l'analyse des champs de sélection CSS

- 小云云original
- 2018-02-02 10:30:161958parcourir
Sur la base des connaissances de base sur la syntaxe CSS apprises ci-dessus, implémentons maintenant l'analyse des champs. Tout d’abord, analysez le titre. Ouvrez les outils de développement Web et recherchez le code source correspondant au titre. Cet article présente principalement les informations pertinentes sur la mise en œuvre du sélecteur CSS pour l'analyse des champs. Les amis qui en ont besoin peuvent s'y référer. J'espère que cela pourra aider tout le monde
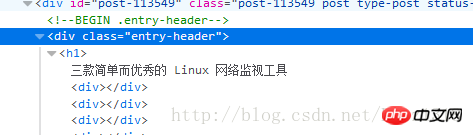
J'ai trouvé que c'était le cas. le nœud h1 ci-dessous p class="entry-header", j'ai donc ouvert le shell Scrapy pour le débogage

Mais que dois-je faire si je ne veux pas de balise comme 4a249f0d628e2318394fd9b75b4636b1 ? cette fois, je dois utiliser le pseudo-code dans la méthode de classe CSS. Comme indiqué ci-dessous.

Notez les deux deux-points. Utiliser des sélecteurs CSS est vraiment pratique. De la même manière, j'utilise CSS pour implémenter l'analyse de champs. Le code est le suivant
# -*- coding: utf-8 -*-
import scrapy
import re
class JobboleSpider(scrapy.Spider):
name = 'jobbole'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/113549/']
def parse(self, response):
# title = response.xpath('//p[@class = "entry-header"]/h1/text()').extract()[0]
# create_date = response.xpath("//p[@class = 'entry-meta-hide-on-mobile']/text()").extract()[0].strip().replace("·","").strip()
# praise_numbers = response.xpath("//span[contains(@class,'vote-post-up')]/h10/text()").extract()[0]
# fav_nums = response.xpath("//span[contains(@class,'bookmark-btn')]/text()").extract()[0]
# match_re = re.match(".*?(\d+).*",fav_nums)
# if match_re:
# fav_nums = match_re.group(1)
# comment_nums = response.xpath("//a[@href='#article-comment']/span").extract()[0]
# match_re = re.match(".*?(\d+).*", comment_nums)
# if match_re:
# comment_nums = match_re.group(1)
# content = response.xpath("//p[@class='entry']").extract()[0]
#通过CSS选择器提取字段
title = response.css(".entry-header h1::text").extract()[0]
create_date = response.css(".entry-meta-hide-on-mobile::text").extract()[0].strip().replace("·","").strip()
praise_numbers = response.css(".vote-post-up h10::text").extract()[0]
fav_nums = response.css("span.bookmark-btn::text").extract()[0]
match_re = re.match(".*?(\d+).*", fav_nums)
if match_re:
fav_nums = match_re.group(1)
comment_nums = response.css("a[href='#article-comment'] span::text").extract()[0]
match_re = re.match(".*?(\d+).*", comment_nums)
if match_re:
comment_nums = match_re.group(1)
content = response.css("p.entry").extract()[0]
tags = response.css("p.entry-meta-hide-on-mobile a::text").extract()[0]
pass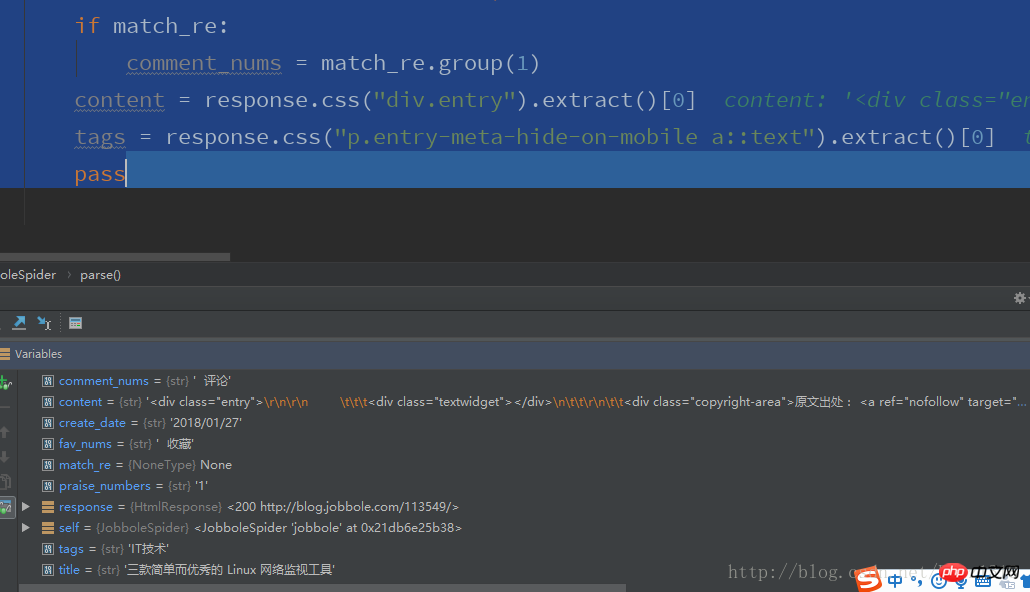
Recommandations associées :
Employé OpenERP ( employé) table Analyse des champs associés aux tables utilisateur
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!