
Maison >Java >javaDidacticiel >Compréhension approfondie du principe d'implémentation de HashMap en Java (photo)
Compréhension approfondie du principe d'implémentation de HashMap en Java (photo)

- 黄舟original
- 2017-03-28 10:32:591906parcourir
Cet article présente principalement des informations pertinentes pour une compréhension approfondie des principes de mise en œuvre de HashMap en Java. Les amis dans le besoin peuvent se référer à
1. La structure de données de HashMap
comprend des tableaux et des listes chaînées pour stocker les données, mais ces deux-là sont fondamentalement deux extrêmes.Tableau
L'intervalle de stockage du tableau est continu et prend beaucoup de mémoire, donc l'espace est très complexe. Cependant, la complexité temporelle de larecherche binaire des tableaux est faible, O(1) ; les caractéristiques des tableaux sont : faciles à adresser, difficiles à insérer et à supprimer
Liste chaînéeL'intervalle de stockage de la liste chaînée est discret et la mémoire occupée est relativement lâche, donc la complexité spatiale est très petite, mais la complexité temporelle est très grande, atteignant O (N).
Les caractéristiques de la liste chaînéesont : difficile à adresser, facile à insérer et à supprimer.
Table de hachagePouvons-nous donc combiner les caractéristiques des deux et créer une structure de données facile à adresser et facile à insérer et à supprimer ? La réponse est oui, c'est la table de hachage que nous allons mentionner. La table de hachage (Hash table) répond non seulement à la commodité de la recherche de données, mais ne prend pas non plus trop d'espace de contenu et est très pratique à utiliser
Il existe de nombreuses méthodes d'implémentation différentes de la table de hachage. follow L'explication est la méthode la plus couramment utilisée - la méthode zipper, que nous pouvons comprendre comme "
tableau de liste chaînée", comme le montre l'image :
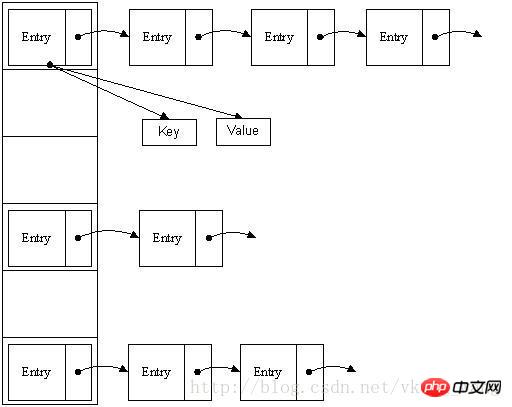
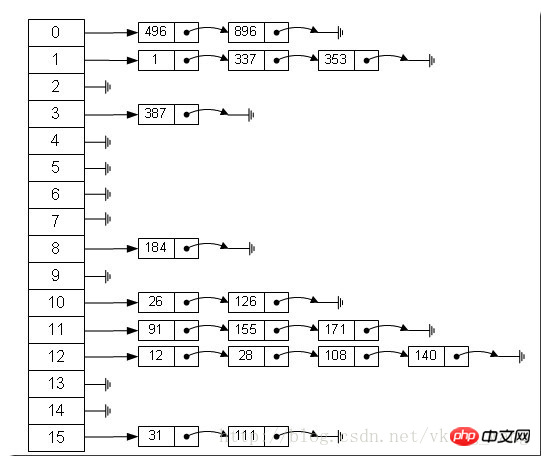
D'après l'image ci-dessus, nous pouvons constater que la table de hachage est composée de
dans un tableau de longueur 16, chaque élément stocke Le nœud principal d'une liste chaînée. Alors selon quelles règles ces éléments sont-ils stockés dans le tableau Généralement, il est obtenu par hash(key)%len, c'est-à-dire que la valeur de hachage de la clé de l'élément est obtenue modulo ? la longueur du tableau. Par exemple, dans la table de hachage ci-dessus, 12%16=12, 28%16=12, 108%16=12, 140%16=12 Donc 12, 28, 108 et 140 sont tous stockés à la fois. index du tableau 12. 🎜>HashMap est en fait implémenté comme un tableau linéaire, on peut donc comprendre que le conteneur pour stocker les données est un tableau linéaire. Cela peut nous rendre confus, comment un tableau linéaire peut-il accéder aux données par paires clé-valeur ? HashMap effectue un certain traitement. Tout d'abord, HashMap implémente une entrée de classe interne statique. Ses
attributsincluent
key, value, next. Attributs clé et valeur que Entry est un bean de base pour l'implémentation des paires clé-valeur HashMap. Comme nous l'avons mentionné ci-dessus, la base de HashMap est un tableau linéaire. Ce tableau est Entry[] et le contenu de la carte est enregistré dans. Entry[]. 2. Implémentation de l'accès HashMap
Puisqu'il s'agit d'un tableau linéaire, pourquoi HashMap est-il utilisé ici ? ceci : /**
* The table, resized as necessary. Length MUST Always be a power of two.
*/
transient Entry[] table;1) put
Question : Si deux clés obtiennent l'index via hash%Entry[].length Idem, y a-t-il un risque d'écrasement ?// 存储时: int hash = key.hashCode(); // 这个hashCode方法这里不详述,只要理解每个key的hash是一个固定的int值 int index = hash % Entry[].length; Entry[index] = value; // 取值时: int hash = key.hashCode(); int index = hash % Entry[].length; return Entry[index];
Ici, le concept de structure de données chaînée est utilisé dans HashMap. Nous avons mentionné ci-dessus qu'il existe un attribut next dans la classe Entry, qui pointe vers l'entrée suivante. Par exemple, lorsque la première paire clé-valeur A arrive, l'index=0 obtenu en calculant le hachage de sa clé est enregistré comme : Entry[0] = A. Au bout d'un moment, une autre paire clé-valeur B arrive, et son index est également égal à 0 par calcul. Que dois-je faire maintenant ? HashMap fera ceci : B.next = A,Entry[0] = B. Si C revient, l'index est également égal à 0, alors
C.next = B,Entry[0 ] = C; De cette façon, nous constatons que l'endroit où index=0 accède en fait à trois paires clé-valeur A, B et C, et elles sont liées entre elles via l'attribut suivant. Alors ne vous inquiétez pas si vous avez des questions.
C'est-à-dire que le dernier élément inséré est stocké dans le tableau.À ce stade, nous devrions avoir une compréhension claire de la mise en œuvre générale de HashMap. Bien entendu, HashMap contient également quelques implémentations d'optimisation, dont je parlerai ici. Par exemple : une fois la longueur de Entry[] fixée, à mesure que les données de la carte deviennent de plus en plus longues, la chaîne du même index sera très longue. Cela affectera-t-il les performances ? Un facteur est défini dans HashMap. À mesure que la taille de la carte devient de plus en plus grande, Entry[] s'allongera selon certaines règles.
2) obtenir public V put(K key, V value) {
if (key == null)
return putForNullKey(value); //null总是放在数组的第一个链表中
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
//遍历链表
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
//如果key在链表中已存在,则替换为新value
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
} void addEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);//参数e, 是Entry.next
//如果size超过threshold,则扩充table大小。再散列
if (size++ >= threshold)
resize(2 * table.length);
}
3) Accès à la clé nulle
La clé nulle est toujours stockée dans l'entrée [] Le premier élément du tableau.public V get(Object key) {
if (key == null)
return getForNullKey();
int hash = hash(key.hashCode());
//先定位到数组元素,再遍历该元素处的链表
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}4) Déterminez l'index du tableau : hashcode % table.length modulo
Lors de l'accès à HashMap, vous devez calculer que la clé actuelle doit correspondre à la Entry[] array Quel élément est utilisé pour calculer l'indice du tableau ; l'algorithme est le suivant : private V putForNullKey(V value) {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
}
private V getForNullKey() {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null)
return e.value;
}
return null;
}Union au niveau des bits, ce qui équivaut à modulo mod ou reste %.
Cela signifie que les indices du tableau sont les mêmes, mais cela ne signifie pas que le hashCode est le même.5)table初始大小
public HashMap(int initialCapacity, float loadFactor) {
.....
// Find a power of 2 >= initialCapacity
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
this.loadFactor = loadFactor;
threshold = (int)(capacity * loadFactor);
table = new Entry[capacity];
init();
}注意table初始大小并不是构造函数中的initialCapacity!!
而是 >= initialCapacity的2的n次幂!!!!
————为什么这么设计呢?——
3. 解决hash冲突的办法开放定址法(线性探测再散列,二次探测再散列,伪随机探测再散列) 再哈希法 链地址法 建立一个公共溢出区
Java中hashmap的解决办法就是采用的链地址法。
4. 再散列rehash过程
当哈希表的容量超过默认容量时,必须调整table的大小。当容量已经达到最大可能值时,那么该方法就将容量调整到Integer.MAX_VALUE返回,这时,需要创建一张新表,将原表的映射到新表中。
/**
* Rehashes the contents of this map into a new array with a
* larger capacity. This method is called automatically when the
* number of keys in this map reaches its threshold.
*
* If current capacity is MAXIMUM_CAPACITY, this method does not
* resize the map, but sets threshold to Integer.MAX_VALUE.
* This has the effect of preventing future calls.
*
* @param newCapacity the new capacity, MUST be a power of two;
* must be greater than current capacity unless current
* capacity is MAXIMUM_CAPACITY (in which case value
* is irrelevant).
*/
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}
/**
* Transfers all entries from current table to newTable.
*/
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
//重新计算index
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!