
Maison >Java >javaDidacticiel >Apprentissage approfondi JVM - Exemple de code du processus de fichier de classe d'analyse Java
Apprentissage approfondi JVM - Exemple de code du processus de fichier de classe d'analyse Java

- 黄舟original
- 2017-03-18 10:47:351883parcourir
Avant-propos :
En tant que programmeur Java, comment puis-je ne pas comprendre JVM Si vous voulez apprendre JVM, vous devez comprendre le fichier Class, Class ? est pour la machine virtuelle, tout comme un poisson pour l'eau, la machine virtuelle est vivante grâce à la classe. "Compréhension approfondie de la machine virtuelle Java" consacre un chapitre entier à expliquer les fichiers de classe, mais après l'avoir lu, je suis toujours confus et à moitié compris. Il m'est arrivé de lire un très bon livre il y a quelque temps : "Ecrivez votre propre machine virtuelle Java". L'auteur a utilisé le langage go pour implémenter une JVM simple. Bien qu'il ne réalise pas pleinement toutes les fonctions de la JVM, il est utile pour. ceux qui sont légèrement intéressés par la JVM Cela dit, la lisibilité reste très élevée. L'auteur l'explique en détail et chaque processus est divisé en un chapitre, dont une partie explique comment analyser les fichiers Class.
Ce livre n'est pas trop épais et je l'ai lu rapidement Après l'avoir lu, j'ai beaucoup gagné. Mais ce n'était qu'une question de temps avant que je l'apprenne sur papier, et je savais que je devais le faire en détail, alors j'ai essayé d'analyser le fichier de classe moi-même. Bien que le langage Go soit excellent, je ne le maîtrise finalement pas, surtout si je ne suis pas habitué à sa syntaxe consistant à mettre des types après des variables, je ferais donc mieux de m'en tenir à Java.
Fichier de classe
Qu'est-ce qu'un fichier de classe ?
La raison pour laquelle Java peut atteindre plusieurs plates-formes est que sa phase de compilation ne compile pas directement le code dans un langage machine lié à la plate-forme, mais le compile d'abord sous forme binaire de bytecode Java et le place dans le fichier de classe. , la machine virtuelle charge ensuite le fichier Class et analyse le contenu requis pour exécuter le programme. Chaque classe sera compilée dans un fichier de classe distinct et la classe interne sera également utilisée comme classe indépendante pour générer sa propre classe.
Structure de base
Trouvez simplement un fichier de classe et ouvrez-le avec Sublime Text comme ceci :
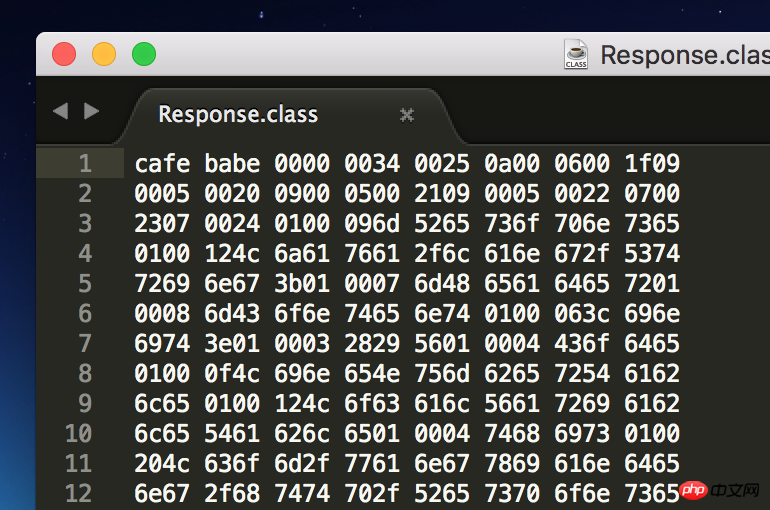
Êtes-vous confus ? Le format de base des fichiers de classe est donné dans la spécification de la machine virtuelle Java. Il vous suffit de l'analyser selon ce format :
ClassFile {
u4 magic;
u2 minor_version;
u2 major_version;
u2 constant_pool_count;
cp_info constant_pool[constant_pool_count-1];
u2 access_flags;
u2 this_class;
u2 super_class;
u2 interfaces_count;
u2 interfaces[interfaces_count];
u2 fields_count;
field_info fields[fields_count];
u2 methods_count;
method_info methods[methods_count];
u2 attributes_count;
attribute_info attributes[attributes_count];
}Les types de champs dans ClassFile sont u1, u2 et u4. ça ? Du drap de laine ? En fait, c'est très simple, cela signifie respectivement 1 octet, 2 octets et 4 octets. Les quatre premiers octets de
sont : Magic, qui est utilisé pour identifier de manière unique le format de fichier. Il est généralement appelé le nombre magique afin que la machine virtuelle puisse reconnaître le fichier chargé. c'est au format classe, le nombre magique de fichiers de classe est cafébabe. Pas seulement les fichiers de classe, la plupart des fichiers ont un numéro magique pour identifier leur format.
La partie suivante contient principalement des informations sur le fichier de classe, telles que le pool de constantes, les indicateurs d'accès à la classe, la classe parent, les informations d'interface, les champs, les méthodes, etc. Pour des informations spécifiques, veuillez vous référer à « Machine virtuelle Java Spécification".
Analyse
Type de champ
Comme mentionné ci-dessus, les types de champs dans ClassFile sont u1, u2, u4, qui représentent respectivement 1 octet, 2 octets et 4 An non signé. nombre entier d'octets. En Java, short, int et long sont des entiers signés de 2, 4 et 8 octets respectivement. Sans le bit de signe, ils peuvent être utilisés pour représenter u1, u2 et u4.
public class U1 {
public static short read(InputStream inputStream) {
byte[] bytes = new byte[1];
try {
inputStream.read(bytes);
} catch (IOException e) {
e.printStackTrace();
}
short value = (short) (bytes[0] & 0xFF);
return value;
}
}
public class U2 {
public static int read(InputStream inputStream) {
byte[] bytes = new byte[2];
try {
inputStream.read(bytes);
} catch (IOException e) {
e.printStackTrace();
}
int num = 0;
for (int i= 0; i < bytes.length; i++) {
num <<= 8;
num |= (bytes[i] & 0xff);
}
return num;
}
}
public class U4 {
public static long read(InputStream inputStream) {
byte[] bytes = new byte[4];
try {
inputStream.read(bytes);
} catch (IOException e) {
e.printStackTrace();
}
long num = 0;
for (int i= 0; i < bytes.length; i++) {
num <<= 8;
num |= (bytes[i] & 0xff);
}
return num;
}
}Piscine constante
Après avoir défini le type de champ, nous pouvons lire le fichier de classe. Tout d'abord, nous devons lire les informations de base telles que les nombres magiques. Cette partie est très simple :
FileInputStream inputStream = new FileInputStream(file); ClassFile classFile = new ClassFile(); classFile.magic = U4.read(inputStream); classFile.minorVersion = U2.read(inputStream); classFile.majorVersion = U2.read(inputStream);
Cette partie n'est qu'un échauffement, la prochaine grande partie est la piscine constante. Avant d’analyser le pool constant, expliquons d’abord ce qu’est le pool constant.
Le pool de constantes, comme son nom l'indique, est un pool de ressources qui stocke des constantes. Les constantes font ici référence à des littéraux et des références de symboles. Les littéraux font référence à certaines ressources chaîne , et les références de symboles sont divisées en trois catégories : les références de symboles de classe, les références de symboles de méthode et les références de symboles de champ. En plaçant des ressources dans le pool constant, d'autres éléments peuvent être directement définis comme index dans le pool constant, évitant ainsi le gaspillage d'espace. Il ne s'agit pas seulement du fichier de classe, mais aussi du fichier exécutable Android dex. les ressources, etc. sont placées dans DexData, et d'autres éléments localisent les ressources via des index. La spécification de la machine virtuelle Java donne le format de chaque élément du pool constant :
cp_info {
u1 tag;
u1 info[];
}Le format ci-dessus est juste un format général. Il existe 14 formats de données réellement contenus dans le pool constant, chaque format étant le suivant. les valeurs des balises sont différentes, comme indiqué ci-dessous :
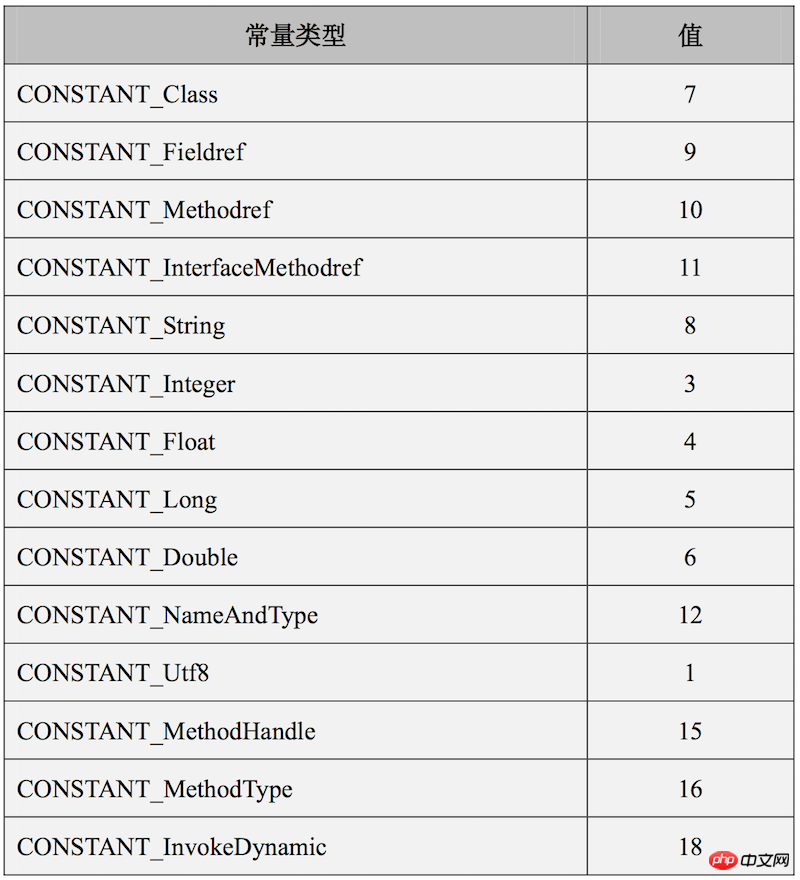
Comme il y a trop de formats, seule une partie de l'article est sélectionnée pour expliquer :
Ici, nous lisons d'abord la taille du pool constant. , initialisons le pool constant :
//解析常量池 int constant_pool_count = U2.read(inputStream); ConstantPool constantPool = new ConstantPool(constant_pool_count); constantPool.read(inputStream);
Ensuite, lisez chaque élément un par un et stockez-le dans le tableau cpInfo dont vous avez besoin. il convient de noter ici que l'indice cpInfo[] commence à partir de 1. Initialement, 0 n'est pas valide et la taille réelle du pool constant est constant_pool_count-1.
public class ConstantPool {
public int constant_pool_count;
public ConstantInfo[] cpInfo;
public ConstantPool(int count) {
constant_pool_count = count;
cpInfo = new ConstantInfo[constant_pool_count];
}
public void read(InputStream inputStream) {
for (int i = 1; i < constant_pool_count; i++) {
short tag = U1.read(inputStream);
ConstantInfo constantInfo = ConstantInfo.getConstantInfo(tag);
constantInfo.read(inputStream);
cpInfo[i] = constantInfo;
if (tag == ConstantInfo.CONSTANT_Double || tag == ConstantInfo.CONSTANT_Long) {
i++;
}
}
}
}Jetons d'abord un coup d'œil au format CONSTANT_Utf8. Cet élément stocke une chaîne codée en MUTF-8 :
CONSTANT_Utf8_info {
u1 tag;
u2 length;
u1 bytes[length];
}Alors, comment lire cet élément ?
public class ConstantUtf8 extends ConstantInfo {
public String value;
@Override
public void read(InputStream inputStream) {
int length = U2.read(inputStream);
byte[] bytes = new byte[length];
try {
inputStream.read(bytes);
} catch (IOException e) {
e.printStackTrace();
}
try {
value = readUtf8(bytes);
} catch (UTFDataFormatException e) {
e.printStackTrace();
}
}
private String readUtf8(byte[] bytearr) throws UTFDataFormatException {
//copy from java.io.DataInputStream.readUTF()
}
}很简单,首先读取这一项的字节数组长度,接着调用readUtf8(),将字节数组转化为String字符串。
再来看看CONSTANT_Class这一项,这一项存储的是类或者接口的符号引用:
CONSTANT_Class_info {
u1 tag;
u2 name_index;
}注意这里的name_index并不是直接的字符串,而是指向常量池中cpInfo数组的name_index项,且cpInfo[name_index]一定是CONSTANT_Utf8格式。
public class ConstantClass extends ConstantInfo {
public int nameIndex;
@Override
public void read(InputStream inputStream) {
nameIndex = U2.read(inputStream);
}
}常量池解析完毕后,就可以供后面的数据使用了,比方说ClassFile中的this_class指向的就是常量池中格式为CONSTANT_Class的某一项,那么我们就可以读取出类名:
int classIndex = U2.read(inputStream);
ConstantClass clazz = (ConstantClass) constantPool.cpInfo[classIndex];
ConstantUtf8 className = (ConstantUtf8) constantPool.cpInfo[clazz.nameIndex];
classFile.className = className.value;
System.out.print("classname:" + classFile.className + "\n");字节码指令
解析常量池之后还需要接着解析一些类信息,如父类、接口类、字段等,但是相信大家最好奇的还是java指令的存储,大家都知道,我们平时写的java代码会被编译成java字节码,那么这些字节码到底存储在哪呢?别急,讲解指令之前,我们先来了解下ClassFile中的method_info,其格式如下:
method_info {
u2 access_flags;
u2 name_index;
u2 descriptor_index;
u2 attributes_count;
attribute_info attributes[attributes_count];
}method_info里主要是一些方法信息:如访问标志、方法名索引、方法描述符索引及属性数组。这里要强调的是属性数组,因为字节码指令就存储在这个属性数组里。属性有很多种,比如说异常表就是一个属性,而存储字节码指令的属性为CODE属性,看这名字也知道是用来存储代码的了。属性的通用格式为:
attribute_info {
u2 attribute_name_index;
u4 attribute_length;
u1 info[attribute_length];
}根据attribute_name_index可以从常量池中拿到属性名,再根据属性名就可以判断属性种类了。
Code属性的具体格式为:
Code_attribute {
u2 attribute_name_index; u4 attribute_length;
u2 max_stack;
u2 max_locals;
u4 code_length;
u1 code[code_length];
u2 exception_table_length;
{
u2 start_pc;
u2 end_pc;
u2 handler_pc;
u2 catch_type;
} exception_table[exception_table_length];
u2 attributes_count;
attribute_info attributes[attributes_count];
}其中code数组里存储就是字节码指令,那么如何解析呢?每条指令在code[]中都是一个字节,我们平时javap命令反编译看到的指令其实是助记符,只是方便阅读字节码使用的,jvm有一张字节码与助记符的对照表,根据对照表,就可以将指令翻译为可读的助记符了。这里我也是在网上随便找了一个对照表,保存到本地txt文件中,并在使用时解析成HashMap。代码很简单,就不贴了,可以参考我代码中InstructionTable.java。
接下来我们就可以解析字节码了:
for (int j = 0; j < methodInfo.attributesCount; j++) {
if (methodInfo.attributes[j] instanceof CodeAttribute) {
CodeAttribute codeAttribute = (CodeAttribute) methodInfo.attributes[j];
for (int m = 0; m < codeAttribute.codeLength; m++) {
short code = codeAttribute.code[m];
System.out.print(InstructionTable.getInstruction(code) + "\n");
}
}
}运行
整个项目终于写完了,接下来就来看看效果如何,随便找一个class文件解析运行:
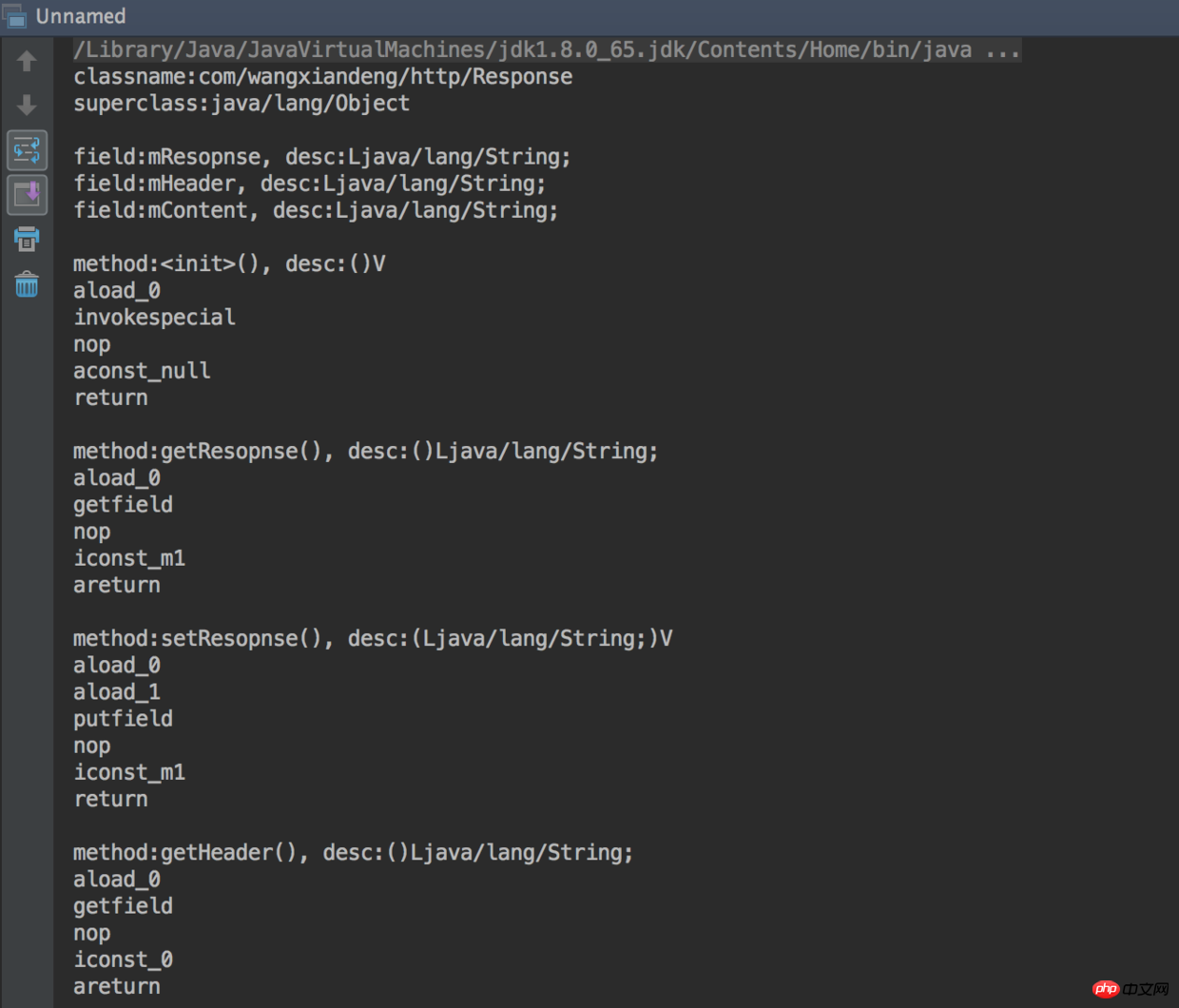
哈哈,是不是很赞!
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Les avantages de développement du framework Java dans les projets cloud natifs
- Interfaces fonctionnelles par défaut en Java
- Comment convertir des entiers en chaînes en Java : quelle méthode est la plus efficace ?
- Comment puis-je compter les occurrences de chaînes dans une liste à l'aide de flux Java ?
- Comment déterminer la taille d'un ResultSet Java ?