
Maison >développement back-end >Tutoriel XML/RSS >Explication détaillée de l'implémentation par Android de la technologie d'analyse XML (image)
Explication détaillée de l'implémentation par Android de la technologie d'analyse XML (image)

- 黄舟original
- 2017-03-09 17:07:061564parcourir
Cet article présente trois façons d'analyser XML sur la plateforme Android.
XML est largement utilisé dans divers développements, et Android ne fait pas exception. En tant que rôle important dans le transport des données, la lecture et l'écriture de XML sont devenues une compétence importante dans le développement Android.
Sous Android, les analyseurs XML courants sont l'analyseur DOM, l'analyseur SAX et l'analyseur PULL Ci-dessous, je vais vous les présenter en détail un par un.
Première méthode : analyseur DOM :
DOM est une collection de des nœuds ou des fragments d'informations basés sur une structure arborescente qui permet aux développeurs d'utiliser l'API DOM pour parcourir l'arborescence XML et récupérer les données requises. L'analyse de cette structure nécessite généralement de charger l'intégralité du document et de construire une arborescence avant que les informations sur les nœuds puissent être récupérées et mises à jour. Android prend entièrement en charge l'analyse DOM. À l'aide d'objets dans le DOM, les documents XML peuvent être lus, recherchés, modifiés, ajoutés et supprimés.
Comment fonctionne DOM : lorsque vous utilisez DOM pour exploiter des fichiers XML, vous devez d'abord analyser le fichier et le diviser en éléments, attributs et commentaires indépendants. , etc., puis représenter le fichier XML en mémoire sous la forme d'une arborescence de nœuds. Vous pouvez accéder au contenu du document via l'arborescence de nœuds et modifier le document selon vos besoins - c'est ainsi que fonctionne le DOM.
L'implémentation DOM définit d'abord un ensemble d'interfaces pour l'analyse des documents XML, l'analyseur lit l'intégralité du document, puis construit une structure arborescente résidant en mémoire, de sorte que le code peut ensuite utiliser l'interface DOM pour manipuler toute la structure arborescente.
Étant donné que le DOM est stocké dans une structure arborescente en mémoire, l'efficacité de la récupération et de la mise à jour sera plus élevée. Mais pour les documents particulièrement volumineux, l’analyse et le chargement de l’intégralité du document nécessiteront beaucoup de ressources. Bien entendu, si le contenu du fichier XML est relativement petit, il est possible d'utiliser DOM.
Interfaces et classes DoM couramment utilisées :
Document : Cette interface définit une série d'analyses et de création de DOM Méthode documents, qui est la racine de l'arborescence des documents et la base du fonctionnement du DOM.
Element : Cette interface hérite de l'interface Node et fournit des méthodes pour obtenir et modifier les noms et attributs des éléments XML.
Node : Cette interface fournit des méthodes pour traiter et obtenir les valeurs des nœuds et des nœuds enfants.
NodeList : Fournit des méthodes pour obtenir le nombre de nœuds et le nœud actuel. Cela permet d'accéder à des nœuds individuels de manière itérative.
DOMParser : Cette classe est la classe d'analyseur DOM dans Xerces d'Apache, qui peut analyser directement les fichiers XML.
Voici le processus d'analyse DOM :

Deuxième méthode : analyseur SAX :
L'analyseur SAX (Simple API for XML) est un analyseur basé sur les événements. La méthode d'analyse en continu de l'analyseur consiste à analyser séquentiellement du début du fichier à la fin du document sans pause ni rembobinage. Son cœur est le modèle de traitement des événements, qui fonctionne principalement autour des sources d'événements et des processeurs d'événements. Lorsque la source d'événement génère un événement, appelez la méthode de traitement correspondante du processeur d'événement et un événement peut être traité. Lorsque la source d'événement appelle une méthode spécifique dans le gestionnaire d'événements, elle doit également transmettre les informations d'état de l'événement correspondant au gestionnaire d'événements, afin que le gestionnaire d'événements puisse décider de son propre comportement en fonction des informations d'événement fournies.
L'avantage de l'analyseur SAX est qu'il a une vitesse d'analyse rapide et prend moins de mémoire. Parfait pour une utilisation sur les appareils mobiles Android.
Le principe de fonctionnement de SAX : Le principe de fonctionnement de SAX est simplement de numériser le document de manière séquentielle lorsque le début et la fin du document (document) sont numérisés. , les éléments ( La fonction de traitement des événements est notifiée lorsque l'élément commence et se termine, le document se termine, etc., et la fonction de traitement des événements prend les actions correspondantes, puis continue la même analyse jusqu'à la fin du document.
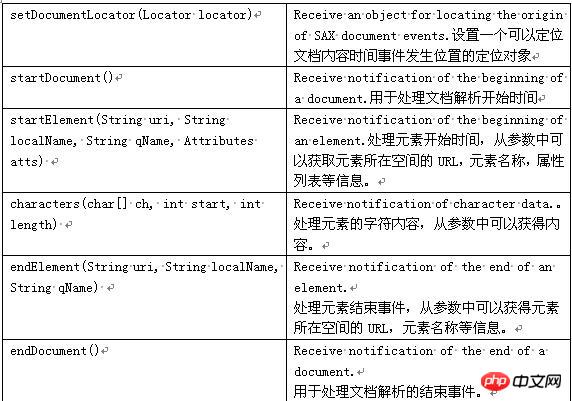
Dans l'interface SAX, la source de l'événement est le XMLReader du package org.xml.sax, qui analyse le document XML via l'analyseur ( ) et générer des événements. Le gestionnaire d'événements est constitué des quatre interfaces ContentHander, DTDHander, ErrorHandler et EntityResolver dans le package org.xml.sax. XMLReader complète la connexion avec les quatre interfaces ContentHander, DTDHander, ErrorHandler et EntityResolver via la méthode d'enregistrement du gestionnaire d'événements correspondante setXXXX().
Interfaces et classes SAX couramment utilisées : Attributs : utilisés Obtenir le nombre, le nom et la valeur des attributs. ContentHandler : définit les événements associés au document lui-même (par exemple, les balises d'ouverture et de fermeture). La plupart des candidatures s'inscrivent à ces événements. DTDHandler : Définit les événements associés à la DTD. Il ne définit pas suffisamment d'événements pour signaler complètement la DTD. Si l’analyse de la DTD est requise, utilisez le DeclHandler facultatif. DeclHandler est une extension de SAX. Tous les analyseurs ne le prennent pas en charge. EntityResolver : définit les événements associés au chargement des entités. Seules quelques candidatures s'inscrivent à ces événements. ErrorHandler : définissez les événements d'erreur. De nombreuses applications enregistrent ces événements pour signaler les erreurs à leur manière. DefaultHandler : Il fournit l'implémentation par défaut de ces interfaces. Dans la plupart des cas, il est plus facile pour une application d'étendre DefaultHandler et de remplacer les méthodes pertinentes que d'implémenter directement une interface. Voir le tableau ci-dessous pour plus de détails : Comme nous pouvons le voir, nous avons besoin de XmlReader et de DefaultHandler pour analyser XML. Voici le processus d'analyse SAX : 

La troisième méthode : analyseur PULL :
Android ne fournit pas prise en charge de l'API Java StAX. Cependant, Android est livré avec un analyseur pull qui fonctionne de manière similaire à StAX. Il permet au code d'application de l'utilisateur d'obtenir des événements de l'analyseur, contrairement à l'analyseur SAX qui transmet automatiquement les événements aux gestionnaires.
L'analyseur PULL fonctionne de la même manière que SAX, les deux sont basés sur des événements. La différence est que les nombres sont renvoyés pendant le processus d'analyse PULL et que nous devons obtenir nous-mêmes les événements générés, puis effectuer les opérations correspondantes, contrairement à SAX où le processeur déclenche un événement et exécute notre code.
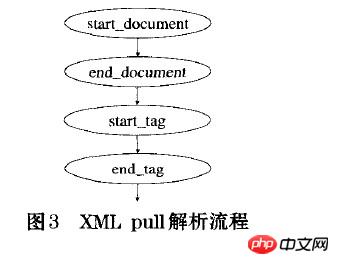
Voici le processus d'analyse PULL du XML :
La lecture de la déclaration XML renvoie START_DOCUMENT ;
Lisez la fin du XML et renvoyez END_DOCUMENT ;
Lisez la balise de début du XML et renvoyez START_TAG
Lire la balise de fin du XML et renvoyer END_TAG
Lire le texte du XML et renvoyer TEXT
L'analyseur PULL est petit et léger, a une vitesse d'analyse rapide, est simple et facile à utiliser et est très approprié pour une utilisation sur mobile Android appareils Le système Android analyse en interne L'analyseur PULL est également utilisé pour divers XML. Android recommande officiellement aux développeurs d'utiliser la technologie d'analyse Pull. La technologie d'analyse pull est une technologie open source développée par un tiers et peut également être appliquée au développement JavaSE.
Comment fonctionne PULL : XML pull fournit un élément de début et un élément de fin. Lorsqu'un élément démarre, nous pouvons appeler parser. nextText extrait toutes les données de caractères du document XML. Lorsque l'interprétation d'un document se termine, l'événement EndDocument est automatiquement généré.
Interfaces et classes d'extraction XML couramment utilisées :
XmlPullParser : l'analyseur d'extraction XML est une fonction d'analyse de définition fournie dans l'interface XMLPULL VlAP1.
XmlSerializer : C'est une interface qui définit la séquence des ensembles d'informations XML.
XmlPullParserFactory : Cette classe est utilisée pour créer des analyseurs XML Pull dans l'API XMPULL V1.
XmlPullParserException : renvoie une seule erreur liée à l'analyseur d'extraction XML.
Le processus d'analyse de PULL est le suivant :
[Supplémentaire] La quatrième voie : classe Android.util.Xml
dans Android Dans l'API, Android est également fourni. util. La classe Xml peut également analyser les fichiers XML. La méthode d'utilisation est similaire à SAX. Vous devez également écrire un gestionnaire pour gérer l'analyse XML, mais il est plus simple à utiliser que SAX, comme indiqué ci-dessous :
Avec Android. util. XML implémente l'analyse XML,
MyHandler myHandler=new MyHandler0;
android. util. Xm1. parse(ur1.openC0nnection().getlnputStream0, Xm1.Encoding.UTF-8, myHandler
river.xml, placé dans le répertoire actifs . est la suivante :
<?xml version="1.0" encoding="utf-8"?> <rivers> <river name="灵渠" length="605"> <introduction>
</
introduction
>
<
imageurl
>
http://www.php.cn/
</
imageurl
>
</
river
>
<
river
name
="胶莱运河"
length
="200"
>
<
introduction
>
胶莱运河南起黄海灵山海口,北抵渤海三山岛,流经现胶南、胶州、平度、高密、昌邑和莱州等,全长200公里,流域面积达5400平方公里,南北贯穿山东半岛,沟通黄渤两海。胶莱运河自平度姚家村东的分水岭南北分流。南流由麻湾口入胶州湾,为南胶莱河,长30公里。北流由海仓口入莱州湾,为北胶莱河,长100余公里。
</
introduction
>
<
imageurl
>
http://www.php.cn/
</
imageurl
>
</
river
>
<
river
name
="苏北灌溉总渠"
length
="168"
>
<
introduction
>
位于淮河下游江苏省北部,西起洪泽湖边的高良涧,流经洪泽,青浦、淮安,阜宁、射阳,滨海等六县(区),东至扁担港口入海的大型人工河道。全长168km。
</
introduction
>
<
imageurl
>
http://www.php.cn/
</
imageurl
>
</
river
>
</
rivers
>
采用DOM解析时具体处理步骤是:
1 首先利用DocumentBuilderFactory创建一个DocumentBuilderFactory实例
2 然后利用DocumentBuilderFactory创建DocumentBuilder
3 然后加载XML文档(Document),
4 然后获取文档的根结点(Element),
5 然后获取根结点中所有子节点的列表(NodeList),
6 然后使用再获取子节点列表中的需要读取的结点。
当然我们观察节点,我需要用一个River对象来保存数据,抽象出River类
public class River implements Serializable {
privatestaticfinallong serialVersionUID = 1L;
private String name;
public String getName() {
return name; }
public void setName(String name) {
this.name = name; }
public int getLength() {
return length; }
public void setLength(int length) {
this.length = length; }
public String getIntroduction() {
return introduction; }
public void setIntroduction(String introduction) {
this.introduction = introduction; }
public String getImageurl() {
return imageurl; }
public void setImageurl(String imageurl) {
this.imageurl = imageurl; }
private int length;
private String introduction;
private String imageurl; }下面我们就开始读取xml文档对象,并添加进List中:
代码如下: 我们这里是使用assets中的river.xml文件,那么就需要读取这个xml文件,返回输入流。 读取方法为:inputStream=this.context.getResources().getAssets().open(fileName); 参数是xml文件路径,当然默认的是assets目录为根目录。
然后可以用DocumentBuilder对象的parse方法解析输入流,并返回document对象,然后再遍历doument对象的节点属性。
//获取全部河流数据
/**
* 参数fileName:为xml文档路径
*/
public List<River> getRiversFromXml(String fileName){
List<River> rivers=new ArrayList<River>();
DocumentBuilderFactory factory=null;
DocumentBuilder builder=null;
Document document=null;
InputStream inputStream=null;
//首先找到xml文件
factory=DocumentBuilderFactory.newInstance();
try {
//找到xml,并加载文档
builder=factory.newDocumentBuilder();
inputStream=this.context.getResources().getAssets().open(fileName);
document=builder.parse(inputStream);
//找到根Element
Element root=document.getDocumentElement();
NodeList nodes=root.getElementsByTagName(RIVER);
//遍历根节点所有子节点,rivers 下所有river
River river=null;
for(int i=0;i<nodes.getLength();i++){
river=new River();
//获取river元素节点
Element riverElement=(Element)(nodes.item(i));
//获取river中name属性值
river.setName(riverElement.getAttribute(NAME));
river.setLength(Integer.parseInt(riverElement.getAttribute(LENGTH)));
//获取river下introduction标签
Element introduction=(Element)riverElement.getElementsByTagName(INTRODUCTION).item(0);
river.setIntroduction(introduction.getFirstChild().getNodeValue());
Element imageUrl=(Element)riverElement.getElementsByTagName(IMAGEURL).item(0);
river.setImageurl(imageUrl.getFirstChild().getNodeValue());
rivers.add(river);
}
}catch (IOException e){
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
}
catch (ParserConfigurationException e) {
e.printStackTrace();
}finally{
try {
inputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return rivers;
}
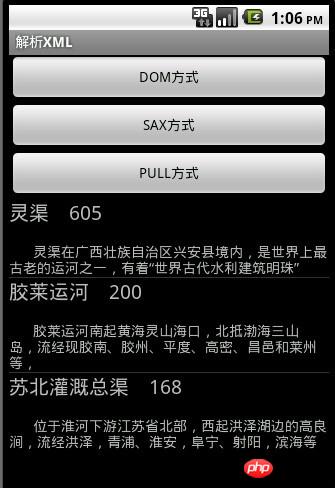
在这里添加到List中, 然后我们使用ListView将他们显示出来。如图所示:
采用SAX解析时具体处理步骤是:
1 创建SAXParserFactory对象
2 根据SAXParserFactory.newSAXParser()方法返回一个SAXParser解析器
3 根据SAXParser解析器获取事件源对象XMLReader
4 实例化一个DefaultHandler对象
5 连接事件源对象XMLReader到事件处理类DefaultHandler中
6 调用XMLReader的parse方法从输入源中获取到的xml数据
7 通过DefaultHandler返回我们需要的数据集合。
代码如下:
public List<River> parse(String xmlPath){
List<River> rivers=null;
SAXParserFactory factory=SAXParserFactory.newInstance();
try {
SAXParser parser=factory.newSAXParser();
//获取事件源
XMLReader xmlReader=parser.getXMLReader();
//设置处理器
RiverHandler handler=new RiverHandler();
xmlReader.setContentHandler(handler);
//解析xml文档
//xmlReader.parse(new InputSource(new URL(xmlPath).openStream()));
xmlReader.parse(new InputSource(this.context.getAssets().open(xmlPath)));
rivers=handler.getRivers();
} catch (ParserConfigurationException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (SAXException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return rivers;
}
重点在于DefaultHandler对象中对每一个元素节点,属性,文本内容,文档内容进行处理。
前面说过DefaultHandler是基于事件处理模型的,基本处理方式是:当SAX解析器导航到文档开始标签时回调startDocument方法,导航到文档结束标签时回调endDocument方法。当SAX解析器导航到元素开始标签时回调startElement方法,导航到其文本内容时回调characters方法,导航到标签结束时回调endElement方法。
根据以上的解释,我们可以得出以下处理xml文档逻辑:
1:当导航到文档开始标签时,在回调函数startDocument中,可以不做处理,当然你可以验证下UTF-8等等。
2:当导航到rivers开始标签时,在回调方法startElement中可以实例化一个集合用来存贮list,不过我们这里不用,因为在构造函数中已经实例化了。
3:导航到river开始标签时,就说明需要实例化River对象了,当然river标签中还有name ,length属性,因此实例化River后还必须取出属性值,attributes.getValue(NAME),同时赋予river对象中,同时添加为导航到的river标签添加一个boolean为真的标识,用来说明导航到了river元素。
4:当然有river标签内还有子标签(节点),但是SAX解析器是不知道导航到什么标签的,它只懂得开始,结束而已。那么如何让它认得我们的各个标签呢?当然需要判断了,于是可以使用回调方法startElement中的参数String localName,把我们的标签字符串与这个参数比较下,就可以了。我们还必须让SAX知道,现在导航到的是某个标签,因此添加一个true属性让SAX解析器知道。
5:它还会导航到文本内标签,(就是a1f02c36ba31691bcfe87b2722de723ba376092e9406724d5c271fcc648ed25a里面的内容),回调方法characters,我们一般在这个方法中取出就是a1f02c36ba31691bcfe87b2722de723ba376092e9406724d5c271fcc648ed25a里面的内容,并保存。 6:当然它是一定会导航到结束标签130b130fec2d2f95e194298b0c54b01d 或者32597ed33a62307b98b0a630505272be的,如果是130b130fec2d2f95e194298b0c54b01d标签,记得把river对象添加进list中。如果是river中的子标签7244917fde7c9800d42f9b80557c07c0,就把前面设置标记导航到这个标签的boolean标记设置为false. 按照以上实现思路,可以实现如下代码:
/**导航到开始标签触发**/
publicvoid startElement (String uri, String localName, String qName, Attributes attributes){
String tagName=localName.length()!=0?localName:qName;
tagName=tagName.toLowerCase().trim();
//如果读取的是river标签开始,则实例化River
if(tagName.equals(RIVER)){
isRiver=true;
river=new River();
/**导航到river开始节点后**/
river.setName(attributes.getValue(NAME));
river.setLength(Integer.parseInt(attributes.getValue(LENGTH)));
}
//然后读取其他节点
if(isRiver){
if(tagName.equals(INTRODUCTION)){
xintroduction=true;
}else if(tagName.equals(IMAGEURL)){
ximageurl=true;
}
}
}
/**导航到结束标签触发**/
public void endElement (String uri, String localName, String qName){
String tagName=localName.length()!=0?localName:qName;
tagName=tagName.toLowerCase().trim();
//如果读取的是river标签结束,则把River添加进集合中
if(tagName.equals(RIVER)){
isRiver=true;
rivers.add(river);
}
//然后读取其他节点
if(isRiver){
if(tagName.equals(INTRODUCTION)){
xintroduction=false;
}else if(tagName.equals(IMAGEURL)){
ximageurl=false;
}
}
}
//这里是读取到节点内容时候回调
public void characters (char[] ch, int start, int length){
//设置属性值
if(xintroduction){
//解决null问题
river.setIntroduction(river.getIntroduction()==null?"":river.getIntroduction()+new String(ch,start,length));
}else if(ximageurl){
//解决null问题
river.setImageurl(river.getImageurl()==null?"":river.getImageurl()+new String(ch,start,length));
}
}
运行效果跟上例DOM 运行效果相同。
采用PULL解析基本处理方式:
当PULL解析器导航到文档开始标签时就开始实例化list集合用来存贮数据对象。导航到元素开始标签时回判断元素标签类型,如果是river标签,则需要实例化River对象了,如果是其他类型,则取得该标签内容并赋予River对象。当然它也会导航到文本标签,不过在这里,我们可以不用。
根据以上的解释,我们可以得出以下处理xml文档逻辑:
1:当导航到XmlPullParser.START_DOCUMENT,可以不做处理,当然你可以实例化集合对象等等。
2:当导航到XmlPullParser.START_TAG,则判断是否是river标签,如果是,则实例化river对象,并调用getAttributeValue方法获取标签中属性值。
3:当导航到其他标签,比如Introduction时候,则判断river对象是否为空,如不为空,则取出Introduction中的内容,nextText方法来获取文本节点内容
4:当然啦,它一定会导航到XmlPullParser.END_TAG的,有开始就要有结束嘛。在这里我们就需要判读是否是river结束标签,如果是,则把river对象存进list集合中了,并设置river对象为null.
由以上的处理逻辑,我们可以得出以下代码:
public List<River> parse(String xmlPath){
List<River> rivers=new ArrayList<River>();
River river=null;
InputStream inputStream=null;
//获得XmlPullParser解析器
XmlPullParser xmlParser = Xml.newPullParser();
try {
//得到文件流,并设置编码方式
inputStream=this.context.getResources().getAssets().open(xmlPath);
xmlParser.setInput(inputStream, "utf-8");
//获得解析到的事件类别,这里有开始文档,结束文档,开始标签,结束标签,文本等等事件。
int evtType=xmlParser.getEventType();
//一直循环,直到文档结束
while(evtType!=XmlPullParser.END_DOCUMENT){
switch(evtType){
case XmlPullParser.START_TAG:
String tag = xmlParser.getName();
//如果是river标签开始,则说明需要实例化对象了
if (tag.equalsIgnoreCase(RIVER)) {
river = new River();
//取出river标签中的一些属性值
river.setName(xmlParser.getAttributeValue(null, NAME));
river.setLength(Integer.parseInt(xmlParser.getAttributeValue(null, LENGTH)));
}else if(river!=null){
//如果遇到introduction标签,则读取它内容
if(tag.equalsIgnoreCase(INTRODUCTION)){
river.setIntroduction(xmlParser.nextText());
}else if(tag.equalsIgnoreCase(IMAGEURL)){
river.setImageurl(xmlParser.nextText());
}
}
break;
case XmlPullParser.END_TAG:
//如果遇到river标签结束,则把river对象添加进集合中
if (xmlParser.getName().equalsIgnoreCase(RIVER) && river != null) {
rivers.add(river);
river = null;
}
break;
default:break;
}
//如果xml没有结束,则导航到下一个river节点
evtType=xmlParser.next();
}
} catch (XmlPullParserException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}catch (IOException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
}
return rivers;
}运行效果和上面的一样。
几种解析技术的比较与总结:
对于Android的移动设备而言,因为设备的资源比较宝贵,内存是有限的,所以我们需要选择适合的技术来解析XML,这样有利于提高访问的速度。
1 DOM在处理XML文件时,将XML文件解析成树状结构并放入内存中进行处理。当XML文件较小时,我们可以选DOM,因为它简单、直观。
2 SAX则是以事件作为解析XML文件的模式,它将XML文件转化成一系列的事件,由不同的事件处理器来决定如何处理。XML文件较大时,选择SAX技术是比较合理的。虽然代码量有些大,但是它不需要将所有的XML文件加载到内存中。这样对于有限的Android内存更有效,而且Android提供了一种传统的SAX使用方法以及一个便捷的SAX包装器。 使用Android.util.Xml类,从示例中可以看出,会比使用 SAX来得简单。
3 XML pull解析并未像SAX解析那样监听元素的结束,而是在开始处完成了大部分处理。这有利于提早读取XML文件,可以极大的减少解析时间,这种优化对于连接速度较漫的移动设备而言尤为重要。对于XML文档较大但只需要文档的一部分时,XML Pull解析器则是更为有效的方法。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!