
Maison >interface Web >js tutoriel >Comprendre les compétences loop_javascript de l'événement JS
Comprendre les compétences loop_javascript de l'événement JS

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBoriginal
- 2016-05-16 15:21:261714parcourir
Avec la popularité de JavaScript, un langage de script de navigateur Web, il est avantageux pour vous d'avoir une compréhension de base de son modèle d'interaction basé sur les événements et de sa différence avec le modèle requête-réponse commun de Ruby, Python et Java. . Dans cet article, j'expliquerai certains des concepts fondamentaux du modèle de concurrence de JavaScript, y compris sa boucle d'événements et ses files d'attente de messages, dans l'espoir d'améliorer votre compréhension d'un langage que vous utilisez peut-être déjà mais que vous ne comprenez peut-être pas complètement.
Pour qui cet article est-il écrit ?
Cet article s'adresse aux développeurs Web qui utilisent ou envisagent d'utiliser JavaScript côté client ou serveur. Si vous connaissez déjà bien les boucles d’événements, la majeure partie de cet article vous sera familière. Pour ceux qui ne sont pas encore aussi compétents, j'espère vous donner une compréhension de base qui vous aidera mieux à lire et à écrire du code au quotidien.
E/S non bloquantes
En JavaScript, presque toutes les E/S sont non bloquantes. Cela inclut les requêtes HTTP, les opérations de base de données et les lectures et écritures sur disque. L'exécution monothread nécessite que lorsqu'une opération est effectuée pendant l'exécution, une fonction de rappel soit fournie et continue ensuite à faire d'autres choses. Une fois l'opération terminée, le message est inséré dans la file d'attente avec la fonction de rappel fournie. À un moment donné dans le futur, le message est supprimé de la file d'attente et la fonction de rappel se déclenche.
Bien que ce modèle d'interaction puisse être familier aux développeurs déjà habitués à travailler avec des interfaces utilisateur, telles que les événements "mousedown" et "click" déclenchés à un moment donné. Ceci est différent du modèle requête-réponse synchrone généralement utilisé dans les applications côté serveur.
Comparons deux petits morceaux de code qui envoient une requête HTTP à www.google.com et imprimons la réponse sur la console. Tout d’abord, jetons un coup d’œil à Ruby et utilisons-le avec Faraday (une bibliothèque de développement de client HTTP Ruby) :
response = Faraday.get 'http://www.google.com' puts response puts 'Done!'
Le chemin d'exécution est facile à retracer :
1. Exécutez la méthode get et le thread d'exécution attend qu'une réponse soit reçue
2. La réponse est reçue de Google et renvoyée à l'appelant, elle est stockée dans une variable
3. La valeur de la variable (dans ce cas, notre réponse) est affichée sur la console
4. La valeur "Terminé!" est affichée sur la console
Faisons la même chose en JavaScript en utilisant Node.js et la bibliothèque Request :
request('http://www.google.com', function(error, response, body) {
console.log(body);
});
console.log('Done!');
Cela semble légèrement différent en surface, mais le comportement réel est complètement différent :
1. Exécutez la fonction de requête, transmettez une fonction anonyme comme rappel et exécutez le rappel lorsque la réponse est disponible à un moment donné dans le futur.
2. "Terminé !" est immédiatement affiché sur la console
3. À un moment donné dans le futur, lorsque la réponse reviendra et que le rappel sera exécuté, affichez son contenu sur la console
Boucle d'événement
Dissociez l'appelant et la réponse afin que JavaScript puisse faire autre chose en attendant la fin de l'opération asynchrone et le déclenchement du rappel pendant l'exécution. Mais comment ces rappels sont-ils organisés en mémoire et dans quel ordre sont-ils exécutés ? Qu’est-ce qui fait qu’on les appelle ?
Le runtime JavaScript contient une file d'attente de messages, qui stocke une liste de messages qui doivent être traités et les fonctions de rappel associées. Ces messages sont mis en file d'attente en réponse à des événements externes impliqués dans la fonction de rappel (tels que des clics de souris ou des réponses à des requêtes HTTP). Par exemple, si l'utilisateur clique sur un bouton et qu'aucune fonction de rappel n'est fournie, aucun message ne sera mis en file d'attente.
Dans une boucle, la file d'attente récupère le message suivant (chaque récupération est appelée un "tick"), et lorsqu'un événement se produit, le rappel du message est exécuté.
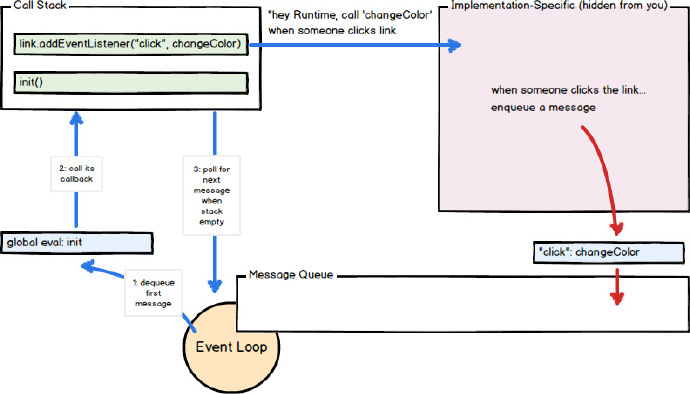
L'appel à la fonction de rappel agit comme un cadre d'initialisation (fragment) dans la pile d'appels. Puisque JavaScript est monothread, l'extraction et le traitement des futurs messages sont arrêtés en attendant le retour de tous les appels de la pile. Les appels de fonction ultérieurs (synchrones) ajoutent de nouvelles trames d'appel à la pile (par exemple, la fonction init appelle la fonction changeColor).
function init() {
var link = document.getElementById("foo");
link.addEventListener("click", function changeColor() {
this.style.color = "burlywood";
});
}
init();
Dans cet exemple, lorsque l'utilisateur clique sur l'élément "foo", un message (et sa fonction de rappel changeColor) sera inséré dans la file d'attente et l'événement "onclick" sera déclenché. Lorsqu'un message quitte la file d'attente, sa fonction de rappel changeColor est appelée. Lorsque changeColor renvoie (ou génère une erreur), la boucle d'événements continue. Tant que la fonction changeColor existe et est spécifiée comme rappel à la méthode onclick de l'élément "foo", alors cliquer sur cet élément entraînera l'insertion de plus de messages (et du rappel changeColor associé) dans la file d'attente.
Message d'ajout de file d'attente
Si une fonction est appelée de manière asynchrone dans le code (comme setTimeout), le rappel fourni sera finalement exécuté dans le cadre d'une file d'attente de messages différente, qui se produira lors d'une action future dans la boucle d'événements. Par exemple :
function f() {
console.log("foo");
setTimeout(g, 0);
console.log("baz");
h();
}
function g() {
console.log("bar");
}
function h() {
console.log("blix");
}
f();
由于setTimeout的非阻塞特性,它的回调将在至少0毫秒后触发,而不是作为消息的一部分被处理。在这个示例中,setTimeout被调用, 传入了一个回调函数g且延时0毫秒后执行。当我们指定时间到达(当前情况是,几乎立即执行),一个单独的消息将被加入队列(g作为回调函数)。控制台打印的结果会是像这样:“foo”,“baz”,“blix”,然后是事件循环的下一个动作:“bar”。如果在同一个调用片段中,两个调用都设置为setTimeout -传递给第二个参数的值也相同-则它们的回调将按照调用顺序插入队列。
Web Workers
使用Web Workers允许您能够将一项费时的操作在一个单独的线程中执行,从而可以释放主线程去做别的事情。worker(工作线程)包括一个独立的消息队列,事件循 环,内存空间独立于实例化它的原始线程。worker和主线程之间的通信通过消息传递,看起来很像我们往常常见的传统事件代码示例。

首先,我们的worker:
// our worker, which does some CPU-intensive operation
var reportResult = function(e) {
pi = SomeLib.computePiToSpecifiedDecimals(e.data);
postMessage(pi);
};
onmessage = reportResult;
然后,主要的代码块在我们的HTML中以script-标签存在:
// our main code, in a <script>-tag in our HTML page
var piWorker = new Worker("pi_calculator.js");
var logResult = function(e) {
console.log("PI: " + e.data);
};
piWorker.addEventListener("message", logResult, false);
piWorker.postMessage(100000);
在这个例子中,主线程创建一个worker,同时注册logResult回调函数到其“消息”事件。在worker里,reportResult函数注册到自己的“消息”事件中。当worker线程接收到主线程的消息,worker入队一条消息同时带上reportResult回调函数。消息出队时,一条新消息发送回主线程,新消息入队主线程队列(带上logResult回调函数)。这样,开发人员可以将cpu密集型操作委托给一个单独的线程,使主线程解放出来继续处理消息和事件。
关于闭包的
JavaScript对闭包的支持,允许你这样注册回调函数,当回调函数执行时,保持了对他们被创建的环境的访问(即使回调的执行时创建了一个全新的调用栈)。理解我们的回调作为一个不同的消息的一部分被执行,而不是创建它的那个会很有意思。看看下面的例子:
function changeHeaderDeferred() {
var header = document.getElementById("header");
setTimeout(function changeHeader() {
header.style.color = "red";
return false;
}, 100);
return false;
}
changeHeaderDeferred();
在这个例子中,changeHeaderDeferred函数被执行时包含了变量header。函数 setTimeout被调用,导致消息(带上changeHeader回调)被添加到消息队列,在大约100毫秒后执行。然后 changeHeaderDeferred函数返回false,结束第一个消息的处理,但header变量仍然可以通过闭包被引用,而不是被垃圾回收。当 第二个消息被处理(changeHeader函数),它保持了对在外部函数作用域中声明的header变量的访问。一旦第二个消息 (changeHeader函数)执行结束,header变量可以被垃圾回收。
提醒
JavaScript 事件驱动的交互模型不同于许多程序员习惯的请求-响应模型,但如你所见,它并不复杂。使用简单的消息队列和事件循环,JavaScript使得开发人员在构建他们的系统时使用大量asynchronously-fired(异步-触发)回调函数,让运行时环境能在等待外部事件触发的同时处理并发操作。然而,这不过是并发的一种方法。
以上就是本文的全部内容,希望对大家的学习有所帮助。
Articles Liés
Voir plus- Une analyse approfondie du composant de groupe de liste Bootstrap
- Explication détaillée du currying de la fonction JavaScript
- Exemple complet de génération de mot de passe JS et de détection de force (avec téléchargement du code source de démonstration)
- Angularjs intègre l'interface utilisateur WeChat (weui)
- Comment basculer rapidement entre le chinois traditionnel et le chinois simplifié avec JavaScript et l'astuce permettant aux sites Web de prendre en charge le basculement entre les compétences en chinois simplifié et traditionnel_javascript