
Maison >interface Web >js tutoriel >Tutoriel avancé du robot Nodejs sur la concurrence asynchrone control_node.js
Tutoriel avancé du robot Nodejs sur la concurrence asynchrone control_node.js

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBoriginal
- 2016-05-16 15:15:381968parcourir
J'ai déjà écrit un petit robot qui semble très imparfait maintenant. De nombreux aspects n'ont pas été bien gérés. Par exemple, lorsque vous cliquez sur une question sur Zhihu, toutes ses réponses ne sont pas chargées lorsque vous y arrivez. À la fin de la réponse, cliquez sur Charger plus et la réponse sera à nouveau chargée. Par conséquent, si vous envoyez directement un lien de demande vers une question, la page obtenue sera incomplète. De plus, lorsque nous téléchargeons des images en envoyant des liens, nous les téléchargeons une par une. S'il y a trop d'images, elles seront toujours téléchargées une fois que vous aurez fini de dormir. De plus, le robot que nous avons écrit avec nodejs ne télécharge pas les images une par une. one. C'est un tel gaspillage que la fonctionnalité asynchrone et simultanée la plus puissante de nodejs ne soit pas utilisée.
Pensées
Le robot de cette fois est une version améliorée du dernier. Cependant, même si le dernier était simple, il convient très bien aux novices. Le code du robot cette fois peut être trouvé sur mon github => NodeSpider.
L'idée de l'ensemble du robot est la suivante : au début, nous avons exploré une partie des données de la page via le lien de la question de la requête, puis nous avons simulé la requête ajax dans le code pour intercepter les données restantes de la page. Bien sûr, cela peut également être fait de manière asynchrone ici. Pour obtenir la concurrence, pour le contrôle de processus asynchrone à petite échelle, vous pouvez utiliser ce module => eventproxy, mais je n'en ai aucune utilité ici ! Nous interceptons les liens de toutes les images en analysant la page obtenue, puis implémentons le téléchargement par lots de ces images via une concurrence asynchrone.
Il est très simple de capturer les données initiales de la page, je n'expliquerai donc pas grand chose ici
/*获取首屏所有图片链接*/
var getInitUrlList=function(){
request.get("https://www.zhihu.com/question/")
.end(function(err,res){
if(err){
console.log(err);
}else{
var $=cheerio.load(res.text);
var answerList=$(".zm-item-answer");
answerList.map(function(i,answer){
var images=$(answer).find('.zm-item-rich-text img');
images.map(function(i,image){
photos.push($(image).attr("src"));
});
});
console.log("已成功抓取"+photos.length+"张图片的链接");
getIAjaxUrlList();
}
});
}
Simulez la requête ajax pour obtenir la page complète
La prochaine étape est de savoir comment simuler la requête ajax émise en cliquant pour charger plus, allez sur Zhihu et jetez un œil !
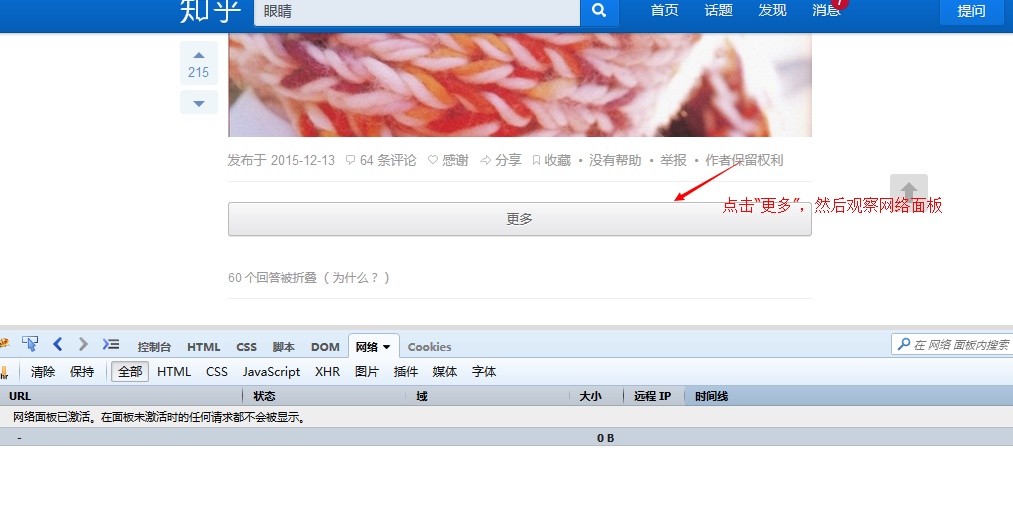
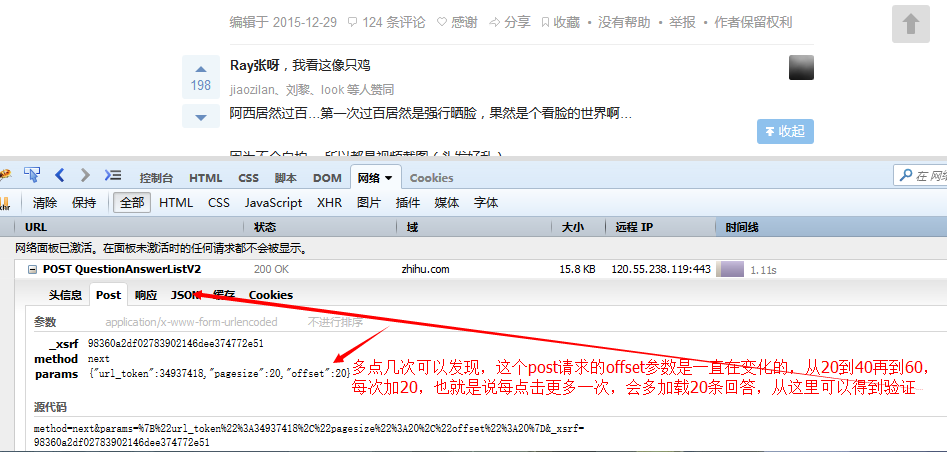
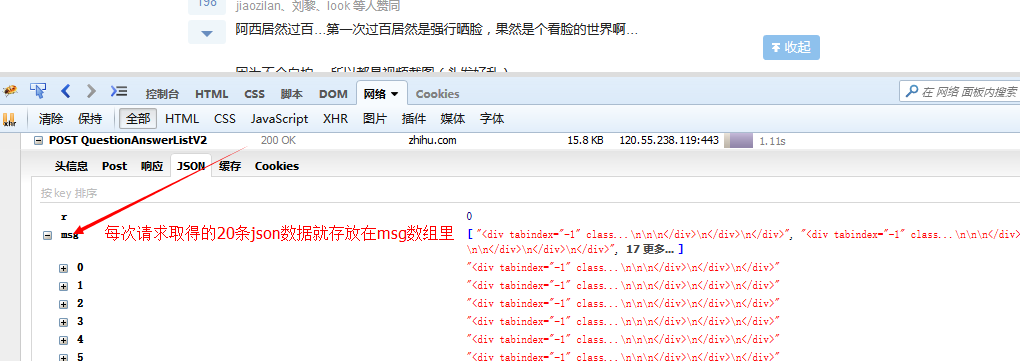
Avec ces informations, vous pouvez simuler l'envoi de la même requête pour obtenir ces données.
/*每隔毫秒模拟发送ajax请求,并获取请求结果中所有的图片链接*/
var getIAjaxUrlList=function(offset){
request.post("https://www.zhihu.com/node/QuestionAnswerListV")
.set(config)
.send("method=next¶ms=%B%url_token%%A%C%pagesize%%A%C%offset%%A" +offset+ "%D&_xsrf=adfdeee")
.end(function(err,res){
if(err){
console.log(err);
}else{
var response=JSON.parse(res.text);/*想用json的话对json序列化即可,提交json的话需要对json进行反序列化*/
if(response.msg&&response.msg.length){
var $=cheerio.load(response.msg.join(""));/*把所有的数组元素拼接在一起,以空白符分隔,不要这样join(),它会默认数组元素以逗号分隔*/
var answerList=$(".zm-item-answer");
answerList.map(function(i,answer){
var images=$(answer).find('.zm-item-rich-text img');
images.map(function(i,image){
photos.push($(image).attr("src"));
});
});
setTimeout(function(){
offset+=;
console.log("已成功抓取"+photos.length+"张图片的链接");
getIAjaxUrlList(offset);
},);
}else{
console.log("图片链接全部获取完毕,一共有"+photos.length+"条图片链接");
// console.log(photos);
return downloadImg();
}
}
});
}
Publiez cette demande dans le code https://www.zhihu.com/node/QuestionAnswerListV2, copiez les en-têtes de demande et les paramètres de demande d'origine comme nos en-têtes de demande et paramètres de demande, superagent La méthode set peut être utilisé pour définir les en-têtes de requête, et la méthode d'envoi peut être utilisée pour envoyer les paramètres de requête. Nous initialisons le décalage dans le paramètre de requête à 20, ajoutons 20 au décalage à chaque fois, puis renvoyons la demande. Cela équivaut à envoyer une requête ajax à chaque fois et à obtenir les 20 dernières données à chaque fois. Obtenez le Lorsque nous obtiendrons les données, nous traiterons les données dans une certaine mesure et les transformerons en un paragraphe entier de HTML, ce qui facilitera l'extraction ultérieure et le traitement des liens. Une fois que le contrôle de concurrence asynchrone a téléchargé les images et obtenu tous les liens d'images, c'est-à-dire lorsqu'il est déterminé que réponse.msg est vide, nous téléchargerons ces images une par une, car comme vous pouvez le voir, nous. Il y a assez de photos
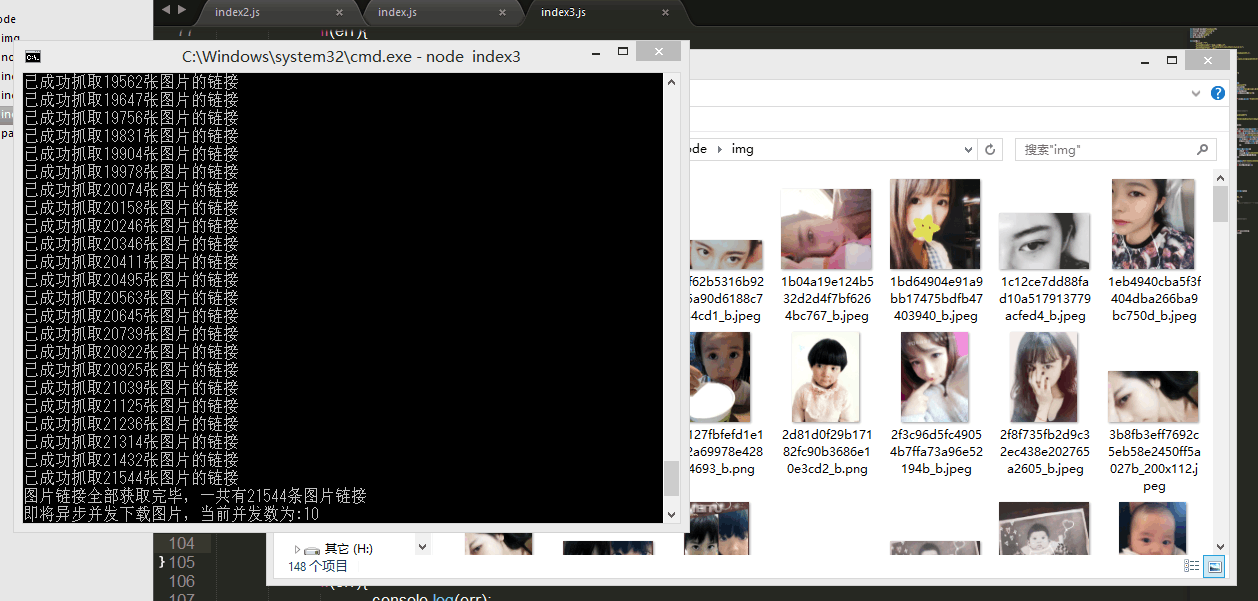
Oui, plus de 20 000 images, mais heureusement, nodejs possède la fonctionnalité magique asynchrone mono-thread, nous pouvons télécharger ces images en même temps. Mais cette fois, un problème surgit. J’ai entendu dire que si trop de requêtes étaient envoyées en même temps, l’adresse IP serait bloquée par le site ! Est-ce vrai ? Je ne sais pas, je ne l'ai pas essayé, parce que je ne veux pas l'essayer ( ̄ー ̄〃), donc pour le moment, nous devons contrôler le nombre de concurrence asynchrone.
Un module magique est utilisé ici => async, qui nous aide non seulement à nous débarrasser du diable de la pyramide de rappel difficile à maintenir, mais nous aide également à gérer facilement les processus asynchrones. Veuillez vous référer à la documentation pour plus de détails. Comme je ne sais pas comment l'utiliser moi-même, j'utilise ici uniquement la puissante méthode async.mapLimit. C'est vraiment génial.
var requestAndwrite=function(url,callback){
request.get(url).end(function(err,res){
if(err){
console.log(err);
console.log("有一张图片请求失败啦...");
}else{
var fileName=path.basename(url);
fs.writeFile("./img/"+fileName,res.body,function(err){
if(err){
console.log(err);
console.log("有一张图片写入失败啦...");
}else{
console.log("图片下载成功啦");
callback(null,"successful !");
/*callback貌似必须调用,第二个参数将传给下一个回调函数的result,result是一个数组*/
}
});
}
});
}
var downloadImg=function(asyncNum){
/*有一些图片链接地址不完整没有“http:”头部,帮它们拼接完整*/
for(var i=;i<photos.length;i++){
if(photos[i].indexOf("http")===-){
photos[i]="http:"+photos[i];
}
}
console.log("即将异步并发下载图片,当前并发数为:"+asyncNum);
async.mapLimit(photos,asyncNum,function(photo,callback){
console.log("已有"+asyncNum+"张图片进入下载队列");
requestAndwrite(photo,callback);
},function(err,result){
if(err){
console.log(err);
}else{
// console.log(result);<=会输出一个有万多个“successful”字符串的数组
console.log("全部已下载完毕!");
}
});
};
Regardez ici d'abord=>
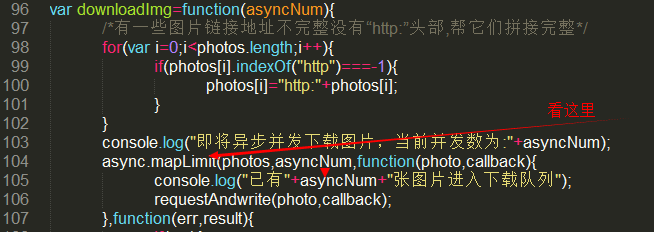
Le premier paramètre photos de la méthode mapLimit est un tableau de tous les liens d'images, qui fait également l'objet de nos requêtes simultanées. asyncNum limite le nombre de requêtes simultanées. Sans ce paramètre, plus de 20 000 requêtes seront envoyées au niveau. en même temps, eh bien, votre IP sera bloquée avec succès, mais lorsque nous avons ce paramètre, par exemple, sa valeur est 10, cela nous aidera seulement à récupérer 10 liens du tableau à la fois et à exécuter des requêtes simultanées après ces 10. les demandes reçoivent une réponse, les 10 demandes suivantes sont envoyées. Dites à Ni Meng, c'est normal d'envoyer 100 messages en même temps. La vitesse de téléchargement est super rapide, je ne sais pas si elle augmente encore. S'il vous plaît, dites-moi...
.
Ce qui précède vous a présenté les connaissances pertinentes sur le contrôle de concurrence asynchrone dans le didacticiel avancé du robot Nodejs. J'espère que cela vous sera utile.
Articles Liés
Voir plus- Une analyse approfondie du composant de groupe de liste Bootstrap
- Explication détaillée du currying de la fonction JavaScript
- Exemple complet de génération de mot de passe JS et de détection de force (avec téléchargement du code source de démonstration)
- Angularjs intègre l'interface utilisateur WeChat (weui)
- Comment basculer rapidement entre le chinois traditionnel et le chinois simplifié avec JavaScript et l'astuce permettant aux sites Web de prendre en charge le basculement entre les compétences en chinois simplifié et traditionnel_javascript