
Maison >développement back-end >C++ >CS - Semaine 5
CS - Semaine 5

- Susan Sarandonoriginal
- 2024-12-28 11:38:24957parcourir
Structures de données
LesLes structures d'information sont des formes d'organisation des informations en mémoire. Il existe de nombreuses façons d'organiser les données en mémoire.
LesLes structures de données abstraites sont des structures que nous imaginons conceptuellement. La familiarité avec ces structures abstraites facilite la mise en œuvre pratique des structures de données à l'avenir.
Pile et file d'attente
La file d'attente est une forme de structures de données abstraites.
La structure de données Queue fonctionne selon la règle FIFO (First In First Out, "le premier élément ajouté sort en premier").
Cela peut être imaginé comme un exemple de personnes faisant la queue devant une attraction : la première personne en ligne entre en premier et la dernière entre en dernier.
Files d'attente :
- Mise en file d'attente : ajoute un nouvel élément à la fin de la file d'attente.
- Dequeue : supprime un élément du début de la file d'attente.
Stack fonctionne selon la règle LIFO (Last In First Out, "le dernier élément ajouté sort en premier")
.
Par exemple, empiler les assiettes dans la cuisine : la dernière assiette est prise en premier.
Stack a les opérations suivantes :
- Push : mettre un nouvel élément sur la pile.
- Pop : supprime un élément de la pile.
Tableau
Array est une méthode de stockage séquentiel de données en mémoire. Un tableau peut être visualisé comme :

La mémoire peut contenir d'autres valeurs stockées par d'autres programmes, fonctions et variables, ainsi que des valeurs redondantes qui étaient auparavant utilisées et ne sont plus utilisées :

Si nous voulons ajouter un nouvel élément - 4 - au tableau, nous devons allouer une nouvelle mémoire et y déplacer l'ancien tableau. Cette nouvelle mémoire est peut-être pleine de valeurs inutiles :


L'inconvénient de cette approche est que l'intégralité du tableau doit être copiée à chaque fois qu'un nouvel élément est ajouté.
Et si on mettait 4 ailleurs en mémoire ? Alors, par définition, ce n'est plus un tableau, car 4 n'est pas contigu aux éléments du tableau en mémoire.
Parfois, les programmeurs allouent plus de mémoire que nécessaire (par exemple 300 pour 30 éléments). Mais c’est une mauvaise conception car cela gaspille les ressources du système et, dans la plupart des cas, la mémoire supplémentaire n’est pas nécessaire. Par conséquent, il est important d'allouer la mémoire en fonction du besoin spécifique.
Liste liée
LaListe chaînée est l'une des structures de données les plus puissantes du langage de programmation C. Ils permettent de combiner des valeurs situées dans différentes régions de mémoire en une seule liste. Cela nous permet également d'élargir ou de réduire dynamiquement la liste à notre guise.

Chaque nœud stocke deux valeurs :
- valeur ;
- est un pointeur qui contient l'adresse mémoire du nœud suivant. Et le dernier nœud contient NULL pour indiquer qu'il n'y a aucun autre élément après lui.

Nous enregistrons l'adresse du premier élément de la liste chaînée dans un pointeur (pointeur).

Dans le langage de programmation C, on peut écrire node comme :
typedef struct node
{
int number;
struct node *next;
}
node;
Regardons le processus de création de Liste chaînée :
- Nous déclarons le nœud *list :

- allouer de la mémoire pour le nœud :
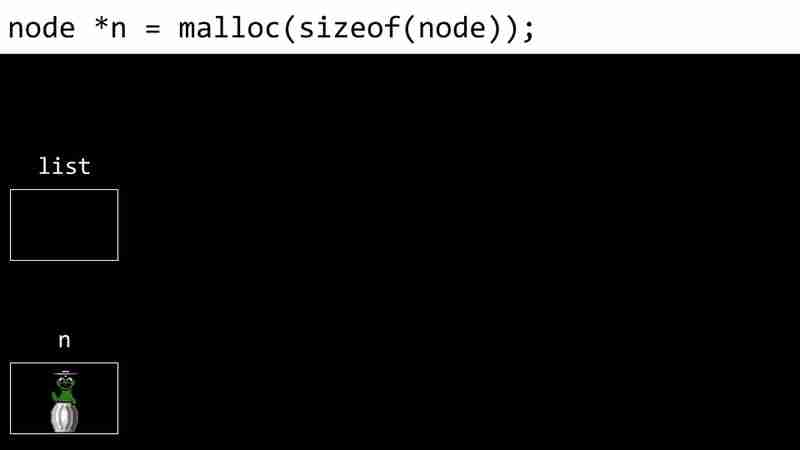
- entrez la valeur du nœud : n->numéro = 1 :

- Nous définissons l'index suivant du nœud sur NULL : n->next = NULL:

- égalisons la liste à :

- Dans le même ordre, on crée un nouveau nœud de valeur 2 :

- Afin de connecter les deux nœuds, nous définissons l'index suivant de n sur la liste :

- Et enfin, nous définissons la liste sur n. Nous avons maintenant une liste chaînée composée de deux éléments :

Dans le langage de programmation C, on peut écrire le code de ce processus comme suit :
typedef struct node
{
int number;
struct node *next;
}
node;
Il y a plusieurs inconvénients à travailler avec une liste chaînée :
- Plus de mémoire : pour chaque élément, il est nécessaire de stocker non seulement la valeur de l'élément lui-même, mais également un pointeur vers l'élément suivant.
- Appeler des éléments par index : dans les tableaux, nous pouvons appeler un certain élément par index, mais dans une liste chaînée, c'est impossible. Pour trouver la position d'un élément particulier, il faut parcourir tous les éléments dans l'ordre, en commençant par le premier élément.
Arbre
Arbre de recherche binaire (BST) est une structure d'information qui permet un stockage, une recherche et une récupération efficaces des données.
Donnons-nous une séquence de nombres triés :

On place l'élément au centre en haut, les valeurs plus petites que l'élément au centre à gauche, et les valeurs plus grandes à droite :

Nous connectons chaque élément les uns aux autres à l'aide de pointeurs :

Le code suivant montre comment implémenter BST :
#include <cs50.h>
#include <stdio.h>
#include <stdlib.h>
typedef struct node
{
int number;
struct node *next;
}
node;
int main(int argc, char *argv[])
{
// Linked list'ni e'lon qilamiz
node *list = NULL;
// Har bir buyruq qatori argumenti uchun
for (int i = 1; i < argc; i++)
{
// Argumentni butun songa o‘tkazamiz
int number = atoi(argv[i]);
// Yangi element uchun xotira ajratamiz
node *n = malloc(sizeof(node));
if (n == NULL)
{
return 1;
}
n->number = number;
n->next = NULL;
// Linked list'ning boshiga node'ni qo‘shamiz
n->next = list;
list = n;
}
// Linked list elementlarini ekranga chiqaramiz
node *ptr = list;
while (ptr != NULL)
{
printf("%i\n", ptr->number);
ptr = ptr->next;
}
// Xotirani bo‘shatamiz
ptr = list;
while (ptr != NULL)
{
node *next = ptr->next;
free(ptr);
ptr = next;
}
}
Nous allouons de la mémoire pour chaque nœud et sa valeur est stockée en nombre, donc chaque nœud a des indicateurs gauche et droit. La fonction print_tree imprime chaque nœud en récursion séquentielle de gauche à droite. La fonction free_tree libère récursivement tous les nœuds de la structure de données de la mémoire.
Avantages duBST :
- Dynamisme : nous pouvons ajouter ou supprimer efficacement des éléments.
- Efficacité de recherche : Le temps nécessaire pour rechercher un élément donné dans BST est O(log n), puisque la moitié de l'arbre est exclue de la recherche à chaque recherche.
BST :
- Si l'équilibre de l'arbre est rompu (par exemple, si tous les éléments sont placés dans une rangée), l'efficacité de la recherche tombe à O(n).
- Nécessite de stocker les pointeurs gauche et droit pour chaque nœud, ce qui augmente la consommation de mémoire sur l'ordinateur.
Dictionnaire
Dictionnaire est comme un livre de dictionnaire, il contient un mot et sa définition, ses éléments clé (clé) et valeur a (valeur).
Si nous interrogeonsDictionary pour un élément, il nous renvoie l'élément en un temps O(1). Les dictionnaires peuvent fournir exactement cette vitesse grâce au hachage.
Le hachage est le processus de conversion des données du tableau d'entrée en une séquence de bits à l'aide d'un algorithme spécial.
Une fonction de hachage est un algorithme qui génère une chaîne de bits de longueur fixe à partir d'une chaîne de longueur arbitraire.
Table de hachage est une excellente combinaison de tableaux et de listes chaînées. On peut l'imaginer ainsi :

Collision (Collision) se produit lorsque deux entrées différentes produisent une valeur de hachage. Dans l'image ci-dessus, les éléments qui entrent en collision sont connectés sous forme de liste chaînée. En améliorant la fonction de hachage, la probabilité de collision peut être réduite.
Un exemple simple de fonction de hachage est :
typedef struct node
{
int number;
struct node *next;
}
node;
Cet article utilise la source CS50x 2024.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Erreur de compilation C++ : Un fichier d'en-tête est référencé plusieurs fois, comment le résoudre ?
- Erreur de compilation C++ : paramètres de fonction incorrects, comment y remédier ?
- Erreur C++ : Le constructeur doit être déclaré dans l'espace public, comment y faire face ?
- Gestion des processus et synchronisation des threads en C++
- Comment gérer les problèmes de fractionnement des données dans le développement C++