
Maison >Java >javaDidacticiel >Quelque chose pourrait doubler l'efficacité du développement des programmeurs Java
Quelque chose pourrait doubler l'efficacité du développement des programmeurs Java

- 王林original
- 2024-09-06 16:31:31367parcourir
Dilemme informatique dans l'application
Développement et cadre, lesquels devraient recevoir la plus haute priorité ?
Java est le langage de programmation le plus couramment utilisé dans le développement d'applications. Mais écrire du code pour traiter des données en Java n’est pas simple. Par exemple, vous trouverez ci-dessous le code Java pour effectuer le regroupement et l'agrégation sur deux champs :
Map<Integer, Map<String, Double>> summary = new HashMap<>();
for (Order order : orders) {
int year = order.orderDate.getYear();
String sellerId = order.sellerId;
double amount = order.amount;
Map<String, Double> salesMap = summary.get(year);
if (salesMap == null) {
salesMap = new HashMap<>();
summary.put(year, salesMap);
}
Double totalAmount = salesMap.get(sellerId);
if (totalAmount == null) {
totalAmount = 0.0;
}
salesMap.put(sellerId, totalAmount + amount);
}
for (Map.Entry<Integer, Map<String, Double>> entry : summary.entrySet()) {
int year = entry.getKey();
Map<String, Double> salesMap = entry.getValue();
System.out.println("Year: " + year);
for (Map.Entry<String, Double> salesEntry : salesMap.entrySet()) {
String sellerId = salesEntry.getKey();
double totalAmount = salesEntry.getValue();
System.out.println(" Seller ID: " + sellerId + ", Total Amount: " + totalAmount);
}
}
En revanche, l'équivalent SQL est beaucoup plus simple. Une clause GROUP BY suffit pour clôturer le calcul.
SELECT année (date de commande), identifiant du vendeur, somme (montant) DES commandes GROUPER PAR année (date de commande), identifiant du vendeur
En effet, les premières applications fonctionnaient avec la collaboration de Java et SQL. Le processus métier a été implémenté en Java côté application et les données ont été traitées en SQL dans la base de données backend. Le cadre était difficile à étendre et à migrer en raison des limitations de la base de données. Cela était très hostile aux applications contemporaines. De plus, à de nombreuses reprises, SQL n'était pas disponible lorsqu'il n'y avait pas de bases de données ou que des calculs inter-bases de données étaient impliqués.
Compte tenu de cela, de nombreuses applications ont ensuite commencé à adopter un cadre entièrement basé sur Java, dans lequel les bases de données n'effectuent que de simples opérations de lecture et d'écriture et les processus métier et le traitement des données sont implémentés en Java du côté des applications, en particulier lorsque les microservices ont émergé. De cette façon, l'application est découplée des bases de données et bénéficie d'une bonne évolutivité et migration, ce qui permet de bénéficier des avantages du framework tout en devant faire face à la complexité du développement Java mentionnée précédemment.
Il semble que nous ne puissions nous concentrer que sur un seul aspect : le développement ou le cadre. Pour profiter des avantages du framework Java, il faut endurer des difficultés de développement ; et pour utiliser SQL, il faut tolérer les lacunes du framework. Cela crée un dilemme.
Alors que pouvons-nous faire ?
Qu'en est-il de l'amélioration des capacités de traitement des données de Java ? Cela évite non seulement les problèmes SQL, mais corrige également les lacunes de Java.
En fait, Java Stream/Kotlin/Scala essaient tous de le faire.
Diffusez
Le Stream introduit dans Java 8 a ajouté de nombreuses méthodes de traitement des données. Voici le code Stream pour implémenter le calcul ci-dessus :
Map<Integer, Map<String, Double>> summary = orders.stream()
.collect(Collectors.groupingBy(
order -> order.orderDate.getYear(),
Collectors.groupingBy(
order -> order.sellerId,
Collectors.summingDouble(order -> order.amount)
)
));
summary.forEach((year, salesMap) -> {
System.out.println("Year: " + year);
salesMap.forEach((sellerId, totalAmount) -> {
System.out.println(" Seller ID: " + sellerId + ", Total Amount: " + totalAmount);
});
});
Stream simplifie en effet le code dans une certaine mesure. Mais dans l’ensemble, il reste lourd et bien moins concis que SQL.
Kotlin
Kotlin, qui prétendait être plus puissant, s'est encore amélioré :
val summary = orders
.groupBy { it.orderDate.year }
.mapValues { yearGroup ->
yearGroup.value
.groupBy { it.sellerId }
.mapValues { sellerGroup ->
sellerGroup.value.sumOf { it.amount }
}
}
summary.forEach { (year, salesMap) ->
println("Year: $year")
salesMap.forEach { (sellerId, totalAmount) ->
println(" Seller ID: $sellerId, Total Amount: $totalAmount")
}
}
Le code Kotlin est plus simple, mais l'amélioration est limitée. Il y a encore un gros écart par rapport à SQL.
Scala
Puis il y a eu Scala :
val summary = orders
.groupBy(order => order.orderDate.getYear)
.mapValues(yearGroup =>
yearGroup
.groupBy(_.sellerId)
.mapValues(sellerGroup => sellerGroup.map(_.amount).sum)
)
summary.foreach { case (year, salesMap) =>
println(s"Year: $year")
salesMap.foreach { case (sellerId, totalAmount) =>
println(s" Seller ID: $sellerId, Total Amount: $totalAmount")
}
}
Scala est un peu plus simple que Kotlin, mais ne peut toujours pas être comparé à SQL. De plus, Scala est trop lourd et peu pratique à utiliser.
En fait, ces technologies sont sur la bonne voie, même si elles ne sont pas parfaites.
Les langages compilés ne sont pas remplaçables à chaud
De plus, Java, étant un langage compilé, ne prend pas en charge le remplacement à chaud. La modification du code nécessite une recompilation et un redéploiement, nécessitant souvent des redémarrages du service. Cela se traduit par une expérience sous-optimale face à des changements fréquents d’exigences. En revanche, SQL n'a aucun problème à cet égard.

Le développement Java est compliqué et le framework présente également des lacunes. SQL a du mal à répondre aux exigences du framework. Le dilemme est difficile à résoudre. Existe-t-il un autre moyen ?
La solution ultime – esProc SPL
esProc SPL est un langage de traitement de données développé uniquement en Java. Il a un développement simple et un cadre flexible.
Syntaxe concise
Passons en revue les implémentations Java pour l'opération de regroupement et d'agrégation ci-dessus :

Comparez avec le code Java, le code SPL est beaucoup plus concis :
Orders.groups(year(orderdate),sellerid;sum(amount))
C'est aussi simple que l'implémentation SQL :
SELECT year(orderdate),sellerid,sum(amount) FROM orders GROUP BY year(orderDate),sellerid
En fait, le code SPL est souvent plus simple que son homologue SQL. Grâce à la prise en charge des calculs basés sur des ordres et procéduraux, SPL est plus efficace pour effectuer des calculs complexes. Prenons cet exemple : calculez le nombre maximum de jours de hausse consécutifs d’un titre. SQL a besoin de l'instruction imbriquée à trois couches suivante, qui est difficile à comprendre, sans parler de l'écriture.
select max(continuousDays)-1
from (select count(*) continuousDays
from (select sum(changeSign) over(order by tradeDate) unRiseDays
from (select tradeDate,
case when closePrice>lag(closePrice) over(order by tradeDate)
then 0 else 1 end changeSign
from stock) )
group by unRiseDays)
SPL implémente le calcul avec une seule ligne de code. C'est encore beaucoup plus simple que le code SQL, sans parler du code Java.
stock.sort(tradeDate).group@i(price<price[-1]).max(~.len())
Comprehensive, independent computing capability
SPL has table sequence – the specialized structured data object, and offers a rich computing class library based on table sequences to handle a variety of computations, including the commonly seen filtering, grouping, sorting, distinct and join, as shown below:
Orders.sort(Amount) // Sorting Orders.select(Amount*Quantity>3000 && like(Client,"*S*")) // Filtering Orders.groups(Client; sum(Amount)) // Grouping Orders.id(Client) // Distinct join(Orders:o,SellerId ; Employees:e,EId) // Join ……
More importantly, the SPL computing capability is independent of databases; it can function even without a database, which is unlike the ORM technology that requires translation into SQL for execution.
Efficient and easy to use IDE
Besides concise syntax, SPL also has a comprehensive development environment offering debugging functionalities, such as “Step over” and “Set breakpoint”, and very debugging-friendly WYSIWYG result viewing panel that lets users check result for each step in real time.
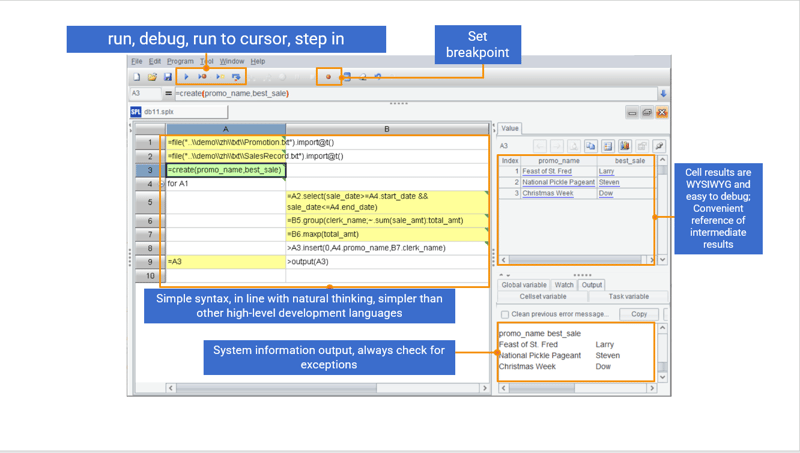
Support for large-scale data computing
SPL supports processing large-scale data that can or cannot fit into the memory.
In-memory computation:

External memory computation:

We can see that the SPL code of implementing an external memory computation and that of implementing an in-memory computation is basically the same, without extra computational load.
It is easy to implement parallelism in SPL. We just need to add @m option to the serial computing code. This is far simpler than the corresponding Java method.

Seamless integration into Java applications
SPL is developed in Java, so it can work by embedding its JARs in the Java application. And the application executes or invokes the SPL script via the standard JDBC. This makes SPL very lightweight, and it can even run on Android.
Call SPL code through JDBC:
Class.forName("com.esproc.jdbc.InternalDriver");
con= DriverManager.getConnection("jdbc:esproc:local://");
st =con.prepareCall("call SplScript(?)");
st.setObject(1, "A");
st.execute();
ResultSet rs = st.getResultSet();
ResultSetMetaData rsmd = rs.getMetaData();
As it is lightweight and integration-friendly, SPL can be seamlessly integrated into mainstream Java frameworks, especially suitable for serving as a computing engine within microservice architectures.
Highly open framework
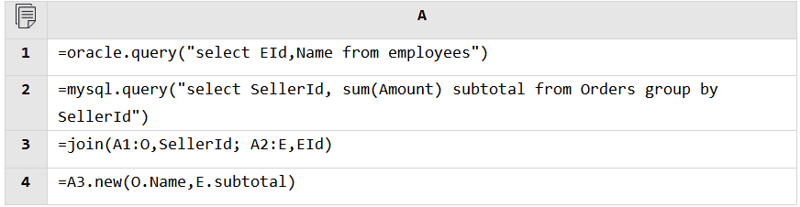
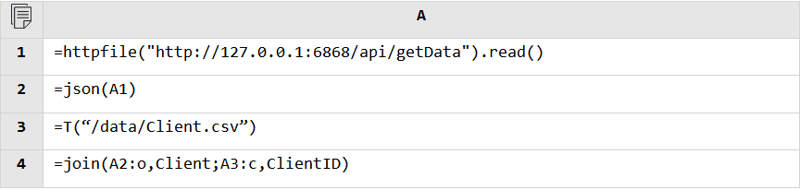
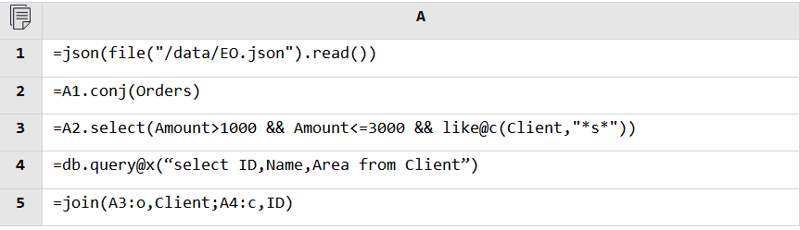
SPL’s great openness enables it to directly connect to various types of data sources and perform real-time mixed computations, making it easy to handle computing scenarios where databases are unavailable or multiple/diverse databases are involved.

Regardless of the data source, SPL can read data from it and perform the mixed computation as long as it is accessible. Database and database, RESTful and file, JSON and database, anything is fine.
Databases:
RESTful and file:
JSON and database:
Interpreted execution and hot-swapping
SPL is an interpreted language that inherently supports hot swapping while power remains switched on. Modified code takes effect in real-time without requiring service restarts. This makes SPL well adapt to dynamic data processing requirements.

This hot—swapping capability enables independent computing modules with separate management, maintenance and operation, creating more flexible and convenient uses.
SPL can significantly increase Java programmers’ development efficiency while achieving framework advantages. It combines merits of both Java and SQL, and further simplifies code and elevates performance.
SPL open source address
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment dessiner des rectangles persistants dans un JPanel sans dégradation des performances ?
- Attentes implicites ou explicites dans Selenium : quand devriez-vous choisir l'attente explicite ?
- Comment remplacer correctement les barres obliques inverses simples par des barres obliques inverses doubles dans les chaînes Java ?
- Évaluation des courts-circuits : quand devez-vous utiliser `||` plutôt que `|` ?
- Comment les assertions Java peuvent-elles améliorer la qualité du code et prévenir les erreurs ?