La rubrique AIxiv est une rubrique où des contenus académiques et techniques sont publiés sur ce site. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. E-mail de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com
Les tests unitaires sont un maillon clé du processus de développement logiciel et sont principalement utilisés. pour Vérifiez que la plus petite unité, fonction ou module testable dans le logiciel fonctionne comme prévu. L'objectif des tests unitaires est de garantir que chaque fragment de code indépendant peut remplir correctement sa fonction, ce qui est d'une grande importance pour améliorer la qualité des logiciels et l'efficacité du développement. Cependant, les grands modèles à eux seuls sont incapables de générer des ensembles d'échantillons de test à haute couverture pour les fonctions complexes testées (cyclocomplexité supérieure à 10). Afin de résoudre ce problème, l'équipe du professeur Li Ge de l'Université de Pékin a proposé une nouvelle méthode pour améliorer la couverture des cas de test. Cette méthode utilise le découpage du programme (Method Slicing) pour décomposer les fonctions complexes testées en plusieurs fragments simples basés sur la sémantique. le grand modèle génère des cas de test pour chaque fragment simple séparément. Lors de la génération d'un seul cas de test, le grand modèle n'a besoin d'analyser qu'un fragment de la fonction originale à tester, ce qui réduit la difficulté d'analyse et la difficulté de générer des tests unitaires couvrant ce fragment. Cette promotion peut améliorer la couverture du code de l’ensemble global d’échantillons de test. L'article connexe « HITS : High-coverage LLM-based Unit Test Generation via Method Slicing » a été récemment publié par l'ASE 2024 (lors de la 39e conférence internationale IEEE/ACM sur Génie logiciel automatisé) sera accepté. 
Adresse papier : https://www.arxiv.org/pdf/2408.11324Regardez ensuite Le spécifique contenu de la recherche papier de l'équipe de l'Université de Pékin : HITS utilise de grands modèles pour le partitionnement de programmesLe partitionnement de programme fait référence à la division d'un programme en plusieurs étapes de résolution de problèmes basées sur la sémantique. Un programme est l'expression formelle d'une solution à un problème. Une solution à un problème se compose généralement de plusieurs étapes, chaque étape correspondant à une tranche de code dans le programme. Comme le montre la figure ci-dessous, un bloc de couleur correspond à un morceau de code et une étape pour résoudre le problème.
HITS erfordert, dass das große Modell Unit-Test-Code für jeden Codeabschnitt entwirft, der ihn effizient abdecken kann. Nehmen wir die obige Abbildung als Beispiel: Wenn wir die in der Abbildung gezeigten Slices erhalten, erfordert HITS, dass das große Modell Testproben für Slice 1 (grün), Slice 2 (blau) bzw. Slice 3 (rot) generiert. Die für Slice 1 generierten Testbeispiele sollten Slice 1 so weit wie möglich abdecken, unabhängig von Slice 2 und Slice 3. Das Gleiche gilt für andere Codeteile. HITS funktioniert aus zwei Gründen. Erstens sollten große Modelle darüber nachdenken, die Menge des abgedeckten Codes zu reduzieren. Am Beispiel der obigen Abbildung müssen beim Generieren von Testproben für Slice 3 nur die bedingten Zweige in Slice 3 berücksichtigt werden. Um einige bedingte Zweige in Slice 3 abzudecken, müssen Sie nur einen Ausführungspfad in Slice 1 und Slice 2 finden, ohne die Auswirkungen dieses Ausführungspfads auf die Abdeckung von Slice 1 und Slice 2 zu berücksichtigen. Zweitens helfen Codeteile, die auf der Grundlage der Semantik (Problemlösungsschritte) segmentiert sind, großen Modellen dabei, die Zwischenzustände der Codeausführung zu erfassen. Beim Generieren von Testfällen für spätere Codeblöcke müssen Änderungen am Programmstatus berücksichtigt werden, die durch vorherigen Code verursacht wurden. Da Codeblöcke nach tatsächlichen Problemlösungsschritten segmentiert sind, können die Operationen vorheriger Codeblöcke in natürlicher Sprache beschrieben werden (wie in der Anmerkung in der Abbildung oben gezeigt). Da die meisten aktuellen großen Sprachmodelle das Produkt eines gemischten Trainings zwischen natürlicher Sprache und Programmiersprache sind, kann eine gute Zusammenfassung natürlicher Sprache großen Modellen dabei helfen, durch Code verursachte Änderungen im Programmstatus genauer zu erfassen. HITS verwendet große Modelle für das Programm-Sharding. Die Problemlösungsschritte werden normalerweise in natürlicher Sprache mit der subjektiven Farbe des Programmierers ausgedrückt, sodass große Modelle mit überlegenen Fähigkeiten zur Verarbeitung natürlicher Sprache direkt verwendet werden können. Insbesondere nutzt HITS das Lernen im Kontext, um große Modelle aufzurufen. Das Team nutzte seine bisherigen praktischen Erfahrungen in realen Szenarien, um mehrere Programm-Sharding-Beispiele manuell zu schreiben. Nach mehreren Anpassungen entsprach die Wirkung des großen Modells auf das Programm-Sharding den Erwartungen des Forschungsteams. Testbeispiele für Codeausschnitte generierenAngesichts des abzudeckenden Codeausschnitts, Um entsprechende Testproben zu generieren, müssen Sie die folgenden drei Schritte ausführen: 1. Analysieren Sie die Eingabe des Fragments. 2. Erstellen Sie eine Eingabeaufforderung, um das große Modell anzuweisen, eine erste Testprobe zu generieren Selbst-Debug-Anpassung für große Modelle Testen Sie das Beispiel, damit es ordnungsgemäß ausgeführt wird. Analysieren Sie die Eingabe des Fragments, was bedeutet, dass alle externen Eingaben, die vom Fragment akzeptiert werden, für die spätere sofortige Verwendung extrahiert werden. Externe Eingabe bezieht sich auf lokale Variablen, die durch vorherige Fragmente definiert wurden, auf die dieses Fragment angewendet wird, formale Parameter der zu testenden Methode, innerhalb des Fragments aufgerufene Methoden und externe Variablen. Der Wert externer Eingaben bestimmt direkt die Ausführung des abzudeckenden Fragments. Das Extrahieren dieser Informationen zur Eingabe des großen Modells hilft daher dabei, Testfälle gezielt zu entwerfen. Das Forschungsteam stellte in Experimenten fest, dass große Modelle eine gute Fähigkeit haben, externe Eingaben zu extrahieren, daher werden große Modelle verwendet, um diese Aufgabe in HITS zu erfüllen. Als nächstes erstellt HITS eine Gedankenkettenaufforderung, um das große Modell bei der Generierung von Testproben anzuleiten. Die Argumentationsschritte sind wie folgt. Der erste Schritt besteht darin, die externen Eingaben anzugeben und die Permutationen und Kombinationen der verschiedenen bedingten Zweige im abzudeckenden Codeteil zu analysieren. Welche Eigenschaften müssen die externen Eingaben erfüllen? Beispiel: Kombination 1, Zeichenfolge a muss enthalten Zeichen 'x', die Ganzzahlvariable i muss nicht negativ sein; in Kombination 2 muss die Zeichenfolge a nicht leer sein und die Ganzzahlvariable i muss eine Primzahl sein. Analysieren Sie im zweiten Schritt für jede Kombination im vorherigen Schritt die Art der Umgebung, in der der entsprechende zu testende Code ausgeführt wird, einschließlich, aber nicht beschränkt auf die Eigenschaften tatsächlicher Parameter und die Einstellungen globaler Variablen. Der dritte Schritt besteht darin, für jede Kombination ein Testmuster zu erstellen. Das Forschungsteam erstellte für jeden Schritt handgearbeitete Beispiele, damit das große Modell die Anweisungen richtig verstehen und ausführen konnte. Schließlich ermöglicht HITS die korrekte Ausführung von Testbeispielen, die von großen Modellen generiert wurden, durch Nachbearbeitung und Selbst-Debugging. Von großen Modellen generierte Testbeispiele sind oft schwer direkt zu verwenden, und es kommt zu verschiedenen Kompilierungsfehlern und Laufzeitfehlern, die durch falsch geschriebene Testbeispiele verursacht werden. Das Forschungsteam entwarf mehrere Regeln und Fälle zur Behebung häufiger Fehler auf der Grundlage eigener Beobachtungen und Zusammenfassungen bestehender Arbeiten. Versuchen Sie zunächst, das Problem gemäß den Regeln zu beheben. Wenn die Regel nicht repariert werden kann, verwenden Sie die Selbst-Debug-Funktion des großen Modells, um sie zu reparieren. In der Eingabeaufforderung für die Referenz des großen Modells werden Reparaturfälle für häufige Fehler angezeigt.
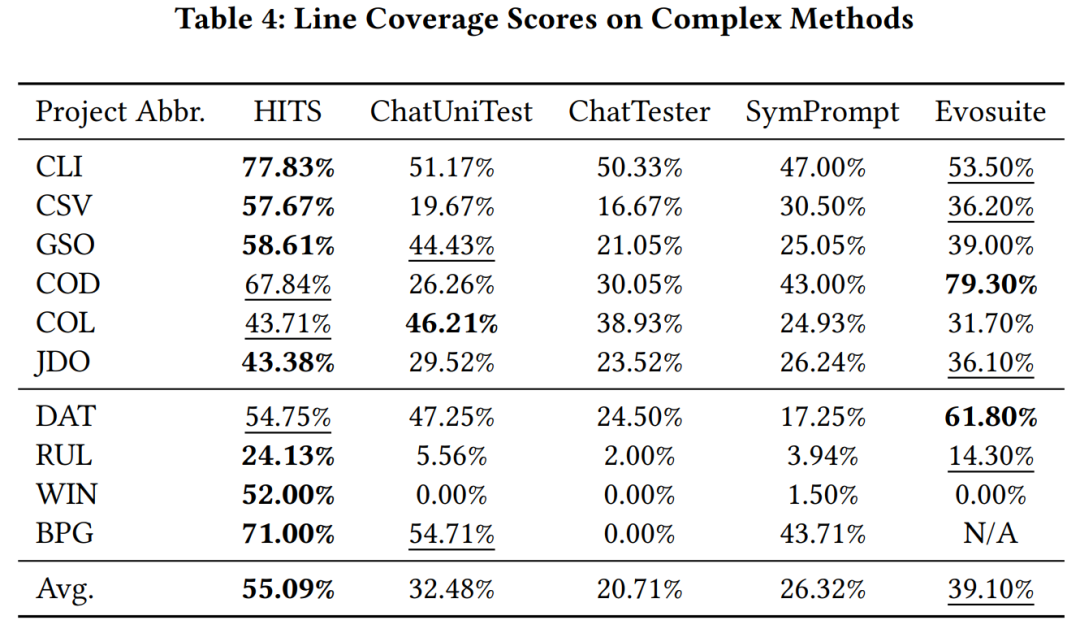
Die Gesamtdarstellung von Hits Experimentelle Verifizierung Das Forschungsteam verwendet gpt-3.5-turbo als das von HITS aufgerufene große Modell und vergleicht HITS auf komplexe Funktionen (Zyklokomplexität größer als 10) in Java-Projekten, die von großen Modellen erlernt wurden, und solche, die es gelernt haben Andere große modellbasierte Unit-Testmethoden und Codeabdeckung mit evosuite wurden nicht erlernt. Experimentelle Ergebnisse zeigen, dass HITS im Vergleich zu den verglichenen Methoden erhebliche Leistungsverbesserungen aufweist.
So analysieren Sie das Beispiel und zeigen die Slice-Methode an, um den Code zu verbessern Abdeckung. Wie im Bild gezeigt.
In diesem Fall konnte die mit der Basismethode generierte Testprobe das rote Codefragment in Slice 2 nicht vollständig abdecken. Da sich HITS jedoch auf Slice 2 konzentrierte, analysierte es die externen Variablen, auf die es verwies, erfasste die Eigenschaft „Wenn Sie das rote Codefragment abdecken möchten, muss die Variable „Argumente“ nicht leer sein“ und erstellte ein Testbeispiel Basierend auf dieser Eigenschaft wurde die Abdeckung roter Vorwahlen erfolgreich erreicht.
Verbessern Sie die Unit-Test-Abdeckung, erhöhen Sie die Systemzuverlässigkeit und -stabilität und verbessern Sie dadurch die Softwarequalität. HITS nutzt Programm-Sharding-Experimente, um zu beweisen, dass diese Technologie nicht nur die Codeabdeckung des gesamten Testbeispielsatzes erheblich verbessern kann, sondern auch über eine einfache und direkte Implementierungsmethode verfügt. Es wird erwartet, dass sie Teams in Zukunft dabei hilft, Entwicklungsfehler zu entdecken und zu korrigieren früher in der realen Szenariopraxis, wodurch die Qualität der Softwarebereitstellung verbessert wird.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Déclaration:Le contenu de cet article est volontairement contribué par les internautes et les droits d'auteur appartiennent à l'auteur original. Ce site n'assume aucune responsabilité légale correspondante. Si vous trouvez un contenu suspecté de plagiat ou de contrefaçon, veuillez contacter admin@php.cn