
Maison >Périphériques technologiques >IA >Prenant en charge 1 024 images et une précision de près de 100 %, NVIDIA « LongVILA » commence à développer de longues vidéos
Prenant en charge 1 024 images et une précision de près de 100 %, NVIDIA « LongVILA » commence à développer de longues vidéos

- 王林original
- 2024-08-21 16:35:04695parcourir
Désormais, Long Context Visual Language Model (VLM) dispose d'une nouvelle solution full-stack - LongVILA, qui intègre le système, la formation de modèles et le développement d'ensembles de données.

Adresse papier : https://arxiv.org/pdf/2408.10188 Adresse code : https://github.com/NVlabs/VILA/blob/main/LongVILA.md -
Titre de l'article : LONGVILA : MISE À L'ÉCHELLE DES MODÈLES DE LANGAGE VISUEL À LONG-CONTEXTE POUR LES VIDÉOS LONGUES
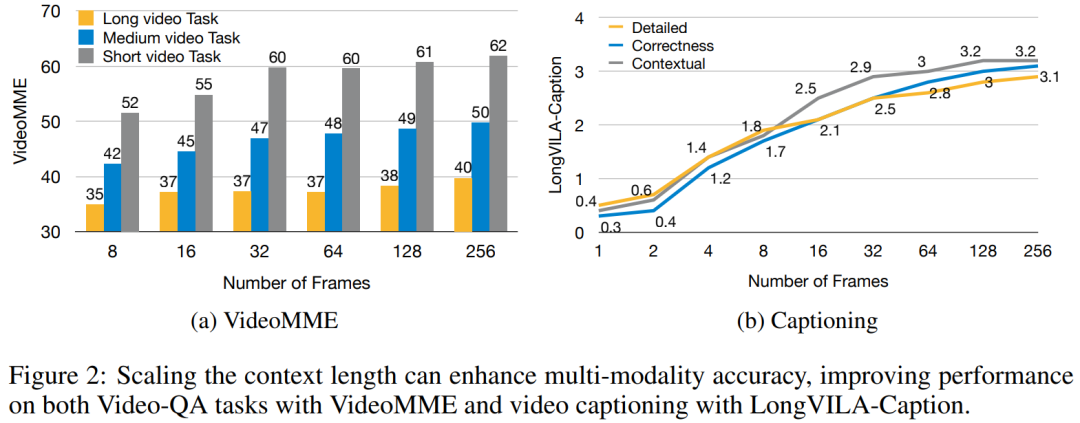

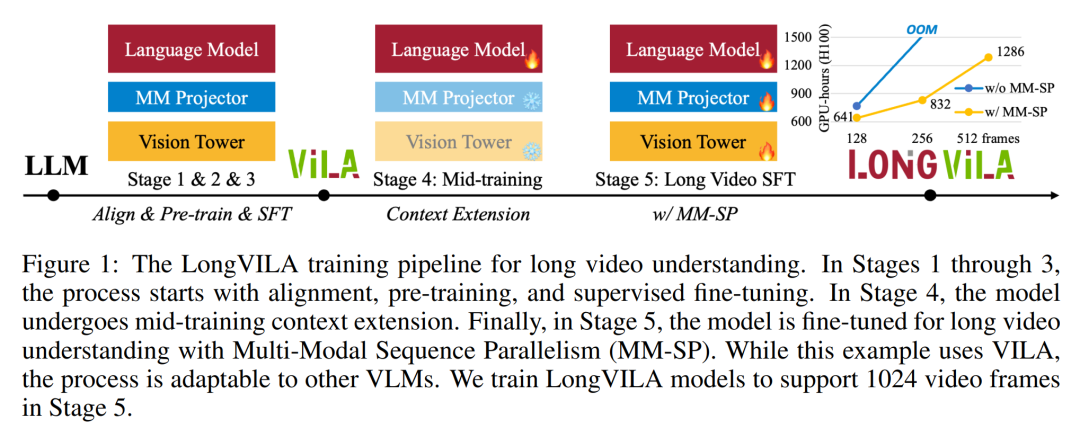
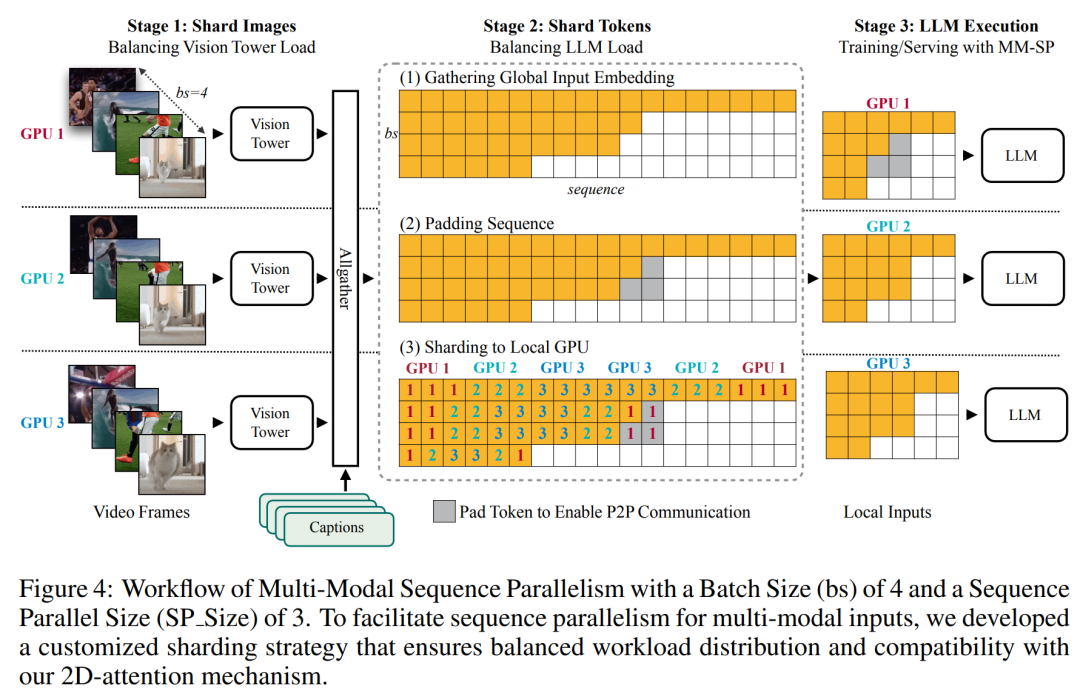

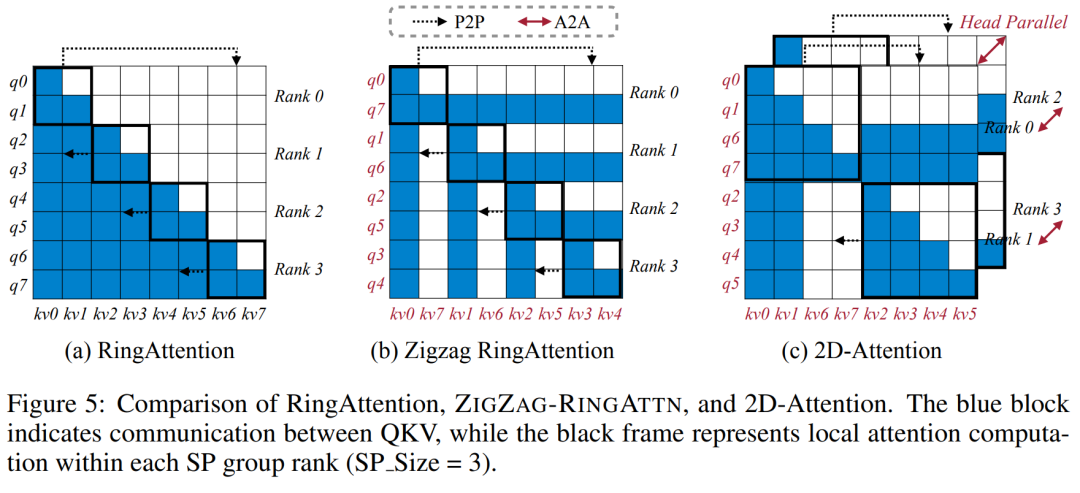
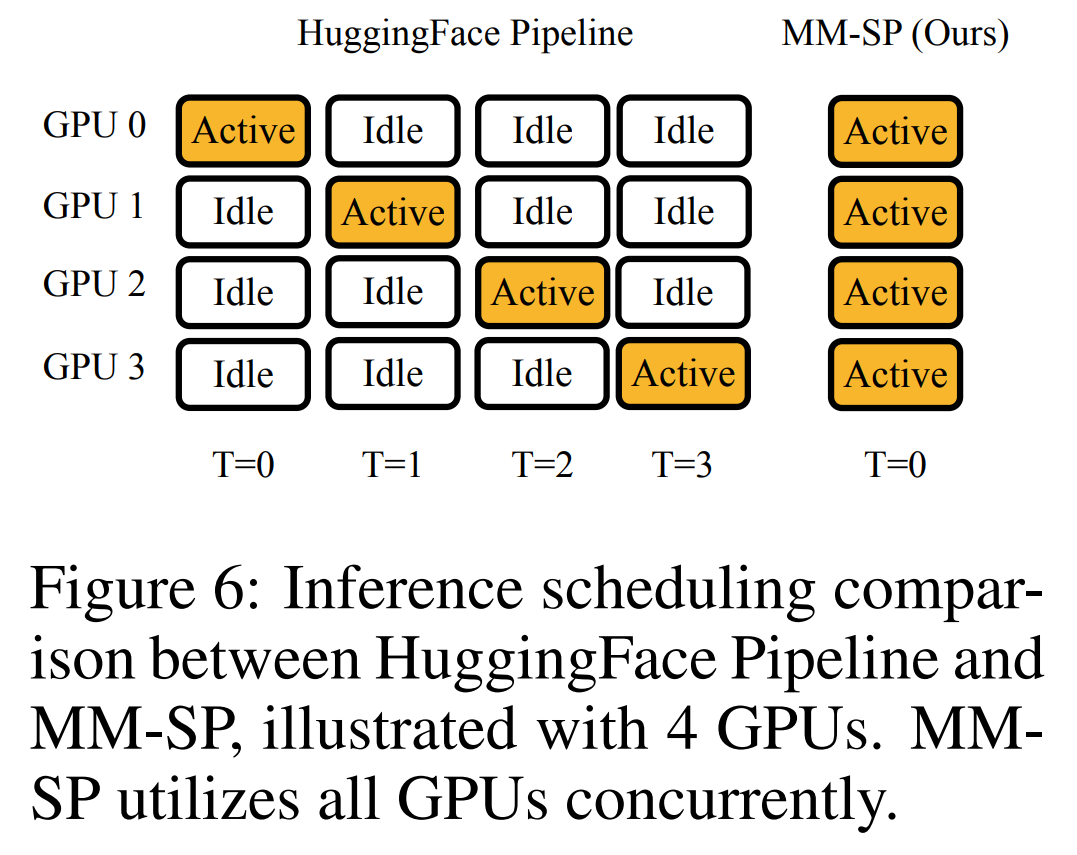
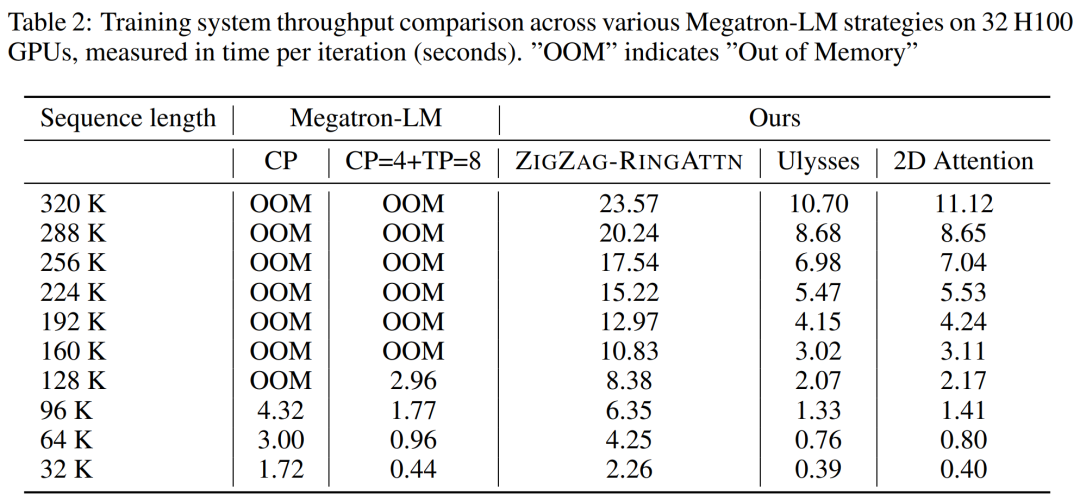
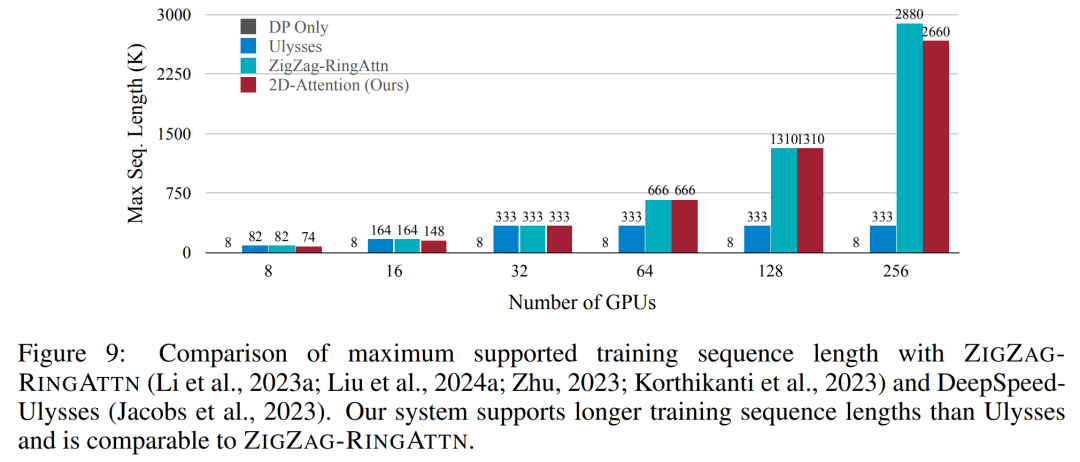

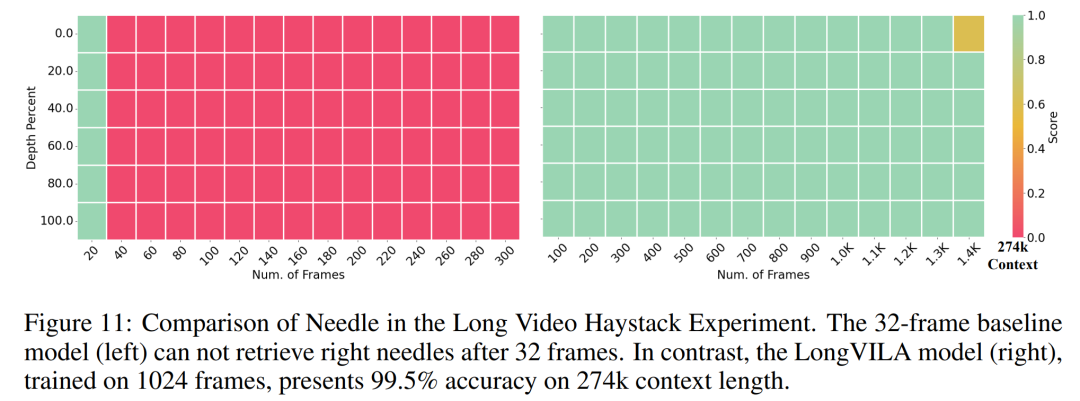
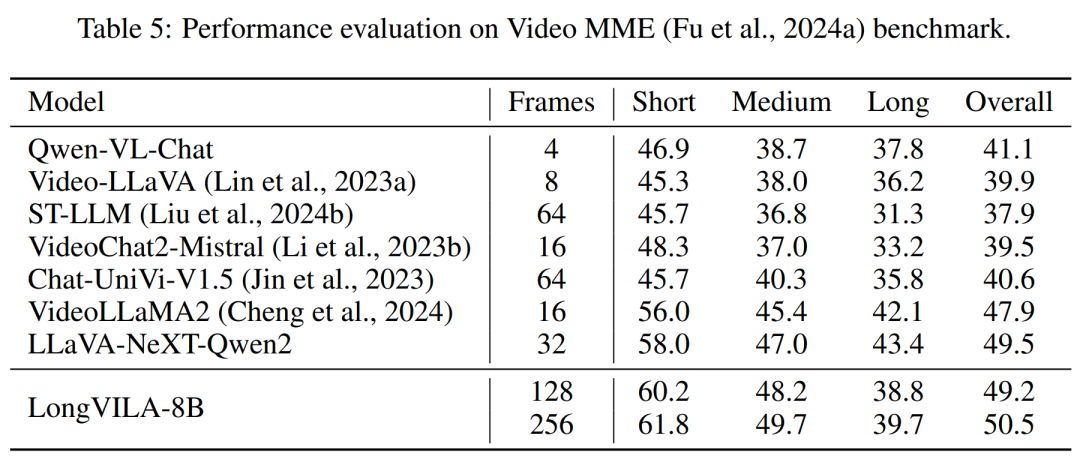
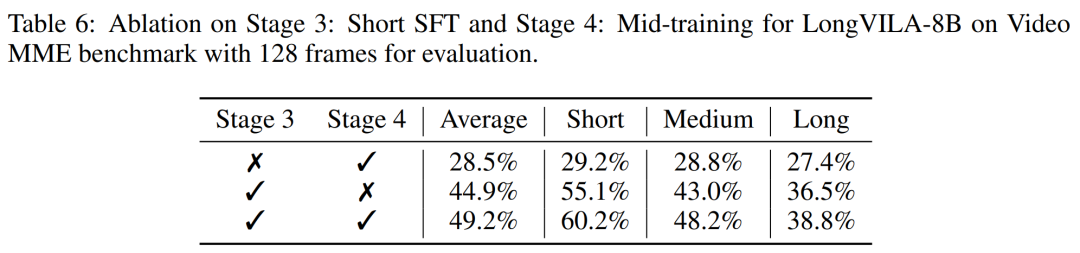
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Déclaration:
Le contenu de cet article est volontairement contribué par les internautes et les droits d'auteur appartiennent à l'auteur original. Ce site n'assume aucune responsabilité légale correspondante. Si vous trouvez un contenu suspecté de plagiat ou de contrefaçon, veuillez contacter admin@php.cn
Article précédent:Cela permet d'économiser 2 millions de dollars chaque année. Sans Elsevier, le MIT se porte plutôt bien.Article suivant:Cela permet d'économiser 2 millions de dollars chaque année. Sans Elsevier, le MIT se porte plutôt bien.
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI