Les contributeurs ont beaucoup gagné de cette conférence ACL.
L'ACL 2024, d'une durée de six jours, se tient à Bangkok, en Thaïlande. 
ACL est la plus grande conférence internationale dans le domaine de la linguistique informatique et du traitement du langage naturel. Elle est organisée par l'Association internationale pour la linguistique informatique et a lieu chaque année. L'ACL a toujours été classée première en termes d'influence académique dans le domaine de la PNL, et c'est également une conférence recommandée par le CCF-A. La conférence ACL de cette année est la 62e et a reçu plus de 400 travaux de pointe dans le domaine de la PNL. Hier après-midi, la conférence a annoncé le meilleur article et d'autres récompenses. Cette fois, 7 Best Paper Awards (deux inédits), 1 Best Theme Paper Award et 35 Outstanding Paper Awards ont été décernés. La conférence a également décerné 3 Resource Awards, 3 Social Impact Awards et 2 Time Test Awards. De plus, le Lifetime Achievement Award de cette conférence a été décerné au professeur Ralph Grishman du Département d'informatique de l'Université de New York. Ce qui suit sont les informations spécifiques sur les gagnants. "Meilleur article" owald, Christopher PottsInstitutions : Université de Stanford, Université de Californie, Irvine, Université du Texas à Austin
Lien papier : https://arxiv.org/abs/2401.06416
Introduction papier : Chomsky et al. On pense que les grands modèles de langage (LLM) ont les mêmes capacités d'apprentissage pour les langues qui peuvent ou non être apprises par les humains. Cependant, il existe peu de preuves expérimentales publiées pour étayer cette affirmation.
- L'étude a développé un ensemble de langages synthétiques de complexité variable, chacun conçu en modifiant systématiquement les données anglaises en utilisant un ordre des mots et des règles grammaticales non naturelles, dans le but de synthétiser quelque chose qu'il serait impossible pour les humains d'apprendre une langue.
- L'étude a mené des expériences d'évaluation approfondies pour évaluer la capacité du petit modèle GPT-2 à apprendre ces « langues impossibles », et a mené ces évaluations à différentes étapes tout au long de la formation pour comparer le processus d'apprentissage de chaque langue. La principale conclusion de l'étude est que GPT-2 est difficile à apprendre comme des « langues impossibles » par rapport à l'anglais, ce qui remet en question les affirmations de Chomsky et d'autres.
-
Plus important encore, l'étude espère que son approche pourra ouvrir une piste de recherche fructueuse, permettant de tester différentes architectures LLM sur divers « langages impossibles » pour comprendre comment le LLM peut être utilisé comme outil d'enquête cognitive et typologique. .
Article 2 : Pourquoi les fonctions sensibles sont-elles difficiles pour les transformateurs ?
- Auteur : Michael Hahn, Mark Rofin
- Institution : Université de la Sarre
- Lien de l'article : https://arxiv org. /abs/2402.09963
Résumé : Des études expérimentales ont identifié une série de biais d'apprentissage et de limites des transformateurs, tels que la difficulté persistante à apprendre à calculer des langages formels simples tels que PARITY, et la difficulté à apprendre Fonction de bas niveau (bas degré). Cependant, la compréhension théorique reste limitée et les théories existantes de la représentation surestiment ou sous-estiment les capacités d’apprentissage réalistes. Cette étude prouve que dans l'architecture du transformateur, le paysage de la fonction de perte (paysage des pertes) est limité par la sensibilité de l'espace d'entrée : un transformateur dont la sortie est sensible à de nombreuses parties de la chaîne d'entrée est situé à un endroit isolé. point dans l’espace des paramètres, ce qui entraîne un biais de faible sensibilité. Cette étude montre théoriquement et expérimentalement que la théorie unifie des observations expérimentales approfondies sur les capacités et les biais d'apprentissage des transformateurs, tels que leur biais de généralisation à faible sensibilité et faible degré, et la longueur de parité Difficulté de généralisation. Cela suggère que la compréhension des polarisations inductives d'un transformateur nécessite d'étudier non seulement sa puissance d'expression en principe, mais également son paysage de fonctions de perte.
Pas 3 : Déchiffrer le langage osseux d'Oracle avec des modèles de diffusion
- Auteur : Haisu Guan, Huanxin Yang, Xinyu Wang, Shengwei Han, etc.
- Institution : Université de Zhong Science et technologie, A A Adélaïde University, Anyang Normal College, South China University of Technology
- Lien papier : https://arxiv.org/pdf/2406.00684
Introduction papier : Oracle Bone Script (OBS ) originaire de la dynastie Shang de Chine, il y a environ 3 000 ans, est une pierre angulaire de l’histoire linguistique, antérieure à de nombreux systèmes d’écriture établis. Bien que des milliers d’inscriptions aient été découvertes, un grand nombre d’os d’oracle restent indéchiffrés, enveloppant cette langue ancienne d’un voile de mystère. L’émergence de la technologie moderne de l’IA a ouvert de nouveaux domaines pour le décodage des oracles, posant des défis aux méthodes traditionnelles de PNL qui s’appuient fortement sur de grands corpus de textes. Cet article présente une nouvelle méthode utilisant la technologie de génération d'images pour développer un modèle de diffusion optimisé pour le déchiffrement Oracle, Oracle Bone Script Decipher (OBSD). En utilisant la stratégie de diffusion conditionnelle, OBSD a généré des indices importants pour le déchiffrement Oracle et a ouvert une nouvelle direction pour l’analyse des langues anciennes assistée par l’IA. Afin de vérifier l'efficacité, les chercheurs ont mené des expériences approfondies sur l'ensemble de données Oracle, et les résultats quantitatifs ont prouvé l'efficacité d'OBSD.
Article 4 : Estimation causale des profils de mémorisation
- Auteur : Pietro Lesci, Clara Meister, Thomas Hofmann, Andreas Vlachos, Tiago Pimentel
- Institution : de Cambridge , ETH Zurich Academy
- Lien papier : https://arxiv.org/pdf/2406.04327
Introduction au papier : Comprendre la mémoire dans les modèles de langage a des implications pratiques et sociales, telles que l'étude de la dynamique de formation des modèles ou la prévention violation du droit d'auteur. Des recherches antérieures définissent la mémoire comme la relation causale entre « l'entraînement à l'aide d'une instance » et « la capacité du modèle à prédire cette instance ». Cette définition s'appuie sur un contrefactuel : la capacité d'observer ce qui se serait passé si le modèle n'avait pas vu l'instance. Les méthodes existantes ont du mal à fournir des estimations informatiques efficaces et précises de ces contrefactuels. De plus, ces méthodes estiment généralement la mémoire de l’architecture du modèle plutôt que la mémoire d’instances de modèle spécifiques. Cet article comble une lacune importante en proposant une nouvelle approche, fondée sur des principes et efficace, pour estimer la mémoire basée sur un modèle économétrique de différence en différence. Avec cette méthode, les chercheurs n'observent le comportement du modèle que sur un petit nombre d'instances pendant tout le processus de formation pour décrire le profil de mémoire du modèle, c'est-à-dire sa tendance de mémoire au cours du processus de formation. Dans des expériences utilisant la suite de modèles Pythia, ils ont constaté que la mémoire (i) est plus forte et plus persistante dans les modèles plus grands, (ii) est déterminée par l'ordre des données et le taux d'apprentissage, et (iii) est stable dans différentes tendances de taille de modèle. les mémoires du modèle plus grand peuvent être prédites à partir du modèle plus petit.
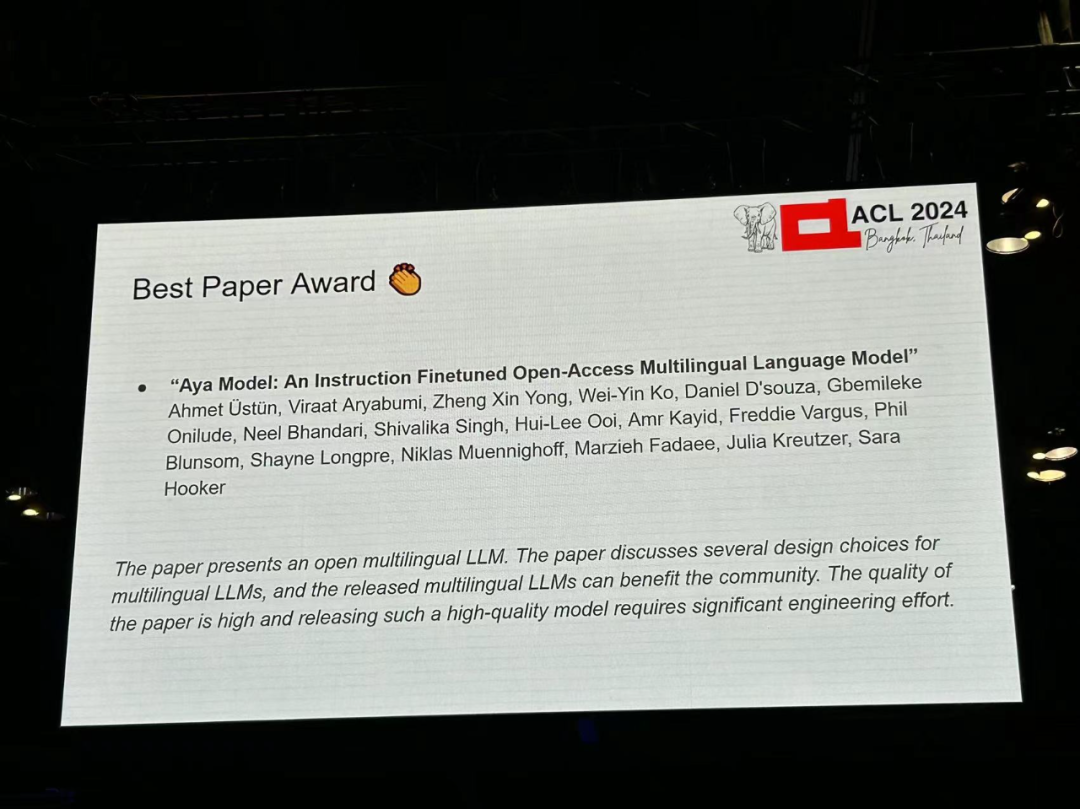
Article 5 : Modèle Aya : Un modèle de langage multilingue en libre accès affiné avec instruction
- Auteur : Ahmet Üstün, Viraat Aryabumi, Zheng Xin Yong, Wei-Yin Ko, etc.
- Institution : Cohere, Brown University et al
- Lien article : https://arxiv.org/pdf/2402.07827
Introduction à l'article : les percées récentes dans les grands modèles de langage (LLM) se concentrent sur un petit nombre de données -des langues riches. Comment étendre les possibilités de percées au-delà des autres langues ? La recherche présente Aya, un modèle de langage génératif multilingue à grande échelle qui suit les instructions pour 101 langues, dont plus de 50 % sont considérées comme à faibles ressources. Aya surpasse mT0 et BLOOMZ sur la plupart des tâches tout en couvrant deux fois plus de langues. De plus, la recherche introduit une nouvelle suite d'évaluation complète, étendant l'état de l'art en matière d'évaluation multilingue à 99 langues. Enfin, l’étude fournit une enquête détaillée sur la composition optimale du mélange, l’élagage des données et la toxicité, les biais et la sécurité du modèle.
Pas 6 : Reconstruction neuronale semi-supervisée du proto-langage
- Auteurs : Liang Lu, Peirong Xie, David R. Mortensen
-
Institution : CMU, Université de Californie du Sud
- Lien vers l'article : https://arxiv.org/pdf/2406.05930
Raison du prix : Cette recherche révolutionnaire vise à semi-automatiser la tâche de reconstruction de prototypes de langues en linguistique historique, en proposant une nouvelle méthode semi-automatique. architecture supervisée. Cette méthode surpasse les méthodes supervisées précédentes en introduisant un processus de réflexion « prototype-langage natif » dans la reconstruction « langage natif-prototype ». Cet article est un bon exemple de la façon dont les modèles informatiques modernes tels que les codeurs-décodeurs neuronaux peuvent contribuer à la linguistique.
Article 7 : Satisfiabilité du langage naturel : exploration de la distribution des problèmes et évaluation des modèles de langage basés sur des transformateurs (non publié) -
Auteurs : Tharindu Madusanka, Ian Pratt-Hartmann, Riza Batista-Navarro
Citation : Cet article décrit clairement un ensemble de données d'évaluation synthétique pour l'inférence logique. Il s’agit d’un bon complément aux grands ensembles de données d’inférence dans lesquels il n’est pas clair quelles capacités sont mesurées. Théoriquement, il y a effectivement des raisons de s’attendre à ce que certains sous-ensembles soient plus difficiles que d’autres, et ces attentes sont validées dans l’article. Au sein de chaque catégorie, les auteurs accordent une attention particulière à l’échantillonnage des cas véritablement difficiles. ACL Time Test Award récompense les articles honorifiques qui ont eu un impact à long terme sur les domaines du traitement du langage naturel et de la linguistique computationnelle, divisé en il y a 10 ans (2014) et Il y a 25 ans Les deux premiers prix (1999) étaient décernés à un maximum de deux articles par an.
Papier 1: GloVe: Globale Vektoren für die Wortdarstellung
- Autoren: Jeffrey Pennington, Richard Socher, Christopher D. Manning
- Institution: Stanford University
- Link zum Papier: https:/ / /aclanthology.org/D14-1162.pdf
Über den Artikel: Methoden zum Erlernen von Vektorraumdarstellungen von Wörtern waren erfolgreich bei der Erfassung feinkörniger semantischer und syntaktischer Regeln mithilfe der Vektorarithmetik, syntaktische Regeln jedoch immer noch bleiben undurchsichtig. Diese Studie analysiert und klärt, welche Eigenschaften das Modell haben muss, damit syntaktische Regeln in Wortvektoren erscheinen. Diese Forschung schlägt ein neues globales logarithmisch-lineares Regressionsmodell vor – GloVe, das zum Erlernen von Vektordarstellungen von Wörtern entwickelt wurde. Dieses Modell kombiniert die Vorteile der globalen Matrixfaktorisierung und der lokalen Kontextfenstermethoden. GloVe erreicht die beste Leistung von 75 % bei der Wortanalogieaufgabe und übertrifft verwandte Modelle bei der Wortähnlichkeitsaufgabe und der Erkennung benannter Entitäten. Begründung der Auszeichnung: Worteinbettungen waren zwischen 2013 und 2018 der Grundstein für Deep-Learning-Methoden zur Verarbeitung natürlicher Sprache (NLP) und üben weiterhin erheblichen Einfluss aus. Sie verbessern nicht nur die Leistung von NLP-Aufgaben, sondern haben auch erhebliche Auswirkungen auf die Computersemantik, beispielsweise auf Wortähnlichkeit und -analogie. Die beiden einflussreichsten Methoden zur Worteinbettung sind wahrscheinlich Skip-Gram/CBOW und GloVe. Im Vergleich zu Skip-Gramm wurde GloVe später vorgeschlagen. Sein relativer Vorteil liegt in seiner konzeptionellen Einfachheit, da die Vektorraumähnlichkeit direkt auf der Grundlage der Verteilungseigenschaften zwischen Wörtern optimiert wird und nicht indirekt als Satz von Parametern aus der Perspektive einer vereinfachten Sprachmodellierung.
Aufsatz 2: Maße der Verteilungsähnlichkeit
- Institution: Cornell University
- . Papierlink: https://aclanthology.org /P99-1004.pdf
Über den Artikel: Der Autor untersucht Verteilungsähnlichkeitsmaße mit dem Ziel, die Wahrscheinlichkeitsschätzungen für unsichtbare gleichzeitig auftretende Ereignisse zu verbessern. Ihr Beitrag ist dreifach: ein empirischer Vergleich einer breiten Palette von Maßen; eine Klassifizierung von Ähnlichkeitsfunktionen auf der Grundlage der darin enthaltenen Informationen und die Einführung einer neuen Funktion, die bei der Bewertung der zugrunde liegenden Agentenverteilungen überlegen ist;
Lifetime Achievement AwardDer Lifetime Achievement Award von ACL wird an Ralph Grishman verliehen. Ralph Grishman ist Professor am Fachbereich Informatik der New York University und konzentriert sich auf die Forschung im Bereich der Verarbeitung natürlicher Sprache (NLP). Er ist der Gründer des Proteus-Projekts, das bedeutende Beiträge zur Informationsextraktion (IE) geleistet und das Gebiet weiterentwickelt hat.
Er entwickelte außerdem das Java Extraction Toolkit (JET), ein weit verbreitetes Informationsextraktionstool, das mehrere Sprachanalysekomponenten wie Satzsegmentierung, Annotation benannter Entitäten, Annotation und Normalisierung zeitlicher Ausdrücke, Wortart-Tagging, Teilparsing und Koreferenz bereitstellt Analyse. Diese Komponenten können je nach Anwendungsfall zu Pipelines zusammengefasst werden, die zur interaktiven Analyse einzelner Sätze oder zur Batch-Analyse ganzer Dokumente verwendet werden können. Darüber hinaus bietet JET einfache Tools für die Annotation und Anzeige von Dokumenten und umfasst vollständige Prozesse zur Extraktion von Entitäten, Beziehungen und Ereignissen gemäß der ACE-Spezifikation (Automatic Content Extraction). Professor Grishmans Arbeit deckt mehrere Kernthemen des NLP ab und hatte tiefgreifende Auswirkungen auf die moderne Sprachverarbeitungstechnologie.35 herausragende Artikel , Gabriele Oliaro, Zhihao Zhang, Qing Li, Yong Jiang, Zhihao Jia. Institutionen: CMU, Tsinghua-Universität, Pengcheng-Labor usw Aufsatz 2: L-Eval: Einführung einer standardisierten Bewertung für Sprachmodelle mit langem KontextAutoren: Chenxin An, Shansan Gong, Ming Zhong, Xingjian Zhao, Mukai Li, Jun Zhang, Lingpeng Kong, Xipeng Qiu
-
Institutionen: Fudan University, University of Hong Kong, University of Illinois at Urbana-Champaign, Shanghai AI Lab
-
Papierlink: https://arxiv.org/abs/2307.11088
-
Papier 3: Kausalgesteuertes aktives Lernen zur Entzerrung großer Sprachmodelle
Papier-Link: https://openreview.net/forum?id=idp_1Q6F-lC
Papier 4: CausalGym: Benchmarking von Methoden der kausalen Interpretierbarkeit bei sprachlichen AufgabenAutoren: Aryaman Arora, Dan Jurafsky, Christopher PottsInstitution: Stanford University
Link zum Papier: https://arxiv.org/abs/2402.12560 🎞 Institutionen: University of Washington, University of California, Berkeley, Hong Kong University of Science and Technology, CMUPapierlink: https://arxiv.org/abs/2402.00367
Aufsatz 6: Sprachübersetzung mit Speech Foundation-Modellen und großen Sprachmodellen: Was ist da und was fehlt?Autor: Marco Gaido, Sara Papi, Matteo Negri, Luisa BentivogliOrganisation: Bruno Kessler Stiftung , Italien - : Charles Darwin University
Paper-Link: https://drive.google.com/file/d/1hvF7_WQrou6CWZydhymYFTYHnd3ZIljV/view
- Paper 8: IRCoder: Intermediate Representations Make Language Models Robust Multi lingualer Code Gen Autoren
- Autoren: Indraneil Paul, Goran Glavaš, Iryna Gurevych
- Institution: TU Darmstadt, etc.
Papierlink: https://arxiv.org/abs/2403.03894
-
Paper 9: MultiLegalPile: A 689GB Multilingual Legal CorpusAutoren: Matthias Stürmer, Veton Matoshi, etc. Institutionen: Universität Bern, Stanford University, etc. Paper-Link: https:/ /arxiv.org/ PDF/2306.02069 Yongting Zhang, Lijun Li, Hongzhi Gao, Lijun Wang, Huchuan Lu, Feng Zhao, Yu Qiao, Jing Shao
Institution: Shanghai Artificial Intelligence Laboratory, Dalian University of Technology, University of Science and Technology of China
-
Link zum Papier: https://arxiv.org/pdf/2401.11880 Sunghwan Kim usw Spinning Arrow? Auf dem Weg zu aussagekräftigeren Bewertungen für Werte und Meinungen in großen Sprachmodellen
-
Autoren: Paul Röttger, Valentin Hofmann usw.
-
Institutionen: Bocconi University, Allen Institute for Artificial Intelligence usw.
- Link zum Papier: https://arxiv.org/pdf/ 2402.16786
- Aufsatz 13: Gleiche Aufgabe, mehr Token: Der Einfluss der Eingabelänge auf die Argumentationsleistung großer Sprachmodelle
- Autor: Mosh Levy, Alon Jacoby, Yoav Goldberg
- Institution: Pakistan Elan University, Allen Institute for Artificial Intelligence
- Paper-Link: https://arxiv.org/pdf/2402.14848
- Paper 14: Funktionieren Lamas auf Englisch? Über die latente Sprache der Mehrsprachigkeit Transformers
- Autoren: Chris Wendler, Veniamin Veselovsky usw.
-
- Aufsatz 15: Getting Serious about Humor: Crafting Humor Datasets with Unfunny Large Language Models
Autoren: Zachary Horvitz, Jingru Chen usw. Institution: Columbia University, EPFL Papierlink: https://arxiv.org/pdf/2403.00794
- Papier 16: Schätzung des Niveaus von. Dia Lektüre Prognostiziert die Übereinstimmung zwischen Annotatoren in arabischen Datensätzen mit mehreren Dialekten
Autor: Amr Keleg, Walid Magdy, Sharon GoldwaterInstitution: University of EdinburghLink zum Papier: https://arxiv.org/pdf /2405.11282
- paper 17: G-DLG: In Richtung Gradientenbasis Dlverse- und hochwertiger Anweisungsdatenauswahl für maschinelle Übersetzungen , Yu Lu, Shanbo Cheng
Institution: ByteDance ResearchPapierlink: https: https://arxiv.org/pdf/2405.12915 -
Papierlink: https://openreview.net/pdf? id=9AV_zM56pwj Yin
Aufsatz 20: Gier ist alles, was Sie brauchen: Eine Bewertung der Tokenizer-InferenzmethodenInstitution: Ben Guri, Negev Ann University, MIT
Autoren: Omri Uzan, Craig W. Schmidt, Chris Tanner, Yuval Pinter Nicht
-
institution: Universität von Notre Dame (USA)
-
Author: Chihiro Taquchi, David Chiang
-
paper Link: https://arxiv.org/abs/2406.09202
-
Paper 22: Steering Llama 2 via Contrastive Activation Addition
-
Institutionen: Anthropic, Harvard University, Universität Göttingen (Deutschland), Center for Human-Compatible AI
Autoren: Nina Rimsky, Nick Gabrieli, Julian Schulz, Meg Tong, Evan J Hubinger, Alexander Matt Turner Agenten zur Simulation makroökonomischer Aktivitäten
- Institution: Tsinghua University – Shenzhen International Graduate School, Tsinghua University
- Autoren: Nian Li, Chen Gao, Mingyu Li, Yong Li, Qingmin Liao
- Link zum Papier: https: //arxiv.org/abs/2310.10436
Papier 24: M4LE: Ein Multi-Ability Multi-Range Multi-Task Multi-Domain Long-Context Evaluation Benchmark für große Sprachmodelle
- Institutionen : Chinesische Universität Hongkong, Huawei Noah's Ark Laboratory, Hong Kong University of Science and Technology
- Autoren: Wai-Chung Kwan, Xingshan Zeng, Yufei Wang, Yusen Sun, Liangyou Li, Lifeng Shang, Qun Liu, Kam- Fai Wong
- Papierlink: https://arxiv.org/abs/2310.19240
Papier 25: CHECKWHY: Kausalfaktenüberprüfung durch Argumentstruktur
- Autor: Jias Heng Si, Yibo Zhao, Yingjie Zhu, Haiyang Zhu, Wenpeng Lu, Deyu Zhou
Zu Papier 26: Über EFFIZIENT und Statistik. U darmstadt, Apple Inc für große Sprachmodelle kann nach hinten losgehen!
Autor: Zhanhui Zhou, Jie Liu, Zhichen Dong, Jiaheng Liu, Chao Yang, Wanli Ouyang, Yu Qiao
-
Institution: Shanghai Artificial Intelligence Laboratory
-
Link zum Papier: https://arxiv.org/PDF/2402.12343 Khan, Priyam Mehta, Ananth Sankar usw.
-
Institutionen: Nilekani Center bei AI4Bharat, Indian Institute of Technology (Madras), Microsoft usw.
-
Link zum Papier: https://arxiv.org/pdf/ 2403.06350
Institutionen: Universität Turin, Aqua-Tech, Amazon Development Center (Italien) usw. Papierlink: https://assets.amazon.science/08/83/9b686f424c89b08e8fa0a6e1d020/multipico-multilingual-perspectivist-irony-corpus.pdf-
- Aufsatz 30: MMToM-QA: Multimodale Theorie der Beantwortung von Geistesfragen
- Autoren: Chuanyang Jin, Yutong Wu, Jing Cao, jiannan Xiang usw.
Institutionen: New York University, Harvard University, MIT, University of California, San Diego, University of Virginia, Johns Hopkins UniversityLink zum Papier: https://arxiv.org/pdf/2401.08743
- Papier 31: MAP nicht Noch tot: Aufdeckung wahrer Sprachmodellmodi durch Wegkonditionierung der Degeneration
- Autor: Davis Yoshida, Kartik Goyal, Kevin Gimpel
Institution: Toyota Institute of Technology Chicago, Georgia Institute of TechnologyLink zum Papier: https https://arxiv.org/pdf/2311.08817
- Aufsatz 33: Die Erde ist flach, weil... der Glaube von LLMs an Fehlinformationen durch überzeugende Gespräche untersucht wird
- Autoren: Rongwu Xu, Brian S. Lin, Shujian Yang, Tiangi Zhang usw.
Institutionen: Tsinghua University, Shanghai Jiao Tong University, Stanford University, Nanyang Technological UniversityPapierlink: https://arxiv.org/pdf/2312.09085
- Papier.3 4: Let's Go Real Talk: Gesprochenes Dialogmodell für persönliche Gespräche
- Autor: Se Jin Park, Chae Won Kim, Hyeongseop Rha, Minsu Kim usw.
Institution: Korea Advanced Institute of Science and Technology (KAIST) Papierlink: https://arxiv.org/pdf/2406.07867
- Papier 35: Worteinbettungen sind Steuerelemente für Sprachmodelle
- Autoren: Chi Han, Ji Aliang Xu, Manling Li, Yi Fung, Chenkai Sun, Nan Jiang, Tarek F. Abdelzaher, Heng Ji
Institution: University of Illinois at Urbana – Champaign Link zum Papier: https://arxiv.org/pdf /2305.12798
Best Theme Paper Award
Artikel: OLMo: Accelerating the Science of Language Models
- Autoren: Dirk Groeneveld, Iz Beltagy usw.
- Institution: Allen Institute for Artificial Intelligence, University of Washington usw.
- Link zum Papier: https://arxiv.org/pdf/2402.00838
Zitat: Diese Arbeit ist ein wichtiger Schritt in Richtung Transparenz und Reproduzierbarkeit beim Training großer Sprachmodelle, etwas, das die Community erreicht. Für den Fortschritt dringend erforderlich (oder zumindest für andere Forscher, die keine Branchenriesen sind). 3 Arbeiten haben den Resource Paper Award gewonnen. ??? Perez, Itziar Aldabe, German Rigau, Eneko Agirre, Aitor Ormazabal, Mikel Artetxe, Aitor SoroaLink: https://arxiv.org/pdf/2403.20266Fall für die Auszeichnung: Das Papier beschreibt Die Korpussammlung im Detail, Details zur Datensatzauswertung. Obwohl diese Methodik für die baskische Sprachforschung relevant ist, kann sie auf die Konstruktion großer Modelle für andere ressourcenarme Sprachen ausgeweitet werden. ?? Autor: Luca Soldaini, Rodney Kinney usw. Link: https://arxiv.org/abs/2402.00159
-
Grund für die Auszeichnung: Dieses Papier zeigt die Bedeutung des Datenmanagements bei der Vorbereitung Datensätze zum Training großer Sprachmodelle. Dies liefert sehr wertvolle Erkenntnisse für ein breites Spektrum von Menschen innerhalb der Community.
Paper 3: AppWorld: Eine kontrollierbare Welt von Apps und Menschen zum Benchmarking interaktiver CodierungsagentenInstitutionen: State University of New York in Stony Brook, Allen Institute for Artificial Intelligence usw. Autoren: Harsh Trivedi, Tushar Khot usw.Link: https://arxiv.org/abs/2407.18901
-
Grund für die Auszeichnung: Diese Forschung ist sehr wichtig und erstaunlich beim Aufbau interaktiver Umgebungssimulations- und Bewertungsarbeiten. Es wird alle dazu ermutigen, anspruchsvollere dynamische Benchmarks für die Community zu erstellen.
3 Beiträge haben den Social Impact Award gewonnen. Aufsatz 1: Wie Johnny LLMs davon überzeugen kann, sie zu jailbreaken: Überzeugungsarbeit überdenken, um die KI-Sicherheit durch Humanisierung von LLMs herauszufordern
Autoren: Yi Zeng, Hongpeng Lin, Jingwen Zhang, Diyi Yang usw .-
Institutionen: Virginia Tech, Renmin University of China, University of California, Davis, Stanford University
Papierlink: https://arxiv.org/pdf/2401.06373Grund für Auszeichnung: Dieser Artikel befasst sich mit dem Thema KI-Sicherheit – Jailbreaking und untersucht eine Methode, die im Bereich der sozialwissenschaftlichen Forschung entwickelt wurde. Die Forschung ist sehr interessant und hat das Potenzial, erhebliche Auswirkungen auf die Gemeinschaft zu haben. Aufsatz 2: DIALECTBENCH: Ein NLP-Benchmark für Dialekte, Varietäten und eng verwandte SprachenAutor: Fahim Faisal, Orevaoghene Ahia, Aarohi Srivastava, Kabir Ahuja usw. Institutionen: George Mason University, University of Washington, University of Notre Dame, RC Athena ist ein wichtiger Bereich in NLP und künstlicher Intelligenz. Ein wenig erforschtes Phänomen. Aus sprachlicher und gesellschaftlicher Sicht ist seine Forschung jedoch von äußerst hohem Wert und hat wichtige Implikationen für die Anwendung. Dieses Papier schlägt einen sehr neuartigen Maßstab zur Untersuchung dieses Problems in der LLM-Ära vor.
- Aufsatz 3: Nach dem Gebet ein Bier trinken? Kulturelle Voreingenommenheit in großen Sprachmodellen messen
Autor: Tarek Naous, Michael J. Ryan, Alan Ritter, Wei Xu
Institution: Georgia Institute of Technology Link zum Papier: https://arxiv.org/pdf/2305.14456Grund für die Auszeichnung: Dieser Artikel verdeutlicht ein wichtiges Thema in der LLM-Ära: kulturelle Voreingenommenheit.Dieser Artikel untersucht die arabische Kultur und den arabischen Raum und zeigt, dass wir bei der Gestaltung von LLMs kulturelle Unterschiede berücksichtigen müssen. Daher kann dieselbe Studie in anderen Kulturen wiederholt werden, um zu verallgemeinern und zu beurteilen, ob auch andere Kulturen von diesem Problem betroffen sind.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Déclaration:Le contenu de cet article est volontairement contribué par les internautes et les droits d'auteur appartiennent à l'auteur original. Ce site n'assume aucune responsabilité légale correspondante. Si vous trouvez un contenu suspecté de plagiat ou de contrefaçon, veuillez contacter admin@php.cn