
Maison >Périphériques technologiques >IA >L'équipe ECCV2024 | Harvard développe FairDomain pour parvenir à l'équité dans la segmentation et la classification des images médicales inter-domaines
L'équipe ECCV2024 | Harvard développe FairDomain pour parvenir à l'équité dans la segmentation et la classification des images médicales inter-domaines

- WBOYoriginal
- 2024-08-05 20:04:361274parcourir

Éditeur | ScienceAI
Dans le domaine de l'intelligence artificielle (IA), en particulier de l'IA médicale, il est crucial de résoudre les problèmes d'équité pour garantir des résultats médicaux équitables.
Récemment, les efforts visant à renforcer l'équité ont introduit de nouvelles méthodes et de nouveaux ensembles de données. Cependant, la question de l’équité a été peu explorée dans le contexte du transfert de domaine, même si les cliniques s’appuient souvent sur différentes technologies d’imagerie (par exemple, différentes modalités d’imagerie rétinienne) pour le diagnostic des patients.
Cet article propose FairDomain, qui est la première étude systématique de l'équité des algorithmes sous transfert de domaine. Nous testons les algorithmes de pointe d'adaptation de domaine (DA) et de généralisation de domaine (DG) pour la segmentation et la classification d'images médicales. tâches. , conçues pour comprendre comment les préjugés sont transférés entre différents domaines.
Nous proposons également un nouveau module plug-and-play Fair Identity Attention (FIA) pour améliorer l'équité de divers algorithmes DA et DG en utilisant un mécanisme d'auto-attention pour ajuster l'importance des caractéristiques en fonction du sexe des attributs démographiques.
De plus, nous avons compilé et rendu public le premier ensemble de données de changement de domaine axé sur l'équité, qui contient des tâches de segmentation médicale et de classification de deux modalités d'imagerie appariées de la même population de patients pour évaluer rigoureusement les scénarios de changement de domaine. L'exclusion des effets confusionnels des différences de répartition de la population entre les domaines source et cible permettra une quantification plus claire des performances du modèle de transfert de domaine.
Notre évaluation approfondie montre que la FIA proposée améliore considérablement l'équité et les performances du modèle sous différentes caractéristiques démographiques dans toutes les tâches de transfert de domaine (c'est-à-dire DA et DG), surpassant les méthodes de pointe dans les tâches de segmentation et de classification. est loin.
Partagez ici le travail de la version finale de l'ECCV 2024 "FairDomain : Atteindre l'équité dans la segmentation et la classification des images médicales inter-domaines"

Adresse de l'article : https://arxiv.org/abs/2407.08813
Adresse du code : https://github.com/Harvard-Ophthalmology-AI-Lab/FairDomain
Site Web de l'ensemble de données : https://ophai.hms.harvard.edu/datasets/harvard-fairdomain20k
Lien de téléchargement de l'ensemble de données : https://drive.google.com/drive/folders/1huH93JVeXMj9rK6p1OZRub868vv0UK0O?usp=sharing
Harvard-Ophthalmology-AI-Lab s'engage à fournir des ensembles de données d'équité de haute qualité et davantage d'ensembles de données d'équité. cliquez sur la page d'accueil de l'ensemble de données du laboratoire : https://ophai.hms.harvard.edu/datasets/
Background
Ces dernières années, les progrès de l'apprentissage profond dans le domaine de l'imagerie médicale ont grandement amélioré la classification et tâches de segmentation Effet. Ces technologies contribuent à améliorer la précision du diagnostic, à simplifier la planification du traitement et, à terme, à améliorer la santé des patients. Cependant, un défi important lors du déploiement de modèles d'apprentissage profond dans différents contextes médicaux réside dans les préjugés et la discrimination inhérents à l'algorithme à l'égard de groupes démographiques spécifiques, ce qui peut nuire à l'équité du diagnostic et du traitement médicaux.
Certaines recherches récentes ont commencé à résoudre le problème du biais des algorithmes dans l'imagerie médicale et ont développé des méthodes pour améliorer l'équité des modèles d'apprentissage profond. Cependant, ces méthodes supposent généralement que la distribution des données reste inchangée pendant les phases de formation et de test, ce qui n'est souvent pas vrai dans les scénarios médicaux réels.
Par exemple, différentes cliniques de soins primaires et hôpitaux spécialisés peuvent s'appuyer sur différentes technologies d'imagerie (par exemple, différentes modalités d'imagerie rétinienne) pour le diagnostic, ce qui entraîne des changements de domaine importants, qui à leur tour affectent les performances et l'équité du modèle.
Par conséquent, lors du déploiement réel, le transfert de domaine doit être pris en compte et des modèles capables de maintenir l'équité dans des scénarios inter-domaines doivent être appris.
Bien que l'adaptation de domaine et la généralisation de domaine aient été largement explorées dans la littérature, ces études se sont principalement concentrées sur l'amélioration de la précision des modèles, ignorant l'importance de garantir que les modèles fournissent des prédictions équitables pour différents groupes de population. Dans le domaine médical en particulier, les modèles de prise de décision affectent directement la santé et la sécurité des personnes. L’étude de l’équité entre domaines revêt donc une grande importance.
Cependant, seules quelques études ont commencé à explorer la question de l'équité entre domaines, et ces études manquent d'investigations systématiques et complètes, se concentrant généralement uniquement sur l'adaptation ou la généralisation du domaine, mais rarement sur les deux. De plus, les recherches existantes résolvent principalement les problèmes de classification médicale, tout en ignorant la tâche tout aussi importante de segmentation médicale dans le cadre du transfert de domaine.
Pour résoudre ces problèmes, nous présentons FairDomain, qui est la première étude dans le domaine de l'imagerie médicale à explorer systématiquement l'équité des algorithmes sous transfert de domaine.
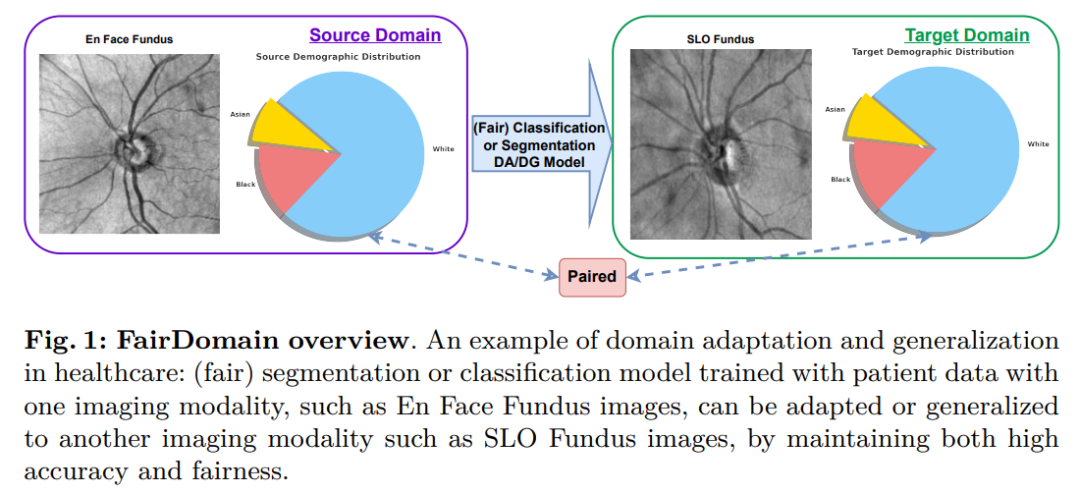
Nous menons des expériences approfondies avec plusieurs algorithmes d'adaptation et de généralisation de domaines de pointe pour évaluer leur exactitude et leur équité sous différents attributs démographiques et comprendre comment l'équité se transfère entre différents domaines.
Nos observations révèlent que les différences de performances de groupe entre les domaines source et cible sont considérablement exacerbées dans différentes tâches de classification et de segmentation médicale. Cela démontre la nécessité de concevoir des algorithmes axés sur l’équité pour résoudre efficacement ce problème urgent.

Pour compenser les lacunes des efforts existants d'atténuation des biais, nous introduisons un nouveau mécanisme polyvalent Fair Identity Attention (FIA) conçu pour être intégré de manière transparente dans diverses stratégies d'adaptation et de généralisation de domaine, l'importance des fonctionnalités est coordonnée avec l'auto-attention dérivée des attributs démographiques (par exemple, le groupe racial) pour promouvoir l’équité.
Un défi clé dans le développement du benchmark FairDomain est l’absence d’un ensemble de données d’imagerie médicale qui reflète véritablement les changements de domaine dans les domaines médicaux réels, qui sont souvent causés par différentes technologies d’imagerie.
Dans les ensembles de données médicales existantes, les différences démographiques des patients entre les domaines source et cible introduisent des confusions, ce qui rend difficile de distinguer si les biais algorithmiques observés sont dus à des changements de répartition démographique ou à des changements de domaine inhérents.
Pour résoudre ce problème, nous avons organisé un ensemble de données unique composé d'images appariées du fond d'œil rétinien de la même cohorte de patients, en utilisant deux modalités d'imagerie différentes (images du fond d'œil En face et SLO), spécifiquement pour analyser les biais algorithmiques des scénarios de transfert de domaine.
Résumé de nos contributions :
2. Une technologie d'attention à l'identité équitable est introduite pour améliorer la précision et l'équité dans l'adaptation et la généralisation du domaine.
3. Création d'un ensemble de données de segmentation et de classification médicales à grande échelle pour la recherche sur l'équité, étudiant spécifiquement les problèmes d'équité dans le cadre du transfert de domaine.
Collecte de données et contrôle qualité
Les sujets ont été sélectionnés dans un grand hôpital ophtalmologique universitaire de la Harvard Medical School entre 2010 et 2021. Deux tâches interdomaines sont explorées dans cette étude, à savoir les tâches de segmentation médicale et de classification médicale. Pour la tâche de segmentation médicale, les données comprennent les cinq types suivants :
2. Analyse d'image du fond d'œil SLO ;
Informations démographiques du patient ;5. Annotation du masque de tasse et d'assiette.
Plus précisément, l'annotation pixel de la zone cupule-disque est d'abord acquise via le dispositif OCT, et le logiciel du fabricant OCT segmente le bord du disque en OCT 3D dans les ouvertures de la membrane de Bruch et détecte le bord de la cupule comme membrane limitante interne (ILM ) coupant le plan Le point d'intersection de la surface minimale.
En raison du contraste élevé des ouvertures de membrane de Bruch et des membranes limitantes internes avec l’arrière-plan, ces limites peuvent être facilement segmentées. Étant donné que le logiciel du fabricant d’OCT utilise des informations 3D, la segmentation cupule-disque est généralement fiable.
Compte tenu de la disponibilité limitée et du coût élevé de l'équipement OCT en soins primaires, nous proposons une méthode pour transférer les annotations OCT 3D vers des images de fond d'œil SLO 2D pour améliorer l'efficacité du dépistage précoce du glaucome.
Nous utilisons l'outil NiftyReg pour aligner avec précision les images du fond d'œil SLO avec les annotations de pixels dérivées de l'OCT, générant ainsi un grand nombre d'annotations de masque de fond d'œil SLO de haute qualité.
Ce processus a été validé par une équipe d'experts médicaux avec un taux de réussite d'enregistrement de 80 %, rationalisant le processus d'annotation pour une utilisation plus large dans les établissements de soins primaires. Nous exploitons ces annotations alignées et inspectées manuellement, combinées aux images de fond SLO et En face, pour étudier l'équité algorithmique des modèles de segmentation sous changement de domaine.
Pour la tâche de classification médicale, les données comprennent les quatre types suivants :
1. Analyse d'image du fond d'œil en face ;
2. Analyse d'image du fond d'œil SLO ;
Les sujets de l'ensemble de données de classification médicale sont divisés en deux catégories : normaux et glaucomes sur la base des résultats des tests du champ visuel.
Caractéristiques des donnéesL'ensemble de données de segmentation médicale contient 10 000 échantillons provenant de 10 000 sujets. Nous divisons les données en un ensemble d'apprentissage de 8 000 échantillons et un ensemble de test de 2 000 échantillons. L'âge moyen des patients était de 60,3 ± 16,5 ans.
L'ensemble de données contient six attributs démographiques, notamment l'âge, le sexe, la race, l'origine ethnique, la langue préférée et l'état civil. La répartition démographique est la suivante : Sexe : 58,5 % de femmes, 41,5 % d'hommes
Race : 9,2 % d'Asiatiques, 14,7 % de noirs, 76,1 % de blancs
Ethnie : 90,6 % de non-hispaniques, les Hispaniques représentaient 3,7 % ; , inconnu représentait 5,7 % ;
État matrimonial : marié ou en couple 57,7 ; %, célibataires 27,1%, divorcés 6,8%, séparés légalement 0,8%, veufs 5,2%, inconnus 2,4%.
De même, l'ensemble de données de classification médicale contient 10 000 échantillons de 10 000 sujets avec un âge moyen de 60,9 ± 16,1 ans. Nous divisons les données en un ensemble d'apprentissage de 8 000 échantillons et un ensemble de test de 2 000 échantillons. La répartition démographique est la suivante :
Sexe : 72,5 % de femmes, 27,5 % d'hommes
Race : 8,7 % d'Asiatiques, 14,5 % de noirs, 76,8 % de blancs
Ethnie : 96,0 % de non-hispaniques, les Hispaniques représentent 4,0 % ; ;
Langue préférée : 92,6 % anglais, 1,7 % espagnol, 3,6 % autres langues, 2,1% inconnu ;
État civil : 58,5 % mariés ou en couple, 26,1 % célibataires, 6,9 % divorcés, la séparation légale représentait 0,8 %, les veufs représentaient 1,9 % et les inconnus représentaient 5,8 %.
Ces informations démographiques détaillées fournissent une base de données riche pour des recherches approfondies sur l'équité dans les tâches inter-domaines.
Méthodes utilisées pour améliorer l'équité des modèles d'IA inter-domaines Fair Identity Attention (FIA)

Définition du problème
Adaptation de domaine (DA) et généralisation de domaine (DG) C'est une technique clé dans le développement de modèles d'apprentissage automatique et est conçu pour faire face à la variabilité qui peut survenir lorsqu'un modèle est appliqué d'un domaine spécifique à un autre.
Dans le domaine de l'imagerie médicale, les techniques DA et DG sont essentielles pour créer des modèles capables de gérer de manière robuste la variabilité entre les différentes institutions médicales, appareils d'imagerie et populations de patients. Cet article vise à explorer la dynamique de l'équité dans le contexte du transfert de domaine et à développer des méthodes pour garantir que les modèles restent équitables et fiables lors de l'adaptation ou de la généralisation à de nouveaux domaines.
Nous visons à développer une fonction de méthode f qui atténue la dégradation courante de l'équité lorsqu'un modèle est transféré du domaine source au domaine cible. De telles exacerbations sont principalement dues à la possibilité que des changements de domaine amplifient les biais existants dans l'ensemble de données, en particulier ceux liés aux attributs démographiques tels que le sexe, la race ou l'origine ethnique.
Pour résoudre ce problème, nous proposons une approche basée sur un mécanisme d'attention qui vise à identifier et exploiter les caractéristiques de l'image pertinentes pour les tâches en aval telles que la segmentation et la classification tout en prenant en compte les attributs démographiques.
La figure 3 montre l'architecture du module d'attention à l'identité équitable proposé. Ce module obtient d'abord l'image d'entrée intégrant E_i et l'incorporation d'attribut E_a en traitant l'image d'entrée et les étiquettes d'attribut statistique d'entrée. Ces plongements sont ensuite ajoutés à la position plongeant E_p. La formule de calcul détaillée est la suivante :
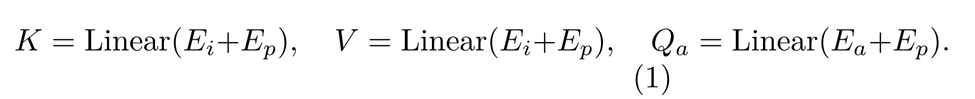
En calculant le produit scalaire de la requête et de la clé, nous extrayons la matrice de similarité liée à l'attribut de fonctionnalité actuel. Le produit scalaire de cette matrice et de cette valeur est ensuite utilisé pour extraire les fonctionnalités importantes dans les tâches en aval pour chaque attribut de fonctionnalité. Ce processus est représenté par la formule suivante :

où D est un facteur d'échelle pour éviter des valeurs trop grandes dans la fonction softmax.
Par la suite, une connexion résiduelle ajoute E_i à la sortie d'attention pour maintenir l'intégrité des informations d'entrée. Enfin, une couche de normalisation et une couche de perceptron multicouche (MLP) extraient davantage les caractéristiques. Après une autre opération résiduelle sur les sorties de ces deux couches, nous obtenons la sortie finale du module fair attention.
Le mécanisme d'attention à l'identité équitable est un outil puissant et polyvalent conçu pour améliorer les performances du modèle tout en résolvant les problèmes d'équité. En tenant explicitement compte des attributs démographiques tels que le sexe, la race ou l’origine ethnique, cela garantit que les représentations apprises n’amplifient pas par inadvertance les biais présents dans les données.
Son architecture lui permet de s'intégrer de manière transparente dans n'importe quel réseau existant en tant que composant plug-in. Cette nature modulaire permet aux chercheurs et aux praticiens d'intégrer une attention identitaire équitable dans leurs modèles sans nécessiter de modifications importantes de l'architecture sous-jacente.
Par conséquent, le module d'attention équitable à l'identité contribue non seulement à améliorer la précision et l'équité du modèle dans les tâches de segmentation et de classification, mais favorise également la mise en œuvre d'une IA digne de confiance en favorisant un traitement équitable des différents groupes dans l'ensemble de données.
Expériences
Équité algorithmique dans le transfert de domaine
Dans nos expériences, nous analysons d'abord l'équité dans le contexte du transfert de domaine, en nous concentrant spécifiquement sur la tâche de segmentation des gobelets et des plaques. La segmentation cupule-disque fait référence au processus de délinéation précise de la cupule optique et du disque dans les images du fond d'œil, ce qui est essentiel pour calculer le rapport cupule-disque (CDR), un paramètre clé dans l'évaluation de la progression et du risque de glaucome.
Cette tâche est particulièrement importante dans le domaine de l’imagerie médicale, notamment lors du diagnostic et de la prise en charge des maladies oculaires comme le glaucome. Étant donné que la cupule optique est une sous-région importante du disque optique, nous recadrons la tâche de segmentation en segmentation de la cupule et du bord (la région tissulaire entre la cupule optique et le bord du disque optique) pour éviter les erreurs dues au chevauchement important entre la cupule optique et le disque optique. disque optique, entraînant une distorsion des performances.
Nous avons étudié les performances en matière d'équité sur trois données démographiques différentes (sexe, race et origine ethnique) dans deux domaines différents : les images du fond d'œil de face acquises à partir de la tomographie par cohérence optique (OCT) et l'image du fond d'œil par balayage laser (SLO).
Dans les expériences ultérieures, nous avons sélectionné l'image du fond d'œil En face comme domaine source et l'image du fond d'œil SLO comme domaine cible. La raison en est que, comparées aux images du fond d'œil SLO, les images du fond d'œil en face sont plus courantes dans les établissements de soins oculaires spécialisés et la disponibilité des données est donc nettement plus élevée.
Oleh itu, kami memilih untuk menggunakan imej En face fundus sebagai domain sumber dan imej fundus SLO sebagai domain sasaran. Untuk tugas pengelasan, kami menggunakan imej fundus kedua-dua domain ini sebagai domain sumber dan sasaran, diklasifikasikan kepada dua kategori: normal dan glaukoma.
Metrik Penilaian
Kami menggunakan metrik Dice dan IoU untuk menilai prestasi pembahagian, dan AUC untuk menilai prestasi tugasan pengelasan. Metrik pembahagian dan pengelasan tradisional ini, sambil mencerminkan prestasi model, secara semula jadi tidak mengambil kira keadilan merentas kumpulan demografi.
Untuk menangani potensi pertukaran antara prestasi model dan keadilan dalam pengimejan perubatan, kami menggunakan metrik Equity Scaled Performance (ESP) novel untuk menilai prestasi dan kesaksamaan pada tugasan segmentasi dan pengelasan.
Biar ∈{Dice,IoU,AUC,...}M dalam {Dice,IoU, AUC, .}M∈{Dice,IoU,AUC,...} mewakili prestasi umum yang sesuai untuk indeks pembahagian atau pengelasan. . Penilaian tradisional sering mengabaikan atribut identiti demografi, dengan itu kehilangan penilaian keadilan kritikal. Untuk menggabungkan kesaksamaan, kami mula-mula mengira perbezaan prestasi Δ, yang ditakrifkan sebagai sisihan kolektif setiap metrik kumpulan demografi daripada prestasi keseluruhan, yang dirumuskan seperti berikut:

Apabila kesaksamaan prestasi merentas kumpulan dicapai, Δ adalah hampir kepada Sifar , mencerminkan perbezaan terkecil. Kemudian, metrik ESP boleh dirumuskan seperti berikut:
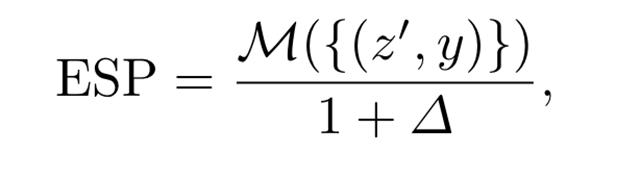
Metrik bersatu ini membantu menilai secara menyeluruh model pembelajaran mendalam, menekankan bukan sahaja memfokuskan pada ketepatannya (seperti melalui pengukuran seperti Dice, IoU, dan AUC), tetapi juga pada prestasi mereka dalam Ekuiti yang berbeza di kalangan kumpulan penduduk.
Keputusan Segmentasi Cup-Rim di bawah Anjakan Domain
Artikel ini memfokuskan pada kecerdasan buatan (terutamanya perubatan Isu keadilan dalam AI), yang merupakan kunci untuk mencapai penjagaan kesihatan yang saksama. 
 Kami mencadangkan modul plug-and-play novel Perhatian Identiti Adil (FIA) untuk mempelajari korelasi ciri berdasarkan atribut demografi melalui mekanisme perhatian untuk meningkatkan keadilan dalam tugas pemindahan domain.
Kami mencadangkan modul plug-and-play novel Perhatian Identiti Adil (FIA) untuk mempelajari korelasi ciri berdasarkan atribut demografi melalui mekanisme perhatian untuk meningkatkan keadilan dalam tugas pemindahan domain.
Kami juga mencipta set data merentas domain fokus keadilan pertama yang mengandungi dua imej pengimejan berpasangan bagi kohort pesakit yang sama untuk mengecualikan kesan mengelirukan perubahan pengedaran demografi pada keadilan model, membolehkan penilaian tepat Kesan pemindahan domain pada keadilan model. 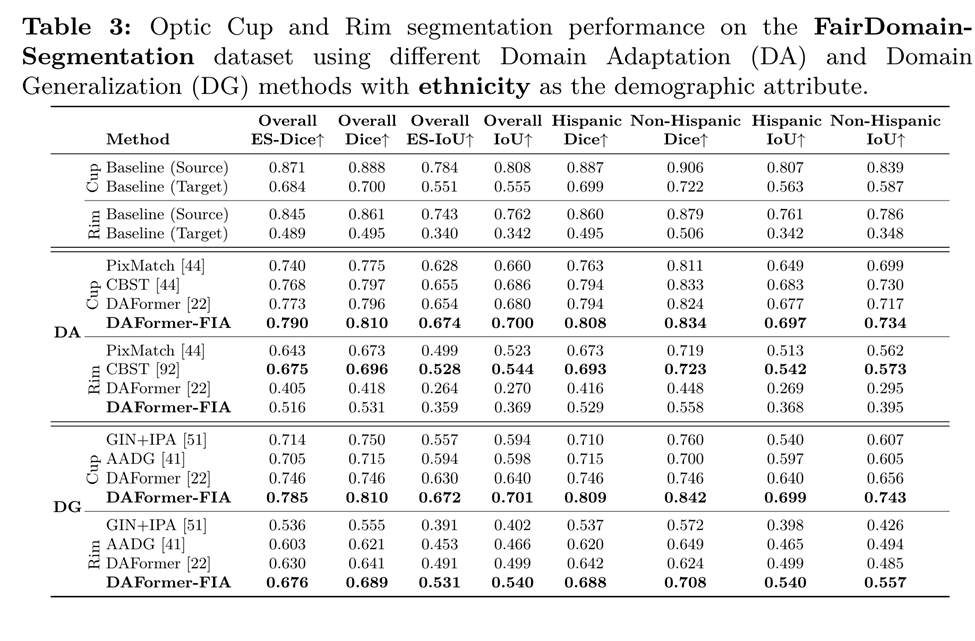
Nota: Imej muka depan dijana oleh AI.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI