
Maison >Périphériques technologiques >IA >Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.

- 王林original
- 2024-07-25 06:42:231234parcourir

Éditeur | ScienceAI
Les ensembles de données de questions et réponses (AQ) jouent un rôle essentiel dans la promotion de la recherche sur le traitement du langage naturel (NLP). Des ensembles de données d'assurance qualité de haute qualité peuvent non seulement être utilisés pour affiner les modèles, mais également évaluer efficacement les capacités des grands modèles linguistiques (LLM), en particulier la capacité à comprendre et à raisonner sur les connaissances scientifiques.
Bien qu'il existe actuellement de nombreux ensembles de données scientifiques d'assurance qualité couvrant la médecine, la chimie, la biologie et d'autres domaines, ces ensembles de données présentent encore certaines lacunes.
Premièrement, le formulaire de données est relativement simple, dont la plupart sont des questions à choix multiples. Elles sont faciles à évaluer, mais elles limitent la plage de sélection des réponses du modèle et ne peuvent pas tester pleinement la capacité du modèle à répondre aux questions scientifiques. En revanche, la réponse aux questions ouvertes (openQA) permet d'évaluer de manière plus complète les capacités du modèle, mais manque de mesures d'évaluation appropriées.
Deuxièmement, une grande partie du contenu des ensembles de données existants provient de manuels scolaires au niveau universitaire et inférieur, ce qui rend difficile l'évaluation des capacités de rétention des connaissances de haut niveau du LLM dans des environnements de recherche ou de production universitaires réels.
Troisièmement, la création de ces ensembles de données de référence repose sur l'annotation d'experts humains.
Relever ces défis est crucial pour créer un ensemble de données d'assurance qualité plus complet et favorise également une évaluation plus précise du LLM scientifique.
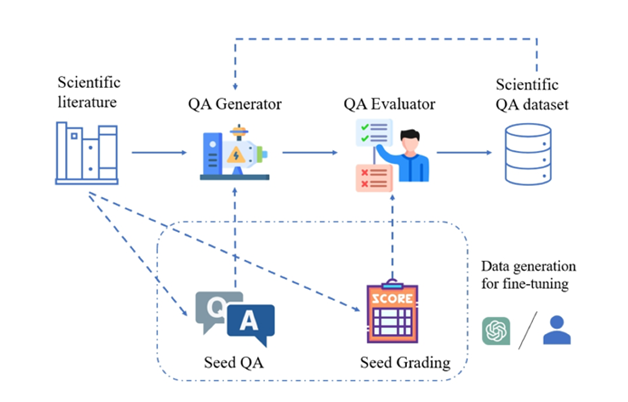
Illustration : cadre SciQAG pour générer des paires de questions et réponses scientifiques de haute qualité à partir de la littérature scientifique.
A cet effet, l'Argonne National Laboratory aux Etats-Unis, l'équipe du Professeur Ian Foster de l'Université de Chicago (lauréat du Prix Gordon Bell 2002), l'équipe UNSW AI4Science du Professeur Bram Hoex de l'Université de Nouvelle-Galles du Sud, L'Australie, la société AI4Science GreenDynamics et l'équipe du professeur Jie Chunyu de la City University of Hong Kong ont proposé conjointement SciQAG, le premier nouveau cadre permettant de générer automatiquement des paires de questions et réponses scientifiques ouvertes de haute qualité à partir de grands corpus de littérature scientifique basés sur de grands modèles de langage. (LLM).

Lien papier :https://arxiv.org/abs/2405.09939
Lien github :https://github.com/MasterAI-EAM/SciQAG
Sur la base de SciQAG, les chercheurs ont construit SciQAG-24D, un ensemble de données d'AQ scientifique ouvert à grande échelle, de haute qualité, contient 188 042 paires d'AQ extraites de 22 743 articles scientifiques dans 24 domaines scientifiques, et est conçu pour servir au réglage fin du LLM et à l'évaluation des problèmes scientifiques. capacités de résolution.
Les expériences démontrent qu'un réglage fin des LLM sur l'ensemble de données SciQAG-24D peut améliorer considérablement leurs performances dans les réponses aux questions ouvertes et les tâches scientifiques.
L'ensemble de données, le modèle et le code d'évaluation ont été open source (https://github.com/MasterAI-EAM/SciQAG) pour promouvoir le développement conjoint de questions-réponses scientifiques ouvertes par la communauté AI for Science.
Cadre SciQAG avec ensemble de données de référence SciQAG-24D
SciQAG se compose d'un générateur d'assurance qualité et d'un évaluateur d'assurance qualité, visant à générer rapidement diverses paires de questions et réponses ouvertes basées sur la littérature scientifique à grande échelle. Tout d’abord, le générateur convertit les articles scientifiques en paires de questions et réponses, puis l’évaluateur filtre les paires de questions et réponses qui ne répondent pas aux normes de qualité, obtenant ainsi un ensemble de données de questions et réponses scientifiques de haute qualité.
Générateur QA
Les chercheurs ont conçu une invite (invite) en deux étapes à travers des expériences comparatives, permettant à LLM d'extraire d'abord des mots-clés, puis de générer des paires de questions et réponses basées sur les mots-clés.
Étant donné que l'ensemble de données de questions et réponses généré adopte le mode « livre fermé », c'est-à-dire que l'article original n'est pas fourni et se concentre uniquement sur les connaissances scientifiques extraites elles-mêmes, l'invite exige que les paires de questions et réponses générées ne s'appuient pas. sur ou faire référence aux informations uniques contenues dans l'article original (par exemple, aucune nomenclature moderne n'est autorisée), telle que « ceci/cet article », « cette/cette recherche », etc., ou poser des questions sur les tableaux/images contenus dans l'article).
Pour équilibrer performances et coûts, les chercheurs ont choisi d'affiner un LLM open source comme générateur. Les utilisateurs de SciQAG peuvent choisir n'importe quel LLM open source ou fermé comme générateur en fonction de leurs propres circonstances, soit en utilisant un réglage fin, soit en utilisant une ingénierie de mots rapide.
Évaluateur QA
L'évaluateur est utilisé pour atteindre deux objectifs : (1) Évaluer la qualité des paires de questions et réponses générées ; (2) Supprimer les paires de questions et réponses de mauvaise qualité en fonction de critères définis.
Les chercheurs ont développé un indice d'évaluation complet RACAR, qui se compose de cinq dimensions : pertinence, agnosticisme, exhaustivité, exactitude et caractère raisonnable.
Dans cette étude, les chercheurs ont directement utilisé GPT-4 comme évaluateur d'assurance qualité pour évaluer les paires d'assurance qualité générées selon RACAR, avec un niveau d'évaluation de 1 à 5 (1 signifie inacceptable, 5 signifie tout à fait acceptable).
Comme le montre la figure, pour mesurer la cohérence entre GPT-4 et l'évaluation manuelle, deux experts du domaine ont utilisé la métrique RACAR pour effectuer une évaluation manuelle sur 10 articles (un total de 100 paires de questions et réponses). Les utilisateurs peuvent choisir n'importe quel LLM open source ou fermé comme évaluateur en fonction de leurs besoins.
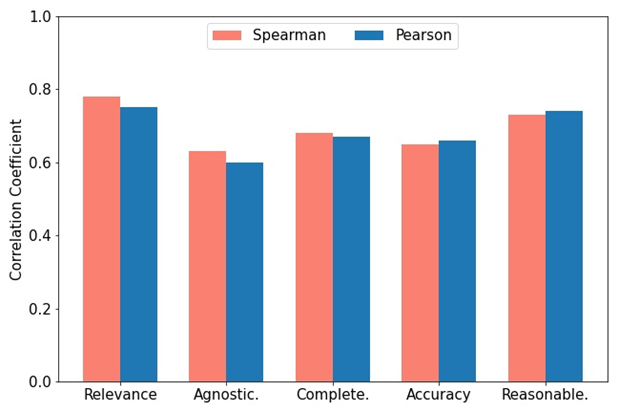
Illustration : Corrélations de Spearman et Pearson entre les scores attribués par GPT-4 et les scores d'annotation d'experts.
Application du cadre SciQAG
Cette étude a obtenu un total de 22 743 articles très cités dans 24 catégories de la base de données de base du Web of Science (WoS), dans les domaines de la science des matériaux, de la chimie, de la physique, de l'énergie, etc. , visant à construire une source de connaissances scientifiques fiable, riche, équilibrée et représentative.
Pour affiner le LLM open source afin de former un générateur d'assurance qualité, les chercheurs ont sélectionné au hasard 426 articles de la collection d'articles comme entrée et ont généré 4 260 paires d'assurance qualité de départ en invitant GPT-4.
En utilisant le générateur d'AQ formé pour effectuer des inférences sur les articles restants, un total de 227 430 paires d'AQ (y compris les paires d'AQ de départ) ont été générées. Cinquante articles ont été extraits de chaque catégorie (1 200 articles au total), GPT-4 a été utilisé pour calculer le score RACAR de chaque paire d'AQ générée, et les paires d'AQ avec un score de dimension inférieur à 3 ont été filtrées comme ensemble de test.
Pour les paires d'assurance qualité restantes, une méthode basée sur des règles est utilisée pour filtrer toutes les paires de questions et réponses contenant des informations uniques sur le document afin de former un ensemble de formation.
Ensemble de données de référence SciQAG-24D
Sur la base de ce qui précède, les chercheurs ont établi l'ensemble de données de référence scientifique ouvert SciQAG-24D. L'ensemble de formation filtré comprend 21 529 articles et 179 511 paires d'assurance qualité, et l'ensemble de test filtré contient. 1 199 articles et 8 531 paires d’assurance qualité.
Les statistiques montrent que 99,15 % des données dans les réponses proviennent de l'article original, 87,29 % des questions ont une similarité inférieure à 0,3 et les réponses couvrent 78,26 % du contenu original.
Cet ensemble de données est largement utilisé : l'ensemble de formation peut être utilisé pour affiner le LLM et y injecter des connaissances scientifiques ; l'ensemble de tests peut être utilisé pour évaluer les performances du LLM sur des tâches d'assurance qualité ouvertes dans un domaine scientifique spécifique ou global. . Étant donné que l’ensemble de tests est plus grand, il peut également être utilisé comme données de haute qualité pour un réglage fin.
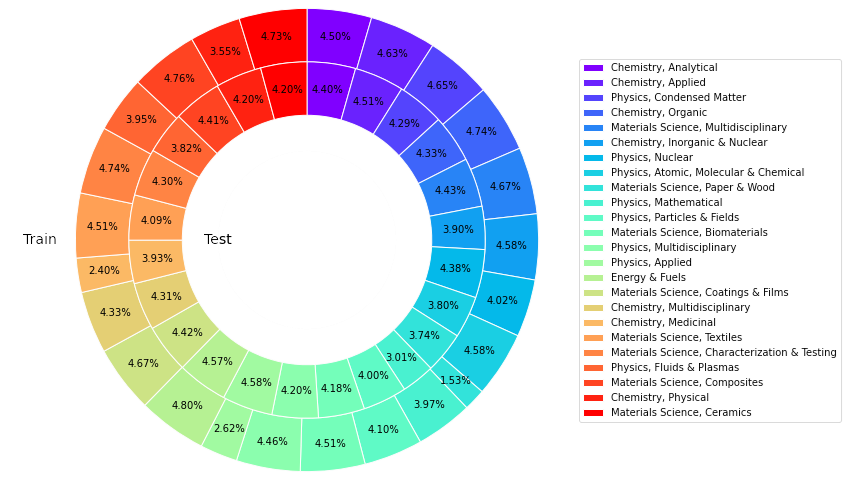
Illustration : La proportion d'articles dans différentes catégories dans la formation et les tests de l'ensemble de données SciQAG-24D.
Résultats expérimentaux
Les chercheurs ont mené des expériences complètes pour comparer les différences de performances en matière de réponse aux questions scientifiques entre différents modèles de langage et explorer l'impact d'un réglage fin.
Réglage du tir zéro
Les chercheurs ont utilisé une partie de l'ensemble de tests du SciQAG-24D pour comparer les performances du tir zéro des cinq modèles. Deux d'entre eux sont des LLM open source : LLaMA1 (7B) et LLaMA2-chat (7B), et les autres sont des LLM open source.
Appel via API : GPT3.5 (gpt-3.5-turbo), GPT-4 (gpt-4-1106-preview) et Claude 3 (claude-3-opus-20240229). Chaque modèle a été soumis à 1 000 questions dans le test, et ses résultats ont été évalués par la métrique CAR (adaptée de la métrique RACAR, se concentrant uniquement sur l'évaluation des réponses) pour mesurer sa capacité zéro à répondre aux questions de recherche scientifique.
Comme le montre la figure, parmi tous les modèles, GPT-4 a le score le plus élevé en termes d'exhaustivité (4,90) et de plausibilité (4,99), tandis que Claude 3 a le score de précision le plus élevé (4,95). GPT-3.5 fonctionne également très bien, se plaçant juste derrière GPT-4 et Claude 3 sur toutes les mesures.
Notamment, LLaMA1 a les scores les plus bas dans les trois dimensions. En revanche, bien que le modèle LLaMA2-chat n'obtienne pas un score aussi élevé que le modèle GPT, il s'améliore considérablement par rapport au LLaMA1 d'origine dans toutes les mesures. Les résultats démontrent les performances supérieures des LLM commerciaux pour répondre aux questions scientifiques, tandis que les modèles open source (tels que LLaMA2-chat) ont également réalisé des progrès significatifs à cet égard.
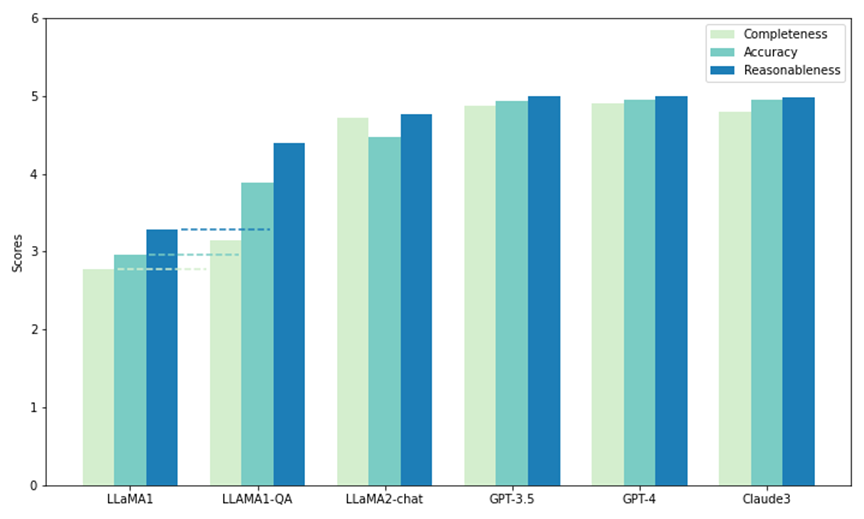
Illustration : Test d'échantillon zéro et test de réglage fin (LLAMA1-QA) sur SciQAG-24D
Paramètre de réglage fin (paramètre de réglage fin)
Les chercheurs ont sélectionné LLaMA1 avec le pire zéro- performances de l'échantillon Un réglage fin est effectué sur l'ensemble d'entraînement de SciQAG-24D pour obtenir LLaMA1-QA. À travers trois expériences, les chercheurs ont démontré que SciQAG-24D peut être utilisé comme données de réglage efficace pour améliorer les performances des tâches scientifiques en aval :
(a) LLaMA-QA par rapport au LLaMA1 original sur l'ensemble de tests invisible SciQAG-24D. comparaison.
Comme le montre la figure ci-dessus, les performances de LLaMA1-QA ont été considérablement améliorées par rapport au LLaMA1 original (exhaustivité augmentée de 13 %, précision et plausibilité augmentées de plus de 30 %). Cela montre que LLaMA1 a appris la logique pour répondre aux questions scientifiques à partir des données d'entraînement de SciQAG-24D et a internalisé certaines connaissances scientifiques.
(b) Comparaison des performances de réglage fin sur SciQ, un benchmark scientifique QCM.
La première ligne du tableau ci-dessous montre que LLaMA1-QA est légèrement meilleur que LLaMA1 (+1%). Selon les observations, le réglage fin a également amélioré la capacité de suivi des instructions du modèle : la probabilité d'une sortie non analysable a chuté de 4,1 % dans LLaMA1 à 1,7 % dans LLaMA1-QA.
(c) Comparaison des performances de mise au point sur diverses tâches scientifiques.
En termes d'indicateurs d'évaluation, le score F1 est utilisé pour les tâches de classification, le MAE est utilisé pour les tâches de régression et la divergence KL est utilisée pour les tâches de transformation. Comme le montre le tableau ci-dessous, LLaMA1-QA présente des améliorations significatives par rapport au modèle LLaMA1 dans les tâches scientifiques.
L'amélioration la plus évidente se reflète dans la tâche de régression, où le MAE est passé de 463,96 à 185,32. Ces résultats suggèrent que l'incorporation de paires d'assurance qualité pendant la formation peut améliorer la capacité du modèle à apprendre et à appliquer des connaissances scientifiques, améliorant ainsi ses performances dans les tâches de prédiction en aval.
Étonnamment, par rapport aux modèles d'apprentissage automatique spécialement conçus et dotés de fonctionnalités, LLM peut obtenir des résultats comparables, voire même les surpasser, dans certaines tâches. Par exemple, dans la tâche de bande interdite, bien que LLaMA1-QA ne fonctionne pas aussi bien que des modèles tels que MODNet (0,3327), il a surpassé AMMExpress v2020 (0,4161).
Dans la tâche de diversité, LLaMA1-QA surpasse la ligne de base de l'apprentissage profond (0,3198). Ces résultats indiquent que le LLM a un grand potentiel dans des tâches scientifiques spécifiques.
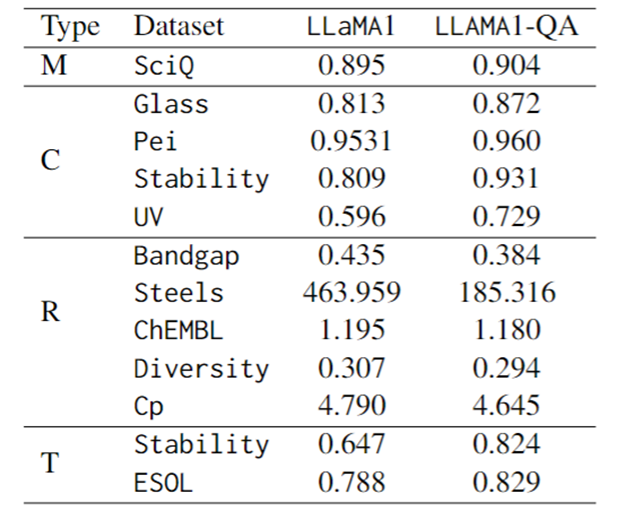
Illustration : Affiner les performances de LLaMA1 et LLaMA1-QA sur SciQ et les tâches scientifiques (M représente un choix multiple, C représente la classification, R représente la régression, T représente la transformation)
Résumé et perspectives
( 1) SciQAG est un cadre permettant de générer des paires d'assurance qualité à partir de la littérature scientifique. Combiné à la métrique RACAR pour évaluer et filtrer les paires d'assurance qualité, il peut générer efficacement de grandes quantités de données d'assurance qualité basées sur les connaissances pour les domaines scientifiques pauvres en ressources.
(2) L'équipe a généré un ensemble complet de données scientifiques d'assurance qualité open source contenant 188 042 paires d'assurance qualité, appelé SciQAG-24D. L'ensemble de formation est utilisé pour affiner le LLM, et l'ensemble de tests évalue les performances du LLM sur des tâches d'assurance qualité scientifique à livre fermé et ouvertes.
Comparé les performances sans échantillon de plusieurs LLM sur l'ensemble de test SciQAG-24D et affiné LLaMA1 sur l'ensemble d'entraînement SciQAG-24D pour obtenir LLaMA1-QA. Ce réglage fin améliore considérablement ses performances sur plusieurs tâches scientifiques.
(3) La recherche montre que le LLM a du potentiel dans les tâches scientifiques et que les résultats de LLaMA1-QA peuvent atteindre des niveaux dépassant même la base de l'apprentissage automatique. Cela démontre l'utilité multiforme de SciQAG-24D et montre que l'intégration de données scientifiques d'assurance qualité dans le processus de formation peut améliorer la capacité de LLM à apprendre et à appliquer les connaissances scientifiques.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Tout ce que vous devez savoir sur les utilisateurs de ChatGPT-4
- La vraie création 3D est là, vous devez utiliser vos mains pour faire des gestes ! L'IA ne peut pas prendre mon travail cette fois, n'est-ce pas ?
- La version Google de ChatGPT est soudainement lancée en version bêta publique ! Les résultats du test proprement dit sont ici. La demande d'expérience est acceptée rapidement.
- Pour lutter contre ChatGPT, Google lance la version bêta de Bard