La rubrique AIxiv est une rubrique où ce site publie du contenu académique et technique. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. E-mail de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com
L'auteur principal de cet article est Huang Yichong. Huang Yichong est doctorant au Centre de recherche en informatique sociale et en recherche d'informations de l'Institut de technologie de Harbin et stagiaire au laboratoire de Pengcheng. Il étudie sous la direction du professeur Qin Bing et du professeur Feng Xiaocheng. Les axes de recherche incluent l'apprentissage d'ensembles de grands modèles de langage et les grands modèles multilingues. Des articles connexes ont été publiés dans les principales conférences sur le traitement du langage naturel, ACL, EMNLP et COLING. Alors que les grands modèles linguistiques font preuve d'une intelligence linguistique étonnante, les grandes sociétés d'IA ont lancé leurs propres grands modèles. Ces grands modèles ont généralement leurs propres atouts dans différents domaines et tâches. La manière de les intégrer pour exploiter leur potentiel complémentaire est devenue un sujet pionnier dans la recherche en IA. Récemment, des chercheurs de l'Institut de technologie de Harbin et du laboratoire Pengcheng ont proposé le « Cadre d'apprentissage intégré à grand modèle hétérogène sans formation » DeePEn. Différent des méthodes précédentes qui entraînent des modules externes à filtrer et fusionner les réponses générées par plusieurs modèles, DeePEn fusionne les distributions de probabilité de plusieurs sorties de modèles pendant le processus de décodage et détermine conjointement le jeton de sortie de chaque étape. En comparaison, cette méthode peut non seulement être rapidement appliquée à n'importe quelle combinaison de modèles, mais permet également aux modèles intégrés d'accéder aux représentations internes de chacun (distributions de probabilité), permettant ainsi une collaboration plus approfondie entre les modèles. Les résultats montrent que DeepEN peut réaliser des améliorations significatives sur plusieurs ensembles de données publiques, élargissant efficacement les limites de performances des grands modèles : 
Le document et le code actuels ont été rendus publics : 
- Titre de l'article : Ensemble Learning for Heterogeneous LargeLanguage Models with Deep Parallel Collaboration
- Adresse de l'article : https://arxiv.org/abs/2404.12715
- Adresse du code : https://github.com/OrangeInSouth/DeePEn
Introduction à la méthodeLa principale difficulté de l'intégration de grands modèles hétérogènes est de savoir comment résoudre le problème de différence de vocabulaire entre les modèles. À cette fin, DeepEN construit un espace de représentation relative unifié composé de jetons partagés entre plusieurs vocabulaires de modèles basés sur la théorie de la représentation relative. Lors de l'étape de décodage, DeepEN mappe les distributions de probabilité produites par différents grands modèles sur cet espace de fusion. Aucune formation aux paramètres n'est requise dans l'ensemble du processus. L'image ci-dessous montre la méthode de DeepEn. Étant donné N modèles pour l'ensemble, DeepEN construit d'abord ses matrices de transformation (c'est-à-dire des matrices de représentation relative), mappant les distributions de probabilité de plusieurs espaces absolus hétérogènes dans un espace relatif unifié. À chaque étape de décodage, tous les modèles effectuent des calculs directs et génèrent N distributions de probabilité. Ces distributions sont cartographiées dans un espace relatif et agrégées. Enfin, les résultats de l'agrégation sont reconvertis dans l'espace absolu d'un modèle (le modèle maître) pour déterminer le jeton suivant. 
Figure 1 : Diagramme schématique. Parmi eux, la matrice de transformation de représentation relative est obtenue en calculant la similarité d'intégration de mots entre chaque jeton du vocabulaire et le jeton d'ancrage partagé entre les modèles. Construire une transformation de représentation relative À partir des modèles N à intégrer, DeepEn trouve d'abord l'intersection de tous les vocabulaires modèles, c'est-à-dire le vocabulaire partagé  , Et extrayez un sous-ensemble A⊆C ou utilisez tous les mots partagés comme ensemble de mots d’ancrage A=C. Pour chaque modèle
, Et extrayez un sous-ensemble A⊆C ou utilisez tous les mots partagés comme ensemble de mots d’ancrage A=C. Pour chaque modèle  , DeePEn calcule la similarité d'intégration entre chaque jeton du vocabulaire et le jeton d'ancrage pour obtenir une matrice de représentation relative
, DeePEn calcule la similarité d'intégration entre chaque jeton du vocabulaire et le jeton d'ancrage pour obtenir une matrice de représentation relative 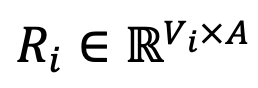 . Enfin, afin de surmonter le problème de dégradation de la représentation relative des mots aberrants, l'auteur de l'article effectue une normalisation des lignes sur la matrice de représentation relative et effectue une opération softmax sur chaque ligne de la matrice pour obtenir la matrice de représentation relative normalisée
. Enfin, afin de surmonter le problème de dégradation de la représentation relative des mots aberrants, l'auteur de l'article effectue une normalisation des lignes sur la matrice de représentation relative et effectue une opération softmax sur chaque ligne de la matrice pour obtenir la matrice de représentation relative normalisée 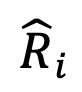 . Fusion de représentation relative Dans chaque étape de décodage, une fois que le modèle
. Fusion de représentation relative Dans chaque étape de décodage, une fois que le modèle  génère la distribution de probabilité
génère la distribution de probabilité  , DeepEn utilise la matrice de représentation relative normalisée pour convertir
, DeepEn utilise la matrice de représentation relative normalisée pour convertir  en une représentation relative
en une représentation relative  :
: 
et effectuez une moyenne pondérée de toutes les représentations relatives pour obtenir la représentation relative agrégée :  où
où  est le poids de collaboration du modèle
est le poids de collaboration du modèle  . Les auteurs ont essayé deux méthodes pour déterminer les valeurs de poids collaboratives : (1) DeePEn-Avg, qui utilise les mêmes poids pour tous les modèles ; (2) DeePEn-Adapt, qui définit les poids pour chaque modèle proportionnellement en fonction des performances de son ensemble de validation.
. Les auteurs ont essayé deux méthodes pour déterminer les valeurs de poids collaboratives : (1) DeePEn-Avg, qui utilise les mêmes poids pour tous les modèles ; (2) DeePEn-Adapt, qui définit les poids pour chaque modèle proportionnellement en fonction des performances de son ensemble de validation.
Mappage inverse de représentation relativePour décider du prochain jeton en fonction de la représentation relative agrégée, DeePEn le convertit de l'espace relatif en espace absolu du modèle principal (le modèle le plus performant sur l'ensemble de développement ). Afin de réaliser cette transformation inverse, DeePEn adopte une stratégie basée sur la recherche pour trouver la représentation absolue dont la représentation relative est la même que la représentation relative agrégée : 
où 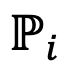 représente l'espace absolu du modèle
représente l'espace absolu du modèle  , et
, et 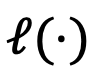 est la mesure de la représentation relative de la fonction de perte (divergence KL) entre les distances. DeePEn utilise le gradient de la fonction de perte
est la mesure de la représentation relative de la fonction de perte (divergence KL) entre les distances. DeePEn utilise le gradient de la fonction de perte  par rapport à la représentation absolue
par rapport à la représentation absolue  pour guider le processus de recherche et effectue la recherche de manière itérative. Plus précisément, DeepEN initialise le point de départ de la recherche
pour guider le processus de recherche et effectue la recherche de manière itérative. Plus précisément, DeepEN initialise le point de départ de la recherche 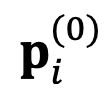 à la représentation absolue originale du maître modèle et la met à jour :
à la représentation absolue originale du maître modèle et la met à jour : 
Où η est un hyperparamètre appelé taux d'apprentissage relatif d'ensemble, et T est le nombre d'étapes d'itération de recherche. Enfin, utilisez la représentation absolue mise à jour 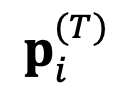 pour déterminer le jeton à sortir à l'étape suivante.
pour déterminer le jeton à sortir à l'étape suivante. 
Tableau 1 : Principaux résultats de l'expérience. La première partie est la performance d'un modèle unique, la deuxième partie est l'apprentissage d'ensemble des 2 meilleurs modèles sur chaque ensemble de données et la troisième partie est l'intégration des 4 meilleurs modèles. Grâce à des expériences, l'auteur de l'article est arrivé aux conclusions suivantes : (1) Les grands modèles ont leurs propres atouts dans différentes tâches. Comme le montre le tableau 1, il existe des différences significatives dans les performances des différents grands modèles sur différents ensembles de données. Par exemple, LLaMA2-13B a obtenu les résultats les plus élevés sur les ensembles de données TriviaQA et NQ, mais ne s'est pas classé parmi les quatre premiers pour les quatre autres tâches. (2) La fusion de distribution a réalisé des améliorations constantes sur divers ensembles de données. Comme le montre le tableau 1, DeePEn-Avg et DeePEn-Adapt ont obtenu des améliorations de performances sur tous les ensembles de données. Sur GSM8K, combinée au vote, une amélioration des performances de +11,35 a été obtenue. Tableau 2 : Performances d’apprentissage d’ensemble sous différents nombres de modèles. 
À mesure que le nombre de modèles intégrés augmente, les performances d'intégration augmentent d'abord puis diminuent
. L'auteur ajoute les modèles à l'ensemble par ordre décroissant en fonction des performances du modèle, puis observe les changements de performances. Comme le montre le tableau 2, à mesure que des modèles aux performances moins bonnes sont continuellement introduits, les performances d'intégration augmentent d'abord, puis diminuent.
Tableau 3 : Apprentissage d'ensemble entre grands modèles et traduction modèles experts sur l’ensemble de données de traduction automatique multilingue Flores. 
Intégrez de grands modèles et des modèles experts pour améliorer efficacement les performances de tâches spécifiques
. Les auteurs ont également intégré le grand modèle LLaMA2-13B et le modèle de traduction multilingue NLLB sur des tâches de traduction automatique. Comme le montre le tableau 3, l'intégration entre un grand modèle général et un modèle expert spécifique à une tâche peut améliorer considérablement les performances.
Il existe actuellement un flot incessant de grands modèles qui émergent, mais il est difficile pour un modèle d'écraser complètement les autres modèles sur toutes les tâches. Par conséquent, comment tirer parti des avantages complémentaires entre les différents modèles est devenu un axe de recherche important. Le framework DeePEn présenté dans cet article résout le problème des différences de vocabulaire entre différents grands modèles dans la fusion de distribution sans aucune formation de paramètres. Un grand nombre d'expériences montrent que DeepEN a obtenu des améliorations stables des performances dans des contextes d'apprentissage d'ensemble avec différentes tâches, différents numéros de modèle et différentes architectures de modèles. Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Déclaration:Le contenu de cet article est volontairement contribué par les internautes et les droits d'auteur appartiennent à l'auteur original. Ce site n'assume aucune responsabilité légale correspondante. Si vous trouvez un contenu suspecté de plagiat ou de contrefaçon, veuillez contacter admin@php.cn



 génère la distribution de probabilité
génère la distribution de probabilité  en une représentation relative
en une représentation relative  par rapport à la représentation absolue
par rapport à la représentation absolue