
Maison >Périphériques technologiques >IA >La formation Axiom permet au LLM d'apprendre le raisonnement causal : le modèle à 67 millions de paramètres est comparable au niveau de mille milliards de paramètres GPT-4.
La formation Axiom permet au LLM d'apprendre le raisonnement causal : le modèle à 67 millions de paramètres est comparable au niveau de mille milliards de paramètres GPT-4.

- 王林original
- 2024-07-17 10:14:381481parcourir
Montrez la chaîne causale à LLM et il apprendra les axiomes.

Titre de l'article : Enseigner le raisonnement causal aux transformateurs grâce à la formation axiomatique Adresse de l'article : https://arxiv.org/pdf/2407.07612
 , et la conclusion est « oui ».
, et la conclusion est « oui ».  , où n est le nombre de nœuds dans chaque i-ième prémisse. P est la prémisse, c'est-à-dire une expression en langage naturel d'une certaine structure causale (telle que X provoque Y, Y provoque Z) suivie de la question H (telle que X provoque Y ? L est l'étiquette (Oui) ; ou pas). Ce formulaire couvre effectivement toutes les paires de nœuds pour chaque chaîne unique dans un graphe causal donné.
, où n est le nombre de nœuds dans chaque i-ième prémisse. P est la prémisse, c'est-à-dire une expression en langage naturel d'une certaine structure causale (telle que X provoque Y, Y provoque Z) suivie de la question H (telle que X provoque Y ? L est l'étiquette (Oui) ; ou pas). Ce formulaire couvre effectivement toutes les paires de nœuds pour chaque chaîne unique dans un graphe causal donné.  L'analyse montre que par rapport à la prédiction de jeton suivante, en utilisant ces pertes peut donner des résultats prometteurs.
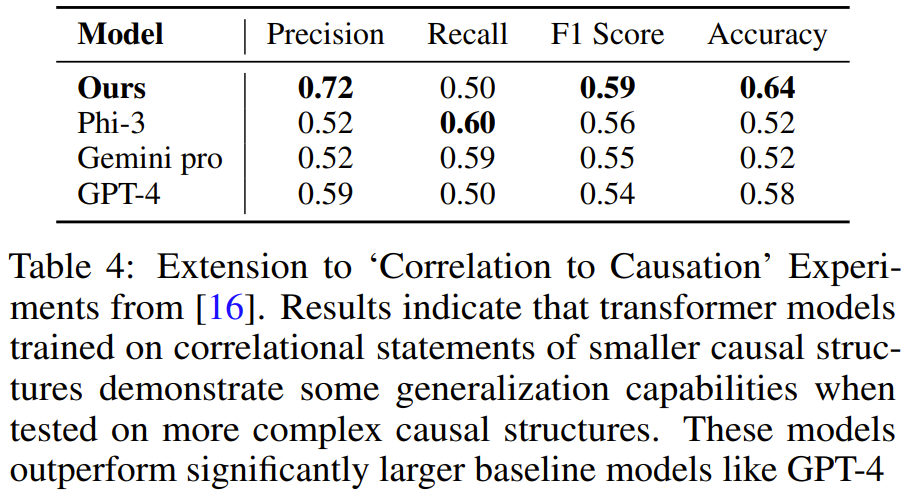
L'analyse montre que par rapport à la prédiction de jeton suivante, en utilisant ces pertes peut donner des résultats prometteurs. 




Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Déclaration:
Le contenu de cet article est volontairement contribué par les internautes et les droits d'auteur appartiennent à l'auteur original. Ce site n'assume aucune responsabilité légale correspondante. Si vous trouvez un contenu suspecté de plagiat ou de contrefaçon, veuillez contacter admin@php.cn
Article précédent:Si vous souhaitez vous lancer dans l’IA, n’étudiez pas la science des données au lycée : Altman et Musk sont enfin d’accord maintenantArticle suivant:Si vous souhaitez vous lancer dans l’IA, n’étudiez pas la science des données au lycée : Altman et Musk sont enfin d’accord maintenant
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI