
Maison >Périphériques technologiques >IA >Après avoir adopté plus de 30 dialectes, nous n'avons pas réussi le test du modèle de grande parole de China Telecom.
Après avoir adopté plus de 30 dialectes, nous n'avons pas réussi le test du modèle de grande parole de China Telecom.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBoriginal
- 2024-07-15 17:44:571121parcourir
Peu importe de quelle ville vous venez, je crois que vous avez votre propre « dialecte de ville natale » dans votre mémoire : le dialecte Wu est doux et délicat, le dialecte Guanzhong est simple et épais, le dialecte du Sichuan est humoristique et humoristique, le cantonais est pittoresque et débridé. ..
Dans un sens, le dialecte n'est pas seulement une habitude linguistique, mais aussi un lien émotionnel et une identité culturelle. La plupart des nouveaux mots que nous rencontrons en surfant sur Internet proviennent de dialectes locaux de divers endroits.
Bien sûr, parfois le dialecte est aussi une « barrière » à la communication.
Dans la vraie vie, nous voyons souvent des « poulets parlant comme des canards » causés par des dialectes, comme celui-ci : 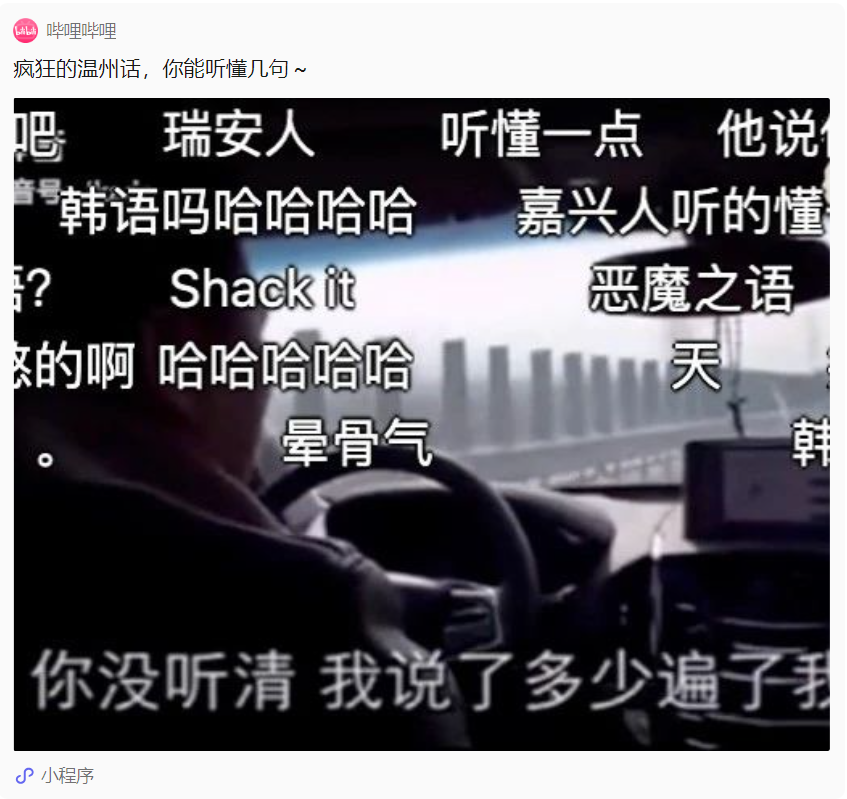
Si vous faites attention aux tendances récentes dans le cercle technologique, vous saurez que l'assistant vocal IA actuel peut déjà atteindre Le niveau de « réponse en temps réel » est encore plus rapide que la réaction humaine. De plus, l’IA est capable de comprendre pleinement les émotions humaines et peut exprimer elle-même diverses émotions.
Sur cette base, si l'assistant vocal peut reconnaître et comprendre chaque dialecte, il peut complètement briser les barrières de communication et communiquer avec n'importe quel groupe sans barrières.
En fait, quelqu'un l'a déjà fait : récemment, l'Institut de recherche sur l'intelligence artificielle de China Telecom (TeleAI) a publié le premier « modèle de reconnaissance vocale super multidialecte Xingchen » qui prend en charge le mélange libre de 30 dialectes. comprend le cantonais, le shanghaïen, le sichuan, le wenzhou et d'autres dialectes locaux. Il s'agit d'un vaste modèle de reconnaissance vocale qui prend en charge la plupart des dialectes en Chine.
Par exemple, dans le scénario de conférence suivant, face à la contribution de plusieurs dialectes, la précision de reconnaissance du grand modèle de reconnaissance vocale multidialecte de Xingchen a atteint le premier niveau de l'industrie. Tout d'abord, le représentant de la société du Guangdong a parlé en cantonais :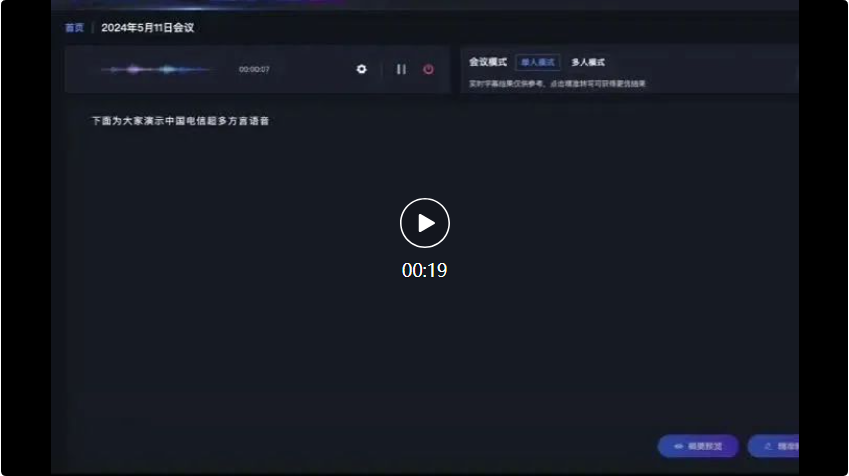
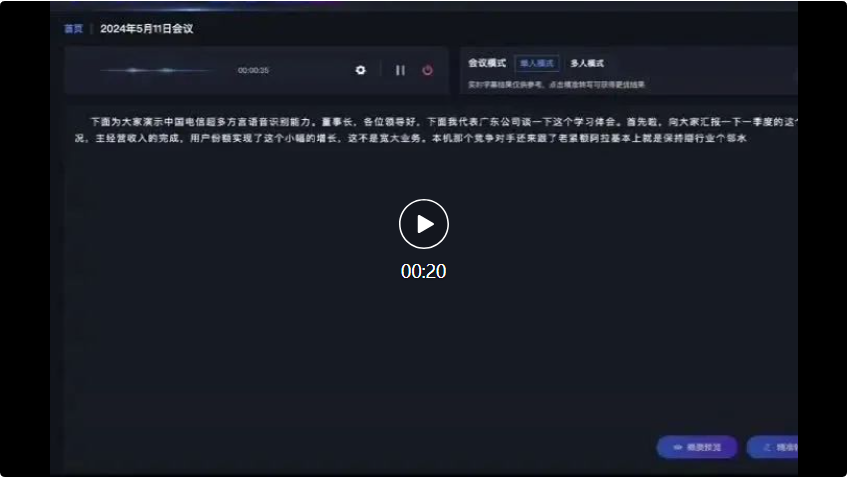 Dans le dialogue qui a suivi entre le dialecte du Sichuan et le dialecte du Shanxi, le grand modèle de reconnaissance vocale multi-dialecte de Xingchen peut également reconnaître avec précision et convertir en enregistrements de texte :
Dans le dialogue qui a suivi entre le dialecte du Sichuan et le dialecte du Shanxi, le grand modèle de reconnaissance vocale multi-dialecte de Xingchen peut également reconnaître avec précision et convertir en enregistrements de texte : 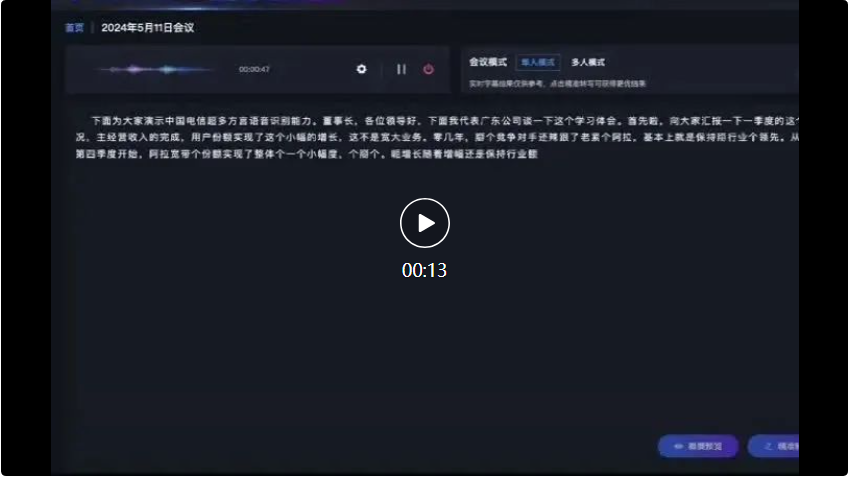
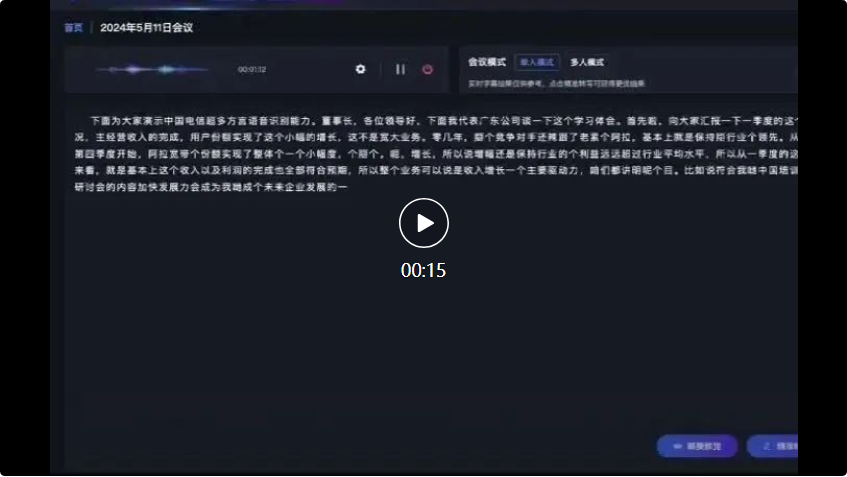
Plus de 30 dialectes, comment avoir le grand modèle ?
Il n'est pas aussi simple qu'on l'imagine de laisser un grand modèle apprendre plus de 30 dialectes en une seule fois - les défis existent également en termes de données, d'algorithmes et de puissance de calcul. D'une part, en raison de la rareté desdonnées dialectales, l'effet de la formation d'un modèle dialectal seul sans utiliser les informations communes dans d'autres données dialectales est souvent insatisfaisant.
Après des années d'accumulation dans le domaine de la parole, TeleAI a construit une base de données de dialectes de haute qualité de plus de 30 types et de plus de 300 000 heures. La base de données de dialectes se classe à la pointe du secteur en termes de richesse et de haute qualité. Des données vocales de haute qualité constituent un avantage considérable pour les chercheurs, car elles permettent aux modèles d’organiser et de résumer les dialectes de manière plus efficace et systématique. À plus long terme, la création d’une base de données dialectales de haute qualité constitue également la base de la protection et de la recherche dialectales. Un autre défi vient de latechnologie de reconnaissance vocale. Comment faire en sorte que les utilisateurs parlent à de grands modèles aussi naturellement qu'à des membres de leur famille, sans avoir besoin de passer délibérément au mandarin, sans avoir besoin d'augmenter le volume ou de ralentir la vitesse de parole, est un nouvel objectif poursuivi actuellement par l'industrie.
Dirigé par Li Xuelong, CTO de China Telecom et directeur de l'Institut de recherche sur l'intelligence artificielle, TeleAI a développé indépendamment le modèle de reconnaissance vocale Xingchen à grande échelle. L'équipe a été pionnière de l'algorithme d'entraînement conjoint « distillation + expansion », qui a résolu le problème de l'effondrement avant l'entraînement dans des ensembles de données multi-scénarios à très grande échelle et dans des conditions de paramètres à grande échelle, et a réalisé un entraînement stable du modèle à 80 couches. . Dans le même temps, grâce à un pré-entraînement vocal à très grande échelle et à une modélisation conjointe multi-dialectes, un modèle unique prend en charge la reconnaissance vocale mixte gratuite de 30 dialectes.

Le grand modèle de reconnaissance vocale Xingchen est également le premier grand modèle de reconnaissance vocale open source de l'industrie basé sur une représentation vocale discrète, grâce au nouveau paradigme de modélisation de « de la parole au jeton en passant par le texte », le débit binaire de transmission de la parole pendant. l'inférence est réduite Réduit des dizaines de fois.
Avec ses performances absolument leaders, le grand modèle de reconnaissance vocale Xingchen a déjà remporté plusieurs championnats internationaux de compétition faisant autorité au niveau international.
Par exemple, dans la piste ASR (Automatic Speech Recognition, Automatic Speech Recognition) de l'Interspeech 2024 Discrete Speech Unit Modeling Challenge, la conférence internationale faisant autorité sur la parole, l'équipe de grands modèles de reconnaissance vocale de Xingchen est en avance sur l'Université Johns Hopkins, Card Well Des universités et des entreprises renommées au pays et à l'étranger, notamment l'Université Mellon et NVIDIA, ont remporté le championnat de piste d'un seul coup.
La solution système proposée par l'équipe dans ce concours est très distinctive : elle adopte une conception « en trois étapes » pendant la formation, comprenant la stratégie d'ajustement de la représentation du modèle de pré-formation frontale (Frontend Model), l'extraction de la représentation et le processus de discrétisation. (Dsicrete Token Process) et le processus de formation du modèle de reconnaissance multilingue (Discrete ASR Model), alors que seuls ces deux derniers processus sont utilisés dans l'étape d'inférence.
La méthode de discrétisation de la représentation permet au modèle de conserver les informations liées à la tâche dans la parole tout en supprimant d'autres informations non pertinentes pour atteindre l'objectif de réduire le débit binaire de transmission de l'inférence vocale, de réduire l'utilisation de la mémoire et d'améliorer l'efficacité de la formation. sont fournis dans les domaines de la construction de modèles unifiés, de la modélisation de modèles multimodaux et de la protection de la confidentialité des locuteurs pour des tâches multiples (telles que l'ASR, le TTS, la reconnaissance du locuteur, etc.).
Sur la tâche KeSpeech, un ensemble de données de reconnaissance vocale multidialecte bien connu dans l'industrie, le grand modèle de reconnaissance vocale Xingchen a battu le record de 20 % devant le meilleur résultat précédent, atteignant une précision des mots de 92,97 %. Dans le cadre de la tâche de reconnaissance vocale Babel du téléphone cantonais à faibles ressources organisée par le NIST (Institut national des normes et de la technologie), le grand modèle de reconnaissance vocale Xingchen a également obtenu les meilleurs résultats de l'industrie.
En termes de défis courants en matière de puissance de calcul, l'équipe R&D du grand modèle de reconnaissance vocale Xingchen présente également des avantages. China Telecom est le premier opérateur national à entrer dans le domaine du cloud computing et a accumulé un grand nombre de technologies de base pour la construction et la planification de la puissance de calcul. En outre, China Telecom a successivement mis en service plusieurs centres de calcul intelligents publics qui répondent aux besoins de formation de grands modèles, tels que le centre de calcul intelligent Pékin-Tianjin-Hebei et le centre de calcul intelligent Centre-Sud.
Sur la base de ces avantages, le grand modèle de reconnaissance vocale multidialecte de Xingchen est né, brisant le dilemme selon lequel un modèle unique ne peut reconnaître qu'un seul dialecte spécifique. Lors de plusieurs tests de référence, le grand modèle de reconnaissance vocale super multidialecte Xingchen a montré des capacités extrêmement excellentes :
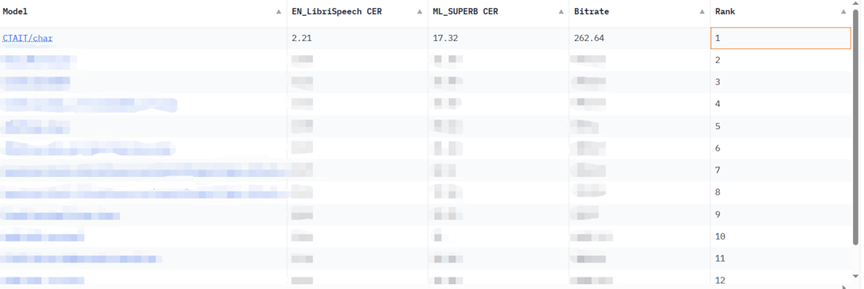
dans le grand modèle. L'expérience utilisateur des assistants vocaux, des appareils intelligents et des systèmes de service client qui étaient largement utilisés avant l'avènement de la technologie dépend fortement de la précision du système de reconnaissance vocale. De nombreux fabricants nationaux et étrangers travaillent sur cette piste, mais tout le monde constatera également qu'en dehors des langues traditionnelles, les dialectes chinois avec des centaines de millions d'utilisateurs n'ont pas reçu l'attention voulue et leur valeur scénique a été sérieusement sous-estimée.
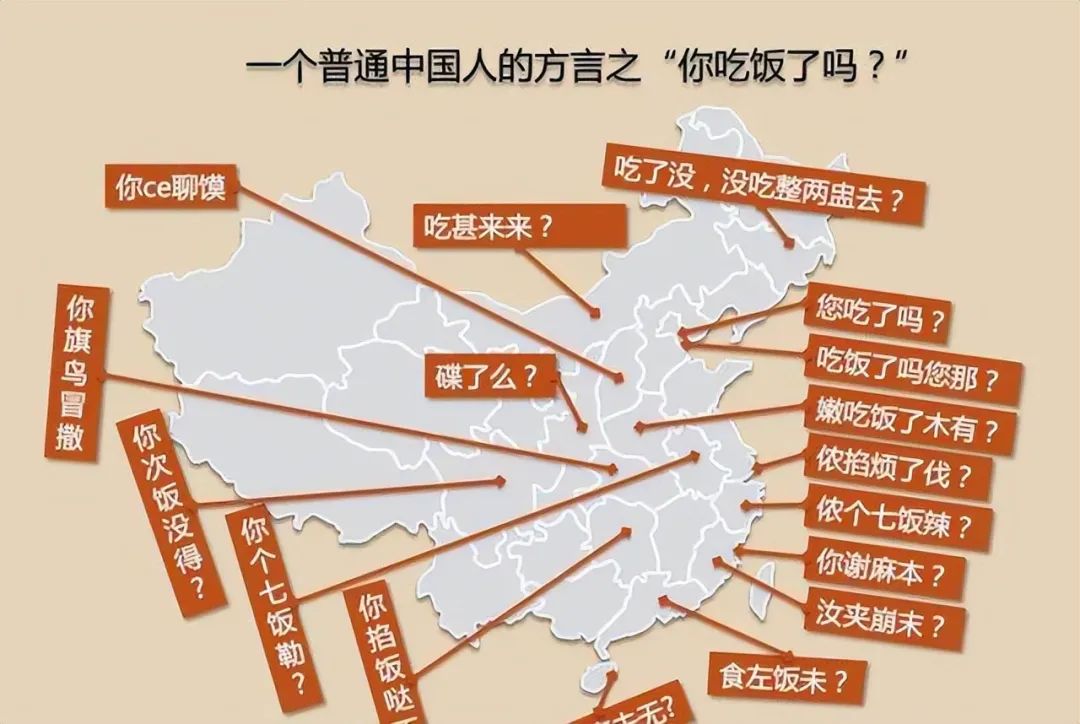
À long terme, les capacités multidialectes du modèle de reconnaissance vocale multidialecte à grande échelle de Xingchen peuvent être utiles dans un très large éventail de scénarios de vie sociale. En prenant comme exemple le scénario Smart Cockpit avec une fréquence élevée d'interaction vocale, le grand modèle de reconnaissance vocale multidialecte de Xingchen, qui convient à divers dialectes, peut permettre au système de reconnaître et de transcrire plus précisément les entrées vocales dans divers dialectes, apporter une expérience plus naturelle et plus fluide. L'expérience interactive, en particulier dans les zones où les dialectes sont couramment utilisés, peut réduire les malentendus causés par les « poules parlant avec les canards ».
Du point de vue du compagnon émotionnel, la compréhension et la maîtrise des grands modèles dans les dialectes peuvent grandement améliorer la qualité de la compagnie des produits de robots conversationnels et résoudre efficacement le problème des personnes âgées et d'autres groupes qui ne maîtrisent pas le mandarin et qui sont incapables de accéder aux services d’information. Tout comme l’intrigue du film de science-fiction « Her », l’IA peut fournir aux humains des soins de haute qualité qui transcendent les relations interpersonnelles dans le monde réel. 
Actuellement, le vaste modèle de reconnaissance vocale multidialecte de Xingchen a commencé à être intégré dans diverses industries et explore activement les scénarios d'application émergents. Par exemple, le modèle de reconnaissance vocale multidialecte à grande échelle de Xingchen a été testé dans le système de service client intelligent Wanhao de China Telecom au Fujian, au Jiangxi, au Guangxi, à Pékin, en Mongolie intérieure et dans d'autres endroits après avoir accédé au multidialecte à grande échelle de Xingchen. modèle de reconnaissance vocale, Wanhao Le service client intelligent comprend 30 dialectes en quelques secondes et traite en moyenne environ 2 millions d'appels par jour ; la plate-forme de service client intelligent Yisheng est connectée aux capacités de compréhension et d'analyse de la parole du super multi-dialecte Xingchen modèle de reconnaissance, atteignant une couverture complète dans 31 provinces et peut traiter chaque jour 1,25 million d'appels au service client.
Pour China Telecom, il existe un autre point de départ très important : avant 2023, lorsque l’on parle de technologie à grand modèle, la valeur du bien-être public sera rarement évoquée. Mais en 2024, cette valeur est de plus en plus « vue ».
L'application de la technologie des grands modèles favorisera grandement la protection de la culture dialectale. Parmi les plus de 130 langues que compte notre pays, 68 ont moins de 10 000 locuteurs, 48 ont moins de 5 000 locuteurs, 25 ont moins de 1 000 locuteurs et certaines langues n'ont qu'une douzaine, voire quelques locuteurs. peut parler. La participation de grands modèles de parole peut aider à enregistrer et à protéger les dialectes menacés et à promouvoir l’héritage et l’apprentissage des dialectes. Pour les documents et archives historiques contenant une grande quantité de contenu dialectal, les grands modèles dialectaux peuvent également faciliter le travail de numérisation et d’organisation afin de prévenir la perte du patrimoine culturel.
« Voice Assistant » est entièrement ouvert
Comment China Telecom peut-elle mener la bataille pour la mise en œuvre de grands modèles ?
La bataille pour les grands modèles dure depuis un an et demi. Il existe actuellement un consensus dans l'industrie : à mesure que le coût de l'inférence de grands modèles baisse considérablement, les gens vont inaugurer une période d'explosion pour les applications de grands modèles.
Parmi les nombreux grands acteurs nationaux et étrangers, China Telecom est un acteur très spécial. Dans cette nouvelle étape, par rapport aux entreprises technologiques que nous connaissons, les opérateurs comme China Telecom disposent de plus d'avantages en termes de ressources et de business.
D'une part, les opérateurs disposent de ressources réseau et informatiques abondantes, et relativement parlant, les coûts de formation et d'inférence sont inférieurs. Surtout dans la construction de grands modèles, il est plus facile de tirer parti de l’échelle. D'autre part, China Telecom dispose d'une large clientèle et de riches entreprises de services d'information 2C, 2H et 2B, qui peuvent rapidement promouvoir la mise en œuvre de grands modèles d'intelligence artificielle dans divers domaines et former de nouveaux pôles de croissance économique. Ces avantages incitent les opérateurs à accroître leurs investissements dans le domaine de l’intelligence artificielle et à stimuler le progrès technologique.
Parmi les opérateurs nationaux, China Telecom est le premier à se déployer dans le domaine de l'IA et adhère à la voie du développement de l'innovation technologique et de la recherche et du développement indépendants des capacités de base. Depuis l'année dernière, du grand modèle sémantique Xingchen au grand modèle multimodal Xingchen et au grand modèle de reconnaissance vocale Xingchen, les grands modèles de China Telecom ont toujours maintenu une itération rapide et complété le modèle complet de sémantique, de parole, de vision et de multimodalité. . Disposition dynamique du grand modèle.

 Avez-vous hâte de disposer d'un assistant vocal chinois aussi polyvalent ?
Avez-vous hâte de disposer d'un assistant vocal chinois aussi polyvalent ?
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI