
Maison >Périphériques technologiques >IA >CCTV a fait l'éloge de la technique d'invocation de résurrection de l'IA nationale, et les guerriers en terre cuite ont en fait rappé avec Oncle Gemstone ?
CCTV a fait l'éloge de la technique d'invocation de résurrection de l'IA nationale, et les guerriers en terre cuite ont en fait rappé avec Oncle Gemstone ?

- 王林original
- 2024-07-15 17:09:101116parcourir



 Ce n'est pas la première fois qu'EMO sort "du cercle". "Gao Qiqiang et Luo Xiang Pufa", devenu populaire sur les réseaux sociaux, a également été créé par EMO :
Ce n'est pas la première fois qu'EMO sort "du cercle". "Gao Qiqiang et Luo Xiang Pufa", devenu populaire sur les réseaux sociaux, a également été créé par EMO : 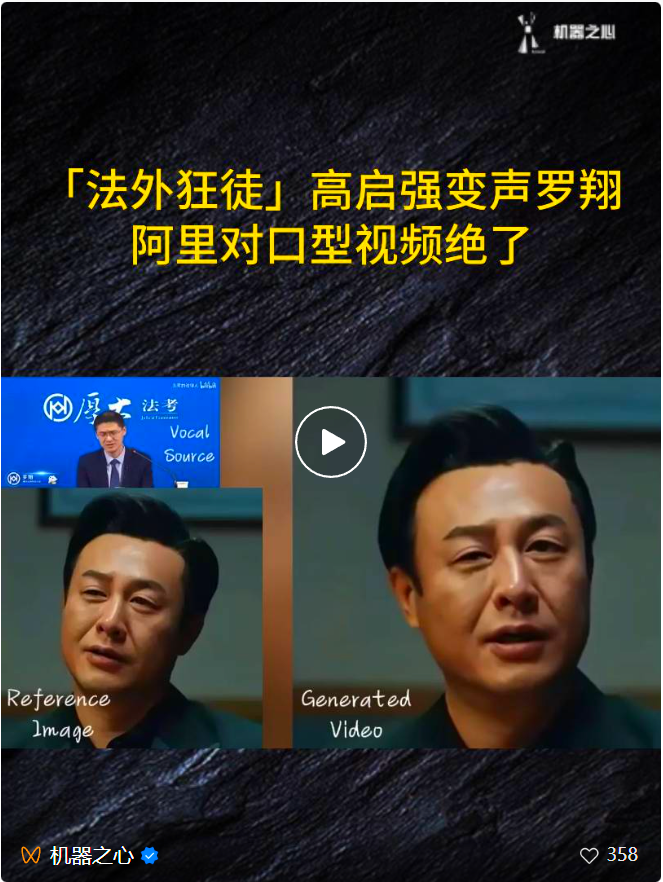

Adresse papier : https://arxiv.org/pdf/2402.17485 Page d'accueil du projet : https://humanaigc.github.io/emote-portrait-alive/




 De la technologie au monde réel
De la technologie au monde réelLes équipes techniques qui veulent gagner en influence à cette époque doivent apprendre à marcher sur deux jambes : les « modèles de base » et les « super applications ».
EMO peut constituer une avancée technologique importante pour mettre fin à cette situation, et l'application Tongyi fournit une large plate-forme pour la mise en œuvre de la technologie.
Cependant, la technologie EMO est très tolérante à la durée audio et la qualité du contenu généré peut répondre aux normes des studios. Par exemple, dans cette « Chant et performance des guerriers et des chevaux en terre cuite » diffusée sur CCTV, pas une seule seconde de la vidéo de quatre minutes de la performance des guerriers et des chevaux en terre cuite n'a nécessité un « réglage fin » manuel en post-production.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Déclaration:
Le contenu de cet article est volontairement contribué par les internautes et les droits d'auteur appartiennent à l'auteur original. Ce site n'assume aucune responsabilité légale correspondante. Si vous trouvez un contenu suspecté de plagiat ou de contrefaçon, veuillez contacter admin@php.cn
Article précédent:Tao Zhexuan le recommande vivement et le vérifie personnellement : suivez simplement cette liste pour apprendre l'IA pour les mathématiquesArticle suivant:Tao Zhexuan le recommande vivement et le vérifie personnellement : suivez simplement cette liste pour apprendre l'IA pour les mathématiques
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI