
Maison >Périphériques technologiques >IA >J'ai hâte de voir Q* d'OpenAI, l'arme secrète de Huawei Noah, MindStar pour explorer le raisonnement LLM, est là en premier
J'ai hâte de voir Q* d'OpenAI, l'arme secrète de Huawei Noah, MindStar pour explorer le raisonnement LLM, est là en premier

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBoriginal
- 2024-07-02 05:01:41732parcourir

La rubrique AIxiv est une rubrique où ce site publie du contenu académique et technique. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. Courriel de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com

Titre de l'article : MindStar : Enhancing Math Reasoning in Pre-trained LLMs at Inference Time Adresse de l'article : https://arxiv.org/abs/2405.16265v2

Le rapport Llama-3 [10] met en évidence une observation importante : face à un problème d'inférence difficile, les modèles génèrent parfois des trajectoires d'inférence correctes. Cela suggère que le modèle sait comment produire la bonne réponse, mais qu’il a du mal à la sélectionner. Sur la base de ces résultats, nous avons posé une question simple : pouvons-nous améliorer les capacités de raisonnement des LLM en les aidant à choisir le bon résultat ? Pour explorer cela, nous avons mené une expérience en utilisant différents modèles de récompense pour la sélection des résultats des LLM. Les résultats expérimentaux montrent que la sélection par étapes surpasse considérablement les méthodes CoT traditionnelles.
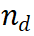 PRM évalue les nouvelles étapes en considérant l'ensemble de la trajectoire de raisonnement actuelle, en encourageant la cohérence et la fidélité au cheminement global. Une valeur de récompense élevée indique que la nouvelle étape
PRM évalue les nouvelles étapes en considérant l'ensemble de la trajectoire de raisonnement actuelle, en encourageant la cohérence et la fidélité au cheminement global. Une valeur de récompense élevée indique que la nouvelle étape 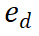 ) est probablement correcte pour un chemin de raisonnement donné
) est probablement correcte pour un chemin de raisonnement donné 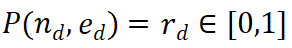 , ce qui rend le chemin d'expansion intéressant une exploration plus approfondie. À l’inverse, une valeur de récompense faible indique que la nouvelle étape peut être incorrecte, ce qui signifie que la solution qui suit ce chemin peut également être incorrecte. L'algorithme
, ce qui rend le chemin d'expansion intéressant une exploration plus approfondie. À l’inverse, une valeur de récompense faible indique que la nouvelle étape peut être incorrecte, ce qui signifie que la solution qui suit ce chemin peut également être incorrecte. L'algorithme 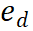
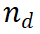
1 Expansion du chemin d'inférence : à chaque itération, le LLM sous-jacent génère l'étape suivante du chemin d'inférence actuel. .
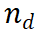 , nous avons conçu un modèle d'invite (exemple 3.1) pour collecter les prochaines étapes du LLM. Comme le montre l'exemple, LLM traite la question d'origine comme {question} et le chemin de raisonnement actuel comme {réponse}. Notez que lors de la première itération de l'algorithme, le nœud sélectionné est le nœud racine qui contient uniquement la question, donc {answer} est vide. Pour un chemin d'inférence
, nous avons conçu un modèle d'invite (exemple 3.1) pour collecter les prochaines étapes du LLM. Comme le montre l'exemple, LLM traite la question d'origine comme {question} et le chemin de raisonnement actuel comme {réponse}. Notez que lors de la première itération de l'algorithme, le nœud sélectionné est le nœud racine qui contient uniquement la question, donc {answer} est vide. Pour un chemin d'inférence  , LLM génère N étapes intermédiaires et les ajoute en tant qu'enfants du nœud actuel. Dans l'étape suivante de l'algorithme, ces nœuds enfants nouvellement générés sont évalués et un nouveau nœud est sélectionné pour une expansion ultérieure. Nous avons également réalisé qu'une autre façon de générer des étapes consiste à affiner le LLM à l'aide de marqueurs d'étape. Cependant, cela peut réduire la capacité d'inférence du LLM et, plus important encore, cela va à l'encontre de l'objectif de cet article : améliorer la capacité d'inférence du LLM sans modifier les pondérations.
, LLM génère N étapes intermédiaires et les ajoute en tant qu'enfants du nœud actuel. Dans l'étape suivante de l'algorithme, ces nœuds enfants nouvellement générés sont évalués et un nouveau nœud est sélectionné pour une expansion ultérieure. Nous avons également réalisé qu'une autre façon de générer des étapes consiste à affiner le LLM à l'aide de marqueurs d'étape. Cependant, cela peut réduire la capacité d'inférence du LLM et, plus important encore, cela va à l'encontre de l'objectif de cet article : améliorer la capacité d'inférence du LLM sans modifier les pondérations. 



Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Déclaration:
Le contenu de cet article est volontairement contribué par les internautes et les droits d'auteur appartiennent à l'auteur original. Ce site n'assume aucune responsabilité légale correspondante. Si vous trouvez un contenu suspecté de plagiat ou de contrefaçon, veuillez contacter admin@php.cn
Article précédent:Venir vite! Luchen Open-Sora peut collecter de la laine et vous pouvez facilement démarrer la génération de vidéos pour 10 yuans.Article suivant:Venir vite! Luchen Open-Sora peut collecter de la laine et vous pouvez facilement démarrer la génération de vidéos pour 10 yuans.
Articles Liés
Voir plus- Comment rédiger une expérience de projet dans un CV d'ingénieur front-end
- Quelles connaissances les ingénieurs d'exploitation et de maintenance Linux doivent-ils maîtriser ?
- Que signifie ingénieur python full stack ?
- Quelle est la différence entre une spécialisation en logiciel informatique et un génie logiciel ?