
Maison >Périphériques technologiques >IA >Bytedance Doubao et l'Université de Wuhan ont proposé CAL : améliorer les effets d'alignement multimodal grâce à des jetons visuellement liés
Bytedance Doubao et l'Université de Wuhan ont proposé CAL : améliorer les effets d'alignement multimodal grâce à des jetons visuellement liés

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBoriginal
- 2024-06-19 09:53:011036parcourir

La rubrique AIxiv est une rubrique où ce site publie du contenu académique et technique. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. E-mail de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com

- Lien papier : https://arxiv.org/pdf/2405.17871
- Lien code : https://github.com/foundation-multimodal-models/CAL
- peut être directement intégré dans le processus de formation sans étape de pré-formation supplémentaire.
- a obtenu des améliorations significatives dans les tests d'OCR et de légende. À partir de la visualisation, on peut constater que CAL améliore l'alignement modal de l'image.
- CAL rend le processus de formation plus résistant aux données bruyantes.
Texte hautement lié aux images : tels que les entités ( Tels que personnes, animaux, objets), quantité, couleur, texte, etc. Ces jetons correspondent directement aux informations de l'image et sont cruciaux pour l'alignement multimodal. Texte avec une faible corrélation avec l'image : Comme les mots suivants ou le contenu qui peut être déduit du texte précédent. Ces jetons sont en fait principalement utilisés pour entraîner les capacités de texte brut de VLM. Texte qui contredit le contenu de l'image : ces jetons ne sont pas cohérents avec les informations de l'image et peuvent même fournir des informations trompeuses, affectant négativement le processus d'alignement multimodal.
 标 Figure 1 : La marque verte est liée au jeton lié à un niveau élevé, le rouge est le contraire au contenu et l'incolore est le jeton neutre
标 Figure 1 : La marque verte est liée au jeton lié à un niveau élevé, le rouge est le contraire au contenu et l'incolore est le jeton neutre
- Si vous ajoutez une entrée d'image devant, cela équivaut à fournir des informations contextuelles supplémentaires. Dans ce cas, le logit de chaque jeton de texte sera ajusté en fonction de la nouvelle situation. Les changements logit dans ces deux cas représentent l'impact du nouvel état de l'image sur chaque jeton de texte.
- Plus précisément, pendant le processus de formation, CAL saisit respectivement les séquences d'images et de texte et les séquences de texte individuelles dans le grand modèle de langage (LLM) pour obtenir le logit de chaque jeton de texte. En calculant la différence logit entre les deux cas, on peut mesurer l’impact de l’image sur chaque token. Plus la différence logit est grande, plus l'impact de l'image sur le jeton est grand, donc le jeton est plus pertinent par rapport à l'image. La figure ci-dessous montre l'organigramme des méthodes logit diff et CAL pour les jetons de texte.对 Figure 2 : L'image de gauche est la visualisation du diff logit du jeton dans les deux situations. L'image de droite est la visualisation du processus de la méthode CAL
 Cal in Llava Une vérification expérimentale a été effectuée sur deux. modèles grand public : MGM et MGM, et des améliorations de performances ont été obtenues dans des modèles de différentes tailles.
Cal in Llava Une vérification expérimentale a été effectuée sur deux. modèles grand public : MGM et MGM, et des améliorations de performances ont été obtenues dans des modèles de différentes tailles. 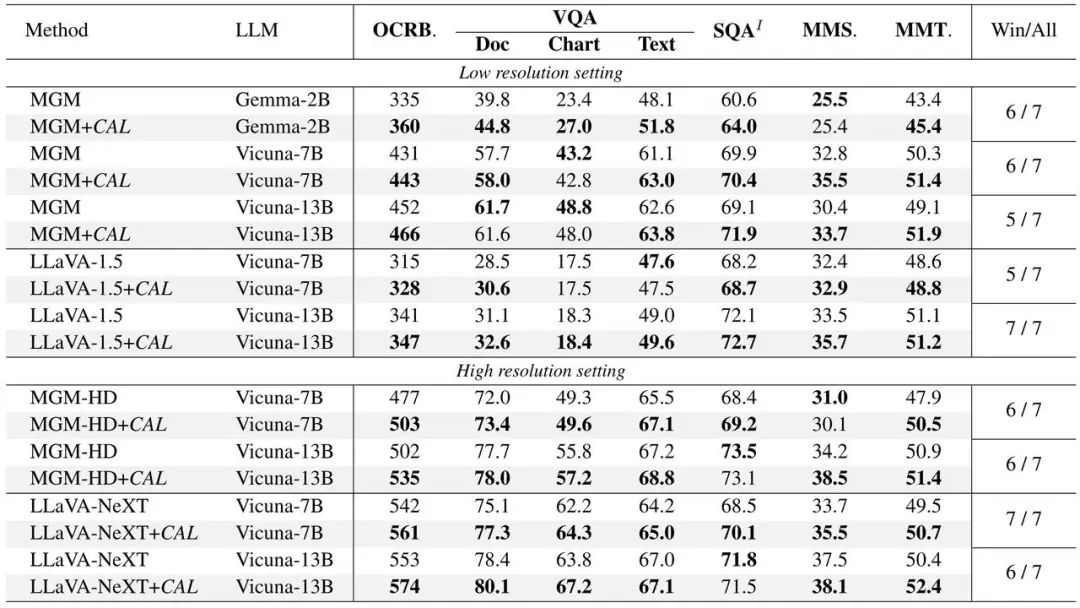

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Déclaration:
Le contenu de cet article est volontairement contribué par les internautes et les droits d'auteur appartiennent à l'auteur original. Ce site n'assume aucune responsabilité légale correspondante. Si vous trouvez un contenu suspecté de plagiat ou de contrefaçon, veuillez contacter admin@php.cn
Article précédent:Tuer comme un fou ! Google convertit la vidéo en parole et des effets sonores réalistes font des vidéos IA un adieu au silence !Article suivant:Tuer comme un fou ! Google convertit la vidéo en parole et des effets sonores réalistes font des vidéos IA un adieu au silence !
Articles Liés
Voir plus- Combien coûte la formation PHP pour les ingénieurs PHP ?
- En débloquant la bonne combinaison de CNN et Transformer, ByteDance propose un transformateur visuel efficace de nouvelle génération
- Le moteur de recherche de ByteDance « Wukong Search » a été officiellement renommé « Little Wukong » et a ajouté des fonctionnalités d'IA avancées
- Il semblerait que le département de jeux de ByteDance soit confronté à des licenciements massifs et qu'il mettra fin à tous les projets non en ligne.
- Le salaire de ByteDance a augmenté tranquillement, avec une augmentation réelle de 20% ! Internaute : La nouvelle tendance du secteur !